Hadoop 3.0 zookeeper spark hive hbase scala搭建 集群搭建
Hadoop 3.0 集群搭建
目录
Hadoop 3.0 集群搭建
一、hadoop搭建
二、zookeeper搭建
三、hbase搭建
四、Spark安装
五、安装hive
六、搭建scala
一、hadoop搭建
- 机器信息
| 机器 |
Ip |
| Centos7 one |
192.168.1.25 |
| Centos7 two |
192.168.1.32 |
| Centos7 three |
192.168.1.193 |
- 改变hostname
| 机器 |
Ip |
Hostname |
| Centos7 one |
192.168.1.25 |
master |
| Centos7 two |
192.168.1.32 |
node1 |
| Centos7 three |
192.168.1.193 |
node2 |
- 查看hostname : hostname
- 修改hostname : hostnamectl set-hostname master
- 重启:reboot
- 改变hosts
在每一个机器中执行 vim /etc/hosts 加入
192.168.1.25 master
192.168.1.32 node1
192.168.1.193 node1
下面截图有点不对

- 先关闭防火墙
- 查看防火墙信息:systemctl status firewalld
- 关闭防火墙: systemctl stop firewalld
- 关闭开机自启:systemctl disable firewalld
- 配置SSH免密登录
1.将三台机器先执行以下命令 生成ssh秘钥:ssh-keygen –t rsa,一直回车
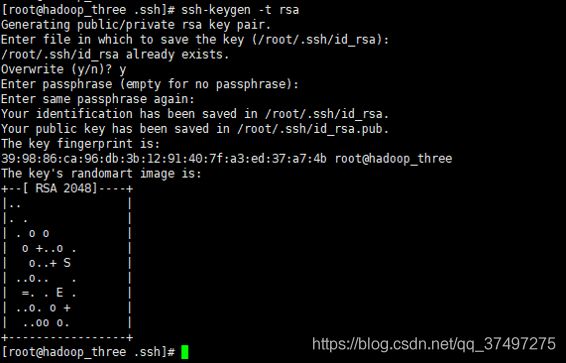
2.把公钥文件放入授权文件中
执行: cd .ssh/
在执行: cat id_rsa.pub >> authorized_keys
注:
authorized_keys:存放远程免密登录的公钥,主要通过这个文件记录多台机器的公钥
id_rsa : 生成的私钥文件
id_rsa.pub : 生成的公钥文件
know_hosts : 已知的主机公钥清单
3.通过scp将内容写到对方的文件中
scp -p ~/.ssh/id_rsa.pub root@node1:/root/.ssh/authorized_keys
4.验证是否成功
ssh root@node1 如果进去说明正确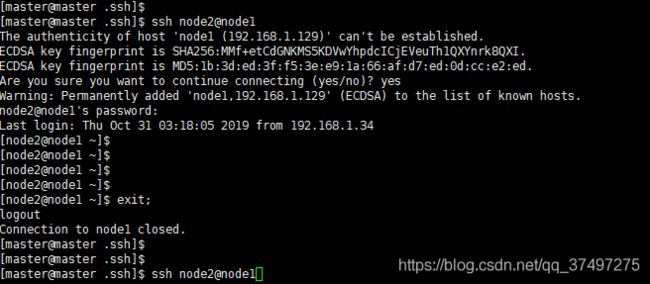
- 配置jdk(全部要配置)
1.上传解压jdk
2.配置jdk
export JAVA_HOME=/usr/local/java/jdk1.8.0_201
export PATH=$JAVA_HOME/bin:$PATH
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
3.source /etc/profile
- 下载Hadoop包
官网:http://hadoop.apache.org/releases.html // http://archive.apache.org/dist/hadoop/common/stable2/
- 配置hadoop环境变量
1.
