Node EE方案 -- Rockerjs在微店的建设与发展
阅读目录
- Node EE的前世今生
- Rockerjs的野蛮生长
- 未来的挑战
- JOIN US,JOIN NODE EE GROUP
本文是根据2019.4.13日参加 “Node-Party”论坛使用的PPT,加上笔者新的思考与沉淀而来。在此再次感谢贝贝网前端部门和芋头君以及相关与会人员的支持! —— 微店杨力(曾用名 欲休)
- Node EE的前世今生
- 什么是 Node EE
- Node EE的诞生
- Node EE范畴
- 总结
- Rockerjs的野蛮生长
- 什么是Rockerjs
- Rockerjs-Core
- Rockerjs-MVC
- RPC
- ORM
- 分布式调用链路追踪
- 自动埋点
- 埋点与“ThreadLocal”
- APM
- 监控
- 诊断
- 总结
- 未来的挑战
- JOIN US,JOIN NODE EE GROUP
Node EE的前世今生
什么是 Node EE
Node EE全称为 “Node Enterprise Edition”,它是微店在探索Node.js在企业级开发过程中结合中间件、运维、测试相关经验与方案,给出的一套相对完整的企业级解决方案。
我们可通过数学集合图了解Node EE与Node.js的关系: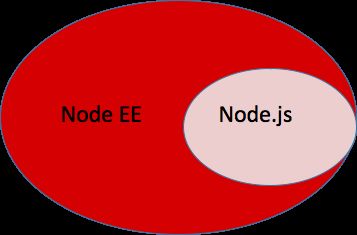
Node.js的集合部分包括:进程、文件、网络、流、JavaScript语言,再往底层包括JavaScript引擎V8和事件循环的实现libuv,通常我们都是用Node.js的这些模块以及相关的底层服务实现业务逻辑。
Node EE集合包含了Node.js,那么Node EE到底有哪些 “额外”的功能呢?在这里先埋下一个疑点,我们将会在下文中给出答案。
哎等等,现在只介绍了Node EE大概是什么,还未点 “前世今生” 的题呢。我们把思路撤回到原点,Node EE是如何诞生的,它是KPI的产物吗,是重复造轮子吗?
Node EE的诞生
首先扔出一张图,
作为开发人员,我们非常熟悉当需求来时,每个角色的分工如何。在这里总结了技术人员视角的三类角色:
- 与用户、产品距离最近,冲在用户侧第一线的“市场、产品与运营”
- 设计与研发侧,包括“UED、业务开发、测试”
- 基础侧,包括“中间件、运维”
这三类角色完成了互联网公司日常的运营生产活动。由市场人员洞悉当前需求或运营同学发起一些日常活动,由产品人员进行具体的需求总结与产品设计,这样“任务流程”就流转到第二层“设计研发侧”。通过UED设计、视觉评审、prd评审、技术评审后开始进入具体业务开发,测试人员设计测试用例以及可能存在的性能测试、安全测试等;于此同时底层的“基础侧”需要给上层提供相关服务,如机器、存储、CI、中间件产品、基础接口等,保障研发侧的顺利上线。当研发侧与基础侧都测试完毕后,交付给市场人员、运营和用户,完成一轮生产流程。
这个生产流程每日在公司不停的上演,以致于在大多数参与其中的成员看来也没什么问题,都已习惯于这样的生产模式中。可是在仔细分析整个生产流程中,我们会发现一个问题,一个有关 生产速率 的问题:
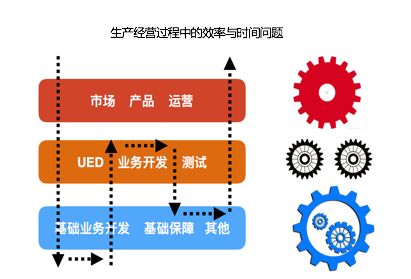
上图中,黑色的虚线标识生产流程的流转,右侧的三种齿轮代表不同角色的响应速率。作为冲在第一线的“市场、产品与运营”而言,他们为了响应市场、用户、舆论的反应,必须快速应对,因此对应红色的齿轮必须高速率运转;可作为“研发侧”的“UED、业务开发和测试人员”而言,无法及时快速响应第一线的“小、快”需求,因此对应的黑色齿轮转速远低于红色齿轮。研发侧无法快速响应,不仅仅与提出的大量需求有关,也和研发的客观规律有关,“快速”与“可靠”很难进行权衡;作为基础侧,由于相关系统建设且功能逐渐稳定,因此响应的速度也是较快,即蓝色齿轮转速高于上层的黑色齿轮。
