基于word2vec和TextCNN的新闻标题分类器
一、背景
本人做新闻爬虫工作,由于工作需要,经常需要将一个列表页中的a标签链接进行提前并进行抓取,但问题是,如何确定一个列表页大概率是新闻页面那?
起初,通过一些规则的方法,比如新闻高频词来确定是否是新闻列表页,但由于热词更新的滞后以及无热词页面,规则匹配的效果变得很差,故放弃了该方案。后期,通过总结新闻标题的模式发现,
新闻和非新闻的标题内容在用词以及语义上存在明显的区别,如果规则解决不了的问题,也许可以借助NLP来解这个问题。经过调研,发现有很多通过NLP来实现对评论进行情感分类的项目,
都是二分类的问题,自己目前面临的问题也是二分类,这坚定了我趟这条路的信心。
二、技术路线
由于面临的问题是一个文本二分类问题,所以有两个问题需要解决:
- 如何将标题向量化,以喂给模型训练。
- 选择什么模型来训练数据。
通过调研,问题1可通过Word2vec将词的语义嵌入到一个低维向量中。问题2解决方法很多,由于时下正是深度学习大红大紫之时,因此选择了TextCNN,它是一种卷积神经网络,在文本分类领域表现非常抢眼。
三、Word2vec
Word2vec是非常流行的词嵌入(将一个词表示成一个向量)方法之一而Word2vec是其中的佼佼者,其主要优点是:
- 可以将文本在低维空间中进行稠密表示,克服了one-shot的表示稀疏性。
- 可以很好的表达词与词之间的语义相似性,如 “国王” 和 "女王",“男人” 和 “女人”,但是one-shot表示是体现不出这种相似性的。
Word2vec的流行实现有Skip和CBOW,在此不做详述,感兴趣的可以参考 秒懂词向量Word2vec 。
词向量的问题解决之后,便可以将不同词的词向量表示成二维矩阵输入给TextCNN进行训练。
四、TextCNN
TextCNN是一个基于卷积神经网络的文本分类模型,在众多应用领域表现非常出色,原始论文是Convolutional Neural Networks for Sentence Classification。本文的工作均参考了
How to Develop a Multichannel CNN Model for Text Classification 文中的实现。同图像分类一样,TextCNN的输入也是一个 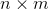 的二维矩阵,然后通过卷积层和池化层进行特征提取,
的二维矩阵,然后通过卷积层和池化层进行特征提取,
最后展平卷积部分的输出到一个全连接层,最后输出层给出分类结果。其中, 表示词汇表的大小,
表示词汇表的大小, 表示词嵌入的维度,表示我们希望将一个词嵌入到一个多少维的向量空间中。
表示词嵌入的维度,表示我们希望将一个词嵌入到一个多少维的向量空间中。
TextCNN的基本思想是实现了一个多通道的卷积神经网络,并通过融合不同通道的信息进行文本分类。
具体的,通过设定多组尺寸不同的卷积核,每组卷积核对应不同大小的滑动窗口。比如,可以分别设定核尺寸大小为1、2、4的三组卷积核,每组的数量自行设定,这样,
每组卷积核可在不同大小的滑动窗口中提取语义特征,最后融合不同组的卷积核所提取的特征(通过concatenate实现),并将融合后的特征向量送入全连接层层,输出层最后给出最终的分类,
大体的思想是这样,细节方面可以参考原始论文。下图很好的阐述了其基本实现过程。
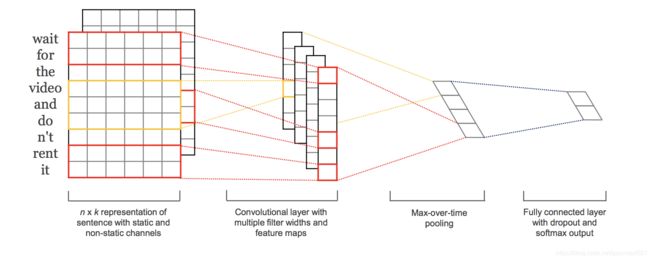
五、 训练词向量
由于本人是做爬虫工作,训练数据收集可谓是近水楼台先得月。收集了新闻标题(正样本)5834363例,非新闻标题(负样本)5108778。
为了训练词向量,将正负样本中的每个标题通过jieba进行了分词,并去掉了停用词。同时将所有的词用空格分隔,同时,为了在滑窗过程中,不同标题之间的数据产生关联,
在不同标题的分词结果之间插入了6个UNK标识,因为本人选择的窗口大小是3,所以6个UNK标识刚好了隔离不同标题的分词结果。如下图所示。
![]()
如图,“获刑” 和 “黑白” 属于不同标题的首尾词,因为UNK标识,在训练过程中不会因为大小为3的滑窗而组成训练样本,不会干扰最终的训练结果。word2vec的内部实现好像并没有提及这样的处理细节。
但个人认为这么做是有必要的,不然会将不同标题的首部和尾部的词进行关联,而这些词本身可能并无关联。
这里选择了开源的gensim来实现词向量的训练,这里不做详述,参考使用Gensim模块训练词向量。
下面直接把训练的代码贴一下。
import sys
import os
import random
import json
import logging
import gensim
from gensim.models import Word2Vec
from gensim import models
from gensim.models.word2vec import PathLineSentences
def train(path):
# 日志信息输出
program = os.path.basename(sys.argv[0])
logger = logging.getLogger(program)
logging.basicConfig(format='%(asctime)s: %(levelname)s: %(message)s')
logging.root.setLevel(level=logging.INFO)
logger.info("running %s" % ' '.join(sys.argv))
# training
model = Word2Vec(PathLineSentences("../data/tokens.txt"), size=256, window=3, sg=1, min_count=1, iter=20)
# save model
model.save(path + "text_embed.model")
model.wv.save_word2vec_format(path + "binary_embed.model", binary=True)
def main():
path = "../model/"
train(path)
if __name__ == '__main__':
main()训练方法中,传递一个保存训练模型的路径,开启日志输出。关键的一行是 Word2Vec(PathLineSentences("../data/tokens.txt"), size=256, window=3, sg=1, min_count=1, iter=20),
意思是将../data/tokens.txt作为训练数据,词嵌入维度是256,滑动窗口大小为3,采用skip-model(sg=0表示使用CROW-model),所有词都不会忽略,迭代20次。
训练完成后将模型以二进制的形式保存在path下。训练1000万条标题切词后的数据(tokens.txt),耗时大约5个小时,这是在CPU上监测的结果。
六、训练TextCNN
