上才艺!CentOS7从0到1部署Apache Hadoop生态集群
文章目录
-
-
- 一、Linux环境准备
-
- 1、配置映射(三台主机)
- 2、免密操作
- 3、同步节点时间
-
- (1)选择时区(三台主机)
- (2)安装ntp服务,配置Hadoop1为服务器
- 4、JDK安装
-
- (1)卸载其他版本JDK
- (2)安装JDK1.8+
- 5、端口号操作
- 二、Hadoop集群安装
-
- 1、zookeeper安装
- 2、Hadoop安装
- 3、Hbase安装
- 4、数据仓库:Mysql+metastore+hive cli
-
- (1)hadoop3:mysql安装
- (2)hadoop2:hive metastore
- (3)hive client
- (4)启动hive
- 三、集群测试
-
- 1、MR测试
-
- (1)计算圆周率
- (2)词频统计
- 2、Hive分析
-
- (1)导入到Hive
- (2)从Hive导出
-
迄今为止,Hadoop是世界上最多公司使用的大数据平台。尽管已有其他优秀的公司开发出媲美Hadoop组件的软件,比如Spark、Flink 之于 MapReduce,云存储之于 HDFS,K8S 之于 YARN。
但在生态方面,Hadoop独树一帜。
Hadoop的发行版本较多,比较出众的有
- Cloudera’s Distribution Including Apache Hadoop,简称CDH
- Hortonworks Data Platform,简称“HDP”
- Apache Hadoop 最原始的版本,所有发行版均基于这个版本进行改进,是最适合大数据入门学习的版本,也是本文的主题。
目前Cloudera和Hortonworks已合并,预计在2022年推出整合性的新产品。
一、Linux环境准备
1、配置映射(三台主机)
配置映射后可以直接使用映射名访问其他主机,映射类似于DNS服务器,会将便于记忆可读性高的映射名转换为实际的IP进行访问。
vim /etc/hosts
最后面插入IP 映射名,映射名可以不是主机名
192.168.206.132 hadoop1
192.168.206.134 hadoop2
192.168.206.133 hadoop3
修改主机名(可选操作),完成后重启:reboot
[root@hadoop1 ~]# vim /etc/hostname
[root@hadoop1 ~]# hostname
hadoop1
2、免密操作
免密能帮助我们在开\关服务时节省大量时间,这也是Hadoop节点之间通信、访问的必要基础操作。
主(Hadoop1)节点上:
[root@hadoop1 ~]# ssh-keygen #之后按三次回车,会在~/.ssh 生成文件
Generating public/private rsa key pair.
Enter file in which to save the key (/root/.ssh/id_rsa):
Enter passphrase (empty for no passphrase):
Enter same passphrase again:
Your identification has been saved in /root/.ssh/id_rsa.
Your public key has been saved in /root/.ssh/id_rsa.pub.