简单来说,生产活动中,红色齿轮转速过快,黑色齿轮转速太慢,蓝色齿轮转速一般。这类似与“木桶理论”,由于瓶颈(研发侧)的存在,导致整个流程无法快速运行,也是大多数企业面临的头痛问题。
换个角度,从经济学中的“微笑曲线”同样能找到相关情形:
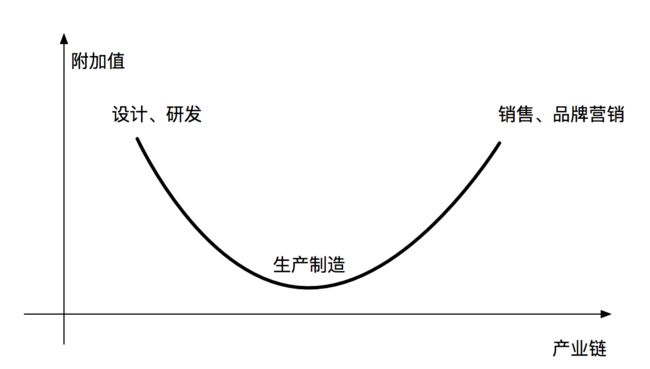
“微笑曲线”的纵轴为“附加值”,可粗略理解为产品的增值,横轴为产业链,对比上图可带入为三种角色。
其中微笑曲线产业链的“销售、品牌营销”对应互联网中生产经营的第一层“市场、产品与运营”,产业链的“生产制造”对应于研发层“业务开发、测试”,产业链的“设计、研发”对应于研发层的“业务开发、测试”和基础侧的“中间件、运维”等。
在互联网公司中,作为产业链附加价值最低的生产制造环节其实是“业务开发与测试”,这里充斥了太多频繁、琐碎、重复且没有太多技术含量的劳动量,而且由于生产制造环节流程冗长,因此占用了较大的生产时间。但是,“业务开发与测试”同时也是产业链中“研发”的一部分,在疲于生产制造的同时还需要进行部分研发任务,如系统架构、高可用优化、数据采集分析、自动化测试等,这一项显然大大提高了相关的附加值。
因此,根据“微笑曲线”,作为业务研发人员要想最大化自身价值,应该尽可能的将自己的产业链属性向“研发侧”延伸,尽一切努力摆脱千篇一律的“生产制造”属性,同时通过某种手段,减少“生产制造”环节的时间占比,甚至于在互联网公司特殊的轻资产模型下,由产业链的另一端“销售、营销”实现快速“生产”。
为了解决效能问题并且兼顾提升业务开发人员的“设计、研发”能力,微店给出了 中台化的答案,由研发侧向“一线市场、产品与运营”交付各种系统,让他们自己快速实现自己的需求并上线,如果无法实现,则由业务人员快速产出并沉淀为模块待下次使用。这就对 中台化 的各种系统提出了强大能力的要求,目前,微店在 建模平台、搭建平台、数据分析平台、前后端协作平台、接口搭建平台等领域都进行了尝试,实现了超过60%的需求在第一线解决。
搭建这么多服务平台,离不开服务端编码。我们经过调研了Java技术栈、Node.js技术栈和Golang技术栈,最终选择了前端开发人员比较熟悉的Node.js技术栈,在这里不详细讲述。因此,可以说是微店的中台化催生了微店全栈化,而微店全栈化在发展过程中提出了Node EE理念。

总结一下,齿轮转速均衡 -> 业务侧研发快速响应 -> 业务建模平台、搭建平台等支持、专业的业务辅助团队解决平台无法解决的部分 -> 全栈化 -> Node EE ,这就是Node EE的产生。
Node EE范畴
还记得首节的Node EE与Node.js的数学集合图吗?它只表明两者的包含关系并未细化Node EE的每一块领域。下图则是Node EE在Node.js基础之上衍生出来的相关方向: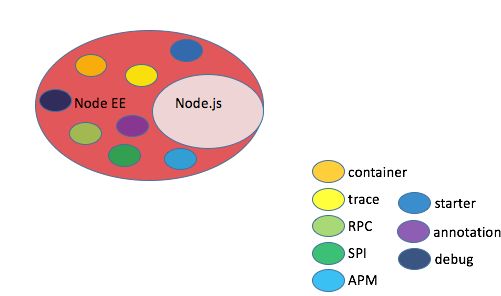
Node EE包括了 “应用容器、调用链路追踪、RPC、模块扩展规范SPI、Starter机制、注解、调试(远程)、APM” 等方面,这是在微店的生产过程中总结出的可代表大多数场景的几个方向,如有其他方面的遗漏,欢迎加入我们 Node EE小组 一起探讨。
应用容器并不是一个新的概念,在Java领域早已成为一种规范。但是在Node.js领域没有容器的说法,某些方面讲进程管理工具如PM2在某些方面却拥有容器的部分功能。Node EE中的应用容器可管理所有注解标识类的实例化对象,并管理其生命周期、对象间的依赖关系;当使用这些对象时可通过注解直接引用,无需手动实例化或建立对象间依赖;同时它也负责各种模块的初始化与运行,如Component、Filter、Controller和Server。因此,容器化可以让开发者无需关心依赖、编写可重构代码,把复杂的事情留给容器。
调用链路追踪是后端开发中必须解决的问题,开发者和测试人员必须清楚每一个请求对应的后端链路,分析瓶颈并解决问题。
RPC则是构建微服务必不可少的一环,并且必须与 链路追踪 打通才有意义,同时Node应用不应只作为RPC的消费者,有许多场景需要Node应用提供服务提供方的要求,因此也需要考虑。
关于SPI(Service Provider Interface),则是Node EE对面向扩展开放的一种实现规则。Starter机制是Node EE兼顾编码理念 配置优先还是约定优先 的一种尝试。
Node EE主张采用元编程的方法简化代码逻辑,TypeScript的装饰器是我们最终的选择。在Node EE中将装饰器称之为Annotation(注解),它是Node EE建设的基石,贯穿于编码的方方面面。通过Annotation实现DI(依赖注入)和元信息注册可极大简化代码,理清逻辑。
至于debug和APM,则是应用正常运行的保障。远程debug保障在线即时调试,APM则时刻监视应用资源的状况,同时提供在线profile功能。
总结
Node EE是面向企业级应用开发场景,满足应用高可维护、可扩展,在无缝接入各级中间件同时,能追踪请求的各层链路、远程调试、在线实时监控与性能分析。
Node EE有以下特点:
开发时体验爽
运行时放心跑
故障时快速调
重构时尽管改哎呦
“做企业和开发者喜欢的Node EE方案” -- Rockerjs的目标
Rockerjs的野蛮生长
什么是Rockerjs
Rockerjs是微店对Node EE的一种探索和实现。它基于注解提供 IoC 和 AOP 的特性在简化模块依赖的同时让编码二维化,基于此衍生出来了MVC框架、RPC、Node Persistence of XML、ThreadLocal 、trace、SPI、分布式事务及容器监控等中间件,目前微店内部多个平台与外网服务基于此而生。
Rockerjs的核心理念是: 容器化与IoC。容器化可让开发人员专注于业务,不关心非核心业务的实现;IoC则简化依赖,依赖倒置,可扩展性高。
Rockerjs-Core
Rockerjs的核心是 Rockerjs-Core,它是基于 TypeScript 和注解的轻量级IoC容器,提供了依赖注入、面向切面编程及异常处理等功能。Rockerjs-Core可在任意工程中引入,是一个框架无关的IoC容器。源码:https://github.com/weidian-inc/rockerjs-core文档:https://rockerjs.weidian.com/rockerjs/core.html
Rockerjs-MVC
Rockerjs的主要应用场景是Web服务端开发, Rockerjs-MVC 便是为了解决服务端开发的MVC框架。它基于 Rockerjs-Core构建,是一套基于配置、具有轻量级容器特性且集成了链路追踪功能的Node.js Web应用框架。 源码:https://github.com/weidian-inc/rockerjs-mvc 文档:https://rockerjs.weidian.com/compass/mvc.html
Rockerjs-MVC有如下特点:
- 配置大于一切
- 约定简化编码
- 元编程思想
- DI解耦
- 默认集成调用链路追踪
- TS强类型约束
- 面向对象、面向接口
- 熟悉的main函数
技术细节如下:
由容器维护Rockerjs-MVC和应用中的各种模块,如component、starter、filter、controller等。filter采用职责链模式可通过配置文件设置顺序,最终请求由 dispatcher 分发给对应的controller。service负责每次处理事务,包括DAO、RPC等。最终controller的响应再由dispatcher下发给插件 view resolver,渲染完毕后返回响应。
Rockerjs-MVC内部通过插件的形式扩展渲染模板,目前提供了基于vue和ejs模板的渲染引擎。
Rockerjs-MVC实例
index.ts
import { Application, AbstractApplication } from "@rockerjs/mvc";
@Application
class App extends AbstractApplication{
public static async main(args: RockerConfig.Application) {
console.log('main bussiness', args);
}
}homeController.ts
import { Controller, Get, Param, Request } from '@rockerjs/mvc';
@Controller("/home")
export class HomeController {
@Get({url: '/a'})
async home(@Param("name") name: string, @Param("person") person: object) {
return {
tag: 'hello world',
name,
person
}
}
}app.dev.config
port=8080
[filter:trace]
[mysql]
starter=@rockerjs/mysql-starter
host=127.0.0.1
user=NODE_PERF_APP_user
port=3308
database=NODE_PERF_APP
password=root
resourcePath=model/resourceRockerjs-MVC中通过 app.${env}.config 定义相关初始化信息,相关的类与中间件都交于容器并根据配置文件进行实例化和初始化,这样就完成一个最简单应用的搭建。具体使用,请详见 文档。
RPC
Node EE推荐的RPC方式为 “Dubbo和HTTP”。Node EE设计初期考虑到与现存系统无缝接入的需求,因此毫无顾虑的投入 Dubbo 的怀抱。在Dubbo中间件领域内,我们开发了基于此协议的 Consumer 和 Provider支撑业务需求。
- consumer
- 支持泛化调用,无需声明接口动态调用
- 测试阶段可配置负载策略
- provider
- 支持泛化调用
- 兼容常规HTTP接口
- Java研发快速上手
- 服务治理
关于Dubbo Provider,我们采用Proxy和Facade设计模式尽可能让前后端开发人员快速、可扩展的编写代码,同时兼容已有项目。
@Dubbo({
interface: 'com.vdian.vstudio.service.ProjectService',
method: 'getProjectInfo',
params: ['id','type'],
version: '1.0.0',
nodeServerUri: '/dubbo/get/project'
})
@Post({ url: '/get/project'})
@AutoWrap