export HADOOP_HOME=/usr/local/hadoop/hadoop-3.1.2
export JAVA_HOME=/usr/local/java/jdk1.8.0_201
export PATH=$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
2.source /etc/profile
- 修改hadoop的jdk配置(只需要主机操作,其他的先不操作)
- cd/usr/local/hadoop/hadoop_3.1.2/etc/hadoop
- vim Hadoop_env.sh
- export JAVA_HOME=/usr/local/java/jdk1.8.0_201/
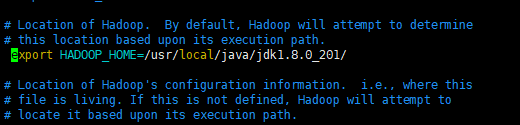
如果输入hado 在用tab补全是 Hadoop 就说明好了
- 修改hadoop配置
1.在 /usr/local/hadoop/ 下创建 tmp hdfs/name hdfs/data 文件
2.修改core-site.xml
fs.defaultFS
hdfs://master:9000
HDFS的URI
hadoop.tmp.dir
file:/usr/local/hadoop/tmp
节点上本地的hadoop临时文件夹
3.修改 hdfs-site.xml
dfs.namenode.http-address
master:50070
dfs.namenode.name.dir
file:/usr/local/hadoop/hdfs/name
namenode上存储hdfs名字空间元数据
dfs.datanode.data.dir
file:/usr/local/hadoop/hdfs/data
datanode上数据块的物理存储位置
dfs.replication
3
副本个数,默认是3,应小于datanode机器数量
dfs.webhdfs.enabled
true
dfs.permissions.enabled
false
4.修改mapred-site.xml
mapreduce.framework.name
yarn
指定mapreduce使用yarn框架
5.修改yarn-site.xml
yarn.resourcemanager.hostname
master
指定resourcemanager所在的hostname
yarn.nodemanager.aux-services
mapreduce_shuffle
NodeManager上运行的附属服务。
需配置成mapreduce_shuffle,才可运行MapReduce程序
6.输入 vim workers 修改配置文件(老版本是slaves文件,3.0.3 用 workers 文件代替 slaves 文件)
master
node1
node2
7.将hadoop的配置拷贝到其他机器上
sudo scp -rp /usr/local/hadoop/hadoop-3.1.2 node1: /usr/local/hadoop/
sudo scp -rp /usr/local/hadoop/hadoop-3.1.2 node2: /usr/local/hadoop/
- Hadoop搭建基本好了,下面我们来运行hadoop
1.格式化 hdfs namenode –format 第一次使用
2.添加HDFS权限,编辑如下脚本,在第二行空白位置添加HDFS权限
分别对下面两个文件操作
[root@hadoop01 sbin]# vim sbin/start-dfs.sh
[root@hadoop01 sbin]# vim sbin/stop-dfs.sh
加入下面的内容
HDFS_DATANODE_USER=root
HDFS_DATANODE_SECURE_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
3.添加Yarn权限:编辑如下脚本,在第二行空白位置添加Yarn权限
操作下面两个文件
[root@hadoop01 sbin]# vim sbin/start-yarn.sh
[root@hadoop01 sbin]# vim sbin/stop-yarn.sh
加入以下内容
YARN_RESOURCEMANAGER_USER=root
HDFS_DATANODE_SECURE_USER=yarn
YARN_NODEMANAGER_USER=root
注意:若不添加上述权限,则会报错:缺少用户权限定义所致。
![]()
ERROR: Attempting to launch hdfs namenode as root
ERROR: but there is no HDFS_NAMENODE_USER defined. Aborting launch.
Starting datanodes
ERROR: Attempting to launch hdfs datanode as root
ERROR: but there is no HDFS_DATANODE_USER defined. Aborting launch.