The key fingerprint is:
SHA256:9xezCwJWTfZAOrTPiFeave97f1q+dhINec05PiS1HHc root@hadoop1
The key's randomart image is:
+---[RSA 2048]----+
| ..= |
| . * o oE|
| = o +oB|
| o X .o*+|
| S * + *+.|
| . + . ..*.|
| . + o.o|
| . +.=+|
| .B*B|
+----[SHA256]-----+
查看文件
[root@hadoop1 ~]# ll ~/.ssh/
total 12
-rw-------. 1 root root 1675 Jul 19 18:44 id_rsa #密钥
-rw-r--r--. 1 root root 394 Jul 19 18:44 id_rsa.pub #公钥
-rw-r--r--. 1 root root 185 Jul 19 18:44 known_hosts #已连接的记录
复制密钥到其他主机上:
ssh-copy-id hadoop1 #ssh内回环
ssh-copy-id hadoop2
ssh-copy-id hadoop3
第一次需要输入密码,完成之后可以使用ssh hadoop[1,2,3]无密码登录连接
3、同步节点时间
Hadoop集群对事件非常敏感,zookeeper中以毫秒为单位监听节点心跳,如果时间不统一,可能造成集群异常
(1)选择时区(三台主机)
tzselect #之后依次选择——>亚洲———>中国———>北京,最后选择1)yes
yes之后会生成shell命令修改时区,我们直接复制粘贴使用
[root@hadoop1 ~]# TZ='Asia/Shanghai'; export TZ
(2)安装ntp服务,配置Hadoop1为服务器
yum install –y ntp
Hadoop1作为 ntp 服务器,修改 ntp 配置文件。(Hadoop1上执行)
[root@hadoop1 ~]# vim /etc/ntp.conf
server 127.127.1.0 # local clock
fudge 127.127.1.0 stratum 10 #stratum 设置为其它值也是可以的,其范围为 0~15
重启ntp服务
[root@hadoop1 ~]# /bin/systemctl restart ntpd.service
在其他节点同步时间(两台节点)
[root@hadoop2 ~]# ntpdate hadoop1
19 Jul 19:07:36 ntpdate[13451]: adjust time server 192.168.206.132 offset 0.003229 sec
[root@hadoop2 ~]#
添加定时任务,每10分钟同步一次(两台节点)
[root@hadoop2 ~]# crontab -e #-e:添加,-l:列出,-r:删除定时任务
*/10 * * * * /usr/sbin/ntpdate hadoop1
4、JDK安装
(1)卸载其他版本JDK
查询有无其他JDK版本,需要卸载掉(三台)
[root@hadoop1 ~]# rpm -qa |grep jdk
一次性全部卸载:
[root@hadoop1 ~]# rpm -qa |grep jdk |xargs rpm -e --nodeps
(2)安装JDK1.8+
使用rz命令将Windows下的文件传到Linux当前目录中(需安装lrzsz,安装命令:yum install -y lrzsz)
将所有需要的包传入到/usr/local/share中
解压JDK
[root@hadoop1 share]# ll
total 678020
-rw-r--r--. 1 root root 149756462 Nov 30 2018 apache-hive-2.1.1-bin.tar.gz
drwxr-xr-x. 2 root root 28 Nov 5 2019 applications
-rw-r--r--. 1 root root 214092195 Nov 22 2018 hadoop-2.7.3.tar.gz
-rw-r--r--. 1 root root 104497899 Nov 28 2018 hbase-1.2.4-bin.tar.gz
drwxr-xr-x. 2 root root 6 Apr 10 2018 info
-rw-r--r--. 1 root root 190890122 Nov 21 2018 jdk-8u171-linux-x64.tar.gz
drwxr-xr-x. 21 root root 243 Nov 5 2019 man
