PyTorch——线性回归的从零开始实现
PyTorch——线性回归的从零开始实现
-
- 一、生成数据集
- 二、读取数据
- 三、初始化模型参数
- 四、定义模型
- 五、定义损失函数
- 六、定义优化算法
- 七、训练模型
- 附1:损失函数曲线
本文是学习《动手学深度学习(pytorch)》“3.2 线性回归的从零开始实现” 的笔记,具体解释请参考原文。
一、生成数据集
构造一个简单的人工训练数据集。
设训练数据集样本数为1000,输入个数(特征数)为2。线性回归模型的真实权重 w=[2,−3.4](转置) 和偏差 b=4.2,以及一个随机噪声项 ϵ 来生成标签。
公式为:labels = w * features + b + ϵ
其中,噪声项 ϵ服从均值为0、标准差为0.01的正态分布。噪声代表了数据集中无意义的干扰。
# 1 生成数据集
num_inputs = 2
num_examples = 1000
true_w = [2, -3.4]
#true_w = torch.tensor([[2],[-3.4]])
true_b = 4.2
features = torch.normal(0, 1, (num_examples, num_inputs))
labels = true_w[0] * features[:,0] + true_w[1] * features[:,1] + true_b
#labels = torch.mm(true_w, features) + true_b
labels += torch.normal(0, 0.01, labels.size())
注意,features的每一行是一个长度为2的向量,而labels的每一行是一个长度为1的向量(标量)。
原文中,画出了 features 和 labels 的散点图。
labels 有两种求法,一种是自己实现矩阵乘法,一种是使用torch.mm()函数:
(1)自己实现矩阵乘法:得到的 labels 是一个向量。
(2)使用torch.mm()函数 :得到的 labels 是一个矩阵。
【订正】下面图片中 第三行 labels 多加了一遍!!!对照 labels2 改正即可。
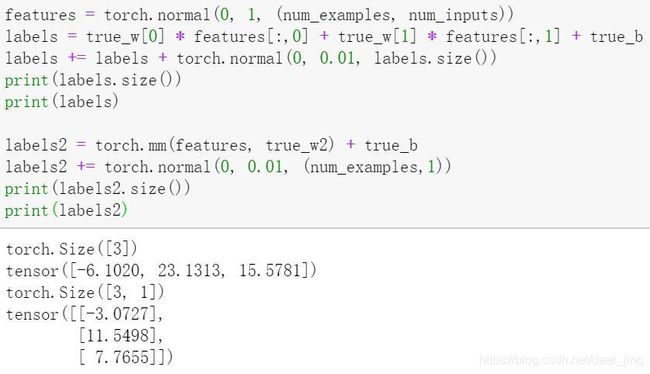
原因可能是:
(1000,2)×(2,1)在torch.mm()函数的结果是(1000,1)。
torch.mm() 中的 ture_w 需要是(2,1)的 tensor 类型,否则函数会报错。
二、读取数据
在训练模型的时候,我们需要遍历数据集并不断读取小批量数据样本。这里我们定义一个函数:它每次返回batch_size(批量大小)个随机样本的特征和标签。
# 2 读取数据
# 定义“取小批量数据样本”函数
def data_iter(batch_size, features, labels):
num_examples = len(features)
indicies = list(range(num_examples))
random.shuffle(indicies)
for i in range(0, num_examples, batch_size):
j = torch.tensor(indicies[i: min(i+batch_size, num_examples)])
yield features.index_select(0, j), labels.index_select(0, j)
(1)min(i+batch_size, num_examples) :最后一次可能不足一个batch
(2)函数返回值用 yield 还是 return?
