首先,造成这个问题的 BUG RocketMQ 官方已经在 3月16号 的这个提交中修复了,这里只是探讨一下在修复之前造成问题的具体细节,更多的上下文可以参考我之前写的 《RocketMQ Consumer 启动时都干了些啥?》 ,这篇文章讲解了 RocketMQ 的 Consumer 启动之后都做了哪些操作,对理解本次要讲解的 BUG 有一定的帮助。
其中讲到了:
 消息堆积
消息堆积
重复消费自不必说,你 ClientID 都相同了。本篇着重聊聊为什么会消息堆积。
文章中讲到,初始化 Consumer 时,会初始化 Rebalance 的策略。你可以大致将 Rebalance 策略理解为如何将一个 Topic 下的 m 个 MessageQueue 分配给一个 ConsumerGroup 下的 n 个 Consumer 实例的策略,看着有些绕,其实就长这样:
 rebalance策略
rebalance策略
而从 Consumer 初始化的源码中可以看出,默认情况下 Consumer 采取的 Rebalance 策略是 AllocateMessageQueueAverage()。
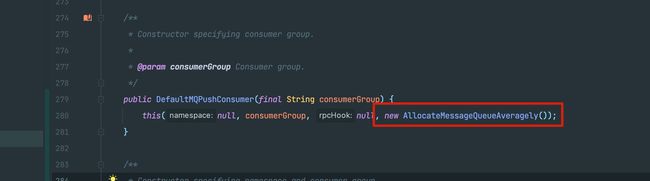 默认的 Rebalance 策略
默认的 Rebalance 策略
默认的策略很好理解,将 MessageQueue 平均的分配给 Consumer。举个例子,假设有 8 个 MessageQueue,2 个 Consumer,那么每个 Consumer 就会被分配到 4 个 MessageQueue。
那如果分配不均匀怎么办?例如只有 7 个 MessageQueue,但是 Consumer 仍然是 2 个。此时 RocketMQ 会将多出来的部分,对已经排好序的 Consumer 再做平均分配,一个一个分发给 Consumer,直到分发完。例如刚刚说的 7 个 MessageQueue 和 2 个 ConsumerGroup 这种 case,排在第一个的 Consumer 就会被分配到 4 个 MessageQueue,而第二个会被分配到 3 个 MessageQueue。
大家可以先理解一下 AllocateMessageQueueAveragely 的实现,作为默认的 Rebalance 的策略,其实现位于这里:
接下来我们看看,AllocateMessageQueueAveragely 内部具体都做了哪些事情。
其核心其实就是实现的 AllocateMessageQueueStrategy 接口中的 allocate 方法。实际上,RocketMQ 对该接口总共有 5 种实现:
- AllocateMachineRoomNearby
- AllocateMessageQueueAveragely
- AllocateMessageQueueAveragelyByCircle
- AllocateMessageQueueByConfig
- AllocateMessageQueueByMachineRoom
- AllocateMessageQueueConsistentHash
其默认的 AllocateMessageQueueAveragely 只是其中的一种实现而已,那执行 allocate 它需要什么参数呢?