-rw-r--r--. 1 root root 35042811 Nov 28 2018 zookeeper-3.4.10.tar.gz
[root@hadoop1 share]# tar -zxvf ./jdk-8u171-linux-x64.tar.gz -C /usr/local/ #-C :指定目录
配置环境变量
[root@hadoop1 share]# vim /etc/profile
export JAVA_HOME=/usr/local/jdk1.8.0_171
export PATH=$PATH:$JAVA_HOME/bin
生效环境变量
[root@hadoop1 share]# source /etc/profile
[root@hadoop1 share]#
查看Java版本或使用jps命令
[root@hadoop1 share]# java -version
java version "1.8.0_171"
Java(TM) SE Runtime Environment (build 1.8.0_171-b11)
Java HotSpot(TM) 64-Bit Server VM (build 25.171-b11, mixed mode)
[root@hadoop1 share]# jps
4995 Jps
[root@hadoop1 share]#
以上操作可以在三台主机上同步进行,也可以在hadoop1当中完成后传输到hadoop[2,3],命令:scp -r /usr/local/jdk1.8.0_171 hadoop2:/usr/local/,但是配置环境变量需要手动配置,然后source生效
5、端口号操作
hadoop集群需要大量的端口号,如zookeeper的心跳检测端口、选举端口,yarn的资源端口等。为了方便,建议直接关闭防火墙,但是在生产环境中,可以使用端口号操作
添加
firewall-cmd --zone=public --add-port=80/tcp --permanent #–permanent永久生效,没有此参数重启后失效
重新载入
firewall-cmd --reload
查看
firewall-cmd --zone= public --query-port=80/tcp
删除
firewall-cmd --zone= public --remove-port=80/tcp --permanent
此处直接关闭防火墙(三台):
[root@hadoop1 jdk1.8.0_171]# systemctl stop firewalld
[root@hadoop1 jdk1.8.0_171]# systemctl status firewalld
● firewalld.service - firewalld - dynamic firewall daemon
Loaded: loaded (/usr/lib/systemd/system/firewalld.service; disabled; vendor preset: enabled)
Active: inactive (dead)
Docs: man:firewalld(1)
[root@hadoop1 jdk1.8.0_171]#
二、Hadoop集群安装
Hadoop安装的大步骤:解压—>配置环境变量—>修改配置文件—>传输文件到节点—>测试启动
1、zookeeper安装
zookeeper:高性能的分布式应用协调服务框架,可以帮助我们管理集群节点之间的操作,防止出现部分逻辑错误。我个人喜欢先安装它
解压
[root@hadoop1 share]# tar -zxvf ./zookeeper-3.4.10.tar.gz -C /usr/local/
配置环境变量
[root@hadoop1 local]# vim /etc/profile
export ZOOKEEPER_HOME=/usr/local/zookeeper-3.4.10
export PATH=$PATH:$JAVA_HOME/bin:$ZOOKEEPER_HOME/bin
[root@hadoop1 local]# source /etc/profile
进入配置目录,开始配置zookeeper
[root@hadoop1 local]# source /etc/profile
[root@hadoop1 local]# cd zookeeper-3.4.10/conf/
[root@hadoop1 conf]# pwd
/usr/local/zookeeper-3.4.10/conf
[root@hadoop1 conf]# ll
total 12
-rw-rw-r--. 1 mysqlroot mysqlroot 535 Mar 23 2017 configuration.xsl
