CDNOW用户购买行为分析 - 2020
这是我练习的一个Python数据分析项目
数据来源于国外一家CD网站的销售情况
我们根据这份数据从多个维度进行分析,这是一篇很基础的电商分析案例
一、基础数据清洗
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus']=False
%matplotlib inline
plt.style.use('ggplot')
columns = ['user_id','order_dt','order_products','order_amount']
df=pd.read_csv('CDNOW_master.txt',names=columns,sep='\s+')
df.head()
| user_id | order_dt | order_products | order_amount | |
|---|---|---|---|---|
| 0 | 1 | 19970101 | 1 | 11.77 |
| 1 | 2 | 19970112 | 1 | 12.00 |
| 2 | 2 | 19970112 | 5 | 77.00 |
| 3 | 3 | 19970102 | 2 | 20.76 |
| 4 | 3 | 19970330 | 2 | 20.76 |
- user_id : 用户ID
- order_dt : 购买日期
- order_products : 购买产品数量
- order_amount : 购买金额
df.describe()
| user_id | order_dt | order_products | order_amount | |
|---|---|---|---|---|
| count | 69659.000000 | 6.965900e+04 | 69659.000000 | 69659.000000 |
| mean | 11470.854592 | 1.997228e+07 | 2.410040 | 35.893648 |
| std | 6819.904848 | 3.837735e+03 | 2.333924 | 36.281942 |
| min | 1.000000 | 1.997010e+07 | 1.000000 | 0.000000 |
| 25% | 5506.000000 | 1.997022e+07 | 1.000000 | 14.490000 |
| 50% | 11410.000000 | 1.997042e+07 | 2.000000 | 25.980000 |
| 75% | 17273.000000 | 1.997111e+07 | 3.000000 | 43.700000 |
| max | 23570.000000 | 1.998063e+07 | 99.000000 | 1286.010000 |
- 一共有约7w条消费记录
- 消费金额的中位数低于平均值,说明有极大值干扰,数据向右偏移
- 注:平均值受极值/异常值干扰,中位数不受影响
- 注:这里的平均值并不是人均,因为一个用户可能多条消费记录,需要剔除
df['order_dt'] = pd.to_datetime(df.order_dt,format='%Y%m%d') #修改为日期格式
df.head()
| user_id | order_dt | order_products | order_amount | |
|---|---|---|---|---|
| 0 | 1 | 1997-01-01 | 1 | 11.77 |
| 1 | 2 | 1997-01-12 | 1 | 12.00 |
| 2 | 2 | 1997-01-12 | 5 | 77.00 |
| 3 | 3 | 1997-01-02 | 2 | 20.76 |
| 4 | 3 | 1997-03-30 | 2 | 20.76 |
df.info()
RangeIndex: 69659 entries, 0 to 69658
Data columns (total 4 columns):
user_id 69659 non-null int64
order_dt 69659 non-null datetime64[ns]
order_products 69659 non-null int64
order_amount 69659 non-null float64
dtypes: datetime64[ns](1), float64(1), int64(2)
memory usage: 2.1 MB
然后新增一列月份,方便我们后续做数据统计分析,这里有两个方法。
方法一:通过截取order_dt再拼接成类似2020-2-1的Month,因为有不同年份,单独截取月容易混淆
#df['month1'] = df.order_dt.map(lambda x : str(x)[:8]+'01')
#df['month1'] = pd.to_datetime(df.month1,format='%Y-%m-%d') #修改为日期格式,注意这里要加中横杠匹配
方法二:通过astype(‘datetime64[M]’)转成日期,很巧妙的方法;
df['month'] = df.order_dt.values.astype('datetime64[M]')
df.tail(10)
| user_id | order_dt | order_products | order_amount | month | |
|---|---|---|---|---|---|
| 69649 | 23564 | 1997-11-30 | 3 | 46.47 | 1997-11-01 |
| 69650 | 23565 | 1997-03-25 | 1 | 11.77 | 1997-03-01 |
| 69651 | 23566 | 1997-03-25 | 2 | 36.00 | 1997-03-01 |
| 69652 | 23567 | 1997-03-25 | 1 | 20.97 | 1997-03-01 |
| 69653 | 23568 | 1997-03-25 | 1 | 22.97 | 1997-03-01 |
| 69654 | 23568 | 1997-04-05 | 4 | 83.74 | 1997-04-01 |
| 69655 | 23568 | 1997-04-22 | 1 | 14.99 | 1997-04-01 |
| 69656 | 23569 | 1997-03-25 | 2 | 25.74 | 1997-03-01 |
| 69657 | 23570 | 1997-03-25 | 3 | 51.12 | 1997-03-01 |
