python 获取li的内容_python爬虫xpath篇-以爬取京东商品信息为例附思路和详细代码注释...

这两天在学习python爬虫,有了一些对爬虫的理解和心得。学习的时候在网上查过许多资料,但是由于自己是小白,所以学的时候总是觉得网上的例子不够实在,对我来说有点难懂。然后这段时间学了爬虫之后,也成功实现了几个实例,有了一些理解、思路和方法。为了能够帮助更多的初学者快速入门简单的爬虫,写下这篇文章希望可以对大家有帮助。
这篇文章我主要是通过分享一个实例,来帮助大家理解爬虫的概念、html信息获取方法、如何用xpath定位和获取html内容,以及保存爬到的信息到excel表格。
本文的任务:获取京东surface pro 7第一页显示的所有商品的名称、链接、价格和店铺名称(例子用到的网址点这里),并保存到excel表格中。
本文分成以下几个部分:
- 爬虫是个啥?
- 我要在上面那个链接里完成获取商品信息这个任务,我要怎么做(分几个步骤)?要用到什么工具(一些python包)?
- 首先,我想先说下我对爬虫的理解。我们可以将爬虫看成一个复制粘贴工具,它是在我们浏览一个网页时,代替我们人工去对网页上展示的部分信息进行复制和粘贴到本地的一个工具。(比如我浏览京东的时候,特别想把全部的商品名称和价格复制下来,然后整理到一个excel上,但是一般一个页面有30个商品,手动复制粘贴太慢了,那么爬虫就可以帮你把这些特定的信息自动复制下来,你所要做的就是设定复制的规则即可)
- 要完成一个爬虫的任务(本文任务为例),可以分成以下几个步骤:
- 爬取整个网页信息:
- 你需要获得网址的html信息(浏览器按F12可以查看),因为你看到的整个页面的所有内容都保存在html信息里(自然也包括我们要的所有商品信息):

from - 从爬取到的整个网页信息中筛选出你想要的信息(用xpath路径获取):
获取信息有许多方法,有用BeautiSoup定位信息的、有用re正则表达式的,还可以用xpath定位路径的。试了一圈下来,我个人觉得还是xpath路径方便,也比较适合我(正则表达式太复杂了我完全记不住)。主要是xpath路径浏览器就可以直接获得,比如下图找到价格后,只要右键就可以查看价格所在的完整xpath路径了。

# 由于这个例子是只爬取单个页面,所以直接看下页面有多少个商品,进行循环查找就行
# 如果是要爬取多个页面,则可以再用一个循环来修改url页面参数
# 比如豆瓣电影top250,第一页是https://movie.douban.com/top250?start=0&filter=
# 第二页是https://movie.douban.com/top250?start=25&filter=
# 只要设出参数X,X为25*N,N=0,1,...,对X循环即可
# 对应的url=https://movie.douban.com/top250?start=X&filter=
# 表示从第X个电影开始给出25个电影信息,实际上就是N页
# 京东的翻页也同理
# 如果想要对仍以一个关键词爬取信息,则要先把关键词转换为二进制编码,然后替换url中的keyword部分即可
# 先看看我们要找什么内容,把他们对应的xpath路径先找一个出来:
# 浏览器检查html(F12):定位到对应内容的html源码,将完整xpath路径复制下来
# 商品名称=/html/body/div[7]/div/div[2]/div[1]/div/div[2]/ul/li[7]/div/div[3]/a/em/text()
# 商品链接=/html/body/div[7]/div/div[2]/div[1]/div/div[2]/ul/li[7]/div/div[3]/a/@href
# 商品价格=/html/body/div[7]/div/div[2]/div[1]/div/div[2]/ul/li[7]/div/div[2]/strong/i/text()
# 店铺名称=/html/body/div[7]/div/div[2]/div[1]/div/div[2]/ul/li[4]/div/div[5]/span/a/
# 以商品名称的xpath路径为例,结合html源码,可以看到,如果要找其它的商品名称,只要修改li[4]里面的数字即可
# 后面就好操作了,用个循环表示所有商品信息,改一下路径的字符串就可以了
# 大致为:爬每一个商品信息,存到list里,把list的信息写到excel中保存,完成。
'''
temp = "/html/body/div[7]/div/div[2]/div[1]/div/div[2]/ul/li[7]/div/div[3]/a/em/text()"
temp1 = selector.xpath(temp)
print(temp1)
# /html/body/div[7]/div/div[2]/div[1]/div/div[2]/ul/li[7]/div/div[2]/strong/i
# /html/body/div[7]/div/div[2]/div[1]/div/div[2]/ul/li[1]/div/div[3]/a/em
# /html/body/div[7]/div/div[2]/div[1]/div/div[2]/ul/li[2]/div/div[3]/a/em
# /html/body/div[7]/div/div[2]/div[1]/div/div[2]/ul/li[7]/div/div[3]/a/em/text()
/html/body/div[7]/div/div[2]/div[1]/div/div[2]/ul/li[1]/div/div[2]/strong/i
/html/body/div[7]/div/div[2]/div[1]/div/div[2]/ul/li[30]/div/div[2]/strong/i
'''
datalist = []# 建立一个总表
# 一个页面有30个商品信息
for i in range(0, 30):
data = []#建立一个保存每一个商品信息的列表
t = str(i+1) # 修改xpath路径li[i]的数字
firstlink = "/html/body/div[6]/div[3]/div[2]/div[1]/div/div[2]/ul/li["
