正则表达式,又称规则表达式。(英语:Regular Expression,在代码中常简写为regex、regexp或RE),计算机科学的一个概念。正则表达式通常被用来检索、替换那些符合某个模式(规则)的文本。
Python作为一门数据处理语言,经常使用正则匹配段落,比如爬虫爬取数据时。正则表达式是Python内置的模块,不需要额外安装。

今天来给大家分享一份比较全面的Python正则表达式宝典,学会之后,你将掌握正则表达式的各种应用场景。
re模块
re (Regular Expression简写),这个很好记住。
1.导入re模块
在使用正则表达式之前,需要导入re模块。
import re
2.findall()的语法:
导入了re模块之后就可以使用findall()方法了,
re.findall(pattern, string, flags=0)
参数
pattern:必填。正则表达式
string:必填,需要检索的文本, == 确保没乱码 ==
Flags:选填,功能标志位
返回数组
str='a1a2a3'
newStr=re.findall('a\d',str )
nullVlue=re.findall('b\d',str)
print('newStr匹配个数:',len(newStr))
print('newStr匹配结果',newStr)
print('nullVlue匹配个数:',len(nullVlue))
print('nullVlue匹配结果',nullVlue)
显示如下:
newStr匹配个数: 3 newStr匹配结果 ['a1', 'a2', 'a3'] nullVlue匹配个数: 0 nullVlue匹配结果 []
基本语法已经介绍完成了。
正则表达式
1.傻瓜式截取findall
import re text='aaa bbb ccc' rol='aaa (.*) ccc' rul=re.findall(rol ,text) print(rul)
显示如下:
['bbb']
直接复制原来的文本,把想要提取的文本替换成(.*)

表达式解释:
| 表示 | 意义 |
|---|---|
(pattern) |
表示匹配pattern并获取这一匹配。要匹配圆括号字符,请使用" "或" "。 |
. |
匹配除“\n"之外的任何单个字符。要匹配包括"\n"在内的任何字符,请使用像"(.|\n)"的模式。 |
* |
匹配前面的子表达式零次或多次。例如,zo*能匹配“z"以及"zoo"。*等价于{0,}。 |
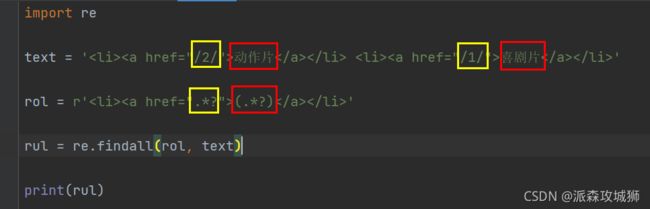
增加替代
显示:
['动作片', '喜剧片']
表达式解释:
| 表示 | 意义 |
|---|---|
? |
非贪婪模式尽可能少的匹配所搜索的字符串,而默认的贪婪模式则尽可能多的匹配所搜索的字符串。 |
pattern |
不带( )表示匹配pattern匹配值不获取~~获取值不输出~~。 |
保留获取
import re text = '
显示:
把括号写在外面就可以了
傻瓜式的讲完了,下面讲讲限定符
1 - [xyz]
字符集合。匹配所包含的任意一个字符。例如,“[abc]“可以匹配"plain"中的"a”。
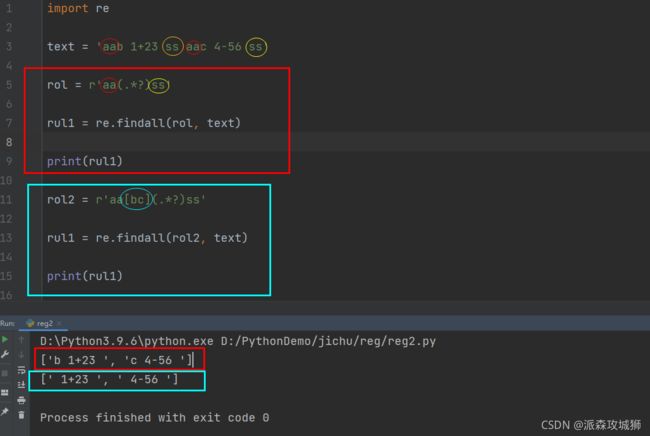
import re text = 'aab 1+23 ss aac 4-56 ss' rol = r'aa(.*?)ss' rul1 = re.findall(rol, text) print(rul1) rol2 = r'aa[bc](.*?)ss' rul1 = re.findall(rol2, text) print(rul1)