有了word2vec的训练结果,训练TextCNN可以说是水到渠成,但是还是少不了一些处理步骤。
# usr/bin/env python
# -*- coding: UTF-8 -*-
import sys
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
import random
import json
import logging
import numpy as np
import tensorflow as tf
from time import sleep
import gensim
from gensim.models import Word2Vec
from gensim import models
from keras.preprocessing.text import Tokenizer
from keras.preprocessing.sequence import pad_sequences
from keras.utils.vis_utils import plot_model
from keras.models import Model
from keras.layers import Input
from keras.layers import Dense
from keras.layers import Flatten
from keras.layers import Dropout
from keras.layers import Embedding
from keras.layers.convolutional import Conv1D
from keras.layers.convolutional import MaxPooling1D
from keras.layers.convolutional import AveragePooling1D
from keras.layers.merge import concatenate
from keras.callbacks import TensorBoard
from keras.models import load_model
from keras import optimizers
from keras import regularizers
from keras import backend as K
logger = logging.getLogger()
logger.setLevel(logging.INFO)
'''
将训练数据中的单词列表转换为对应在词典中的索引列表
如:石油将被编码为100, 表示石油在词典中的索引是100, 未发现的词索引标记为0
length: 最大的标题长度, 默认为16, 长度不足16尾部添0
'''
def encode_data(train_data, word_index_map, length=16):
encode_data = []
for item in train_data:
encode_item = []
for token in item:
index = word_index_map.get(token, 0)
encode_item.append(index)
ln = len(encode_item)
if ln < length:
diff = length - ln
encode_item.extend([0] * diff)
encode_data.append(encode_item[0 : length])
return encode_data
''' this class provide word embedding, word_index and word_vector '''
class WordEmbed(object):
def __init__(self):
self.word_index = {" " : 0}
self.word_vector = {}
self.word_embedding = None
self.vocab_size = 0
self.embed_size = 0
def prepare(self):
# 加载word2vec模型
mpath = "../model/binary_embed.model"
model = models.KeyedVectors.load_word2vec_format(mpath, binary=True)
self.embed_size = model.vector_size
# 构造包含所有词的词典
token_list = [word for word, vocab in model.wv.vocab.items()]
print("token list size: %d" % len(token_list))
self.vocab_size = len(token_list)
self.word_embedding = np.zeros((len(token_list) + 1, model.vector_size))
# build word embedding matrix
for i in range(len(token_list)):
word = token_list[i]
#
self.word_index[word] = i + 1
#
self.word_vector[word] = model.wv[word]
# row num is length of token_list
# colnmn num is model.vector_size
self.word_embedding[i + 1] = model.wv[word]
# output embedding shape
print("Word embedding shape: %s" % str(self.word_embedding.shape))
def get_word_embedding(self):
return self.word_embedding
def get_word_index(self):
return self.word_index
def search_word_index(self, word):
return self.word_index.get(word, 0)
def get_word_vector(self):
return self.word_vector
def get_vocab_size(self):
return self.vocab_size
def get_embed_size(self):
return self.embed_size
class TextCNN(object):
def __init__(self):
self.model = None
def prepare(self):
if os.path.exists("../model/textcnn.model"):
self.model = load_model("../model/textcnn.model")
weights = np.array(self.model.get_weights())
for w in weights:
print("layer shape: %s" % str(w.shape))
lst = [0]*16
self.test(lst)
def build_model(self, length, vocab_size, embed_size, embedding):
filter_size = [4, 8, 32]
kernal_size = [1, 2, 4]
drop_ratio = [0.5, 0.5, 0.5]
pooling_size = [4, 2, 2]
hide_layer_size = 50
# channel 1
inputs1 = Input(shape=(length,))
embedding1 = Embedding(vocab_size, embed_size, weights=[embedding], trainable=False)(inputs1)
conv1 = Conv1D(filters=filter_size[0], kernel_size=kernal_size[0], activation='relu')(embedding1)
drop1 = Dropout(drop_ratio[0])(conv1)
pool1 = MaxPooling1D(pool_size=pooling_size[0])(drop1)
flat1 = Flatten()(pool1)
# channel 2
inputs2 = Input(shape=(length,))
embedding2 = Embedding(vocab_size, embed_size, weights=[embedding], trainable=False)(inputs2)
conv2 = Conv1D(filters=filter_size[1], kernel_size=kernal_size[1], activation='relu')(embedding2)
drop2 = Dropout(drop_ratio[1])(conv2)
pool2 = MaxPooling1D(pool_size=pooling_size[1])(drop2)
flat2 = Flatten()(pool2)
# channel 3
inputs3 = Input(shape=(length,))
embedding3 = Embedding(vocab_size, embed_size, weights=[embedding], trainable=False)(inputs3)
conv3 = Conv1D(filters=filter_size[2], kernel_size=kernal_size[2], activation='relu')(embedding3)
drop3 = Dropout(drop_ratio[2])(conv3)
pool3 = MaxPooling1D(pool_size=pooling_size[2])(drop3)
flat3 = Flatten()(pool3)
# merge
merged = concatenate([flat1, flat2, flat3])
dense1 = Dense(hide_layer_size, activation='relu', \
kernel_initializer='he_normal', \
bias_initializer='he_normal', \
kernel_regularizer=regularizers.l2(0.5), \
bias_regularizer=regularizers.l2(0.1))(merged)
outputs = Dense(1, activation='sigmoid',\
kernel_regularizer=regularizers.l2(0.1))(dense1)
self.model = Model(inputs=[inputs1, inputs2, inputs3], outputs=outputs)
# compile
adm_opt = optimizers.Adam(lr=0.001)
self.model.compile(loss='binary_crossentropy', optimizer=adm_opt, metrics=['accuracy'])
# summarize
print(self.model.summary())
plot_model(self.model, show_shapes=True, to_file='multichannel.png')
return self.model
def train(self, x, y, epoch_num, batch_sz, val_data):
#tbCallBack = TensorBoard(log_dir="./log", histogram_freq=1, write_grads=True)
#self.model.fit(x, y, epochs=epoch_num, batch_size=batch_sz,\
# validation_data=val_data, verbose=1, callbacks=[tbCallBack])
self.model.fit(x, y, epochs=epoch_num, batch_size=batch_sz, validation_data=val_data, verbose=1)
def evaluate(self, text_x, test_y):
self.model.fit(test_x, test_y)
# lst is a index array, element corresponse to the word index in vocab dict
# such as [2,4,233,1,23,0,0,0,0,9823,0,0,70,0,0,35]
def test(self, lst, lenght=16):
try:
if not lst:
logging.info("input empty!")
return (False, 0.0)
ln = len(lst)
if ln < lenght:
lst.extend([0] * (lenght - ln))
else:
lst = lst[0 : lenght]
x = np.array(lst).reshape(1,lenght)
if self.model is not None:
prob = float(self.model.predict([x,x,x]))
return (prob > 0.6, prob)
else:
logging.info("No textcnn model loaded!")
return (False, 0.0)
except Exception as e:
raise Exception("textcnn exception: %s, %s" % (str(e), str(x)))
''' 加载分词后的标题token列表 '''
def load_data(file_name):
f = open(file_name, "r", encoding="utf-8", errors='ignore')
n = 0
train_data = []
max_len = 0
try:
line = next(f)
while line:
try:
n += 1
d = json.loads(line.strip())
token_list = d["token_seq"].split(',')
if len(token_list) > max_len:
max_len = len(token_list)
train_data.append(token_list)
line = next(f)
except Exception as e:
print("inner error: %s" % str(e))
line = f.next()
continue
except Exception as e:
print("outer error: %s" % str(e))
finally:
f.close()
print("%d records in %s" % (n, file_name))
print("max len: %d" % max_len)
return train_data
def train(model_name):
# load train data
pos_x = load_data("../data/news_records.txt")
pos_y = [1] * len(pos_x)
neg_x = load_data("../data/other_records.txt")
neg_y = [0] * len(neg_x)
# 加载词嵌入矩阵
word_embed = WordEmbed()
word_embed.prepare()
word_index_map = word_embed.get_word_index()
word_embedding = word_embed.get_word_embedding()
x = []
x.extend(pos_x)
x.extend(neg_x)
x = encode_data(x, word_index_map)
print("encoded data item: %s" % str(x[0]))
y = []
y.extend(pos_y)
y.extend(neg_y)
p = [i for i in range(len(x))]
for i in range(200):
random.shuffle(p)
# split data into train set, validata set and test set, as 0.7 : 0.2 : 0.1
ds = len(p)
train_x = [x[i] for i in p[0 : int(0.7*ds)]]
train_y = [y[i] for i in p[0 : int(0.7*ds)]]
val_x = [x[i] for i in p[int(0.7*ds)+1 : int(0.9*ds)]]
val_y = [y[i] for i in p[int(0.7*ds)+1 : int(0.9*ds)]]
test_x = [x[i] for i in p[int(0.9*ds)+1 : ds]]
test_y = [y[i] for i in p[int(0.9*ds)+1 : ds]]
print("size: %d, %d, %d" % (len(train_x), len(val_x), len(test_x)))
# define model
textcnn = TextCNN()
vocab_size = word_embed.get_vocab_size()
embed_size = word_embed.get_embed_size()
model = textcnn.build_model(16, vocab_size+1, embed_size, word_embedding)
# clear data for save memory
del pos_x[:]
del neg_x[:]
# train model
tx = np.array(train_x)
vx = np.array(val_x)
vy = np.array(val_y)
val_data = ([vx,vx,vx], vy)
textcnn.train([tx, tx, tx], np.array(train_y), epoch_num=5, batch_sz=4096, val_data=val_data)
# save model
model.save('../model/' + model_name)
# load model
model = load_model("../model/" + model_name)
tx = np.array(test_x)
ty = np.array(test_y)
loss, acc = model.evaluate([tx,tx,tx], ty, verbose=0)
print("test loss and acc: %s, %s" % (str(loss), str(acc)))
def test():
embed = WordEmbed()
embed.prepare()
textcnn = TextCNN()
textcnn.prepare()
lst = ["平湖","广厦","爱尚","绿地","房子","怎么样","可以"]
indexs = [embed.search_word_index(w) for w in lst]
print("%.2f, %s" % (textcnn.test(indexs)[1], str(lst)))
lst = ["调整","完善","土地","收入","使用","范围","优先","支持","乡村","振兴"]
indexs = [embed.search_word_index(w) for w in lst]
print("%.2f, %s" % (textcnn.test(indexs)[1], str(lst)))
def main():
train("textcnn.model")
if __name__ == '__main__':
main() 该脚本实现了训练和测试过程,对于train方法,其执行流程如下:
- 加载正负样本原始训练数据;
- 加载词嵌入矩阵,通过WordEmbed类实现了对之前训练好的词嵌入模型的加载;
- 对训练数据中的每个标题,将其映射为长度为16的词索引列表,这将作为TextCNN模型的输入,详见encode_data方法;
- 充分打乱训练数据,并将数据分隔为训练集、验证集和测试集,比例是7 : 2 :1;
- 定义TextCNN模型,模型的定义和训练在TextCNN中进行了封装;
- 训练TextCNN模型;
- 保存训练的模型;
- 加载训练的模型,验证模型的精度;
经过训练,模型的准确率收敛在了94%左右,精确度还是可以接受的。
七、模型效果
在此,给出实际线上数据的一些执行效果,如下图所示。

上图对应的实际页面类型是新闻类型,从输出概率上来看,预测的比较准确。
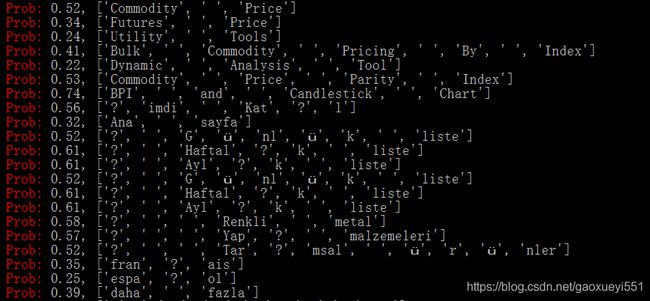
上图对应的是乱码数据,输出概率相对偏低,预测的结果也是符合我们的预期的。

上图对应非新闻页面,预测概率普遍较低,也是符合预期的。