| 69658 | 23570 | 1997-03-26 | 2 | 42.96 | 1997-03-01 |
二、用户消费分析(by month)
- 每月的消费总额
- 每月的消费次数(订单数)
- 每月的产品购买总量
- 每月的消费人数
group_month = df.groupby(by='month')
group_month_amount = group_month.order_amount.sum()
group_month_amount.plot()
plt.title('Total Amount of Order_month')
plt.show()
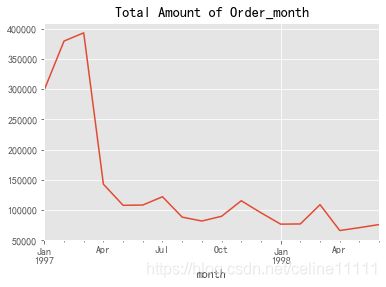
消费总额第一个月30k,连续增长2个月即将到达40k之后开始陡然下降,一个月之后降到15k,之后数据趋于平稳波动
group_month_person = group_month.user_id.count() #这里用count而非sum
group_month_person.plot()
plt.title('Total Quantitly of Order_month')
plt.show()

每月的订单数量,趋势和消费总额类似
group_month_frequency = group_month.order_products.sum()
group_month_frequency.plot()
plt.title("Total Quantity of Products_month")
plt.show()
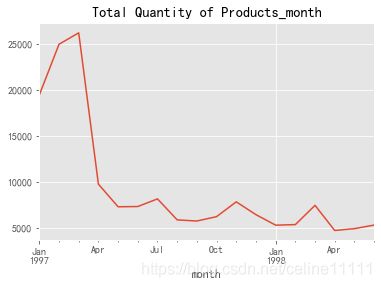
产品购买总量,趋势和消费总额类似
group_month.user_id.apply(lambda x : len(x.drop_duplicates())).plot()
plt.title("Total Quantity of Customer_month")
plt.show()
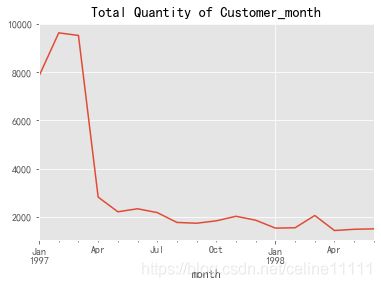
求每月消费人数,需要去重
#没学会,待查
#df1 = df.groupby(by=['month','user_id']).count().reset_index()[['month','user_id']]
#df1.head()
另一种方法求出上述的分析,通过pivot_table透视表:
df1 = df.pivot_table(
values=['order_amount','order_products','user_id'],
index='month',
aggfunc={
'order_products':'sum',
'order_amount':'sum',
'user_id':'count'})
df1.head()
| order_amount | order_products | user_id | |
|---|---|---|---|
| month | |||
| 1997-01-01 | 299060.17 | 19416 | 8928 |
| 1997-02-01 | 379590.03 | 24921 | 11272 |
| 1997-03-01 | 393155.27 | 26159 | 11598 |
| 1997-04-01 | 142824.49 | 9729 | 3781 |
| 1997-05-01 | 107933.30 | 7275 | 2895 |
#df1.order_amount.plot()
#df1.order_products.plot()
#df1.user_id.plot()
深入分析每月平均消费趋势
- 每月用户平均消费金额的趋势
- 每月用户平均消费的数量
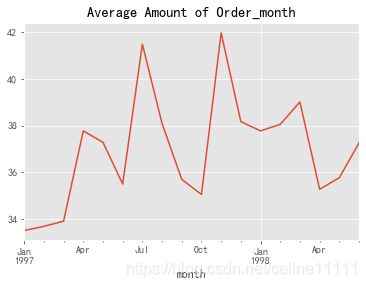
group_month_avg_amount = group_month.order_amount.mean()
group_month_avg_amount.plot()
plt.title('Average Amount of Order_month')
plt.show()
group_month_avg_products = group_month.order_products.mean()
group_month_avg_products.plot()
plt.title('Average Quantity of Products_month')
plt.show()

- 每月平均消费金额和产品数趋势类似
三、用户个体消费分析(一)
- 用户消费金额、购买产品数量的描述统计
- 用户消费金额的散点图
- 用户消费金额的直方分布图
- 用户消费次数的直方分布图
- 用户累计消费金额的占比(帕累托图)
group_user = df.groupby(by='user_id')
group_user.sum().describe()
| order_products | order_amount | |
|---|---|---|
| count | 23570.000000 | 23570.000000 |
| mean | 7.122656 | 106.080426 |
| std | 16.983531 | 240.925195 |
| min | 1.000000 | 0.000000 |
| 25% | 1.000000 | 19.970000 |
| 50% | 3.000000 | 43.395000 |
| 75% | 7.000000 | 106.475000 |
| max | 1033.000000 | 13990.930000 |
- 每位用户的平均消费金额是106,中位数43,最大值13990,最小值0(可能脏数据),受极大值干扰
- 每位用户的平均购买产品数量是7,中位数3,,最大值1033,最小值1,受极大值干扰
- 注:平均值受极值/异常值干扰,中位数不受影响
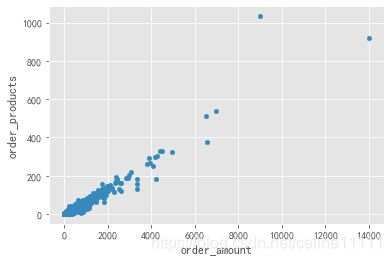
group_user.sum().plot.scatter(x ='order_amount',y='order_products') #有异常值
plt.show()
group_user.sum().query('order_products<300').plot.scatter(x ='order_amount',y='order_products') #加入筛选条件
plt.show()
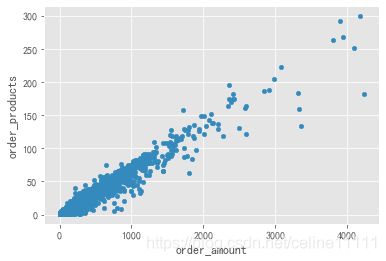
散点图可以揭示出规律,但是没法看出分层感
下面我们通过直方图来分析不同层级的用户消费金额占比