Starting secondary namenodes [localhost.localdomain]
ERROR: Attempting to launch hdfs secondarynamenode as root
ERROR: but there is no HDFS_SECONDARYNAMENODE_USER defined. Aborting l
- 初始化 & 启动
#格式化
[root@hadoop01 hadoop-3.2.0]# bin/hdfs namenode -format
#启动(两种方式均可启动)
方法一:
[root@hadoop01 hadoop-3.2.0]# start-all.sh
方法二:
[root@hadoop01 hadoop-3.2.0]# sbin/start-dfs.sh
[root@hadoop01 hadoop-3.2.0]# sbin/start-yarn.sh
验证
IP根据实际情况换成自己的IP
hdfs管理界面:http://192.168.1.130:50070
yarn管理界面:http://192.168.1.130:8088二、zookeeper搭建
1.下载zookeeper包
https://archive.apache.org/dist/zookeeper/
放在/usr/local/zookeeper 下并解压
2.修改/etc/profilr
export ZOOKEEPER=/usr/local/zookeeper/zookeeper-3.5.6
export HADOOP_HOME=/usr/local/hadoop/hadoop-3.1.2
export JAVA_HOME=/usr/local/java/jdk1.8.0_201
export HBASE_MANAGES_ZK=true
export PATH=$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$ZOOKEEPER/bin:$PATH
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar3.拷贝zoo_sample.cfg 为 zoo.cfg
cd /usr/local/zookeeper/zookeeper-3.5.6/conf/
cp zoo_sample.cfg zoo.cfg 4.修改三个zookeeper节点中的zoo.cfg文件,修改dataDir,添加server.0、server.1、server.2
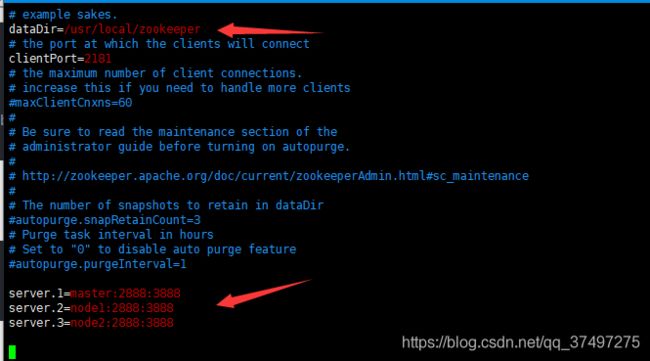
5.在 /usr/local/zookeeper 下面新建myid文件
cd /usr/local/zookeeper
vim myid在master节点的myid文件中写入1保存
6.拷贝到其他节点(环境变量和myid文件要修改)
sudo scp -rp /usr/local/zookeeper/ node2:/usr/local/
7.启动验证
启动:
/usr/local/zookeeper/zookeeper-3.5-6/bin/zkServer.sh start验证:
输入 jps 出现
QuorumPeerMain
三、hbase搭建
1.下载hbase包
cd /usr/local
mkdir hbase
wget http://mirrors.tuna.tsinghua.edu.cn/apache/hbase/2.2.1/hbase-2.2.1-bin.tar.gz或者在官网下 https://archive.apache.org/dist/hbase/
2.修改 /etc/profile 文件
export ZOOKEEPER=/usr/local/zookeeper/zookeeper-3.5.6
export HADOOP_HOME=/usr/local/hadoop/hadoop-3.1.2
export JAVA_HOME=/usr/local/java/jdk1.8.0_201
export HBASE_HOME=/usr/local//hbase/hbase-2.2.1/
export HBASE_MANAGES_ZK=true
export PATH=$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$ZOOKEEPER/bin:$HBASE_HOME/bin:$PATH
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar3.在/usr/local/hbase 下面新建 tmp
cd /usr/local/hbase
mkdir tmp4.修改master节点的配置文件hbase-site.xml(gedit /usr/local/hbase/conf/hbase-site.xml)
hbase.rootdir
hdfs://master:9000/hbase
hbase.cluster.distributed
true
hbase.zookeeper.quorum
master,node1,node2
hbase.temp.dir
/usr/local/hbase/tmp
hbase.zookeeper.property.dataDir
/usr/local/zookeeper
hbase.master.info.port
16010
5.修改配置文件regionservers(gedit /usr/local/hbase/conf/regionservers),删除里面的localhosts,改为:
master
node1
node2
6.修改修改master节点的配置文件hbase-env.sh
添加 export JAVA_HOME=/usr/local/java/jdk1.8.0_201/
