李宏毅《深度学习》(一)
人工智能的浪潮正在席卷全球,诸多词汇时刻萦绕在我们耳边:人工智能(Artificial Intelligence)、机器学习(Machine Learning)、深度学习(Deep Learning)。本文主要是对李宏毅课程内容进行笔记梳理,参考链接在文末已经给出。
1-机器学习介绍
人工智能是我们想要达成的目标,而机器学习是想要达成目标的手段,希望机器通过学习方式,他跟人一样聪明。深度学习则是是机器学习的其中一种方法。简而言之就是:机器学习是一种实现人工智能的方法,深度学习是一种实现机器学习的技术。
机器学习和深度学习
机器学习
机器学习最基本的做法,是使用算法来解析数据、从中学习,然后对真实世界中的事件做出决策和预测。与传统的为解决特定任务、硬编码的软件程序不同,机器学习是用大量的数据来“训练”,通过各种算法从数据中学习如何完成任务。
这里有三个重要的信息:
- 机器学习是模拟、延伸和扩展人的智能的一条路径,所以是人工智能的一个子集;
- “机器学习”是要基于大量数据的,也就是说它的“智能”是用大量数据喂出来的;
- 正是因为要处理海量数据,所以大数据技术尤为重要;“机器学习”只是大数据技术上的一个应用。
常用的10大机器学习算法有:决策树、随机森林、逻辑回归、SVM、朴素贝叶斯、K最近邻算法、K均值算法、Adaboost算法、神经网络、马尔科夫。
深度学习
深度学习是用于建立、模拟人脑进行分析学习的神经网络,并模仿人脑的机制来解释数据的一种机器学习技术。
它的基本特点,是试图模仿大脑的神经元之间传递,处理信息的模式。深度学习本来并不是一种独立的学习方法,其本身也会用到有监督和无监督的学习方法来训练深度神经网络。但由于近几年该领域发展迅猛,一些特有的学习手段相继被提出(如残差网络),因此越来越多的人将其单独看作一种学习的方法。
但是目前深度学习也存在着相应的问题:
- 深度学习模型需要大量的训练数据,才能展现出神奇的效果,但现实生活中往往会遇到小样本问题,此时深度学习方法无法入手,传统的机器学习方法就可以处理。
- 有些领域,采用传统的简单的机器学习方法,可以很好地解决了,没必要非得用复杂的深度学习方法。
- 深度学习的思想,来源于人脑的启发,但绝不是人脑的模拟,人类的学习过程往往不需要大规模的训练数据,而现在的深度学习方法显然不是对人脑的模拟。
机器学习相关技术
机器学习可以主要分为:
- 监督学习
- 半监督学习
- 迁移学习
- 无监督学习
- 监督学习中的结构化学习
- 强化学习
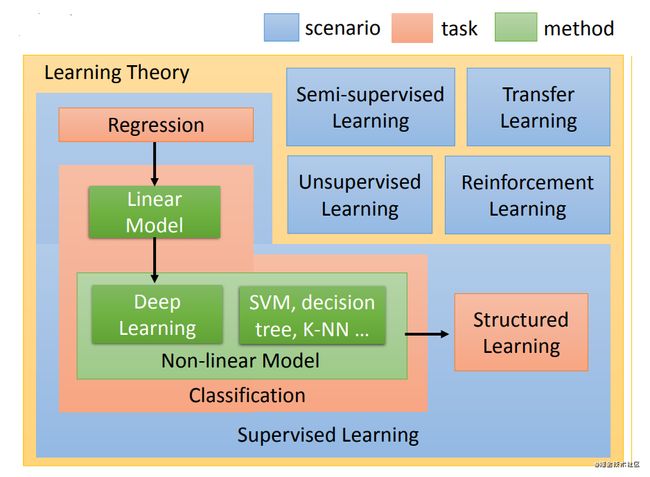
这张图主要是对机器学习进行的相应的细分,我们首先对图的左上角监督学习进行讲解
监督学习
定义:根据已有的数据集,知道输入和输出结果之间的关系。根据这种已知的关系,训练得到一个最优的模型。
也就是说,在监督学习中训练数据既有特征(feature)
又有标签(label),通过训练,让机器可以自己找到特征和标签之间的联系,在面对只有特征没有标签的数据时,可以判断出标签。
通俗一点,可以把机器学习理解为我们教机器如何做事情。
监督学习分为:
- 回归问题(Regression)
- 分类问题(classification)
经典的算法:支持向量机、线性判别、决策树、朴素贝叶斯
回归问题
回归问题是针对于连续型变量的。
回归通俗一点就是,对已经存在的点(训练数据)进行分析,拟合出适当的函数模型y=f(x),这里y就是数据的标签,而对于一个新的自变量x,通过这个函数模型得到标签y。
分类问题
回归问题Regression和分类问题Classification的差别就是我们要机器输出的东西的类型是不一样。在回归问题中机器输出的是一个数值,在分类问题里面机器输出的是类别,和回归最大的区别在于,分类是针对离散型的,输出的结果是有限的。
其中分类问题分为两种:
- 二分类,输出是或否。例如判断肿瘤为良性还是恶性
- 多分类,在多个选项中选择正确的类别。例如输入一张图片判读是猫是狗还是猪
简单来说分类就是,要通过分析输入的特征向量,对于一个新的向量得到其标签。

以上是让机器去解决的问题,解决问题的第一步就是选择解决问题的函数,也就是选择解决问题所需要的模型。
主要为线性模型和非线性模型
半监督学习
传统的机器学习技术分为两类,一类是无监督学习,一类是监督学习。
无监督学习只利用未标记的样本集,而监督学习则只利用标记的样本集进行学习。
但在很多实际问题中,只有少量的带有标记的数据,因为对数据进行标记的代价有时很高,比如在生物学中,对某种蛋白质的结构分析或者功能鉴定,可能会花上生物学家很多年的工作,而大量的未标记的数据却很容易得到。这就促使能同时利用标记样本和未标记样本的半监督学习技术迅速发展起来。简而言之,半监督学习就是去减少标签(label)
的用量。
半监督学习是归纳式的,生成的模型可用做更广泛的样本
半监督学习算法分类:
- self-training(自训练算法)
- generative models生成模型
- SVMs半监督支持向量机
- graph-basedmethods图论方法
- multiview learing多视角算法
- 其他方法
迁移学习
目标: 将某个领域或任务上学习到的知识或模式应用到不同但相关的领域或问题中。
主要思想: 从相关领域中迁移标注数据或者知识结构、完成或改进目标领域或任务的学习效果。
例如人类学会了骑自行车,那么骑摩托车就会很简单,学会了C语言之后,学习其他语言也会很简单,这就是人类学习具有举一反三的能力,那么机器是否也可以具有举一反三的学习能力呢?
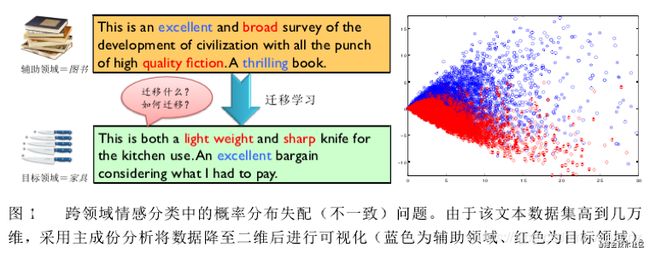
上图是一个商品评论情感分析的例子,图中包含两个不同的产品领域:books 图书领域和 furniture 家具领域;在图书领域,通常用“broad”、“quality fiction”等词汇来表达正面情感,而在家具领域中却由“sharp”、“light weight”等词汇来表达正面情感。可见此任务中,不同领域的不同情感词多数不发生重叠、存在领域独享词、且词汇在不同领域出现的频率显著不同,因此会导致领域间的概率分布失配问题。
迁移学习的关键点:
- 研究可以用哪些知识在不同的领域或者任务中进行迁移学习,即不同领域之间有哪些共有知识可以迁移。
- 研究在找到了迁移对象之后,针对具体问题所采用哪种迁移学习的特定算法,即如何设计出合适的算法来提取和迁移共有知识。
- 研究什么情况下适合迁移,迁移技巧是否适合具体应用,其中涉及到负迁移的问题。(负迁移是旧知识对新知识学习的阻碍作用,比如学习了三轮车之后对骑自行车的影响,和学习汉语拼音对学英文字母的影响研究如何利用正迁移,避免负迁移)
已有的迁移学习方法大致可以分为三类:
- 基于样本的迁移学习方法
- 基于特征的迁移学习方法
- 基于模型的迁移学习方法
以下分别介绍上述三种类型的迁移学习方法: - 基于样本的迁移学习方法
核心思想: 从源域数据集中筛选出部分数据,使得筛选出的部分数据与目标数据概率分布近似。
基于样本选择的方法:假设源域与目标域样本条件分布不同但边缘分布相似,可以根据基于距离度量的方法和基于元学习的方法等方法进行样本选择。
基于样本权重的方法:假设源域与目标域样本条件分布相似但边缘分布不同,通过概率密度比指导样本权重学习。
-
基于特征的迁移学习方法
基于最大均值差异(MMD)的迁移学习方法:将源域与目标域样本映射到可再生和希尔特空间(RKHS),并最小化二者之间的差异。 -
基于模型的迁移学习方法(深度学习)
深度神经网络浅层学习通用特征,深层学习与任务相关的特殊特征。
神经网络迁移性总结:
- 神经网络的前几层基本都是通用特征,迁移的效果比较好
- 深度迁移网络中加入微调,效果提升比较大,可能会比原网络效果好
- 微调可以比较好的克服数据之间的差异性
- 深度迁移网络要比随机初始化权重效果好
- 网络层数的迁移可以加速网络的学习和优化
无监督学习
定义: 我们不知道数据集中数据、特征之间的关系,而是要根据聚类或一定的模型得到数据之间的关系。
可以这么说,比起监督学习,无监督学习更像是自学,让机器学会自己做事情,是没有标签(label)的。
无监督学习使我们能够在几乎不知道或根本不知道结果应该是什么样子的情况下解决问题。我们可以从不需要知道变量影响的数据中得到结构。我们可以根据数据中变量之间的关系对数据进行聚类,从而得到这种结构。在无监督学习中,没有基于预测结果的反馈。
经典算法:聚类K-means算法(K均值算法),主成分分析
监督学习中的结构化学习
structured learning 中让机器输出的是要有结构性的。
在分类的问题中,机器输出的只是一个选项;在有结构的类的问题里面,机器要输出的是一个复杂的物件。
在语音识别的情境下,机器的输入是一个声音信号,输出是一个句子;句子是由许多词汇拼凑而成,它是一个有结构性的object
机器翻译、人脸识别(标出不同的人的名称),比如GAN也是structured Learning的一种方法。
强化学习
定义: 强化学习是机器学习的一个重要分支,是多学科多领域交叉的一个产物,它的本质是解决 decision making 问题,即自动进行决策,并且可以做连续决策。
它主要包含四个元素:agent,环境状态,行动,奖励
强化学习的目标就是获得最多的累计奖励。
强化学习和监督式学习的区别:
- 监督式学习就好比在学习的时候有老师在指导老师怎么是对的怎么是错的,但在很多实际问题中,例如:西洋棋、围棋有几千万种博弈方式的情况,不可能有一个老师知道所有可能的结果。然而强化学习会在没有任何标签的情况下,通过先尝试做出一些行为得到一个结果,通过这个结果是对还是错的反馈,调整之前的行为,就这样不断的调整,算法能够学习到在什么样的情况下选择什么样的行为可以得到最好的结果。
- 两种学习方式都会学习出输入到输出的一个映射,监督式学习出的是之间的关系,可以告诉算法什么样的输入对应着什么样的输出,强化学习出的是给机器的反馈,即用来判断这个行为是好是坏。
- 另外强化学习的结果反馈有延时,有时候可能需要走了很多步以后才知道以前的某一步的选择是好还是坏,而监督学习做了比较坏的选择会立刻反馈给算法。而且强化学习面对的输入总是在变化,每当算法做出一个行为,它影响下一次决策的输入,而监督学习的输入是独立同分布的。
- 通过强化学习,一个 agent 可以在探索和开发(exploration and exploitation)之间做权衡,并且选择一个最大的回报。exploration 会尝试很多不同的事情,看它们是否比以前尝试过的更好。exploitation 会尝试过去经验中最有效的行为。一般的监督学习算法不考虑这种平衡。
强化学习和非监督式学习的区别:
非监督式不是学习输入到输出的映射,而是模式。例如在向用户推荐新闻文章的任务中,非监督式会找到用户先前已经阅读过类似的文章并向他们推荐其一。而强化学习将通过向用户先推荐少量的新闻,并不断获得来自用户的反馈,最后构建用户可能会喜欢的文章的“知识图”。
主要算法和分类
从强化学习的几个元素的角度划分的话,方法主要有下面几类:
- Policy based, 关注点是找到最优策略。
- Value based, 关注点是找到最优奖励总和。
- Action based, 关注点是每一步的最优行动。
2-为什么要学习机器学习
机器学习可以更快且自动的产生模型,以分析更大,更复杂的数据,而且传输更加迅速,结果更加精准——甚至是在非常大的规模中。在现实中无人类干涉时,高价值的预测可以产生更好的决定,和更明智的行为。
参考链接:
- 链接:https://www.zhihu.com/question/57770020/answer/249708509
- 链接:https://www.zhihu.com/question/57770020/answer/542298413
- 链接:https://www.jianshu.com/p/682c88cee5a8
- 链接:https://blog.csdn.net/ice110956/article/details/13775071
- 链接:https://blog.csdn.net/dakenz/article/details/85954548
- 链接:https://blog.csdn.net/mayou32215201/article/details/117923954