group_user.sum().order_amount.plot.hist(bins=100)
plt.title('Purchase Amount')
Text(0.5, 1.0, 'Purchase Amount')
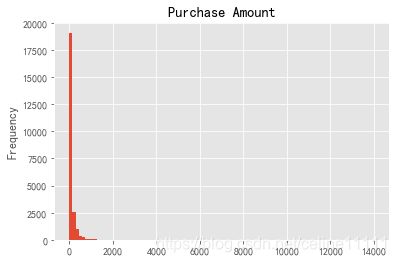
通过对消费总额进行分层,可以看出大部分用户消费都消费很少,只有极小部分用户消费大额,符合二八定律
下面我们通过切比雪夫定理计算出95%的消费次数都聚集在0~90之间,加上筛选条件剔除异常值
group_user.sum().query('order_products<90').order_products.plot.hist(bins=20)
plt.title('Purchase Frequency')
Text(0.5, 1.0, 'Purchase Frequency')
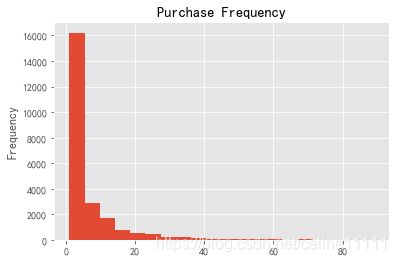
*可以看出大部分用户只购买了5张CD,占比约 (16200/23570)100% = 68%
df_cumsum = group_user.sum().sort_values(by='order_amount')
df_cumsum['cumsum']=df_cumsum['order_amount'].cumsum()
df_cumsum['cumsum_rate']=df_cumsum['cumsum']/sum(df_cumsum['order_amount'])
df_cumsum.tail()
df_cumsum.reset_index().cumsum_rate.plot() #记得reset_index
plt.title('Cumsum Rate')
Text(0.5, 1.0, 'Cumsum Rate')
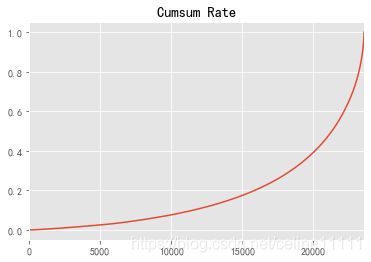
按照消费累计金额作图,后面20%的用户消费占总额的60%
四、用户消费行为(二)
- 用户首购
- 用户最后一次消费
- 新老客消费比
- 多少用户只消费了1次
- 每月新客占比
- 用户分层
- RFM
- 新客、活跃、回流、流失/不活跃
group_user.min().order_dt.value_counts().plot()
plt.title('First Purchase')
Text(0.5, 1.0, 'First Purchase')
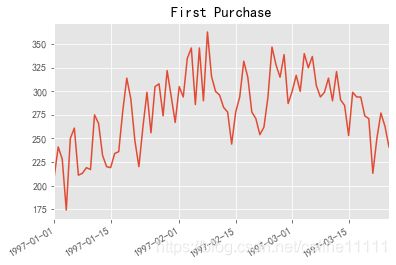
- 整个消费数据包括1997和1998年,但是新增聚集在1997/1~1997/3,后面都是老客购买
group_user.max().order_dt.value_counts().plot()
plt.title('Last Purchase')
Text(0.5, 1.0, 'Last Purchase')
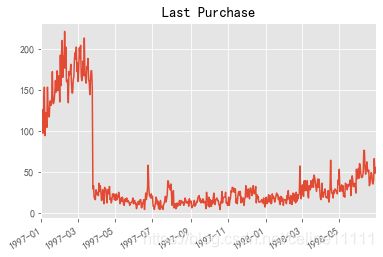
- 最后一次购买,大部分最后一次购买也聚集在前3个月,说明很多用户可能只消费1次,后面就不消费了
df_agg = df.groupby(by='user_id').order_dt.agg(['min','max']) #groupby和agg搭配
df_agg.tail()
| min | max | |
|---|---|---|
| user_id | ||
| 23566 | 1997-03-25 | 1997-03-25 |
| 23567 | 1997-03-25 | 1997-03-25 |
| 23568 | 1997-03-25 | 1997-04-22 |
| 23569 | 1997-03-25 | 1997-03-25 |
| 23570 | 1997-03-25 | 1997-03-26 |
df_agg.query('max == min').count()
min 12054
max 12054
dtype: int64
- 只消费1次的用户有12054人,消费1次以上的11516人,约51%仅消费1次
rfm = df.pivot_table(index='user_id',
values=['order_dt','order_amount','order_products'],
aggfunc={
'order_dt':np.max,
'order_amount':np.sum,
'order_products':np.sum})
rfm.tail()
#分别从RFM三个维度取值,其中距今最近一次消费日期需要再加工处理
| order_amount | order_dt | order_products | |
|---|---|---|---|
| user_id | |||
| 23566 | 36.00 | 1997-03-25 | 2 |
| 23567 | 20.97 | 1997-03-25 | 1 |
| 23568 | 121.70 | 1997-04-22 | 6 |
| 23569 | 25.74 | 1997-03-25 | 2 |
| 23570 | 94.08 | 1997-03-26 | 5 |
rfm['R'] = (rfm.order_dt.max() - rfm.order_dt).astype('timedelta64[D]')
rfm.rename(columns={
'order_amount':'M','order_products':'F'},inplace=True)
rfm.head()
| M | order_dt | F | R | |
|---|---|---|---|---|
| user_id | ||||
| 1 | 11.77 | 1997-01-01 | 1 | 545.0 |
| 2 | 89.00 | 1997-01-12 | 6 | 534.0 |
| 3 | 156.46 | 1998-05-28 | 16 | 33.0 |
| 4 | 100.50 | 1997-12-12 | 7 | 200.0 |
| 5 | 385.61 | 1998-01-03 | 29 | 178.0 |
def func(x):
result = str(x[0])+str(x[1])+str(x[2])
if result == '111':
return '重要价值客户'
if result == '110':
return '一般价值客户'
if result == '100':
return '一般挽留客户'
if result == '101':
return '重要挽留客户'
if result == '010':
return '一般保持客户'