7.拷贝到从机(/etc/profile要自己配置)
scp -r /usr/local/hbase root@node1:/usr/local/
scp -r /usr/local/hbase root@node2:/usr/local/
8.启动
./start-hbase.sh (bin下面) 启动出现下面的内容说明启动该成功
![]()
9.验证
(1)、启动好了之后输入./hbase shell 进入之后说明没问题了
(2)、输入jps查看
四、Spark安装
1.下载spark
cd /usr/local/spark
wget http://mirrors.hust.edu.cn/apache/spark/spark-2.4.0/spark-2.4.0-bin-hadoop2.7.tgz
tar –zxvf spark-2.4.0-bin-hadoop2.7.tgz
2.配置环境变量
export ZOOKEEPER=/usr/local/zookeeper/zookeeper-3.5.6
export HADOOP_HOME=/usr/local/hadoop/hadoop-3.1.2
export JAVA_HOME=/usr/local/java/jdk1.8.0_201
export HBASE_HOME=/usr/local//hbase/hbase-2.2.1/
export SPARK_HOME=/usr/local/spark/spark-2.4.0-bin-hadoop2.7/
export HBASE_MANAGES_ZK=true
export PATH=$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$HBASE_HOME/bin:$SPARK_HOME/bin:$SPARK_HOME/sbin:$ZOOKEEPER/bin:$PATH
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
source /etc/profile
3.spark集群配置
cd /usr/local/sparck/ spark-2.4.0-bin-hadoop2.7/conf
cp spark-env.sh.template spark-env.sh
配置 /conf/sparck-env.shexport JAVA_HOME=/usr/local/java/jdk1.8.0_201/
export SCALA_HOME=/usr/local/scala
export HADOOP_CONF_DIR=/usr/local/hadoop/hadoop-3.1.2/etc/hadoop
export HADOOP_HDFS_HOME=/usr/local/hadoop/hadoop-3.1.2/
export SPARK_HOME=/usr/local/spark/spark-2.4.0-bin-hadoop2.7/
export SPARK_MASTER_IP=master
export SPARK_MASTER_PORT=7077
export SPARK_MASTER_HOST=master
export SPARK_WORKER_CORES=2
export SPARK_WORKER_PORT=8901
export SPARK_WORKER_INSTANCES=1
export SPARK_WORKER_MEMORY=2g
export SPARK_DIST_CLASSPATH=$(/usr/local/hadoop/hadoop-3.1.2/bin/hadoop classpath)
export SPARK_MASTER_WEBUI_PORT=8079source spack-env.sh
4.配置从机
cd /usr/local/sparck/ spark-2.4.0-bin-hadoop2.7/conf
cp slaves.template slaves
vim slaves
写入
master
node1
node2
5.复制spack到从机(从机需要环境变量配置)
scp -r /usr/local/spark/ root@node1:/usr/local
scp -r /usr/local/spark/ root@node2:/usr/local
6.启动
cd /usr/local/sparck/ spark-2.4.0-bin-hadoop2.7
./sbin/start-all.sh
bin/run-example SparkPi 2>&1 | grep "Pi is"
如果出现以下情况说明成功

在虚拟机上输入:http://master:8079 可以看到web页面
五、安装hive
1.下载并解压
wget https://mirrors.tuna.tsinghua.edu.cn/apache/hive/hive-3.1.2/apache-hive-3.1.2-bin.tar.gz
tar –zxvf apache-hive-3.1.2-bin.tar.gz或者 https://archive.apache.org/dist/hive/
2.配置环境变量
vim /etc/profile
写入
export ZOOKEEPER=/usr/local/zookeeper/zookeeper-3.5.6
export HADOOP_HOME=/usr/local/hadoop/hadoop-3.1.2
export JAVA_HOME=/usr/local/java/jdk1.8.0_201
export HBASE_HOME=/usr/local//hbase/hbase-2.2.1/
export SPARK_HOME=/usr/local/spark/spark-2.4.0-bin-hadoop2.7/
export HIVE_HOME=/usr/local/hive/apache-hive-3.1.2-bin/