-rw-rw-r--. 1 mysqlroot mysqlroot 2161 Mar 23 2017 log4j.properties
-rw-rw-r--. 1 mysqlroot mysqlroot 922 Mar 23 2017 zoo_sample.cfg
[root@hadoop1 conf]#
$ZOOKEEPER/conf/下:zoo.cfg
[root@hadoop1 conf]# cp zoo_sample.cfg ./zoo.cfg
[root@hadoop1 conf]# vim zoo.cfg
具体有效配置如下:
dataDir=/usr/local/zookeeper-3.4.10/zk/data #数据目录
dataLogDir=/usr/local/zookeeper-3.4.10/zk/dataLog #日志目录
server.1=hadoop1:2888:2889 #节点:通信端口:选举端口
server.2=hadoop2:2888:2889
server.3=hadoop3:2888:2889
返回到安装目录,创建对应的两个文件目录,并配置myid
[root@hadoop1 conf]# cd ../
[root@hadoop1 zookeeper-3.4.10]# mkdir -p ./zk/data
[root@hadoop1 zookeeper-3.4.10]# mkdir -p ./zk/dataLog
#配置myid
[root@hadoop1 zookeeper-3.4.10]# echo 1 > ./zk/data/myid
[root@hadoop1 zookeeper-3.4.10]# cat ./zk/data/myid
1
分发文件到hadoop[2,3],配置/etc/profile并修改myid为对应的数字
[root@hadoop1 zookeeper-3.4.10]# scp -r /usr/local/zookeeper-3.4.10/ hadoop2:/usr/local/ &
[1] 5547
[root@hadoop1 zookeeper-3.4.10]# scp -r /usr/local/zookeeper-3.4.10/ hadoop3:/usr/local/ &
[2] 5549
[1] Done scp -r /usr/local/zookeeper-3.4.10/ hadoop2:/usr/local/
[root@hadoop1 zookeeper-3.4.10]#
启动,并查看状态
[root@hadoop1 zookeeper-3.4.10]# zkServer.sh start
ZooKeeper JMX enabled by default
Using config: /usr/local/zookeeper-3.4.10/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
[root@hadoop1 zookeeper-3.4.10]# zkServer.sh status
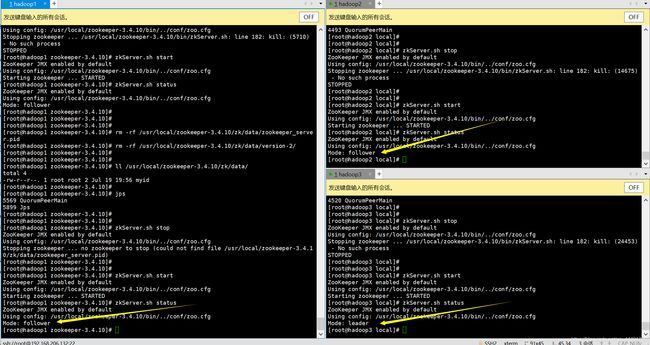
一台为leader,另外两台为follower,至于为什么hadoop3是leader而hadoop1是follower,这和zookeeper的选举机制有关系,有兴趣的小伙伴可以自行了解。
2、Hadoop安装
和zookeeper的安装步骤一致,但是配置的文件较多
解压和配置环境变量就演示了,直接上配置文件!
Hadoop的配置文件分为两种:
- core-default.xml: Hadoop的只读属性
- core-site.xml: 某个给定hadoop的site-specific的配置。
第一种相当于是Hadoop的默认配置,第二种是开放给用户的配置,第二种配置会覆盖掉第一种配置。我们一般是修改第二种文件。
Hadoop配置文件及意义如下:
| 文件名 | 意义 |
|---|---|
| hadoop-env.sh | 运行Hadoop所需要的环境变量 |
| yarn-env.sh | 运行yarn所需要的环境变量 |
| core-site.xml | Hadoop核心全局配置文件,可在其他地方引用 |
| hdfs.site.xml | HDFS配置文件,继承自core-site.xml |
| yarn.site.xml | yarn配置文件,继承自core-site.xml |
| mapred-site.xml | MR配置文件,继承自core-site.xml |
| slaves | Hadoop所有从节点列表 |
到配置文件目录下一个一个修改:
[root@hadoop1 local]# cd hadoop-2.7.3/etc/hadoop/
[root@hadoop1 hadoop]#
[root@hadoop1 hadoop]# pwd
/usr/local/hadoop-2.7.3/etc/hadoop
[root@hadoop1 hadoop]# ls
capacity-scheduler.xml httpfs-env.sh mapred-env.sh
configuration.xsl httpfs-log4j.properties mapred-queues.xml.template
container-executor.cfg httpfs-signature.secret mapred-site.xml
core-site.xml httpfs-site.xml mapred-site.xml.template
hadoop-env.sh kms-acls.xml slaves
hadoop-metrics2.properties kms-env.sh ssl-client.xml.example
hadoop-metrics.properties kms-log4j.properties ssl-server.xml.example
hadoop-policy.xml kms-site.xml yarn-env.sh
hdfs-site.xml log4j.properties yarn-site.xml
hadoop.env.sh
修改JAVA_HOME为自己的安装目录
# The java implementation to use.
export JAVA_HOME=/usr/local/jdk1.8.0_171
core-site.xml
Hadoop集群核心配置,如文件系统主机和端口,临时文件夹等
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://hadoop1:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop-2.7.3/hdfs/tmp</value>
<description>A base for other temporary directories.</description>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
<property>
<name>fs.checkpoint.period</name>
<value>60</value>
</property>
<property>
<name>fs.checkpoint.size</name>
<value>67108864</value>
</property>
</configuration>
hdfs-site.xml
HDFS核心配置,包括备份数量、namenode目录、datanode目录等信息
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/hadoop/hadoop-2.7.3/hdfs/name</value>
<final>true</final>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/hadoop/hadoop-2.7.3/hdfs/data</value>
<final>true</final>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop1:9001</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
</configuration>
yarn-site.xml
RM提供客户端访问的地址,RM的NodeManager的地址,资源调度模型,可用内存最大最小等
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.resourcemanager.address</name>
<value>hadoop1:18040</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>hadoop1:18030</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>hadoop1:18088</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>hadoop1:18025</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>hadoop1:18141</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
mapred-site.xml
map运行模式,有local(本地),yarn,classic
[root@hadoop1 hadoop]# cp ./mapred-site.xml.template mapred-site.xml
[root@hadoop1 hadoop]# vim mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
log4j.properties
日志设置文件,不做探讨
selave
从节点列表,可包括Hadoop1
hadoop2
hadoop3
然后分发文件到两个节点,scp -r /usr/local/hadoop-2.7.3/ hadoop2:/usr/local/–>配置环境变量–>生效
直接一次性启动所有节点(主节点)
[root@hadoop1 hadoop]# pwd
/usr/local/hadoop-2.7.3/etc/hadoop
[root@hadoop1 hadoop]# cd ../..
[root@hadoop1 hadoop-2.7.3]# ./sbin/start-all.sh
[root@hadoop1 hadoop-2.7.3]# jps
5569 QuorumPeerMain