if result == '011':
return '重要保持客户'
if result == '001':
return '重要发展客户'
if result == '000':
return '一般发展客户'
rfm['new']=rfm[['R','F','M']].apply(lambda x: x-x.mean()).applymap(lambda y:1 if y>=0 else 0).apply(func_ql,axis=1)
#这里是否以平均数为基准需要以实际场景为准,中位数也可以替代
rfm.head()
| M | order_dt | F | R | new | |
|---|---|---|---|---|---|
| user_id | |||||
| 1 | 11.77 | 1997-01-01 | 1 | 545.0 | 一般发展客户 |
| 2 | 89.00 | 1997-01-12 | 6 | 534.0 | 一般发展客户 |
| 3 | 156.46 | 1998-05-28 | 16 | 33.0 | 重要保存客户 |
| 4 | 100.50 | 1997-12-12 | 7 | 200.0 | 一般挽留客户 |
| 5 | 385.61 | 1998-01-03 | 29 | 178.0 | 重要保存客户 |
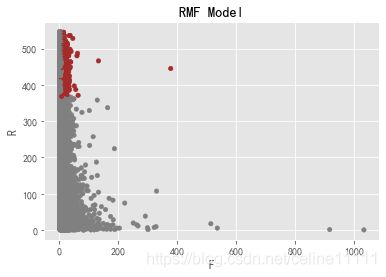
rfm.loc[rfm.new == '重要价值客户','color'] = 'brown'
rfm.loc[~(rfm.new == '重要价值客户'),'color'] = 'gray'
rfm.plot.scatter('F','R',c=rfm.color)
plt.title('RMF Model')
Text(0.5, 1.0, 'RMF Model')
rfm.groupby('new').agg(['count','sum'])
| M | F | R | color | |||||
|---|---|---|---|---|---|---|---|---|
| count | sum | count | sum | count | sum | count | sum | |
| new | ||||||||
| 一般价值客户 | 77 | 7181.28 | 77 | 650 | 77 | 36295.0 | 77 | graygraygraygraygraygraygraygraygraygraygraygr... |
| 一般保持客户 | 206 | 19937.45 | 206 | 1712 | 206 | 29448.0 | 206 | graygraygraygraygraygraygraygraygraygraygraygr... |
| 一般发展客户 | 14074 | 438291.81 | 14074 | 29346 | 14074 | 6951815.0 | 14074 | graygraygraygraygraygraygraygraygraygraygraygr... |
| 一般挽留客户 | 3300 | 196971.23 | 3300 | 13977 | 3300 | 591108.0 | 3300 | graygraygraygraygraygraygraygraygraygraygraygr... |
| 重要价值客户 | 787 | 167080.83 | 787 | 11121 | 787 | 358363.0 | 787 | brownbrownbrownbrownbrownbrownbrownbrownbrownb... |
| 重要保存客户 | 4554 | 1592039.62 | 4554 | 107789 | 4554 | 517267.0 | 4554 | graygraygraygraygraygraygraygraygraygraygraygr... |
| 重要发展客户 | 241 | 33028.40 | 241 | 1263 | 241 | 114482.0 | 241 | graygraygraygraygraygraygraygraygraygraygraygr... |
| 重要挽留客户 | 331 | 45785.01 | 331 | 2023 | 331 | 56636.0 | 331 | graygraygraygraygraygraygraygraygraygraygraygr... |
- 分别从人数/count和消费总额M/sum两个维度展示
- 重要保持客户消费金额占比最高,人数占比却不高,符合二八定律
status_pivot = df.pivot_table(index='user_id',columns='month',values='order_products',aggfunc='count').fillna(0)
#一共18个月
status = status_pivot.applymap(lambda x: 1 if x>0 else 0)
status.head()
| month | 1997-01-01 00:00:00 | 1997-02-01 00:00:00 | 1997-03-01 00:00:00 | 1997-04-01 00:00:00 | 1997-05-01 00:00:00 | 1997-06-01 00:00:00 | 1997-07-01 00:00:00 | 1997-08-01 00:00:00 | 1997-09-01 00:00:00 | 1997-10-01 00:00:00 | 1997-11-01 00:00:00 | 1997-12-01 00:00:00 | 1998-01-01 00:00:00 | 1998-02-01 00:00:00 | 1998-03-01 00:00:00 | 1998-04-01 00:00:00 | 1998-05-01 00:00:00 | 1998-06-01 00:00:00 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| user_id | ||||||||||||||||||
| 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 2 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 3 | 1 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 1 | 0 |
| 4 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 |