public async getProjectInfo(@Param('param') param: {id: number, type: string}, @Param('context') context: object) {
const {id,type} = param;
let result = await this.projectService.getProjectInfoAll(id,type);
return {
project: result
}
}技术细节图如下: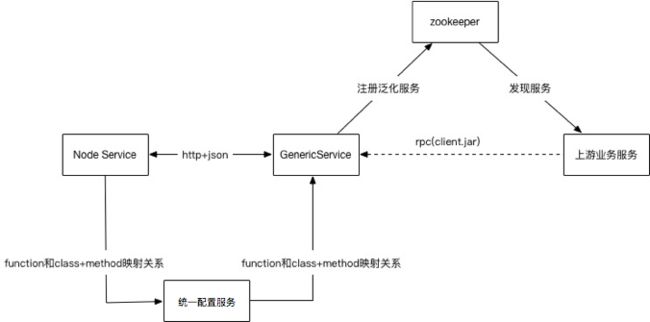
关于Dubbo Provider的详细细节,可参考我的一篇文章# [Nodejs“实现”Dubbo Provider](https://www.cnblogs.com/accordion/p/9391320.html)。
ORM
ORM的框架与库有很多,可是在开发过程中传统的基于对象操作实现SQL的生成往往会有些问题:
- 复杂查询如join的支持、多表查询
- 性能
- 代码维护差
- 安全审计无从谈起
因此Node EE并没有采用传统的ORM框架,而是采用XML模板渲染的形式构建SQL语句,语法与mybatis极度相似。这样的好处不言而喻:
- 模板重用性极高
- 方便维护
- 后端人员无缝上手
- 安全审计容易
示例:
appInfoMapper.xml
insert into app_info ( appid,secrete,username,appname )
#{appid},#{secrete},#{username},#{appname}
update app_info
${key} = #{data[key]},
${key} = #{data[key]}
${key} = #{info[key]} and
${key} = #{info[key]}
delete from app_info where appid=#{appid}
详细使用场景,可参考示例:https://github.com/weidian-inc/rockerjs-demo
分布式调用链路追踪
当打开微店商品详情页时,该请求在后端所有链路的追踪如下所示: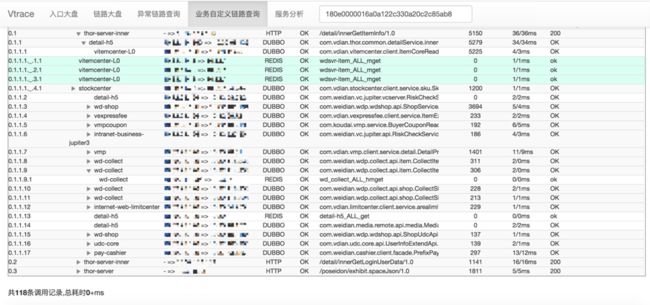
每个请求处理都可追溯到每次RPC调用、每次中间件调用,调用结果及响应时间都可追溯到。这样在消耗一些性能的前提下完成所有请求的追踪是性价比极高的行为,在请求出错的排查、链路压测等情况下尤其有用。
那么,Node.js中如何实现链路追踪的呢?这得益于 Rockerjs-MVC 提供的tracer机制以及相关生态 “Rockerjs-midLogger-starter、Rockerjs-mysql-starter、Rockerjs-redis-starter、Rockerjs-RPC-starter”的支持。

当请求过来时,由网关层生成一个全局唯一的TraceId,在所有的系统调用中传递,包括RPC、DB、Redis、MQ。同时通过日志采集存储在不同的存储介质中,进行离线或实时分析,最终通过看板进行呈现或设置。
那么,Node EE如何进行调用信息的传递呢?
自动埋点
- 由 Rockerjs-MVC和其他中间件创建调用上下文,生成埋点信息
- TraceId、RPCId、isSample等
- 自动埋点,埋点信息由中间件自动放入当前请求的“ThreadLocal”,对开发者完全透明
- 调用上下文在整个链路的透传
- Dubbo调用采用Attachment机制
- HTTP采用header透传
- 中间件请求则本地记录日志
埋点与“ThreadLocal”