# 商品名称
name1 = "/html/body/div[7]/div/div[2]/div[1]/div/div[2]/ul/li["
name2 = "]/div/div[3]/a/em/text()" #加了/text()来获取文本内容
name3 = name1 + t + name2
name = selector.xpath(name3)
data.append(name)
# 商品链接
link1 = "/html/body/div[7]/div/div[2]/div[1]/div/div[2]/ul/li["
link2 = "]/div/div[3]/a/@href"
link3 = link1 + t + link2
link = selector.xpath(link3)
data.append(link)
# 商品价格
price1 = "/html/body/div[7]/div/div[2]/div[1]/div/div[2]/ul/li["
price2 = "]/div/div[2]/strong/i/text()"
price3 = price1 + t + price2
price = selector.xpath(price3)
data.append(price)
#店铺名称
shopname1 = "/html/body/div[7]/div/div[2]/div[1]/div/div[2]/ul/li["
shopname2 = "]/div/div[5]/span/a/text()"
shopname3 = shopname1 + t + shopname2
shopname = selector.xpath(shopname3)
data.append(shopname)
datalist.append(data)- 将筛选出来的信息保存到excel工作表中
# 信息爬完了,是时候存到excel里了
# 此时的列表是有30行,4列
work = xlwt.Workbook(encoding="utf-8")
sheet = work.add_sheet("surface pro 7京东信息表", cell_overwrite_ok=True)
col = ("商品名称","商品链接","商品价格","店铺名称") # 准备excel表头
for i in range(0,4):
sheet.write(0, i, col[i])# 写入表头
print(len(datalist))
for i in range(0,30):
print("第%d条"%(i+1))
data = datalist[i] # 写第i个商品信息
for j in range(0,4):
if len(data[j]) != 0:
sheet.write(i + 1, j, data[j])
else:
sheet.write(i + 1, j, "翻车") # 因为我发现有少数几个店铺返回的信息是空的
work.save("surface pro 7京东信息表.xls")
print("爬取完毕!请到文件目录下查看表格")- 最后贴上完整代码
from scrapy import Selector
from lxml import etree
import urllib.request
import urllib.parse
import xlwt
url = r'https://list.jd.com/list.html?cat=670%2C671%2C2694&ev=exbrand_%E5%BE%AE%E8%BD%AF%EF%BC%88Microsoft%EF%BC%89%5E1107_90246%5E244_116227%5E3753_76033%5E&cid3=2694'
head = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.89 Safari/537.36 Edg/84.0.522.40"}
# 准备好head标识后,网页发送请求,获得html数据
req = urllib.request.Request(url, headers=head)
response = urllib.request.urlopen(req)
# 将获得的数据解码成utf-8格式
html = response.read().decode("utf-8")
# 解析html信息,生成信息树
selector = etree.HTML(html)
# 由于这个例子是只爬取单个页面,所以直接看下页面有多少个商品,进行循环查找就行
# 如果是要爬取多个页面,则可以再用一个循环来修改url页面参数
# 比如豆瓣电影top250,第一页是https://movie.douban.com/top250?start=0&filter=
# 第二页是https://movie.douban.com/top250?start=25&filter=
# 只要设出参数X,X为25*N,N=0,1,...,对X循环即可
# 对应的url=https://movie.douban.com/top250?start=X&filter=
# 表示从第X个电影开始给出25个电影信息,实际上就是N页
# 京东的翻页也同理
# 如果想要对仍以一个关键词爬取信息,则要先把关键词转换为二进制编码,然后替换url中的keyword部分即可
# 先看看我们要找什么内容,把他们对应的xpath路径先找一个出来:
# 浏览器检查html(F12):我们随便定位到几个对应内容的html源码,将完整xpath路径复制下来
# 商品名称=/html/body/div[7]/div/div[2]/div[1]/div/div[2]/ul/li[7]/div/div[3]/a/em/text()
# 商品链接=/html/body/div[7]/div/div[2]/div[1]/div/div[2]/ul/li[7]/div/div[3]/a/@href
# 商品价格=/html/body/div[7]/div/div[2]/div[1]/div/div[2]/ul/li[7]/div/div[2]/strong/i/text()
# 店铺名称=/html/body/div[7]/div/div[2]/div[1]/div/div[2]/ul/li[4]/div/div[5]/span/a/
# 以商品名称的xpath路径为例,结合html源码,可以看到,如果要找其它的商品名称,只要修改li[4]里面的数字即可
# 后面就好操作了,用个循环表示所有商品信息,改一下路径的字符串就可以了
# 大致为:爬每一个商品信息,存到list里,把list的信息写到excel中保存,完成。
'''