| 5 | 1 | 1 | 0 | 1 | 1 | 1 | 1 | 0 | 1 | 0 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 0 |
def active_status(data):
lt = []
for i in range(18):
#当i月没有消费的情况下
if data[i] == 0:
if len(lt) > 0: #判断列表中如果有状态
if lt[i-1]=='未注册':
lt.append('未注册') #当列表中的状态是未注册,本月未消费,所以状态仍然是未注册
else:
lt.append('不活跃') #当列表中的状态是剩下3种不活跃/新用户/活跃中任一状态,因本月未消费,所以状态为不活跃
else:
lt.append('未注册') #判断列表中没有任何状态,则为未注册
#当i月有消费的情况下
else:
if len(lt) > 0: #判断列表中如果有状态
if lt[i-1]=='未注册':
lt.append('新用户') #当列表中的状态是未注册,本月有消费,所以状态是新用户
elif lt[i-1]=='不活跃':
lt.append('回流') #当列表中的状态是不活跃,本月有消费,所以状态是回流
else:
lt.append('活跃') #剩下的两个状态新用户/活跃,本月有消费,状态都是‘活跃’
else:
lt.append('新用户') #判断列表中如果无状态,本月有消费,所以状态是新用户
return pd.Series(lt)
status_transfer = status.apply(active_status,axis=1)
status_transfer.columns = status.columns
status_transfer.head()
| month | 1997-01-01 00:00:00 | 1997-02-01 00:00:00 | 1997-03-01 00:00:00 | 1997-04-01 00:00:00 | 1997-05-01 00:00:00 | 1997-06-01 00:00:00 | 1997-07-01 00:00:00 | 1997-08-01 00:00:00 | 1997-09-01 00:00:00 | 1997-10-01 00:00:00 | 1997-11-01 00:00:00 | 1997-12-01 00:00:00 | 1998-01-01 00:00:00 | 1998-02-01 00:00:00 | 1998-03-01 00:00:00 | 1998-04-01 00:00:00 | 1998-05-01 00:00:00 | 1998-06-01 00:00:00 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| user_id | ||||||||||||||||||
| 1 | 新用户 | 不活跃 | 不活跃 | 不活跃 | 不活跃 | 不活跃 | 不活跃 | 不活跃 | 不活跃 | 不活跃 | 不活跃 | 不活跃 | 不活跃 | 不活跃 | 不活跃 | 不活跃 | 不活跃 | 不活跃 |
| 2 | 新用户 | 不活跃 | 不活跃 | 不活跃 | 不活跃 | 不活跃 | 不活跃 | 不活跃 | 不活跃 | 不活跃 | 不活跃 | 不活跃 | 不活跃 | 不活跃 | 不活跃 | 不活跃 | 不活跃 | 不活跃 |
| 3 | 新用户 | 不活跃 | 回流 | 活跃 | 不活跃 | 不活跃 | 不活跃 | 不活跃 | 不活跃 | 不活跃 | 回流 | 不活跃 | 不活跃 | 不活跃 | 不活跃 | 不活跃 | 回流 | 不活跃 |
| 4 | 新用户 | 不活跃 | 不活跃 | 不活跃 | 不活跃 | 不活跃 | 不活跃 | 回流 | 不活跃 | 不活跃 | 不活跃 | 回流 | 不活跃 | 不活跃 | 不活跃 | 不活跃 | 不活跃 | 不活跃 |
| 5 | 新用户 | 活跃 | 不活跃 | 回流 | 活跃 | 活跃 | 活跃 | 不活跃 | 回流 | 不活跃 | 不活跃 | 回流 | 活跃 | 不活跃 | 不活跃 | 不活跃 | 不活跃 | 不活跃 |
四种状态:新用户-活跃用户-回流用户-不活跃用户
status_value_count = status_transfer.replace('未注册',np.NaN).apply(lambda x:pd.value_counts(x))
status_value_count
| month | 1997-01-01 00:00:00 | 1997-02-01 00:00:00 | 1997-03-01 00:00:00 | 1997-04-01 00:00:00 | 1997-05-01 00:00:00 | 1997-06-01 00:00:00 | 1997-07-01 00:00:00 | 1997-08-01 00:00:00 | 1997-09-01 00:00:00 | 1997-10-01 00:00:00 | 1997-11-01 00:00:00 | 1997-12-01 00:00:00 | 1998-01-01 00:00:00 | 1998-02-01 00:00:00 | 1998-03-01 00:00:00 | 1998-04-01 00:00:00 | 1998-05-01 00:00:00 | 1998-06-01 00:00:00 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 不活跃 | NaN | 6689.0 | 14046 | 20748.0 | 21356.0 | 21231.0 | 21390.0 | 21798.0 | 21831.0 | 21731.0 | 21542.0 | 21706.0 | 22033.0 | 22019.0 | 21510.0 | 22133.0 | 22082.0 | 22064.0 |
| 回流 | NaN | NaN | 595 | 1049.0 | 1362.0 | 1592.0 | 1434.0 | 1168.0 | 1211.0 | 1307.0 | 1404.0 | 1232.0 | 1025.0 | 1079.0 | 1489.0 | 919.0 | 1029.0 | 1060.0 |
| 新用户 | 7846.0 | 8476.0 | 7248 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 活跃 | NaN | 1157.0 | 1681 | 1773.0 | 852.0 | 747.0 | 746.0 | 604.0 | 528.0 | 532.0 | 624.0 | 632.0 | 512.0 | 472.0 | 571.0 | 518.0 | 459.0 | 446.0 |
