【经验分享】谈谈这两年适配过的 AI 硬件
欢迎关注我的公众号 [极智视界],获取我的更多笔记分享
O_o >_< o_O O_o ~_~ o_O
本文主要聊一聊我这两年来适配过的 AI 硬件。
这两年适配过挺多的 AI 硬件,一直以来总觉得少了篇小结性的文章来记录一下,前段时间看到这篇文章《一文看懂AI项目流程及边缘设备开发》,里面介绍了很多作者适配过的边缘计算设备,包括英伟达 Jetson、华为 atlas、比特大陆 Sophon、寒武纪 MLU 等,看了这篇文章我感慨颇多,回顾自己也是有相似的经历,以致于在文章末进行了这样的评论:

上面说的这篇文章的作者主要做边缘侧设备的部署,我们既有板卡也有边缘侧,场景和硬件形态更加丰富一些。这里记录一下我适配过的硬件,也把自己的一些算法部署经历经验分享一下,希望能对需要的同学有一点点帮助。
先罗列一下都适配过哪些厂商的硬件:英伟达 GPU / Jetson、寒武纪 MLU、曙光 DCU、华为昇腾 atlas / 海思、比特大陆 Sophon、瑞芯微 RK、全志 R329、登临 Goldwasser。下面分别进行介绍一下。
文章目录
-
- 1、英伟达
-
- 1.1 英伟达 GPU
- 1.2 英伟达 Jetson
- 2、寒武纪
-
- 2.1 思元 MLU270
- 2.2 思元 MLU220
- 3、曙光
-
- 3.1 曙光 DCU
- 4、华为
-
- 4.1 昇腾 atlas300I
- 4.2 昇腾 atlas500
- 4.3 海思 Hi35xx
- 5、比特大陆
-
- 5.1 Sophon SE5
- 5.2 Sophon SE3
- 6、瑞芯微
-
- 6.1 RK3399
- 7、全志
-
- 7.1 R329
- 8、登临
-
- 8.1 Goldwasser L
1、英伟达
1.1 英伟达 GPU
英伟达 GPU 肯定是大家接触最多的硬件了,其中 Tesla T4 号称 为推理而生。这里以 T4 为例介绍一下,上图:

给出一些硬件性能参数:

GPU 架构为图灵(现在已经有安培架构了),有 320 个 Tensor Cores,2560 个 CUDA Cores,int8 算力达到 130 T,功耗只有 75 瓦。功耗低,性能强,是推理卡的好选择。对于模型推理来说,在 GPU 设备上一般都会用 TensorRT 去做,TensorRT 是英伟达提供的一套推理框架,在里面可以做 模型量化、算符融合、性能调优等算法优化工作。对于 TensorRT 的部署,有多条路线可以选择,可以直接从 tensorflow / pytorch / onnx 导出 TensorRT 模型,也可以用 TensorRT API 去搭建网络。
在用 TensorRT 的时候一般会涉及到 serialize 和 deserialize,这两个过程的示意如下:

[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-et98dBIG-1633869187420)(https://gitee.com/jeremyjj/imageBed/raw/master/share/经验分享/【经验分享】谈谈这两年适配过的AI硬件/image (1)].png)
TensorRT 的整个推理流程如下:

使用 TensorRT 推理一般都能获得不错的性能,虽然 TensorRT 只能用在英伟达 GPU 上,但由于现在用英伟达的公司实在太多,所以 TensorRT 自然也是香饽饽。
1.2 英伟达 Jetson
T4 是板卡,Jetson 系列是英伟达的边缘计算设备,之前也写过几篇关于 Jetson 的文章 《【模型推理】英伟达 Jetson 系列边缘盒子硬件参数汇总》、《【模型推理】英伟达 Jetson 系列边缘盒子性能测评》。
我拿米文动力的产品手册里的图展示,Jetson 的产品矩阵如下,第一档是 Xavier(AGX Xavier、Xavier NX),第二档是 TX2(TX2、TX2 NX),第三档是 Nano。

由于 Jetson 里装的推理卡还是 GPU,所以基本可以 TensorRT 一套通吃,需要注意的是:(1)不同型号的 Jetson 有不同的 GPU 架构,Nano 不支持 int8 精度,其他都支持,涉及到模型量化精度的选择问题;(2)同样是精度问题,TX2 NX 的 Tegra X2 Pascal 架构是刚开始支持 int8 精度,int8 运算指令还不够完善,所以你在 TX2 / TX2 NX 上 int8 推理不一定就比 fp16 更加快;(3)需要注意的是,Xavier 系列 Jetson 设备上还有专门为深度学习神经网络加速所设计的 DLA,这个也是和 GPU 板卡不一样的地方。
总体来说,在 Jetson 做移植还是很方便,是因为 Jetson 和 通用 GPU 之间的技术栈的通用性比较好。
2、寒武纪
2.1 思元 MLU270
寒武纪是我接触比较早的国产 AI 新硬件,在国内算做的比较早的对标英伟达的厂商,我个人还是比较喜欢它的。寒武纪做推理卡也有相对比较悠久的历史,从最开始中科院的 DianNao、DaDianNao 开始到现在的 思元系列,逐步走向成熟。寒武纪也提供了比较丰富的配套学习资料,如陈云霁老师写的《智能计算系统》就是一本比较系统介绍寒武纪推理卡及软件栈的书籍。我之前也写过几篇寒武纪部署相关的文章,也可以作为学习的参考资料:《【经验分享】ubuntu 安装寒武纪MLU-270 SDK教程》、《【经验分享】寒武纪MLU270源码编译 pytorch-mlu》。
和英伟达一样,寒武纪也有全高全长的训练卡 MLU290、半高半长的 PCIE 推理卡 MLU270、边缘计算设备 MLU220,其中 MLU270 说是对标 P4,我实际拿他对标 T4,功耗为 70 瓦,int8 推理算力为 128 T,上图:

给出一些硬件性能参数:

寒武纪有它自己一套十分完整的软件栈,前端也十分丰富,支持 caffe、tensorflow、pytroch、mxnet,寒武纪也提供了 CNML 机器学习算子库,CNRT 运行时库等帮助模型推理落地,我总结了一下寒武纪的推理流程,如下,这里前端只考虑了 from_pytorch 和 from_darknet,yolo 系列的 darknet 模型需要进行模型转换后才能进寒武纪的推理框架,这里采用了 darknet -> caffe 的转换路线。

从上图你可以知道,寒武纪的模型部署技术栈主要有两条路线:
(1)from_caffe / tensorflow / pytorch / mxnet -> CNRT;
(2)trained_model -> cnml -> CNRT;
其中第一条路线是最方便的,如 CNPytorch 或 CNCaffe 其实都是寒武纪在社区版 Pytorch / Caffe 的基础上融入了结合 MLU 推理卡特性的代码后形成的寒武纪版的深度学习框架。推理过程可以分为离线推理和在线推理,其执行结果是一致的,在线推理方便 debug 定位问题。寒武纪推理卡在设置 batch 的时候也比较有讲究,由于 MLU270 的 cluster 为 4,所以在设置 batch 的时候为 4 的倍数的时候性能为最优。
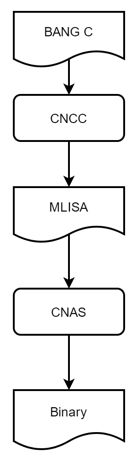
寒武纪还有个特色是 BANG C,这是为 MLU 硬件打造的编程语言,类似英伟达里的 CUDA C,可以充分利用硬件资源和软件编译优化、通过算子新增或替换来提升模型推理性能。下面用一个 L2LossKernel 的 BANG C kernel 的示例来展示一下 BANG C 是怎么写的:
#include "mlu.h"
#define ONELINE 64
__mlu_entry__ void L2LossKernel(half* input, half* output, int32_t len) {
__nram__ int32_t quotient = len / ONELINE;
__nram__ int32_t rem = len % ONELINE;
__nram__ half input_nram[ONELINE];
output[0] = 0;
for (int32_t i = 0; i < quotient; i++) {
__memcpy(input_nram, input + i * ONELINE,
ONELINE * sizeof(half) , GDRAM2NRAM);
__bang_mul(input_nram, input_nram, input_nram, ONELINE);
__bang_mul_const(input_nram, input_nram, 0.5, ONELINE);
for (int32_t j = 0; j < ONELINE; j++) {
output[0] += input_nram[j];
} }
if (rem != 0) {
__memcpy(input_nram, input + quotient * ONELINE,
ONELINE * sizeof(half), GDRAM2NRAM);
__bang_mul(input_nram, input_nram, input_nram, ONELINE);
__bang_mul_const(input_nram, input_nram, 0.5, ONELINE);
for (int i = 0; i < rem; i++) {
output[0] += input_nram[i];
} } }
CNCC 是寒武纪 MLU 用来编译 BANG C 程序的编译器,CNCC 编译器架构如下:
2.2 思元 MLU220
思元 MLU220 是寒武纪的边缘计算设备,功耗为 8.25 瓦,int8 算力为 8 T,这在边缘盒子里算低的,一般用的像 英伟达 Jetson Xavier NX int8 算力有 21T,像华为 atlas500 int8 算力也有 16 T,这么对比看来 思元 220 的算力是比较弱的。上图:

MLU220 可以看成是 MLU270 的袖珍版,MLU220 有 1 个 cluster,4 个核,MLU270 有 4 个 cluster,16 个核。MLU220 通过离线运行模型完成对神经网络或单算子的运算,离线运行模型是将编译原子算子和融合算子后生成的指令,打包保存为离线模型文件,再通过 CNRT 加载离线模型文件来驱动 MLU Core 完成计算。需要在 MLU270 上完成 MLU220 离线模型的模拟调试后,再生成和部署离线模型。由于 MLU270 和 MLU220 硬件结构不同,部分硬件指令参数的设置也会有所不同,导致两个平台上二进制指令无法兼容。因此需要在 MLU270 上完成对 MLU220 离线模型的模拟调试,调试无误后,再生成最终的离线模型,放到 MLU220 上执行。离线运行模型免去了编译过程,减少了运行依赖,也避免了对框架和 CNML 等的依赖。因此,离线运行模型的执行具有更好的性能和通用性。
以 Caffe vgg16 model MLU220 部署为例,需要先在 MLU270 上进行操作:
./build/tools/generate_quantized_pt --ini_file vgg16_quantized.ini
执行下面命令,使用离线模型转换工具转换模型,并生成离线模型 vgg16.cambricon:
./caffe genoff -model vgg16_int8.prototxt -weights vgg16.caffemodel -mcore MLU220 -simple_compile 1 -batchsize 32 -core_number 4 -mname vgg16
其中有几个参数需要注意的,-mcore 需要设置为 MLU220,-core_number 用于指定推理使用的核数,选择核数应小于等于支持的硬件核数,MLU220 最大核数为 4,所以这个参数不能大于 4,然后就可以拿生成的离线模型到 MLU220 上执行推理了。
3、曙光
3.1 曙光 DCU
适配曙光 DCU 是在云平台上做的,云平台融合了 Caffe、TensorFlow 和 PyTorch 等深度学习框架,同时融合了任务调度系统,结合 docker 容器技术,提供深度学习计算服务,集中了数据集管理、镜像管理、容器管理、模型管理、文件管理、任务管理和资源管理,以及训练任务提交、资源状态监控等功能,实现对高性能计算资源的调度分配。
在曙光 DCU 平台上要做模型的推理适配需要先申请计算节点,将外部训练好的权重文件上传至 E-File,在 E-Shell 内申请的计算节点里加载 pytorch / caffe / tensorflow 环境,然后可以使用单卡或分布式 (单节点4卡) 的运行模式来进行模型推理。曙光 DCU 支持原生框架,算法移植十分方便,无需投入更多人力进行再开发,但没有提供专门的推理运行时和摆脱深度学习框架部署的选择,所以对于部署环境依赖过于臃肿,实用性并不强,这里不多说了,我也没有进一步研究。
4、华为
4.1 昇腾 atlas300I
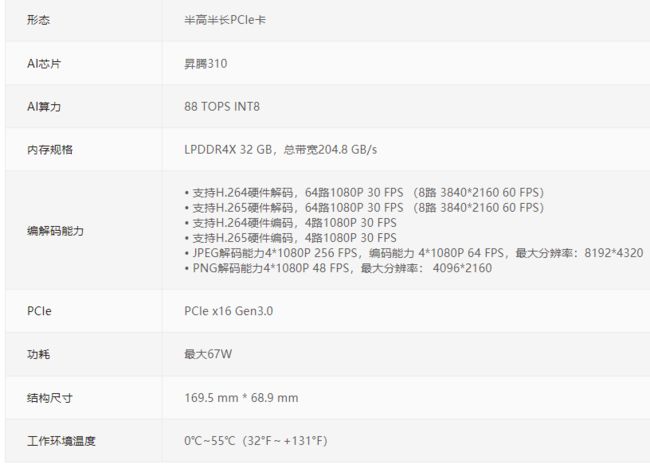
昇腾 atlas300I 是华为昇腾基于 Ascend 310 的半高半长的 PCIE 推理板卡,功耗 67 瓦,单卡 int8 算力 88 T,上图:

给出 atlas300I 的硬件性能参数:
昇腾相关的部署技术我之前写过好几篇文章:《【模型推理】聊一聊昇腾 CANN TBE 算子开发方式》、《【嵌入式AI】atlas500与虚拟机ubuntu交互配置》、《【经验分享】华为atlas500系列aarch64交叉编译opencv》、《【经验分享】华为昇腾 docker 内配置 MindStudio》、《【系统架构】一文看懂昇腾达芬奇架构计算单元》。昇腾提供了一套完整的从训练(MindSpore)、部署(AMCT / ATC )、高性能算子开发(CANN TBE)的软件栈支持,华为的 AI 目前已经号称不需依赖美国技术,这可不是吹牛的。如下给出的 AI 架构图,可以看出它是如此的全面,覆盖 端 / 边 / 云、训练 / 推理、算子开发可扩展。

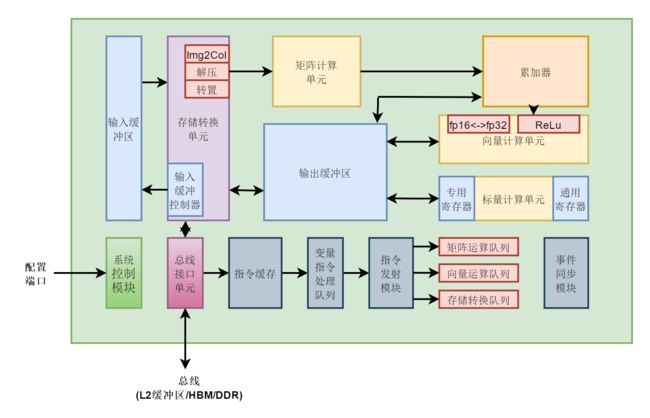
讲昇腾需要先讲达芬奇架构,达芬奇架构是一种特定域架构。 昇腾AI处理器的计算核心主要由 AI Core 构成,包含三种基础计算资源:矩阵计算单元(Cube Unit)、向量计算单元(Vector Unit)和标量计算单元(Scalar Unit),负责执行张量、矢量、标量计算。AI Core 中的矩阵计算单元支持 Int8 和 fp16 的计算,向量计算单元支持 fp16 和 fp32 的计算。AI Core 基本架构如下:
目前昇腾支持的前端框架有 tensorflow、caffe 和 mindspore,以 caffe 为例,如果你的训练框架为 pytorch 或 darknet,在做昇腾的模型部署前需要进行 pytorch / darknet -> caffe 的模型转换,然后如果你需要做量化,昇腾提供了 AMCT 的模型小型化工具。在昇腾的 SDK 中还集成了 TVM 自动调优的性能优化手段,然后可以转离线模型 .om,进行模型推理。整个开发过程可以选择使用 MindStudio,也可以使用命令行进行,使用 MindStudio 会更加方便,缺点是一般一个服务器只能开一个 MindStudio 界面,在我的这篇文章中《【经验分享】华为昇腾 docker 内配置 MindStudio》解决了多人同时使用 MindStudio 开发的问题。
TBE(Tensor Boost Engine)算子开发在昇腾适配中是一个比较核心和有难度的模块,看一下 TBE 所在的位置:

一个完整的 TBE 算子包含四部分:算子原型定义、对应开源框架的算子适配插件、算子信息库定义和算子实现。

TBE 的算子开发方式主要有两种:DSL 和 TIK。DSL 借鉴了 TVM 中的 TOPI 机制,预先提供一些常用运算的调度,封装成一个个运算接口,开发时只需要生命计算的流程再使用调度机制,生成指定目标代码即可。而 TIK 一种基于 Python 语言的动态编程框架,程序员直接使用 TIK 提供的 API 完成计算过程及 Schedule 过程,需要手工控制数据搬运的参数和 Schedule,不过无需关注 Buffer 地址的分配及数据同步处理,由 TIK 工具进行管理。
下面展示一个 add 的 DSL 实现例子:
from te import tvm
from te.platensorfloworm.fusion_manager
import fusion_manager
import te.lang.cce as tbe
from te.utils import para_check
from te.utils import shape_util
from functools import reduce
SHAPE_SIZE_LIMIT = 2147483648
# 实现 Add 算子的计算逻辑
@fusion_manager.register("add")
def add_compute(input_x, input_y, output_z, kernel_name="add"):
shape_x = shape_util.shape_to_list(input_x.shape) # 将 shape 转换为 list
shape_y = shape_util.shape_to_list(input_y.shape) # 将 shape 转换为 list
shape_x, shape_y, shape_max = shape_util.broadcast_shapes(shape_x, shape_y,param_name_input1="input_x",param_name_input="input_y")
shape_size = reduce(lambda x, y: x * y, shape_max[:])
if shape_size > SHAPE_SIZE_LIMIT:
raise RuntimeError("the shape is too large to calculate")
input_x = tbe.broadcast(input_x, shape_max) # 将 input_x 的 shape 广播为 shape_max
input_y = tbe.broadcast(input_y, shape_max) # 将 input_y 的 shape 广播为 shape_max
res = tbe.vadd(input_x, input_y) # 执行 input_x + input_y
return res # 返回计算结果的 tensor
# 算子定义函数
def add(input_x, input_y, output_z, kernel_name="add"):
# 获取算子输入 tensor 的 shape 与 dtype
shape_x = input_x.get("shape")
shape_y = input_y.get("shape")
check_tuple = ("float16", "float32", "int32")
input_data_type = input_x.get("dtype").lower()
if input_data_type not in check_tuple:
raise RuntimeError("only support %s while dtype is %s" % (",".join(check_tuple), input_data_type))
# shape_max 取 shape_x 与 shape_y 的每个维度的最大值
shape_x, shape_y, shape_max = shape_util.broadcast_shapes(shape_x, shape_y,param_name_input1="input_x",param_name_input="input_y")
if shape_x[-1] == 1 and shape_y[-1] == 1 and shape_max[-1] == 1:
# 如果 shape 的长度等于 1,就直接赋值,如果 shape 的长度不等于 1,做切片,将最后一个维度舍弃(按照内存 排布,最后一个维度为 1 与没有最后一个维度的数据排布相同,例如 2*3=2*3*1,将最后一个为 1 的维度舍弃可提升 后续的调度效率)。
shape_x = shape_x if len(shape_x) == 1 else shape_x[:-1]
shape_y = shape_y if len(shape_y) == 1 else shape_y[:-1]
shape_max = shape_max if len(shape_max) == 1 else shape_max[:-1]
# 使用 TVM 的 placeholder 接口对第一个输入 tensor 进行占位,返回一个 tensor 对象
data_x = tvm.placeholder(shape_x, name="data_1", dtype=input_data_type)
# 使用 TVM 的 placeholder 接口对第二个输入 tensor 进行占位,返回一个 tensor 对象
data_y = tvm.placeholder(shape_y, name="data_2", dtype=input_data_type)
# 调用 compute 实现函数
res = add_compute(data_x, data_y, output_z, kernel_name)
# 自动调度
with tvm.target.cce():
schedule = tbe.auto_schedule(res)
# 编译配置
config = {
"name": kernel_name, "tensor_list": (data_x, data_y, res)}
tbe.build(schedule, config)
再展示一个 TIK 的开发示例,如下实现算子用于实现从 Global Memory 中的 A、B 两处分别读取 128 个 float16 类型的数值搬运到 unified buffer 中相加,并将结果从 unified buffer 写入 Global Memory 地址 C 中。
from te import tik
def simple_add():
tik_instance = tik.Tik()
# 指定 Tensor 对象的所在 buffer 空间。scope_gm 表示 Global Memory 中的数据;
# scope_ubuf 表示 unified buffer 中的数据
data_A = tik_instance_Tensor("float16", (128,), name="data_A", scope=tik.scope_gm)
data_B = tik_instance_Tensor("float16", (128,), name="data_B", scope=tik.scope_gm)
data_C = tik_instance_Tensor("float16", (128,), name="data_C", scope=tik.scope_gm)
data_A_ub = tik_instance_Tensor("float16", (128,), name="data_A_ub", scope=tik.scope_ubuf)
data_B_ub = tik_instance_Tensor("float16", (128,), name="data_B_ub", scope=tik.scope_ubuf)
data_C_ub = tik_instance_Tensor("float16", (128,), name="data_C_ub", scope=tik.scope_ubuf)
# 数据搬运 假设要搬运的数据为 128 个 float16 类型的数据,占 128*2Byte,而一个 unifield buffer 为 256kb,每次
# 搬运大小为 128*2/32Byte。
tik_instance.data_move(data_A_ub, data_A, 0, 1, 128 //16, 0, 0)
tik_instance.data_move(data_B_ub, data_B, 0, 1, 128 //16, 0, 0)
tik_instance.vec_add(128, data_C_ub[0], data_A_ub[0], data_B_ub[0], 1, 8, 8, 8)
tik_instance.data_move(data_C, data_C_ub, 0, 1, 128 //16, 0, 0)
tik_instance.BuildCCE(kernel_name="simple_add",inputs=[data_A,data_B],outputs=[data_C])
4.2 昇腾 atlas500
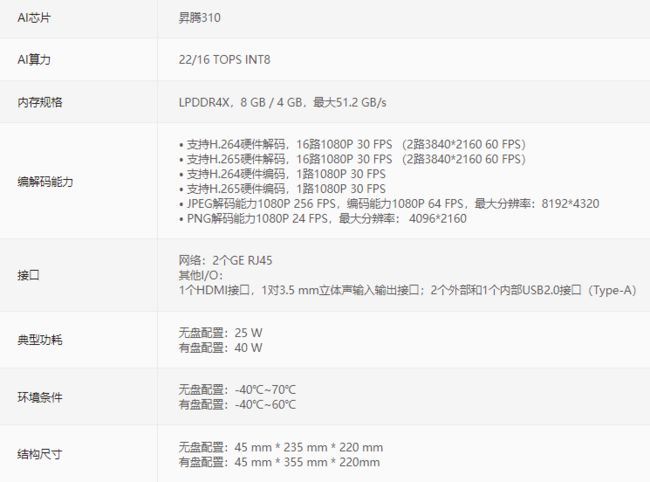
昇腾 altas500 智能小站,是昇腾的边缘计算设备,算力有 int8 22 T 和 16 T 可供选择。