我“自作主张”在Node.js领域起了一个已存在的名词 “ThreadLocal”,它实际上是不准确的,因为Node.js中执行线程只有一个不存在多个执行线程,不过为了大多数人的直观理解,本文仍然采用“ThreadLocal”。准确的讲,它应该被叫做 “Async Context Bound”,即异步上下文绑定。它可与请求相绑定,在HTTP上下文、WebSocket上下文、中间件上下文都可使用。
ThreadLocal 变量作为线程内的局部变量,在多线程下可以保持独立,它存在于线程的生命周期内,可以在线程运行阶段多个模块间共享数据。
上节中的链路追踪就是采用“ThreadLocal”特性实现的,它可脱离HTTP上下文在任意场景下获取相关信息。
关于“ThreadLocal”的实现,可参考我的两篇文章:
- 基于Zone.js的实现:node.js与ThreadLocal(AsyncContext Bound)
- 基于Async Hooks的实现:https://github.com/royalrover/threadlocal
APM
关于应用性能监控与调试,由于有了alinode和easy-monitor的存在,在这里不再详细赘述(具体的实现大体一致)。我们自建了NPS性能平台,专注于Node应用性能监控与在线Profile分析:
通过看板可选择Node项目相关操作,如诊断与监控。
监控
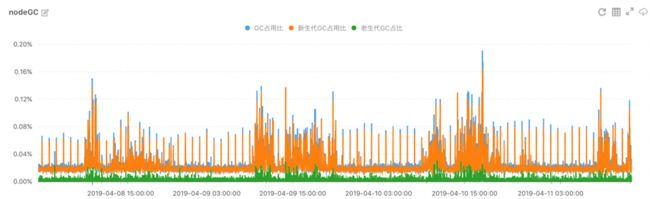
监控主要从三个维度进行,分别是“堆内存、CPU使用率和GC频率”,基本可表征应用的当前运行信息与资源瓶颈: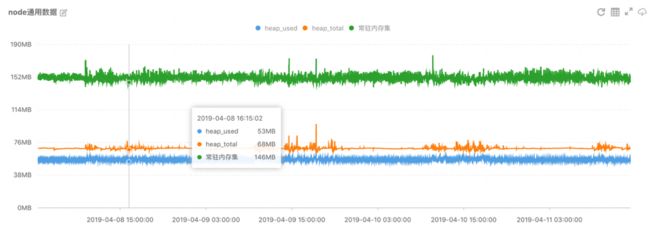

诊断
诊断部分参考了easy-monitor的UI设计,在此感谢作者。NPS可针对进程的内存与CPU进行打点分析,如: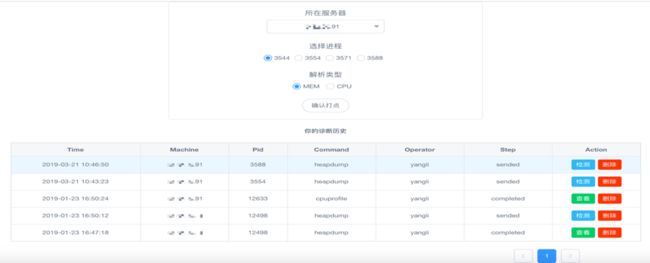
同时和easy-monitor一样提供了自动分析功能: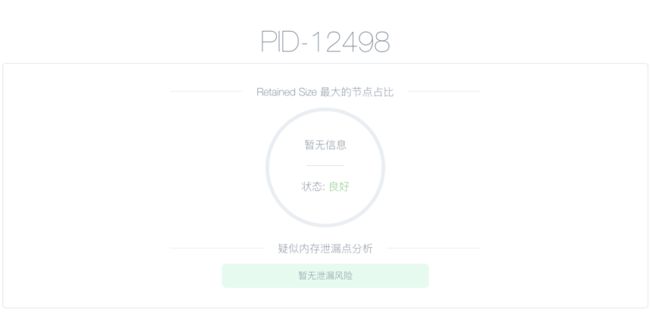

通过实时监控和线上诊断,再配合远程debug,可以放心的在线上运行Node应用。
总结
梳理了Node EE的各个方面,整理了一张结构图,如下:
自底向上,所有的应用进程的性能信息、在线分析功能都依托于 “probe agent” 服务,它以deamon的形式存在于每一台机器上;在此之上,每个应用的核心都是容器,由它负责依赖管理、实例创建、模块初始化、应用启动;在容器之上,衍生了Rockerjs-MVC,同时提供特殊的异常处理机制、SPI扩展规范、AOP编程以及基于注解的tsunit;在右侧有颜色部分,trace追踪散布于调用各阶段;监控、远程调试和日志同样贯穿于应用的整个生命周期。
Node EE中还有些细节并没有探讨,比如进程管理、远程调试等等,这会在后续提供相应服务。
未来的挑战
Node EE是微店在自己业务范围内探索的一套适合自己 小步快跑、快速迭代 业务特点的解决方案,它不可能涵盖所有的场景和需求,因此有些遗漏实属正常,需要社区一起共建。
目前,仍然存在三个方向急需建设:
- 生态建设
- WebSocket兼容
- xxxStarter
- CLI
- Plugins(graphQL、Restful)
- ...
- 框架周边建设
- Rockerjs-MVC
- Rockerjs-DAO
- Rockerjs-Tracer
- Rockerjs-TCC
- 文档建设
- https://rockerjs.weidian.com/
- https://github.com/weidian-inc/rockerjs-mvc
转载:https://www.cnblogs.com/accordion/p/10837180.html