temp = "/html/body/div[7]/div/div[2]/div[1]/div/div[2]/ul/li[7]/div/div[3]/a/em/text()"
temp1 = selector.xpath(temp)
print(temp1)
# /html/body/div[7]/div/div[2]/div[1]/div/div[2]/ul/li[7]/div/div[2]/strong/i
# /html/body/div[7]/div/div[2]/div[1]/div/div[2]/ul/li[1]/div/div[3]/a/em
# /html/body/div[7]/div/div[2]/div[1]/div/div[2]/ul/li[2]/div/div[3]/a/em
# /html/body/div[7]/div/div[2]/div[1]/div/div[2]/ul/li[7]/div/div[3]/a/em/text()
/html/body/div[7]/div/div[2]/div[1]/div/div[2]/ul/li[1]/div/div[2]/strong/i
/html/body/div[7]/div/div[2]/div[1]/div/div[2]/ul/li[30]/div/div[2]/strong/i
'''
datalist = []# 建立一个总表
# 一个页面有30个商品信息
for i in range(0, 30):
data = []#建立一个保存每一个商品信息的列表
t = str(i+1) # 修改xpath路径li[i]的数字
firstlink = "/html/body/div[6]/div[3]/div[2]/div[1]/div/div[2]/ul/li["
# 商品名称
name1 = "/html/body/div[7]/div/div[2]/div[1]/div/div[2]/ul/li["
name2 = "]/div/div[3]/a/em/text()" #加了/text()来获取文本内容
name3 = name1 + t + name2
name = selector.xpath(name3)
data.append(name)
# 商品链接
link1 = "/html/body/div[7]/div/div[2]/div[1]/div/div[2]/ul/li["
link2 = "]/div/div[3]/a/@href"
link3 = link1 + t + link2
link = selector.xpath(link3)
data.append(link)
# 商品价格
price1 = "/html/body/div[7]/div/div[2]/div[1]/div/div[2]/ul/li["
price2 = "]/div/div[2]/strong/i/text()"
price3 = price1 + t + price2
price = selector.xpath(price3)
data.append(price)
#店铺名称
shopname1 = "/html/body/div[7]/div/div[2]/div[1]/div/div[2]/ul/li["
shopname2 = "]/div/div[5]/span/a/text()"
shopname3 = shopname1 + t + shopname2
shopname = selector.xpath(shopname3)
data.append(shopname)
datalist.append(data)
# 信息爬完了,是时候存到excel里了 # 此时的列表是有30行,4列
work = xlwt.Workbook(encoding="utf-8")
sheet = work.add_sheet("surface pro 7京东信息表", cell_overwrite_ok=True)
col = ("商品名称","商品链接","商品价格","店铺名称")
# 准备excel表头
for i in range(0,4):
sheet.write(0, i, col[i])# 写入表头
print(len(datalist))
for i in range(0,30):
print("第%d条"%(i+1))
data = datalist[i] # 写第i个商品信息
for j in range(0,4):
if len(data[j]) != 0:
sheet.write(i + 1, j, data[j])
else:
sheet.write(i + 1, j, "翻车") # 因为我发现有少数几个店铺返回的信息是空的
work.save("surface pro 7京东信息表.xls")
print("爬取完毕!请到文件目录下查看表格")- 效果如下:
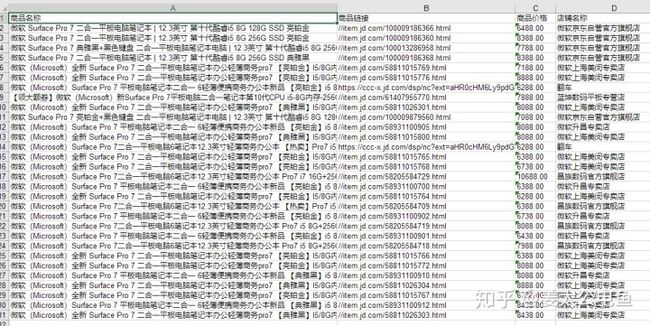
- 总结:个人觉得一个完整的爬虫代码,主要分为html信息获取、html信息筛选和信息保存三个步骤。而最重要也是最容易出错的地方就是制定信息筛选规则部分了(如代码中找xpath路径的部分,从上图看出有两个店铺返回的是空信息,有可能是这两个店铺的路径规则和其它的不同的问题)。
- 而html信息获取环节,一般的网页带上headers就可以防止服务器反爬了,更深一点的反爬以及动态信息部分,我的理解还不够深刻,所以暂时不讨论了。不过我记得动态信息(如下拉加载更多等)可以f12后查找js信息也许可以获得真实的网址以及后续加载的文本内容(比如b站就是这样(b站首页除外),比如单机游戏区的按视频热度排序得到的结果信息并没有保存在html里面,而是保存在js所以获得的html信息不包含这些内容。当然这一段话是个人理解,也不知道准不准确,希望有看到的大佬能够在评论区指点指点)