7027 SecondaryNameNode
6854 DataNode
7191 ResourceManager
7511 Jps
6717 NameNode
7310 NodeManager
[root@hadoop1 hadoop-2.7.3]#
查看从节点的启动进程
[root@hadoop2 local]# jps
15477 DataNode
15592 NodeManager
15753 Jps
4493 QuorumPeerMain
| 进程名 | values |
|---|---|
| QuorumPeerMain | zookeeper运行进程 |
| SecondaryNameNode | namenode守护进程 |
| NameNode | HDFS的主节点运行进程 |
| DataNode | HDFS从节点的运行进程,是实际保存数据的进程 |
| ResourceManager | yarn主节点运行进程 |
| NodeManager | yarn从节点运行进程 |
3、Hbase安装
HBase – Hadoop Database,是一个高可靠性、高性能、面向列、可伸缩的分布式存储系统,利用HBase技术可在廉价PC Server上搭建起大规模结构化存储集群。
HBase在Hadoop之上提供了类似于Bigtable的能力。HBase是Apache的Hadoop项目的子项目。HBase不同于一般的关系数据库,它是一个适合于非结构化数据存储的数据库。另一个不同的是HBase基于列的而不是基于行的模式。
== 解压–>配置环境变量跳过 ==
修改配置文件conf/hbase-env.sh
export HBASE_MANAGES_ZK=false
export JAVA_HOME=/usr/java/jdk1.8.0_171
export HBASE_CLASSPATH=/usr/hadoop/hadoop-2.7.3/etc/Hadoop
一个分布式运行的 Hbase 依赖一个 zookeeper 集群。所有的节点和客
户端都必须能够访问 zookeeper。默认的情况下 Hbase 会管理一个 zookeep 集群,即 Hbase 默认自带一个 zookeep 集群。这个集群会随着 Hbase 的启动而启动。而在实际的商业项目中通常自己管理一个 zookeeper 集群更便于优化配置ᨀ高集群 工 作 效 率 , 但 需 要 配 置 Hbase 。 需 要 修 改 conf/hbase-env.sh 里 面 的HBASE_MANAGES_ZK 来切换。这个值默认是 true 的,作用是让 Hbase 启动的时候同时也启动 zookeeper.在本实验中,我们采用独立运行 zookeeper 集群的方式,故将其属性值改为 false。
配置conf/hbase-site.xml
<configuration>
<property>
<name>hbase.rootdir</name>
<value>hdfs://hadoop1:9000/hbase</value>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<name>hbase.master</name>
<value>hdfs://hadoop1:6000</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>hadoop1,hadoop2,hadoop3</value>
</property>
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/usr/local/zookeeper-3.4.10</value>
</property>
</configuration>
要想运行完全分布式模式,加一个属性 hbase.cluster.distributed
设置为 true 然后把 hbase.rootdir 设置为 HDFS 的 NameNode 的位置
hbase.rootdir:这个目录是 region server 的共享目录,用来持久化 Hbase。URL 需要是’完全正确’的,还要包含文件系统的 scheme
hbase.cluster.distributed :Hbase 的运行模式。false 是单机模式,true是分布式模式。
配置 conf/regionservers
列出了希望运行的全部 HRegionServer
hadoop2
hadoop3
复制hdfs-site.xml和core-site.xml文件到./conf目录
Hbase依赖于HDFS,故需要将core和hdfs配置文件复制到当前目录中
[root@hadoop1 hbase-1.2.4]# cp /usr/local/hadoop-2.7.3/etc/hadoop/hdfs-site.xml /usr/local/hbase-1.2.4/conf/
[root@hadoop1 hbase-1.2.4]# cp /usr/local/hadoop-2.7.3/etc/hadoop/core-site.xml /usr/local/hbase-1.2.4/conf/
分发文件到hadoop2–>配置环境变量
在hadoop1上启动Hbase(保证 hadoop 和 zookeeper 已开启):
bin/start-hbase.sh
[root@hadoop1 hbase-1.2.4]# jps
5569 QuorumPeerMain
7027 SecondaryNameNode
6854 DataNode
7191 ResourceManager
9193 Jps
6717 NameNode
7310 NodeManager
8990 HMaster
从节点查看jps
[root@hadoop2 local]# jps
15477 DataNode
16566 Jps
15592 NodeManager
4493 QuorumPeerMain
16429 HRegionServer
访问Hbase Web管理界面查看
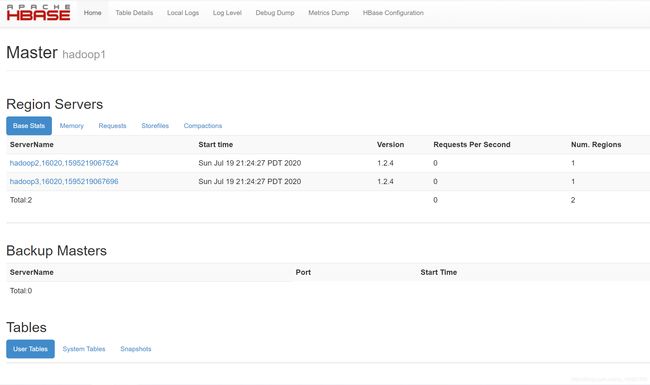
4、数据仓库:Mysql+metastore+hive cli