输出:
['b 1+23 ', 'c 4-56 ']
[' 1+23 ', ' 4-56 ']
== 表达式解释 ==
①我们可以先把固定的截取下来,红框部分。
②再通过非截取方式把b和c过滤掉,蓝色部分。
③[ ]提供的就是包含功能
2 - {}
| 表示 | 意义 |
|---|---|
{n} |
n是一个非负整数。匹配确定的n次。例如,“o{2}"不能匹配"Bob"中的"o",但是能匹配"food"中的两个o。 |
{n,} |
n是一个非负整数。至少匹配n次。例如,“o{2,}"不能匹配"Bob"中的"o",但能匹配"foooood"中的所有o。"o{1,}"等价于"o+"。"o{0,}"则等价于"o*"。 |
{n,m} |
m和n均为非负整数,其中n<=m。最少匹配n次且最多匹配m次。例如,“o{1,3}"将匹配"fooooood"中的前三个o。"o{0,1}"等价于"o?"。请注意在逗号和两个数之间不能有空格。 |
+ |
匹配前面的子表达式一次或多次。例如,“zo+"能匹配"zo"以及"zoo",但不能匹配"z"。+等价于{1,}。。 |
* |
匹配前面的子表达式零次或多次。例如,zo*能匹配“z"以及"zoo"。*等价于{0,}。 |
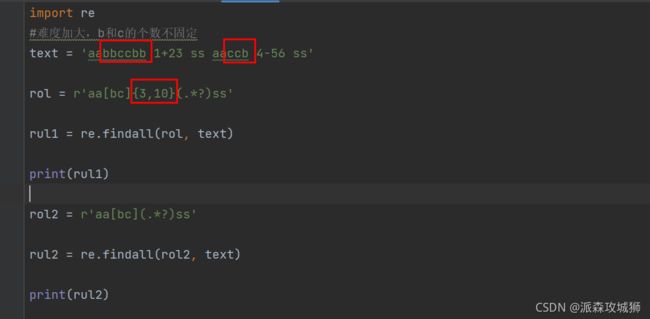
== 难度加大,b和c的个数不固定 ==
import re
#难度加大,b和c的个数不固定
text = 'aabbccbb 1+23 ss aaccb 4-56 ss'
rol = r'aa[bc]{3,10}(.*?)ss'
rul1 = re.findall(rol, text)
print(rul1)
rol2 = r'aa[bc](.*?)ss'
rul2 = re.findall(rol2, text)
print(rul2)
显示:
[' 1+23 ', ' 4-56 ']
['bccbb 1+23 ', 'cb 4-56 ']
3 - (?:pattern)正则断言
断言(Assertions)在正则表达式概念里面难理解,它通常指的是在目标字符串的当前匹配位置进行的一种测试但这种测试并不占用目标字符串,也即不会移动模式在目标字符串中的当前匹配位置。
| 表示 | 意义 |
|---|---|
x|y |
匹配x或y。例如,“z|food"能匹配"z"或"food"。"(z|f)ood"则匹配"zood"或"food"。 |
(?:pattern) |
匹配pattern但不获取匹配结果,也就是说这是一个非获取匹配,不进行存储供以后使用。这在使用或字符“(|)"来组合一个模式的各个部分是很有用。 |
(?=pattern) |
正向肯定预查,在任何匹配pattern的字符串开始处匹配查找字符串。这是一个非获取匹配,也就是说,该匹配不需要获取供以后使用。 |
(?!pattern) |
正向否定预查,在任何不匹配pattern的字符串开始处匹配查找字符串。这是一个非获取匹配,也就是说,该匹配不需要获取供以后使用。 |
(?!pattern) |
正向否定预查,在任何不匹配pattern的字符串开始处匹配查找字符串。这是一个非获取匹配,也就是说,该匹配不需要获取供以后使用。 |
(?<=pattern) |
反向肯定预查,与正向肯定预查类拟,只是方向相反。 |
(? |
反向否定预查,与正向否定预查类拟,只是方向相反。 |
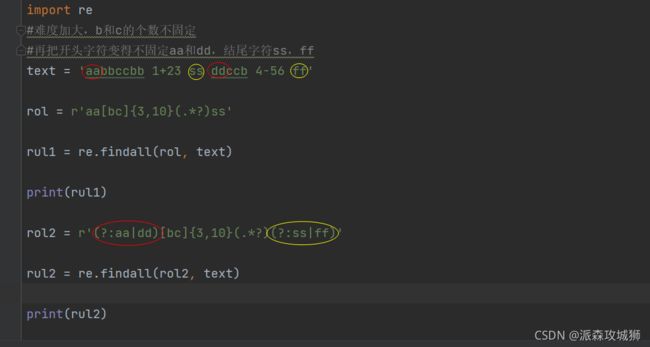
== 再把开头字符变得不固定aa和dd,结尾字符ss,ff ==