给出 altas500 的硬件性能参数:
昇腾 atlas500 的主控是 不带 NNIE 的海思Hi3559A,NPU 是 昇腾310。昇腾 atlas500 的操作系统采用了欧拉系统,在进行 atlas500 开发的时候一般先在 WebUI 端进行 ip 的配置,然后可以使用 nfs 挂载来交互开发,配置过程可以参考《【嵌入式AI】atlas500与虚拟机ubuntu交互配置》。
atlas500 的模型适配和 atlas300 的流程类似,区别是 atlas500 是 arm 架构,atlas300I 是 x86 架构(当然也有 arm 架构),所以编译工具链可能不太一样,如果你要用 arm 版的 opencv,需要进行交叉编译,可以参考这篇文章《【经验分享】华为atlas500系列aarch64交叉编译opencv》。如果你先做了 atlas300I 的开发,那么 atlas500 的开发其实没啥难度。
4.3 海思 Hi35xx
曾几何时,海思 Hi35xx 系列是端场景的首选,现在因为供货问题,其他一些替代产品如 Rockchip 等开始崛起,但海思系列还是擎天柱般的存在,如 Hi3559A 就能提供 4T 算力,这十分的可观。来看下 Hi3559A 的开发板:

一般实际项目开发的时候会采用带摄像头模块的海思模组,长的像这样:

海思的 SDK 是一个庞大的工程,包括图像采集、视频编解码、模型推理等功能模块。对于海思 NNIE 上的模型推理,一般流程是先在 windows 上采用 RuyiStudio 进行模型量化、仿真推理、精度验证、离线模型转换等操作,然后把精度验证没有问题的 .wk 离线模型通过 nfs 放到 Hi35xx 上执行,如下是 RuyiStudio 进行模型转换操作的一些示例。
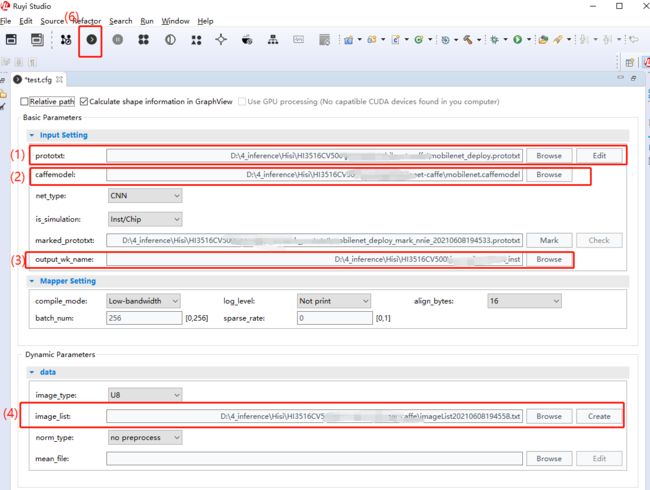
RuyiStudio提供了 Vector Comparision 工具,能够对比输出向量的相似度、绝对误差等信息,可用于验证模型量化后的输出精度误差大小。

同时海思提供了一个中间层输出脚本,该工具可以通过读取cfg文件输出中间层结果。
python CNN_convert_bin_and_print_featuremap.py -i MobileFace.cfg -m mobilefacenet.prototxt -w mobilefacenet.caffemodel -c 0
运行结束后会在data文件夹下生成一个output文件夹,其中存储了中间层输出结果,将其加载到 RuyiStudio 进行 Vector Comparision 精度校验,如下:

通过仿真验证后,生成 xxx.wk 模型文件,将其放到板子上 SVP NNIE 上执行,以 mobilefacenet 为例,NNIE 推理的代码示例如下:
void SAMPLE_SVP_NNIE_Cnn(void)
{
HI_CHAR *pcSrcFile = "./data/nnie_image/rgb_planar/10.bgr";
HI_CHAR *pcModelName = "./data/nnie_model/face/mobilefacenet_inst.wk";
HI_U32 u32PicNum = 1;
HI_S32 s32Ret = HI_SUCCESS;
SAMPLE_SVP_NNIE_CFG_S stNnieCfg = {0};
SAMPLE_SVP_NNIE_INPUT_DATA_INDEX_S stInputDataIdx = {0};
SAMPLE_SVP_NNIE_PROCESS_SEG_INDEX_S stProcSegIdx = {0};
/*Set configuration parameter*/
stNnieCfg.pszPic= pcSrcFile;
stNnieCfg.u32MaxInputNum = u32PicNum; //max input image num in each batch
stNnieCfg.u32MaxRoiNum = 0;
stNnieCfg.aenNnieCoreId[0] = SVP_NNIE_ID_0;//set NNIE core
s_stCnnSoftwareParam.u32TopN = 5;
/*Sys init*/
SAMPLE_COMM_SVP_CheckSysInit();
/*CNN Load model*/
SAMPLE_SVP_TRACE_INFO("Cnn Load model!\n");
s32Ret = SAMPLE_COMM_SVP_NNIE_LoadModel(pcModelName,&s_stCnnModel);
SAMPLE_SVP_CHECK_EXPR_GOTO(HI_SUCCESS != s32Ret,CNN_FAIL_0,SAMPLE_SVP_ERR_LEVEL_ERROR,
"Error,SAMPLE_COMM_SVP_NNIE_LoadModel failed!\n");
/*CNN parameter initialization*/
SAMPLE_SVP_TRACE_INFO("Cnn parameter initialization!\n");
s_stCnnNnieParam.pstModel = &s_stCnnModel.stModel;
s32Ret = SAMPLE_SVP_NNIE_Cnn_ParamInit(&stNnieCfg,&s_stCnnNnieParam,&s_stCnnSoftwareParam);
SAMPLE_SVP_CHECK_EXPR_GOTO(HI_SUCCESS != s32Ret,CNN_FAIL_0,SAMPLE_SVP_ERR_LEVEL_ERROR,
"Error,SAMPLE_SVP_NNIE_Cnn_ParamInit failed!\n");
/*record tskBuf*/
s32Ret = HI_MPI_SVP_NNIE_AddTskBuf(&(s_stCnnNnieParam.astensorfloworwardCtrl[0].stTskBuf));
SAMPLE_SVP_CHECK_EXPR_GOTO(HI_SUCCESS != s32Ret,CNN_FAIL_0,SAMPLE_SVP_ERR_LEVEL_ERROR,
"Error,HI_MPI_SVP_NNIE_AddTskBuf failed!\n");
/*Fill src data*/
SAMPLE_SVP_TRACE_INFO("Cnn start!\n");
stInputDataIdx.u32SegIdx = 0;
stInputDataIdx.u32NodeIdx = 0;
s32Ret = SAMPLE_SVP_NNIE_FillSrcData(&stNnieCfg,&s_stCnnNnieParam,&stInputDataIdx);
SAMPLE_SVP_CHECK_EXPR_GOTO(HI_SUCCESS != s32Ret,CNN_FAIL_1,SAMPLE_SVP_ERR_LEVEL_ERROR,
"Error,SAMPLE_SVP_NNIE_FillSrcData failed!\n");
/*NNIE process(process the 0-th segment)*/
stProcSegIdx.u32SegIdx = 0;
s32Ret = SAMPLE_SVP_NNIE_Forward(&s_stCnnNnieParam,&stInputDataIdx,&stProcSegIdx,HI_TRUE);
SAMPLE_SVP_CHECK_EXPR_GOTO(HI_SUCCESS != s32Ret,CNN_FAIL_1,SAMPLE_SVP_ERR_LEVEL_ERROR,
"Error,SAMPLE_SVP_NNIE_Forward failed!\n");
/*Software process*/
s32Ret = SAMPLE_SVP_NNIE_Cnn_GetTopN(&s_stCnnNnieParam,&s_stCnnSoftwareParam);
SAMPLE_SVP_CHECK_EXPR_GOTO(HI_SUCCESS != s32Ret,CNN_FAIL_1,SAMPLE_SVP_ERR_LEVEL_ERROR,
"Error,SAMPLE_SVP_NNIE_CnnGetTopN failed!\n");
/*Print result*/
SAMPLE_SVP_TRACE_INFO("Cnn result:\n");
s32Ret = SAMPLE_SVP_NNIE_Cnn_PrintResult(&(s_stCnnSoftwareParam.stGetTopN),
s_stCnnSoftwareParam.u32TopN);
SAMPLE_SVP_CHECK_EXPR_GOTO(HI_SUCCESS != s32Ret,CNN_FAIL_1,SAMPLE_SVP_ERR_LEVEL_ERROR,
"Error,SAMPLE_SVP_NNIE_Cnn_PrintResult failed!\n");
s32Ret = SAMPLE_SVP_NNIE_PrintReportResult(&s_stCnnNnieParam);
SAMPLE_SVP_CHECK_EXPR_GOTO(HI_SUCCESS != s32Ret, CNN_FAIL_1, SAMPLE_SVP_ERR_LEVEL_ERROR,"Error,SAMPLE_SVP_NNIE_PrintReportResult failed!");
CNN_FAIL_1:
/*Remove TskBuf*/
s32Ret = HI_MPI_SVP_NNIE_RemoveTskBuf(&(s_stCnnNnieParam.astensorfloworwardCtrl[0].stTskBuf));
SAMPLE_SVP_CHECK_EXPR_GOTO(HI_SUCCESS != s32Ret,CNN_FAIL_0,SAMPLE_SVP_ERR_LEVEL_ERROR,
"Error,HI_MPI_SVP_NNIE_RemoveTskBuf failed!\n");
CNN_FAIL_0:
SAMPLE_SVP_NNIE_Cnn_Deinit(&s_stCnnNnieParam,&s_stCnnSoftwareParam,&s_stCnnModel);
SAMPLE_COMM_SVP_CheckSysExit();
}
5、比特大陆
5.1 Sophon SE5
Sophon SE5 是比特大陆的边缘计算盒子,搭载比特大陆自研的第三代 TPU 芯片 BM1684,int8 算力为 17.6 T,需要说一下 SE5 仅支持 int8 和 fp32 精度,不支持 fp16 精度。

BMNNSDK (Bitmain Neural Network SDK) 是比特大陆基于其自主研发的 AI 芯片所定制的深度学习 SDK,涵盖了神经网络推理阶段所需的模型优化、高效运行时支持等能力,为深度学习应用开发和部署提供易用、高效的全栈式解决方案。BMNNSDK 由 Compiler,Library 和 Examples 部分组成。Compiler 负责对各种深度神经网络模型(如 caffemodel、tensorflow model 等)进行离线编译和优化,最终生成运行时需要的 bmodel;Library 提供了 video、bmcv、runtime 等库,供用户进行深度学习应用开发;Examples 提供了 SoC 和 x86 环境的多个例子,供开发参考。