status_value_count.fillna(0).T.sort_index(axis=1,ascending=False).plot.area()
plt.title("Rate of Four Status in A Life Cycle")
Text(0.5, 1.0, 'Rate of Four Status in A Life Cycle')
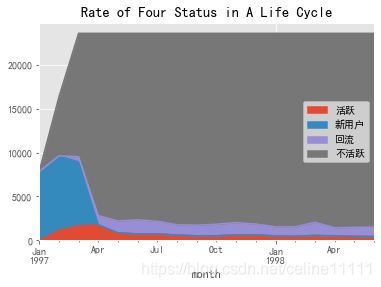
status_value_count.fillna(0).T.sort_index(axis=1,ascending=False).apply(lambda x:x/x.sum())
#计算占比,看得出当月新增/活跃/回流/流失占比
| 活跃 | 新用户 | 回流 | 不活跃 | |
|---|---|---|---|---|
| month | ||||
| 1997-01-01 | 0.000000 | 0.332881 | 0.000000 | 0.000000 |
| 1997-02-01 | 0.090011 | 0.359610 | 0.000000 | 0.019337 |
| 1997-03-01 | 0.130776 | 0.307510 | 0.031390 | 0.040606 |
| 1997-04-01 | 0.137934 | 0.000000 | 0.055342 | 0.059981 |
| 1997-05-01 | 0.066283 | 0.000000 | 0.071854 | 0.061739 |
| 1997-06-01 | 0.058114 | 0.000000 | 0.083988 | 0.061377 |
| 1997-07-01 | 0.058036 | 0.000000 | 0.075653 | 0.061837 |
| 1997-08-01 | 0.046989 | 0.000000 | 0.061620 | 0.063017 |
| 1997-09-01 | 0.041077 | 0.000000 | 0.063888 | 0.063112 |
| 1997-10-01 | 0.041388 | 0.000000 | 0.068953 | 0.062823 |
| 1997-11-01 | 0.048545 | 0.000000 | 0.074070 | 0.062276 |
| 1997-12-01 | 0.049168 | 0.000000 | 0.064996 | 0.062751 |
| 1998-01-01 | 0.039832 | 0.000000 | 0.054075 | 0.063696 |
| 1998-02-01 | 0.036720 | 0.000000 | 0.056924 | 0.063655 |
| 1998-03-01 | 0.044422 | 0.000000 | 0.078554 | 0.062184 |
| 1998-04-01 | 0.040299 | 0.000000 | 0.048483 | 0.063985 |
| 1998-05-01 | 0.035709 | 0.000000 | 0.054286 | 0.063838 |
| 1998-06-01 | 0.034697 | 0.000000 | 0.055922 | 0.063786 |
五、用户周期
-
用户购买周期
-
用户消费周期描述及分布
-
用户生命周期(第一次和最后一次消费)
-
用户生命周期描述及分布
order_datediff = group_user.apply(lambda x: x.order_dt - x.order_dt.shift())
#shift()向下偏移1行,shift(2)则为2行,shift(-1)则为向上1行。如果只移动DataFrame一列,df['R']= df['R'].shift()
#同一个用户的不同日期相减,得出消费周期
order_datediff.head(10)
user_id
1 0 NaT
2 1 NaT
2 0 days
3 3 NaT
4 87 days
5 3 days
6 227 days
7 10 days
8 184 days
4 9 NaT
Name: order_dt, dtype: timedelta64[ns]
order_datediff.describe()
count 46089
mean 68 days 23:22:13.567662
std 91 days 00:47:33.924168
min 0 days 00:00:00
25% 10 days 00:00:00
50% 31 days 00:00:00
75% 89 days 00:00:00
max 533 days 00:00:00
Name: order_dt, dtype: object
可以看出平均消费周期是68天,中位数是31天
order_datediff.astype('timedelta64[D]').hist(bins=20)
plt.title('Purchase Cycle')
Text(0.5, 1.0, 'Purchase Cycle')
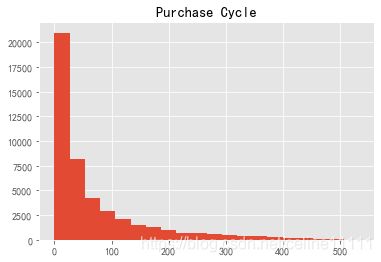
- 20%的用户周期小于100天
- 订单周期呈指数下降趋势
life_cycle = df.groupby(by='user_id').order_dt.agg(['min','max'])
life_cycle.head()
| min | max | |
|---|---|---|
| user_id | ||
| 1 | 1997-01-01 | 1997-01-01 |
| 2 | 1997-01-12 | 1997-01-12 |
| 3 | 1997-01-02 | 1998-05-28 |
| 4 | 1997-01-01 | 1997-12-12 |
| 5 | 1997-01-01 | 1998-01-03 |
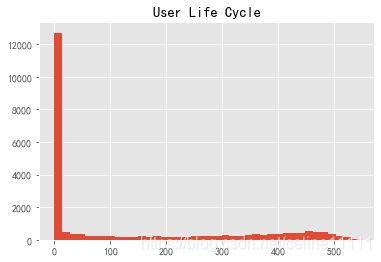
(life_cycle['max']-life_cycle['min']).describe() #注意这种特殊用法,max和min是method,并非列名
count 23570
mean 134 days 20:55:36.987696
std 180 days 13:46:43.039788
min 0 days 00:00:00
25% 0 days 00:00:00
50% 0 days 00:00:00
75% 294 days 00:00:00
max 544 days 00:00:00
dtype: object
(life_cycle['max']-life_cycle['min']).astype('timedelta64[D]').hist(bins=40)
plt.title('User Life Cycle')
#很多0值,只消费1次,为了不影响统计结果,这里暂时排除这部分用户
Text(0.5, 1.0, 'User Life Cycle')
(life_cycle['max']-life_cycle['min']).astype('timedelta64[D]').replace(0,np.NaN).dropna().hist(bins=40)
plt.title('User Life Cycle')
Text(0.5, 1.0, 'User Life Cycle')
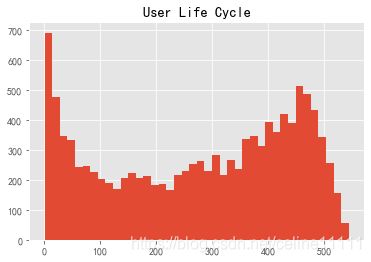
- 排除仅消费1次的用户之后,可以发现其他用户的生命周期趋势稳定
- 用户平均消费周期是134天,而中位数是0天,猜测是搞活动的时候有大部分用户涌入,活动结束,再没有消费
六、复购率和回购率
- 复购率:本月之内多次购买的用户
- 回购率:曾经购买过的用户再次购买
status_pivot = df.pivot_table(index='user_id',columns='month',values='order_products',aggfunc='count').fillna(0)
status_pivot.head()
| month | 1997-01-01 00:00:00 | 1997-02-01 00:00:00 | 1997-03-01 00:00:00 | 1997-04-01 00:00:00 | 1997-05-01 00:00:00 | 1997-06-01 00:00:00 | 1997-07-01 00:00:00 | 1997-08-01 00:00:00 | 1997-09-01 00:00:00 | 1997-10-01 00:00:00 | 1997-11-01 00:00:00 | 1997-12-01 00:00:00 | 1998-01-01 00:00:00 | 1998-02-01 00:00:00 | 1998-03-01 00:00:00 | 1998-04-01 00:00:00 | 1998-05-01 00:00:00 | 1998-06-01 00:00:00 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| user_id | ||||||||||||||||||
| 1 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 2 | 2.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 3 | 1.0 | 0.0 | 1.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 2.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 |
| 4 | 2.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 5 | 2.0 | 1.0 | 0.0 | 1.0 | 1.0 | 1.0 | 1.0 | 0.0 | 1.0 | 0.0 | 0.0 | 2.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
repurchase = status_pivot.applymap(lambda x: 1 if x>1 else 0 if x==1 else np.NaN)
repurchase.head()
#消费1次+属于复购,返回1,消费1次,不计数返回0,无消费返回NA
| month | 1997-01-01 00:00:00 | 1997-02-01 00:00:00 | 1997-03-01 00:00:00 | 1997-04-01 00:00:00 | 1997-05-01 00:00:00 | 1997-06-01 00:00:00 | 1997-07-01 00:00:00 | 1997-08-01 00:00:00 | 1997-09-01 00:00:00 | 1997-10-01 00:00:00 | 1997-11-01 00:00:00 | 1997-12-01 00:00:00 | 1998-01-01 00:00:00 | 1998-02-01 00:00:00 | 1998-03-01 00:00:00 | 1998-04-01 00:00:00 | 1998-05-01 00:00:00 | 1998-06-01 00:00:00 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| user_id | ||||||||||||||||||
| 1 | 0.0 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 2 | 1.0 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 3 | 0.0 | NaN | 0.0 | 0.0 | NaN | NaN | NaN | NaN | NaN | NaN | 1.0 | NaN | NaN | NaN | NaN | NaN | 0.0 | NaN |
| 4 | 1.0 | NaN | NaN | NaN | NaN | NaN | NaN | 0.0 | NaN | NaN | NaN | 0.0 | NaN | NaN | NaN | NaN | NaN | NaN |
| 5 | 1.0 | 0.0 | NaN | 0.0 | 0.0 | 0.0 | 0.0 | NaN | 0.0 | NaN | NaN | 1.0 | 0.0 | NaN | NaN | NaN | NaN | NaN |
(repurchase.sum()/repurchase.count()).plot()
plt.title('Repuchase Rate')
#注意count()计算自动剔除NA值
Text(0.5, 1.0, 'Repuchase Rate')
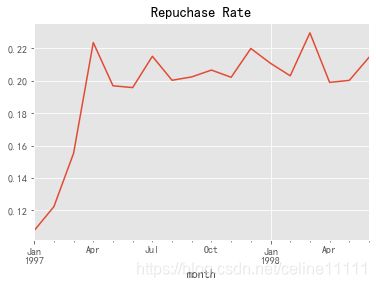
- 复购率前3个月一直在攀升,后期在20%上下稳定浮动