import re
#难度加大,b和c的个数不固定
#再把开头字符变得不固定aa和dd,结尾字符ss,ff
text = 'aabbccbb 1+23 ss ddccb 4-56 ff'
rol = r'aa[bc]{3,10}(.*?)ss'
rul1 = re.findall(rol, text)
print(rul1)
rol2 = r'(?:aa|dd)[bc]{3,10}(.*?)(?:ss|ff)'
rul2 = re.findall(rol2, text)
print(rul2)
显示:
[' 1+23 ']
[' 1+23 ', ' 4-56 ']
Python正则flags
编译标志让你可以修改正则表达式的一些运行方式。多个标志可以通过按位 OR-ing 它们来指定。如 re.I | re.M 。flags都有两种形式,缩写和全写都可以。
| 表示 | 意义 |
|---|---|
re.I或re.IGNORECASE |
忽略大小写 |
re.L或re.LOCALE |
使用当地locale。(python中有个locale模块,locale代表不同的语言,地区和字符集) |
re.U或re.UNICODE |
使用unicode的locale |
re.U或re.UNICODE |
使用unicode的locale |
re.M或re.MULTILINE |
使用^或$时会匹配每一行的行首或行尾 |
re.S或re.DOTALL |
使用.时能匹配换行符 |
re.X或re.VERBOX |
忽略空白字符,而且可以加入注释 |
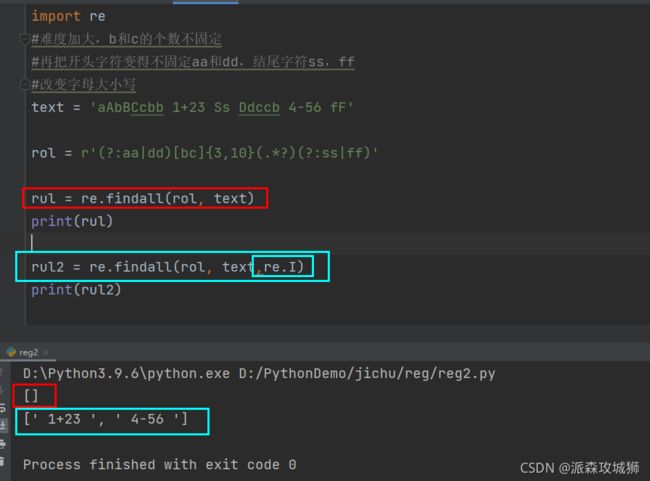
re.I
import re
#难度加大,b和c的个数不固定
#再把开头字符变得不固定aa和dd,结尾字符ss,ff
#改变字母大小写
text = 'aAbBCcbb 1+23 Ss Ddccb 4-56 fF'
rol = r'(?:aa|dd)[bc]{3,10}(.*?)(?:ss|ff)'
rul = re.findall(rol, text)
print(rul)
rul2 = re.findall(rol, text,re.I)
print(rul2)
显示:
[]
[' 1+23 ', ' 4-56 ']
re.M和re.S
import re
#难度加大,b和c的个数不固定
#再把开头字符变得不固定aa和dd,结尾字符ss,ff
#改变字母大小写
#在中间添加一个换行符
text = 'aAbBCcbb 1+23 \n Ss Ddccb 4-56 fF'
rol = r'(?:aa|dd)[bc]{3,10}(.*?)(?:ss|ff)'
rul = re.findall(rol, text,re.I)
print(rul)
rul2 = re.findall(rol, text,re.I|re.S)
print(rul2)
显示:
[' 4-56 ']
[' 1+23 \n ', ' 4-56 ']

== 结果说明 ==
①默认re.M只会匹配在当前 行(非列) 里面进行匹配,“Ss”已经换行了,所以“1+23”没有匹配到。
②re.S表示匹配多行,并且捕获换行符
③re.S|re.I可以并行使用
# 结语 正则的匹配方法,已经写完了,号称万能的文本处理工具,下篇开始讲解,替换,追加。最后最后,感谢大家关注!
到此这篇关于python演示解答正则为什么是最强文本处理工具的文章就介绍到这了,更多相关python 正则内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!