BMNNSDK 的文件结构如下:
BMNNSDK2
├── bin // 相关工具
│ ├── arm
│ └── x86
├── bmlang
├── bmnet // Compiler工具
│ ├── bmnetc // Caffe Compiler
│ ├── bmnetm // MXNet Compiler
│ ├── bmnetp // Pytorch Compiler
│ └── bmnett // Tensor Flow Compiler
│ ├── bmnetu // int8 compiler
│ ├── bmusercpu
│ └── calibration //量化工具
├── documents
├── driver // PCIE卡设备驱动
├── examples // 示例代码
├── include // 运行库头文件,供二次开发使用
├── lib // 运行库,供运行时和二次开发使用,还加入了一些常用第三方库
├── res
├── run_docker_bmnnsdk.sh // Docker启动脚本
比特大陆的模型量化和转换过程比较复杂一些,需要进行 fronted model -> fp32 model -> fp32 umodel -> int8 umodel -> int8 bmodel,其中 umodel 主要是用于验证精度,bmodel 就是可以在 BM1684 上可以执行的离线模型,整个转换和精度验证过程是在交叉编译环境中进行的,最终执行在 SE5 上。

基于 AI 训练框架的模型首先需要借助量化工具转换成 fp32umodel,基于 fp32umodel 后续量化流程已经跟开源框架解耦,作为通用流程执行 int8 量化校准。 比特大陆量化平台框架参考 caffe 框架,因此天然支持 caffemodel,在 caffemodel 时无需借助量化工具进行 fp32umodel 的转换,可直接作为 int8 校准的输入。但 tensorflow、pytorch、mxnet、darknet 出来的模型必须先通过量化工具转换为 fp32umodel,在进行进一步的量化。 Qantization-Tools 是比特大陆 SDK 中提供的模型量化工具,可接主流框架(caffe、mxnet、tensorflow、pytorch、darknet)出的 fp32 model,生成 int8 model。Quantization-Tools 工具架构如下:

BMNet Compiler 是一个模型转换工具,可以对各种框架的模型进行离线转换,将模型转换成 TPU 能够执行的模型格式,然后调用 bmrutime 在初始化阶段读取模型,运行时则将输入数据拷给 TPU,TPU 进行神经网络推理,再将输出读取出来,整个流程是这样的:
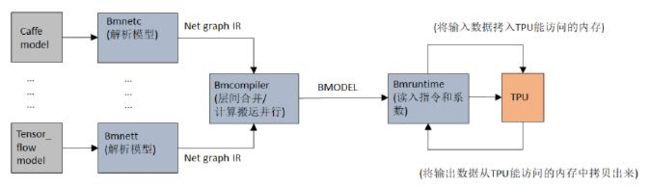
SE5 上的模型加载和推理流程主要分三个部分:(1)加载模型;(2)预处理;(3)推理。之前写过一篇文章《【模型推理】比特大陆 SE5 边缘盒子 caffe SSD 量化与转换部署模型》介绍了 SE5 上 caffe SSD 量化与转换部署模型的方法,下面用一些代码示例对模型推理进行说明一下。
## 1. 加载模型
import sophon.sail as sail
engine = sail.Engine(0)
engine.load(bmodel_path)
## 2. 预处理
class PreProcessor:
def __init__(self, bmcv, scale):
self.bmcv = bmcv
self.ab = [x * scale for x in [1, -123, 1, -117, 1, -104]]
def process(self, input, output):
tmp = self.bmcv.vpp_resize(input, 300, 300)
self.bmcv.convert_to(tmp, output, ((self.ab[0], self.ab[1]), (self.ab[2], self.ab[3]), (self.ab[4], self.ab[5])))
bmcv = sail.Bmcv(handle) # 图形处理加速模块
scale = engine.get_input_scale(graph_name, input_name)
pre_processor = PreProcessor(bmcv, scale) # 预处理初始化
img0 = decoder.read(handle) # 解码视频输出image
img1 = bmcv.tensor_to_bm_image(input) # 将推理的输入地址挂载到image
pre_processor.process(img0, img1) # 预处理
## 3. 推理
graph_name = engine.get_graph_names()[0]
engine.set_io_mode(graph_name, sail.IOMode.SYSO)
input_name = engine.get_input_names(graph_name)[0]
output_name = engine.get_output_names(graph_name)[0]
input_shape = [1, 3, 300, 300]
output_shape = [1, 1, 200, 7]
handle = engine.get_handle()
input_dtype = engine.get_input_dtype(graph_name, input_name)
output_dtype = engine.get_output_dtype(graph_name, output_name)
input = sail.Tensor(handle, input_shape, input_dtype, False, True)
output = sail.Tensor(handle, output_shape, output_dtype, True, True)
input_tensors = {
input_name: input }
output_tensors = {
output_name: output }
...
# 此处省略 解码,预处理 代码
...
engine.process(graph_name, input_tensors, output_tensors) # 推理
out = output.asnumpy()
dets = post_processor.process(out, img0.width(), img0.height()) # 后处理
...
5.2 Sophon SE3
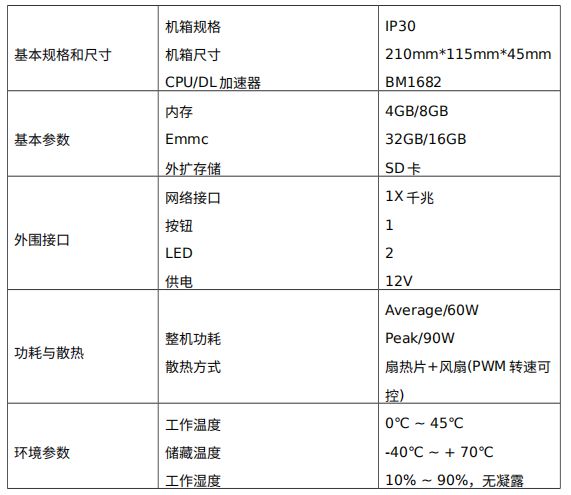
Sophon SE3 是比特大陆算力更低场景的边缘计算设备,搭载的芯片为比特大陆第二代人工智能芯片 BM1682,相比 SE5 的 BM1684 要落后一些,如图,比较精致,不得不说 SE3 的散热做的很好。

SE3 不支持 int8 精度 和 fp16 精度,仅支持 fp32 精度,所以在做模型部署的时候只需要部署 fp32 模型就可以了,可以抛却模型量化的过程。给出 SE3 的硬件性能参数:
同样有了 SE5 的开发经验后,SE3 的开发也不会是啥大问题,这里不多说了。
6、瑞芯微
6.1 RK3399
OpenAILab 的 EAIDK610 搭载了 RockChip 的 RK3399,我在用的是 EAIDK610 的开发者套件,上图:

来看看硬件接口:

RK3399 是瑞芯微推出的一款低功耗、高性能的应用处理器芯片,该芯片基于 Big.Little 架构,具有独立的 NEON 协同处理器的双核Cortex-A72 及四核 Cortex-A53 组合架构,主要应用于计算机、个人互联网移动设备、VR、广告机等智能终端设备。在 RK3399 上部署模型可以考虑 OpenAILab 的 Tengine,正好 EAIDK610 也是 OpenAILab 的产品。
Tengine 于 2017 年在 GitHub 开源,一方面可以通过异构计算技术同时调用 CPU、GPU、DSP、NPU 等不同计算单元来完成 AI 网络推理计算,另一方面,它支持 TensorFlow、Caffe、MXNet 、PyTorch、 MegEngine、 DarkNet、ONNX、 ncnn 等业内主流框架,最友好的是内置了很多的 samples,上手十分方便。Tengine 的架构如下:

7、全志
7.1 R329
全志 R329 搭载的 NPU 是 ARM 周易 AIPU,整个 R329 十分小巧精致,上图:

给出 R329 的硬件参数:

之前写过的几篇关于 R329 的文章可以参考:《【嵌入式AI】全志 R329 开箱与开发环境搭建》、《【嵌入式AI】全志 R329 Tina 系统镜像编译》、《【嵌入式AI】周易 AIPU 算法部署仿真测试》、《【嵌入式AI】全志 R329 板子跑 mobilenetv2》。
在 R329 这种嵌入式设备上同样需要交叉编译模型,然后把模型放到板子上进行执行。以 tensorflow pb 模型部署为例,需要首先对 pb 模型做 export graph 和 freeze graph 的操作得到 frozen pb model,然后需要准备好量化校准数据集,在这种端场景设备上必须是要做量化的。然后配置 NN Compiler 文件,以 mobilenet 为例:
## mobilenet_build.cfg
[Common]
mode=build
[Parser]
model_name = mobilenet
detection_postprocess =
model_domain = image_classification
output = mobilenet/predictions/Reshape
input_model = ./tmp/mobilenet_frozen.pb
input = input
input_shape = [1,224,224,3]
[AutoQuantizationTool]
model_name = mobilenet
quantize_method = SYMMETRIC
ops_per_channel = DepthwiseConv
calibration_data = ./dataset/dataset.npy
calibration_label = ./dataset/label.npy
preprocess_mode = normalize
quant_precision=int8
reverse_rgb = False
label_id_offset = 0
[GBuilder]
outputs=./aipu.bin
profile= True
target=Z1_0701
然后执行:
aipubuild mobilenet_build.cfg
就能生成 R329 能认识执行的 aipu.bin 模型结构文件了,然后交叉编译出 R329 上推理执行程序,在板子上执行类似下面命令配置环境执行推理:
cd /root/maix_sense
insmod aipu.ko
## 让我们跑起来吧
./zhouyi_demo ./aipu.bin 1
效果图如下,mobilenet 差不多能跑到 20 帧,接近实时。

8、登临
8.1 Goldwasser L
Goldwasser L 是登临半高半长的推理卡,对标 T4 ,标出的性能十分强悍,号称要做中国的英伟达。上图:

登临也有覆盖端(Goldwasser UL)、边(Goldwasser L)、云(Goldwasser XL)全场景的推理卡,给出这些卡的性能参数:

对标 T4 的 Goldwasser L 40 瓦的卡就能达到 int 128 T 的算力,而 T4 130 T 算力的功耗是 75 瓦,从数据来看能效比吊打 T4,而 70 瓦 的 Goldwasser L 性能更加的夸张。登临的卡还有个优势是显存,提供了 16G、32G、64G 可选的配置,对比 T4 的 16G,同样具有巨大的优势。
登临的前端目前支持 tensorflow、onnx、caffe,所以如果你们用 pytorch 做训练的话,一般可以选择 torch.onnx.export 导出为 onnx 模型,然后再进登临推理框架;如果你是用 darknet 训练的 yolo 系列,一般也可以做 darknet -> onnx 的模型转换,再接着做推理。登临的推理框架有几个特色的地方:(1)前端集成了 TVM Relay;(2)调优借鉴了 TVM 图优化;(3)登临的推理库 dlnne 接口对标 NVIDIA TensorRT;(4)自定义算子通过 Plugin CUDA C 来写。把这些特色结合起来看,其实蛮有意思,登临最大程度的期望广大的用习惯了 TensorRT 的开发者能够快速的切换到登临的开发世界中。把 TVM 融入自家的推理框架不是登临的首创,华为昇腾也是基于 TVM 的。不过这个由于刚出来没多久,坑还是挺多的,后续可以再分享一些其适配的笔记。
以上我花了两天时间整理、记录了一下我这两年适配过的 AI 硬件。做个记录,也希望给有需要的同学一点点帮助,我也在学习中。
【公众号传送】
《【经验分享】谈谈这两年适配过的 AI 硬件》
扫描下方二维码即可关注我的微信公众号【极智视界】,获取更多AI经验分享,让我们用极致+极客的心态来迎接AI !