hive有三种运行模式:
- 本地单用户模式,hive+derby(自带的数据库)
- 本地多用户模式,hive+mysql
- 远程多用户模式,hive+mysql+服务器
本次演示的是远程多用户模式,使用hadoop3安装MySQL,Hadoop2做metastore服务器,hadoop1当hive客户端
(1)hadoop3:mysql安装
wget http://dev.mysql.com/get/mysql57-community-release-el7-8.noarch.rpm
rpm -ivh mysql57-community-release-el7-8.noarch.rpm
yum -y install mysql-community-server
启动服务
systemctl daemon-reload #重载配置
systemctl start mysqld #开启服务
systemctl enable mysqld #开机启动
安装完毕后,/var/log/mysqld.log 文件中会自动生成一个随机的密码,我们需要先取得这个随机密码,以用于登录 MySQL 服务端:
grep /var/log/mysqld.log #获取初密码
mysql -uroot -p #登陆 MySQL
MySQL密码设置
set global validate_password_policy=0;
set global validate_password_length=4;
alter user 'root'@'localhost' identified by '123456';
密码强度分级如下:
0 为 low 级别,只检查长度;
1 为 medium 级别(默认),符合长度为 8,且必须含有数字,大小写,特殊
字符;
2 为 strong 级别,密码难度更大一些,需要包括字典文件。
密码长度最低长为 4,当设置长度为 1、2、3 时,其长度依然为 4。
MySQL远程登录设置
mysql -uroot -p123456
create user 'root'@'%' identified by '123456';
grant all privileges on *.* to 'root'@'%' with grant option;
flush privileges;
到此,hadoop3配置完毕
(2)hadoop2:hive metastore
解压–>配置环境变量
配置文件hive-env.sh
hadoop的环境变量
[root@hadoop2 conf]# mv ./hive-env.sh.template hive-env.sh
[root@hadoop2 conf]# vim ./hive-env.sh
# Set HADOOP_HOME to point to a specific hadoop install directory
HADOOP_HOME=/usr/local/hadoop-2.7.3
修改 hive-site.xml 文件
hive核心配置,连接地址,MySQL驱动地址等
<configuration>
<!-- Hive 产生的元数据存放位置-->
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive_remote/warehouse</value>
</property>
<!-- 数据库连接 JDBC 的 URL 地址-->
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://192.168.206.133:3306/hive?createDatabaseIfNotExist=true&useSSL=false</value>
</property>
<!-- 数据库连接 driver,即 MySQL 驱动-->
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<!-- MySQL 数据库用户名-->
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<!-- MySQL 数据库密码-->
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>123456</value>
</property>
<property>
<name>hive.metastore.schema.verification</name>
<value>false</value>
</property>
<property>
<name>datanucleus.schema.autoCreateAll</name>
<value>true</value>
</property>
</configuration>
复制MySQL的驱动包
[root@hadoop2 lib]# pwd
/usr/local/hive-2.1.1/lib
[root@hadoop2 lib]# ls | grep mysql
mysql-connector-java-5.1.46-bin.jar
Hadoop需要运行在Java平台上,而MySQL则不是,故需要将MySQL的驱动包复制到hadoop2,用于hadoop2的hive和hadoop3的MySQL通信(我是直接下载的驱动包,rz传到./lib下)
至此,hadoop2配置完毕
(3)hive client
首先解决版本冲突和 jar 包依赖问题
[root@hadoop1 conf]# scp /usr/local/hive-2.1.1/lib/jline-2.12.jar /usr/local/hadoop-2.7.3/share/hadoop/yarn/lib/
由于客户端需要和 Hadoop 通信,所以需要更改 Hadoop 中 jline 的版本。即保留一个高版本的 jline jar 包,从 hive 的 lib 包中拷贝到 Hadoop 中 lib 位置
修改 hive-env.sh
和metastore不同,客户端只需要配置少部分内容
<configuration>
<!-- Hive 产生的元数据存放位置-->
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive_remote/warehouse</value>
</property>
<!--- 使用本地服务连接 Hive,默认为 true-->
<property>
<name>hive.metastore.local</name>
<value>false</value>
</property>
<!-- 连接服务器-->
<property>
<name>hive.metastore.uris</name>
<value>thrift://hadoop2:9083</value>
</property>
</configuration>
至此,hadoop1配置完毕
(4)启动hive
hadoop2:
[root@hadoop2 hive-2.1.1]# ./bin/hive --service metastore
启动效果:
hadoop1:
[root@hadoop1 conf]# hive
hive> SHOW DATABASES;
OK
datadb
default
Time taken: 0.976 seconds, Fetched: 2 row(s)
hive>
三、集群测试
1、MR测试
hadoop内自带了一些jar包,可以直接使用测试
[root@hadoop1 mapreduce]# pwd
/usr/local/hadoop-2.7.3/share/hadoop/mapreduce
[root@hadoop1 mapreduce]# ls
hadoop-mapreduce-client-app-2.7.3.jar hadoop-mapreduce-client-shuffle-2.7.3.jar
hadoop-mapreduce-client-common-2.7.3.jar hadoop-mapreduce-examples-2.7.3.jar
hadoop-mapreduce-client-core-2.7.3.jar lib
hadoop-mapreduce-client-hs-2.7.3.jar lib-examples
hadoop-mapreduce-client-hs-plugins-2.7.3.jar mysql57-community-release-el7-8.noarch.rpm
hadoop-mapreduce-client-jobclient-2.7.3.jar sources
hadoop-mapreduce-client-jobclient-2.7.3-tests.jar
(1)计算圆周率
测试圆周率的计算
格式:hadoop jar jar包名 函数 函数参数
第一个10表示多少次map,第二个10表示每次mar的个数
[root@hadoop1 mapreduce]# hadoop jar hadoop-mapreduce-examples-2.7.3.jar pi 10 10
运行结果(部分)
Estimated value of Pi is 3.20000000000000000000
(2)词频统计
同样也是自带的包内包含的功能,不过需要基于HDFS操作
我已经提前将word.txt传到hdfs的/data目录下,里面是下载的一篇纯英文的长小说,直接上才艺
[root@hadoop1 mapreduce]# hdfs dfs -ls /data
Found 3 items
-rw-r--r-- 2 root supergroup 690577 2020-07-19 01:07 /data/word.txt
[root@hadoop1 mapreduce]# hadoop jar hadoop-mapreduce-examples-2.7.3.jar wordcount /data/word.txt /data/outs
注意:wordcount后面的两个目录均是HDFS下的目录
查看一下
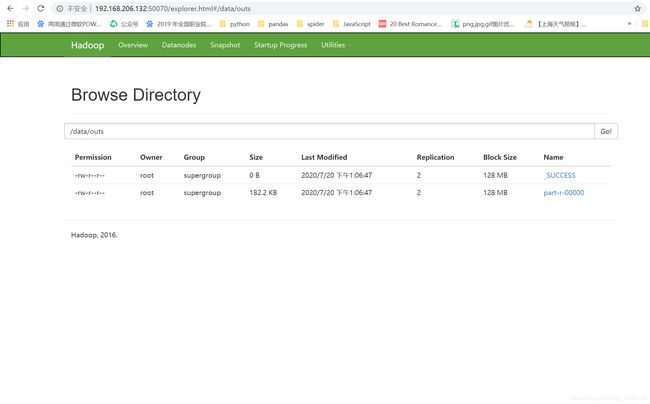
[root@hadoop1 mapreduce]# hdfs dfs -ls /data/outs/
Found 2 items
-rw-r--r-- 2 root supergroup 0 2020-07-19 22:06 /data/outs/_SUCCESS
-rw-r--r-- 2 root supergroup 186577 2020-07-19 22:06 /data/outs/part-r-00000
[root@hadoop1 mapreduce]# hdfs dfs -cat /data/outs/part-r-00000
也可以在Web界面查看目录
2、Hive分析
(1)导入到Hive
本地导入
hive> LOAD DATA LOCAL INPATH "/home/hadoopUser/data/test1.txt"
> INTO TABLE test1;
HDFS导入
hive> LOAD DATA INPATH "/input/test1.txt"
> OVERWRITE INTO TABLE test1;
(2)从Hive导出
到本地:
insert overwrite local directory '/data/hive/export/student_info' select * from default.student
不过我听说这种方式会清空文件夹里的内容,建议使用INTO导出到本地的方式
这里使用了OVERWRITE关键字,因此之前的内容(如果是非分区表,就是之前表中的内容)将会被覆盖掉。
这里如果没有使用OVERWRITE关键字或者使用INTO关键字替换掉它的话,那么Hive将会以追加的方式写入数据而不会覆盖掉之前已经存在的内容。
shell中导出到本地
bin/hive -e "select * from default.student_info ;" > /data/hive/export/local/student_info
~~ 其他的一些方法就不一一罗列了,大家有兴趣的自行了解~~
原创内容,进制复制盗用!欢迎讨论交流.
参考连接:yarn-site.xml配置文件
参考链接:core-site.xml配置文件
参考链接:centos7 添加端口