考虑到这里是想通过函数data_iter(batch_size, features, labels)来不断地生成小批量数据,因此只能使用yield。
参考:python 中 return VS yield
三、初始化模型参数
# 3 初始化模型参数
# 权重、偏差
weights = torch.normal(0, 0.01, (num_inputs, 1))
bias = torch.zeros(1)
weights.requires_grad_(requires_grad=True)
bias.requires_grad_(requires_grad=True)
之后的模型训练中,需要对这些参数求梯度来迭代参数的值,因此我们要让它们的requires_grad=True(默认为False)。
四、定义模型
# 4 定义模型
def linreg(X, weights, bias):
return weights[0] * X[:,0] + weights[1] * X[:,1] + bias
#return torch.mm(X, weights) + bias
矩阵运算要保持一致(如果使用方法一生成的 labels ,模型中也应该使用方法一计算y_hat值)如果不一致,以 “使用方法二生成 labels ,模型中使用方法一计算 y_hat 值” 为例:
生成的 labels 大小为(1000,1),使用模型计算出的 y_hat 大小为 1000,由于 labels(tensor类型) 的广播机制,labels - y_hat 的大小为 (3,3),这样,在计算损失函数的时候,结果是错误的。
a = torch.tensor([[1],[2],[3]])
b = torch.tensor([1,2,3])
print(a.shape)
print(b.shape)
c = a - b
print(c.shape)
print(c)

如果不想这么麻烦,可以在损失函数中使用 view() 函数。
五、定义损失函数
# 5 定义损失函数
def loss(y, y_hat):
return (y - y_hat) ** 2
#return (y_hat - y.view(y_hat.size())) ** 2 / 2
使用return (y_hat - y.view(y_hat.size())) ** 2 / 2 语句,就可以不用管 labels 和 y_hat 计算方法是否一样了。
a = torch.tensor([[1],[2],[3]])
b = torch.tensor([1,2,3])
print(a.shape)
print(b.shape)
d = b.view(a.size())
print(d)
c = a - d
print(c.shape)
print(c)

六、定义优化算法
以下函数实现了小批量随机梯度下降算法,它通过不断迭代模型参数来优化损失函数。这里自动求梯度模块计算得来的梯度是一个批量样本的梯度和,将它除以批量大小来得到平均值。
# 6 定义优化算法
def optim(params, lr, batch_size):
for param in params:
param.data -= lr * param.grad / batch_size
七、训练模型
一定要记得 .sum()
# 7 训练模型
batch_size = 10
lr = 0.01
epoch = 10
Loss_list = []#保存每次迭代的误差,画图用
for i in range(epoch):
for X, y in data_iter(batch_size, features, labels):
y_hat = linreg(X, weights, bias)
l = loss(y, y_hat).sum()
l.backward()
optim([weights, bias], lr, batch_size)
#梯度清零
weights.grad.fill_(0)
bias.grad.fill_(0)
train_l = loss(linreg(features, weights, bias), labels)
print('epoch %d, loss %f' % (i + 1, train_l.mean().item()))
Loss_list.append(l / len(features))
#epoch 1, loss 0.329409
#epoch 2, loss 0.007091
#epoch 3, loss 0.000208
#epoch 4, loss 0.000056
#epoch 5, loss 0.000052
#epoch 6, loss 0.000052
#epoch 7, loss 0.000052
#epoch 8, loss 0.000052
#epoch 9, loss 0.000052
#epoch 10, loss 0.000052
print(weights)
print(bias)
#tensor([[ 2.0001],
# [-3.3998]], requires_grad=True)
#tensor([4.1998], requires_grad=True)
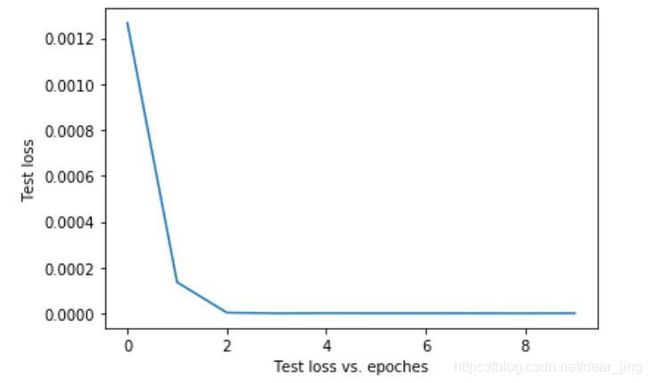
附1:损失函数曲线
# 画图
x = range(0, epoch)
y = Loss_list
plt.plot(x, y)
plt.xlabel('Test loss vs. epoches')
plt.ylabel('Test loss')
plt.show()