status = status_pivot.applymap(lambda x: 1 if x>0 else 0)
status.head()
| month | 1997-01-01 00:00:00 | 1997-02-01 00:00:00 | 1997-03-01 00:00:00 | 1997-04-01 00:00:00 | 1997-05-01 00:00:00 | 1997-06-01 00:00:00 | 1997-07-01 00:00:00 | 1997-08-01 00:00:00 | 1997-09-01 00:00:00 | 1997-10-01 00:00:00 | 1997-11-01 00:00:00 | 1997-12-01 00:00:00 | 1998-01-01 00:00:00 | 1998-02-01 00:00:00 | 1998-03-01 00:00:00 | 1998-04-01 00:00:00 | 1998-05-01 00:00:00 | 1998-06-01 00:00:00 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| user_id | ||||||||||||||||||
| 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 2 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 3 | 1 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 1 | 0 |
| 4 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 |
| 5 | 1 | 1 | 0 | 1 | 1 | 1 | 1 | 0 | 1 | 0 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 0 |
def purchase_back_func(data):
lst=[]
for i in range(17): #这里记得是17,如果写range(18)报错'index out of bounds'
#计算规则:在前1列消费的基础上看后1列是否有消费,最后1列NA填充
#当第1列值为1,说明有消费
if data[i] == 1:
if data[i+1] == 1: #判断如果后1列也有消费,返回1,否则返回0
lst.append(1)
if data[i+1] == 0:
lst.append(0)
#当第1列值为0,说明无消费,返回NA
else:
lst.append(np.NaN)
lst.append(np.NaN) #最后1列NA填充,因为后面没有数值判断
return pd.Series(lst)
purchase_back = status.apply(purchase_back_func,axis=1)
purchase_back.columns = status.columns
purchase_back.head()
| month | 1997-01-01 00:00:00 | 1997-02-01 00:00:00 | 1997-03-01 00:00:00 | 1997-04-01 00:00:00 | 1997-05-01 00:00:00 | 1997-06-01 00:00:00 | 1997-07-01 00:00:00 | 1997-08-01 00:00:00 | 1997-09-01 00:00:00 | 1997-10-01 00:00:00 | 1997-11-01 00:00:00 | 1997-12-01 00:00:00 | 1998-01-01 00:00:00 | 1998-02-01 00:00:00 | 1998-03-01 00:00:00 | 1998-04-01 00:00:00 | 1998-05-01 00:00:00 | 1998-06-01 00:00:00 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| user_id | ||||||||||||||||||
| 1 | 0.0 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 2 | 0.0 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 3 | 0.0 | NaN | 1.0 | 0.0 | NaN | NaN | NaN | NaN | NaN | NaN | 0.0 | NaN | NaN | NaN | NaN | NaN | 0.0 | NaN |
| 4 | 0.0 | NaN | NaN | NaN | NaN | NaN | NaN | 0.0 | NaN | NaN | NaN | 0.0 | NaN | NaN | NaN | NaN | NaN | NaN |
| 5 | 1.0 | 0.0 | NaN | 1.0 | 1.0 | 1.0 | 0.0 | NaN | 0.0 | NaN | NaN | 1.0 | 0.0 | NaN | NaN | NaN | NaN | NaN |
(purchase_back.sum()/purchase_back.count()).plot()
plt.title('Puchase Back Rate')
Text(0.5, 1.0, 'Puchase Back Rate')
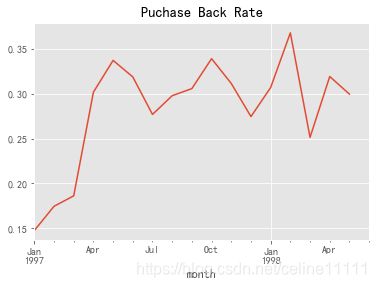
小结:
这是一个很经典的电商数据分析思路,对于新手熟悉分析思路很有帮助,不过涉及的知识面并不少,新手可能因为看不懂个别知识点而困惑,建议遇到的问题都记录下来,一个个去查清楚,理解透彻,适合“精读”。
如果时间充裕,建议先阅读一本书《利用Python进行数据分析·第2版》,点击直达电子版链接,读完再回来开始项目会更游刃有余。
项目分析小结:
- 首先运用了python的不同数据包panda/numpy进行数据清洗/整理
- 并使用python/matplotlib进行数据可视化
- 最后使用了不同类型的python函数进行深入的分析:
- 分组函数groupby + 聚合函数agg
- 数据透析表pivot_table + 聚合参数aggfunc
- 日期格式转换astype
- 函数映射apply/map/applymap
- reset_index()、sort_values()、values_count()等
完结。