 入参
入参
需要以下四个:
- ConsumerGroup 消费者组的名字
- currentCID 当前消费者的 clientID
- mqAll 当前 ConsumerGroup 所消费的 Topic 下的所有的 MessageQueue
- cidAll 当前 ConsumerGroup 下所有消费者的 ClientID
实际上是将某个 Topic 下的所有 MessageQueue 分配给属于同一个消费者的所有消费者实例,粒度是 By Topic 的。
所以到这里剩下的事情就很简单了,无非就是怎么样把这一堆 MessageQueue 分配给这一堆 Consumer。这个怎么样,就对应了 AllocateMessageQueueStrategy 的不同实现。
接下来我们就来看看 AllocateMessageQueueAveragely 是如何对 MessageQueue 进行分配的,之前讲源码我一般都会一步一步的来,结合源码跟图,但是这个源码太短了,我就直接先给出来吧。
public List allocate(String consumerGroup, String currentCID, List mqAll, List cidAll) {
if (currentCID == null || currentCID.length() < 1) {
throw new IllegalArgumentException("currentCID is empty");
}
if (mqAll == null || mqAll.isEmpty()) {
throw new IllegalArgumentException("mqAll is null or mqAll empty");
}
if (cidAll == null || cidAll.isEmpty()) {
throw new IllegalArgumentException("cidAll is null or cidAll empty");
}
List result = new ArrayList();
// 判断一下当前的客户端是否在 cidAll 的集合当中
if (!cidAll.contains(currentCID)) {
log.info("[BUG] ConsumerGroup: {} The consumerId: {} not in cidAll: {}",
consumerGroup,
currentCID,
cidAll);
return result;
}
// 拿到当前消费者在所有的消费者实例数组中的位置
int index = cidAll.indexOf(currentCID);
// 用 messageQueue 的数量 对 消费者实例的数量取余数, 这个实际上就把不够均匀分的 MessageQueue 的数量算出来了
// 举个例子, 12 个 MessageQueue, 有 5 个 Consumer, 12 % 5 = 2
int mod = mqAll.size() % cidAll.size();
int averageSize =
mqAll.size() <= cidAll.size() ? 1 : (mod > 0 && index < mod ? mqAll.size() / cidAll.size() + 1 : mqAll.size() / cidAll.size());
int startIndex = (mod > 0 && index < mod) ? index * averageSize : index * averageSize + mod;
int range = Math.min(averageSize, mqAll.size() - startIndex);
for (int i = 0; i < range; i++) {
result.add(mqAll.get((startIndex + i) % mqAll.size()));
}
return result;
}
其实前半部分都是些常规的 check,可以忽略不看,从这里:
int index = cidAll.indexOf(currentCID);
开始,才是核心逻辑。为了避免逻辑混乱,还是假设有 12 个 MessageQueue,5 个 Consumer,同时假设 index=0 。
那么 mod 的值就为 12 % 5 = 2 了。
而 averageSize 的值,稍微有点绕。如果 MessageQueue 的数量比消费者的数量还少,那么就为 1 ;否则,就走这一堆逻辑(mod > 0 && index < mod ? mqAll.size() / cidAll.size() + 1 : mqAll.size() / cidAll.size())。我们 index 是 0,而 mod 是 2,index < mod 则是成立的,那么最终 averageSize 的值就为 12 / 5 + 1 = 3。
接下来是 startIndex,由于这个三元运算符的条件是成立的,所以其值为 0 * 3 ,就为 0。
看了一大堆逻辑,是不是已经晕了?直接举实例:
12 个 Message Queue
5 个 Consumer 实例
按照上面的分法:
排在第 1 的消费者 分到 3 个
排在第 2 的消费者 分到 3 个
排在第 3 的消费者 分到 2 个
排在第 4 的消费者 分到 2 个
排在第 5 的消费者 分到 2 个
 具体分配流程
具体分配流程
所以,你可以大致认为:
先“均分”,12 / 5 取整为 2。然后“均分”完之后还剩下 2 个,那么就从上往下,挨个再分配,这样第 1、第 2 个消费者就会被多分到 1 个。
所以如果有 13 个 MessageQueue,5 个 Consumer,那么第 1、第 2、第 3 就会被分配 3 个。
但并不准确,因为分配的 MessageQueue 是一次性的,例如那 3 个 MessageQueue 是一次性获取的,不会先给 2 个,再给 1 个。
而我们开篇提到的 Consumer 的 ClientID 相同,会造成什么?
当然是 index 的值相同,进而造成 mod、averageSize、startIndex、range 全部相同。那么最后 result.add(mqAll.get((startIndex + i) % mqAll.size())); 时,本来不同的 Consumer,会取到相同的 MessageQueue(举个例子,Consumer 1 和 Consumer 2 都取到了前 3 个 MessageQueue),从而造成有些 MessageQueue(如果有的话) 没有 Consumer 对其消费,而没有被消费,消息也在不停的投递进来,就会造成消息的大量堆积。
当然,现在的新版本从代码上看已经修复这个问题了,这个只是对之前的版本的原因做一个探索。
本篇文章已放到我的 Github github.com/sh-blog 中,欢迎 Star。微信搜索关注【SH的全栈笔记】,回复【队列】获取MQ学习资料,包含基础概念解析和RocketMQ详细的源码解析,持续更新中。
如果你觉得这篇文章对你有帮助,还麻烦点个赞,关个注,分个享,留个言。