export HBASE_MANAGES_ZK=true
export PATH=$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$HBASE_HOME/bin:$SPARK_HOME/bin:$SPARK_HOME/sbin:$HIVE_HOME/bin:$ZOOKEEPER/bin:$PATH
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
执行
source /etc/profile
3.安装设置MYSQL
新建hive数据库:create database hive;
将hive数据库的字符编码设置为latin1(重要):
cd /usr/local/hive/apache-hive-3.1.2-bin/conf
mv hive-default.xml.template hive-default.xml上面命令是将hive-default.xml.template重命名为hive-default.xml,然后,使用vim编辑器新建一个配置文件hive-site.xml,命令如下:
cd /usr/local/hive/conf
vim hive-site.xml
在hive-site.xml中添加如下配置信息,其中:USERNAME和PASSWORD是MySQL的用户名和密码。
上面命令是将hive-default.xml.template重命名为hive-default.xml,然后,使用vim编辑器新建一个配置文件hive-site.xml,命令如下:
cd /usr/local/hive/conf
vim hive-site.xml
在hive-site.xml中添加如下配置信息,其中:USERNAME和PASSWORD是MySQL的用户名和密码。
javax.jdo.option.ConnectionURL
jdbc:mysql://localhost:3306/hive?createDatabaseIfNotExist=true
JDBC connect string for a JDBC metastore
javax.jdo.option.ConnectionDriverName
com.mysql.jdbc.Driver
Driver class name for a JDBC metastore
javax.jdo.option.ConnectionUserName
root
username to use against metastore database
javax.jdo.option.ConnectionPassword
root
username to use against metastore database
javax.jdo.option.ConnectionPassword
Herbert@123
password to use against metastore database
在hive-env.sh中添加下面配置
export HADOOP_HOME=/usr/local/hadoop/hadoop-2.7.3/
export HIVE_CONF_DIR=/usr/local/hive/apache-hive-1.2.1-bin/conf/
然后,按键盘上的“ESC”键退出vim编辑状态,再输入:wq,保存并退出vim编辑器。由于Hive在连接MySQL时需要JDBC驱动,所以首先需要下载对应版本的驱动,然后将驱动移动到/usr/local/hive/lib中。
#解压
tar -zxvf mysql-connector-java-5.1.47.tar.gz
#将mysql-connector-java-5.1.47.tar.gz拷贝到/usr/local/hive/lib目录下
cp mysql-connector-java-5.1.47/mysql-connector-java-5.1.47-bin.jar /usr/local/hive/lib启动hive(启动hive之前,请先启动hadoop集群)。
./usr/local/hadoop/sbin/start-all.sh #启动hadoop,如果已经启动,则不用执行该命令#启动hivehive
六、搭建scala
1.下载scala
https://www.scala-lang.org/download/
下载 tgz 包
上传到 /usr/local/scala
2.配置scala
export ZOOKEEPER=/usr/local/zookeeper/zookeeper-3.5.6
export HADOOP_HOME=/usr/local/hadoop/hadoop-3.1.2
export JAVA_HOME=/usr/local/java/jdk1.8.0_201
export HBASE_HOME=/usr/local//hbase/hbase-2.2.1/
export SPARK_HOME=/usr/local/spark/spark-2.4.0-bin-hadoop2.7/
export HIVE_HOME=/usr/local/hive/apache-hive-3.1.2-bin/
export HBASE_MANAGES_ZK=true
export SCALA_HOME=/usr/local/scala/scala-2.13.1/
export PATH=$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$HBASE_HOME/bin:$SPARK_HOME/bin:$SPARK_HOME/sbin:$HIVE_HOME/bin:$SCALA_HOME/bin:$ZOOKEEPER/bin:$PATH
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar