基于CRNN+CTC的改进图像文本识别算法
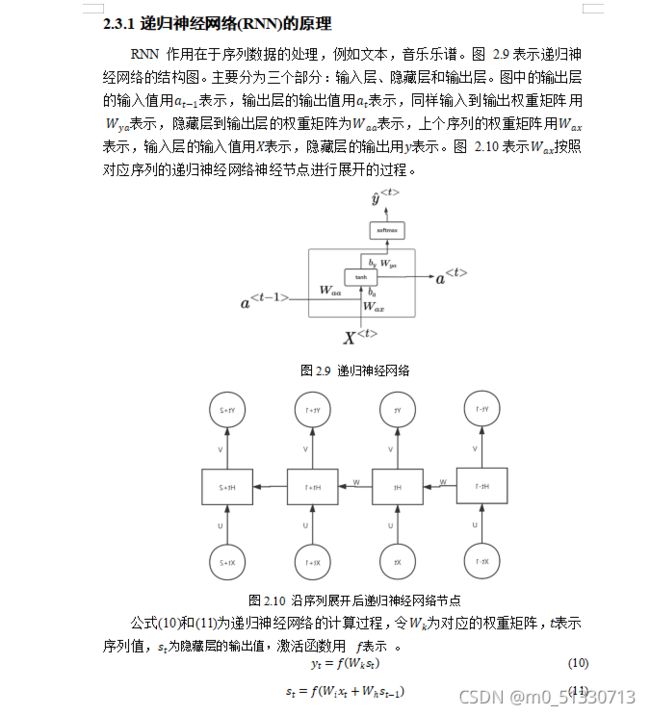
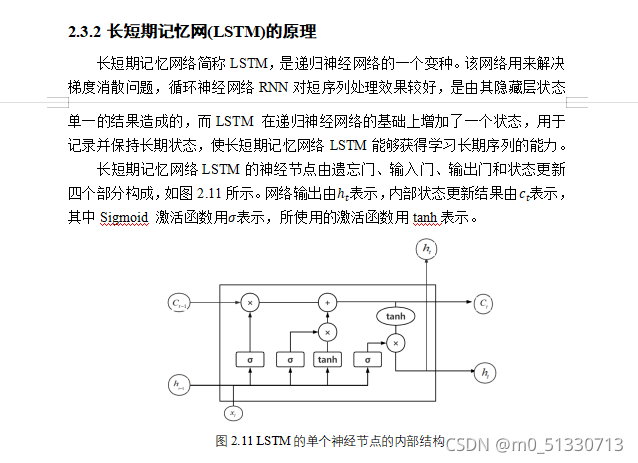
上一次介绍了基于改进EAST(An Efficient and Accurate Scene Text Detector)算法的文本定位算法这次我来介绍基于卷积循环神经网络CRNN (Convolutional Recurrent Neural Network)的图像文本的识别算法进行研究。我们首先来看是利用PaddlePaddle实现的CRNN文字识别。以下是摘取了部分代码(CRNN网络模型)。
# CRNN网络模型
#################### 自己写的代码这里开始 ###################
class CRNN(object):
def __init__(self,
num_classes, # 类别数量
label_dict): # 标签字典
self.outputs = None # 输出
self.label_dict = label_dict # 标签字典
self.num_classes = num_classes # 类别数量
def name(self):
return "crnn"
def conv_bn_pool(self, input, group, # 输入,组
out_ch, # 输入通道数
act="relu", # 激活函数
param=None, bias=None, # 参数、权重初始值
param_0=None, is_test=False,
pooling=True, # 是否执行池化
use_cudnn=False): # 是否对cuda加速
tmp = input
for i in six.moves.xrange(group):
# for i in range(group): # 也可以
# 卷积层
tmp = fluid.layers.conv2d(
input=tmp, # 输入
num_filters=out_ch[i], # num_filters (int) - 滤波器(卷积核)的个数。和输出图像通道相同。
filter_size=3,##滤波器大小
padding=1,##填充大小
param_attr=param if param_0 is None else param_0,##指定权重参数属性的对象
act=None,
use_cudnn=use_cudnn)
# 批量归一化
tmp = fluid.layers.batch_norm(
input=tmp, # 前面卷基层输出作为输入
act=act, # 激活函数
param_attr=param, # 参数初始值
bias_attr=bias, # 偏置初始值
is_test=is_test) # 测试模型
# 根据传入的参数决定是否做池化操作
if pooling:
tmp = fluid.layers.pool2d(
input=tmp, # 前一层的输出作为输入
pool_size=2, # 池化区域
pool_type="max", # 池化类型
pool_stride=2, # 步长
use_cudnn=use_cudnn,
ceil_mode=True) # 输出高度计算公式
return tmp
# 包含4个卷积层操作
def ocr_convs(self, input,
regularizer=None, # 正则化
gradient_clip=None, # 梯度裁剪,防止梯度过大
is_test=False, use_cudnn=False):
###创建一个参数属性对象,用户可设置参数的名称、初始化方式、学习率、正则化规则、是否需要训练、梯度裁剪方式、是否做模型平均等属性。
b = fluid.ParamAttr(
regularizer=regularizer,
gradient_clip=gradient_clip,
initializer=fluid.initializer.Normal(0.0, 0.0))
w0 = fluid.ParamAttr(
regularizer=regularizer,
gradient_clip=gradient_clip,
initializer=fluid.initializer.Normal(0.0, 0.0005))
w1 = fluid.ParamAttr(
regularizer=regularizer,
gradient_clip=gradient_clip,
initializer=fluid.initializer.Normal(0.0, 0.01))
tmp = input
# 第一组卷积池化
tmp = self.conv_bn_pool(tmp,
2, [16, 16], # 组数量及卷积核数量
param=w1,
bias=b,
param_0=w0,
is_test=is_test,
use_cudnn=use_cudnn)
# 第二组卷积池化
tmp = self.conv_bn_pool(tmp,
2, [32, 32], # 组数量及卷积核数量
param=w1,
bias=b,
is_test=is_test,
use_cudnn=use_cudnn)
# 第三组卷积池化
tmp = self.conv_bn_pool(tmp,
2, [64, 64], # 组数量及卷积核数量
param=w1,
bias=b,
is_test=is_test,
use_cudnn=use_cudnn)
# 第四组卷积池化
tmp = self.conv_bn_pool(tmp,
2, [128, 128], # 组数量及卷积核数量
param=w1,
bias=b,
is_test=is_test,
pooling=False, # 不做池化
use_cudnn=use_cudnn)
return tmp
# 组网
def net(self, images,
rnn_hidden_size=200, # 隐藏层输出值数量
regularizer=None, # 正则化
gradient_clip=None, # 梯度裁剪,防止梯度过大
is_test=False,
use_cudnn=True):
# 卷积池化
conv_features = self.ocr_convs(
images,
regularizer=regularizer,
gradient_clip=gradient_clip,
is_test=is_test,
use_cudnn=use_cudnn)
# 将特征图转为序列
sliced_feature = fluid.layers.im2sequence(
input=conv_features, # 卷积得到的特征图作为输入
stride=[1, 1],
# 卷积核大小(高度等于原高度,宽度1)
filter_size=[conv_features.shape[2], 1])
# 两个全连接层
para_attr = fluid.ParamAttr(
regularizer=regularizer, # 正则化
gradient_clip=gradient_clip,
initializer=fluid.initializer.Normal(0.0, 0.02))
bias_attr = fluid.ParamAttr(
regularizer=regularizer, # 正则化
gradient_clip=gradient_clip,
initializer=fluid.initializer.Normal(0.0, 0.02))
bias_attr_nobias = fluid.ParamAttr(
regularizer=regularizer, # 正则化
gradient_clip=gradient_clip,
initializer=fluid.initializer.Normal(0.0, 0.02))
fc_1 = fluid.layers.fc(
input=sliced_feature, # 序列化处理的特征图
size=rnn_hidden_size * 3,
param_attr=para_attr,
bias_attr=bias_attr_nobias)
fc_2 = fluid.layers.fc(
input=sliced_feature, # 序列化处理的特征图
size=rnn_hidden_size * 3,
param_attr=para_attr,
bias_attr=bias_attr_nobias)
# 双向GRU(门控循环单元,LSTM变种, LSTM是RNN变种)
gru_foward = fluid.layers.dynamic_gru(
input=fc_1,
size=rnn_hidden_size,
param_attr=para_attr,
bias_attr=bias_attr,
candidate_activation="relu")
gru_backward = fluid.layers.dynamic_gru(
input=fc_2,
size=rnn_hidden_size,
is_reverse=True, # 反向循环神经网络
param_attr=para_attr,
bias_attr=bias_attr,
candidate_activation="relu")
# 输出层
w_attr = fluid.ParamAttr(
regularizer=regularizer,
gradient_clip=gradient_clip,
initializer=fluid.initializer.Normal(0.0, 0.02))
b_attr = fluid.ParamAttr(
regularizer=regularizer,
gradient_clip=gradient_clip,
initializer=fluid.initializer.Normal(0.0, 0.0))
fc_out = fluid.layers.fc(
input=[gru_foward, gru_backward], # 双向RNN输出作为输入
size=self.num_classes + 1, # 输出类别
param_attr=w_attr,
bias_attr=b_attr)
self.outputs = fc_out
return fc_out
def get_infer(self):
# 将CRNN网络输出交给CTC层转录(纠错、去重)
return fluid.layers.ctc_greedy_decoder(
input=self.outputs, # 输入为CRNN网络输出
blank=self.num_classes)
################### 自己编写代码结束 ####################在CRNN网络结构中增加了可变尺度机制,使用滑动窗口和步长来动态的提取图像不同大小的卷积特征, 最后使用池化函数将卷积特征对应的二维矩阵转化为相同尺度。这是创新之一。
CRNN基本网络结构
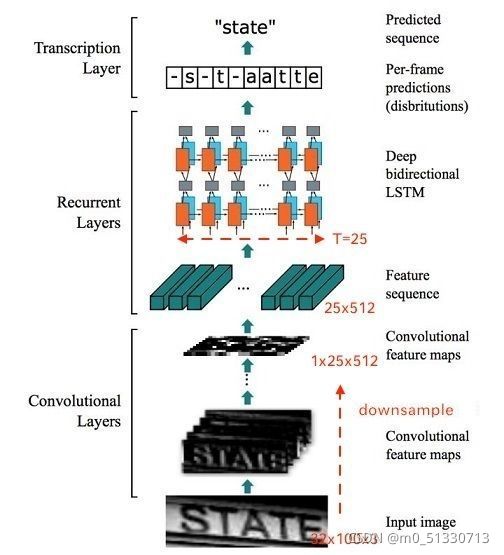
整个CRNN网络可以分为三个部分:
假设输入图像大小为 ![]() ,注意提及图像都是
,注意提及图像都是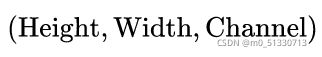 形式。
形式。
- Convlutional Layers
这里的卷积层就是一个普通的CNN网络,用于提取输入图像的Convolutional feature maps,即将大小为![]() 的图像转换为
的图像转换为![]() 大小的卷积特征矩阵,网络细节请参考给出的实现代码(对应TensorFlow 1.15实现代码)。
大小的卷积特征矩阵,网络细节请参考给出的实现代码(对应TensorFlow 1.15实现代码)。
- Recurrent Layers
这里的循环网络层是一个深层双向LSTM网络,在卷积特征的基础上继续提取文字序列特征。
所谓深层RNN网络,是指超过两层的RNN网络。对于单层双向RNN网络,结构如下:
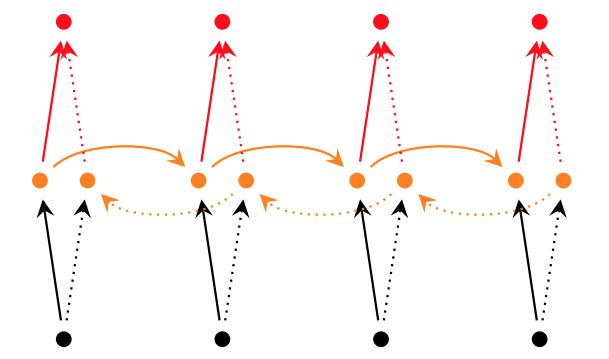
图5 单层双向RNN网络
而对于深层双向RNN网络,主要有2种不同的实现:
tf.nn.bidirectional_dynamic_rnn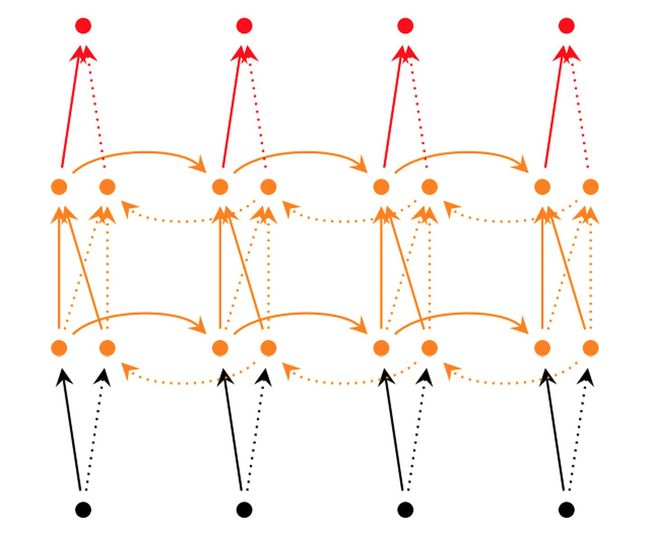
图6 深层双向RNN网络
tf.contrib.rnn.stack_bidirectional_dynamic_rnn
图7 stack形深层双向RNN网络
在CRNN中显然使用了第二种stack形深层双向结构。
由于CNN输出的Feature map是大小,所以对于RNN最大时间长度 T=25 (即有25个时间输入,每个输入 列向量有 )。
- Transcription Layers
将RNN输出做softmax后,为字符输出。
关于代码中输入图片大小的解释:
在本文给出的实现中,为了将特征输入到Recurrent Layers,做如下处理:
- 首先会将图像在固定长宽比的情况下缩放到
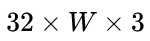 大小( W 代表任意宽度)
大小( W 代表任意宽度) - 然后经过CNN后变为
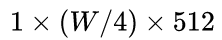
- 针对LSTM设置
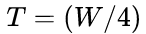 ,即可将特征输入LSTM。
,即可将特征输入LSTM。
所以在处理输入图像的时候,建议在保持长宽比的情况下将高缩放到32 ,这样能够尽量不破坏图像中的文本细节(当然也可以将输入图像缩放到固定宽度,但是这样由于破坏文本的形状,肯定会造成性能下降)。
CTC编程接口
在Tensorflow中官方实现了CTC接口:
tf.nn.ctc_loss(
labels,
inputs,
sequence_length,
preprocess_collapse_repeated=False,
ctc_merge_repeated=True,
ignore_longer_outputs_than_inputs=False,
time_major=True
)在Pytorch中需要使用针对框架编译的warp-ctc:https://github.com/SeanNaren/warp-ctc
2020.4更新,目前Pytorch已经有CTC接口:
torch.nn.CTCLoss(blank=0,reduction='mean',zero_infinity=False)CTC总结
CTC是一种Loss计算方法,用CTC代替Softmax Loss,训练样本无需对齐。CTC特点:
- 引入blank字符,解决有些位置没有字符的问题
- 通过递推,快速计算梯度
看到这里你也应该大致了解MFCC+CTC在语音识别中的应用了(图17来源)。

图17 MFCC+CTC在语音识别中的应用
CRNN+CTC总结
这篇文章的核心,就是将CNN/LSTM/CTC三种方法结合:
- 首先CNN提取图像卷积特征
- 然后LSTM进一步提取图像卷积特征中的序列特征
- 最后引入CTC解决训练时字符无法对齐的问题
即提供了一种end2end文字图片识别算法,也算是方向的简单入门。
特别说明
一般情况下对一张图像中的文字进行识别需要以下步骤
- 定位文稿中的图片,表格,文字区域,区分文字段落(版面分析)
- 进行文本行识别(识别)
- 使用NLP相关算法对文字识别结果进行矫正(后处理)
下面是关于CRNN的运用
基于CRNN及可变尺度图像文本识别算法具体的训练流程如下所示:(1)使用CRNN 神经网络算法对ICPR MTWI 2018 图像文本数据集进行训练;(2)保存训练好的模型;(3)加载预训练模型,修改卷积层部分神经网络参数,使网络自适应单通道到RGB三通道的变化;(4)在循环层中加入可变尺度机制,初始化特征序列的权重参数;(5)将标注好的图像数据集划分为训练集和测试集,将训练集输入预训练模型当中,优化参数,并开始训练。(6)保存带有可变尺度机制的权重参数,并再次保存模型。(7)使用数据集中的测试集对训练完成的模型进行测试。
利用改进的基于CRNN及可变尺度机制的图像识别网络进行文本识别,在大多数情况下能够准确的识别出每张图像中的位置名称,例如城市,乡镇的名称信息。但是会存在一些易混淆的字符难以正确识别,需要根据相应的地理信息词库来进行匹配校对。因此本文设计了一种位置名称匹配算法来对识别错误的地名来进行校正。利用地图上的位置信息固定这一先验知识,从数据库中找到同一区域所有类似地名,数据库存放了地质图像上存在的所有的地点名称,然后在这些地名里查找和神经网络识别出来的结果匹配度最高的结果作为最终结果。步骤如下:

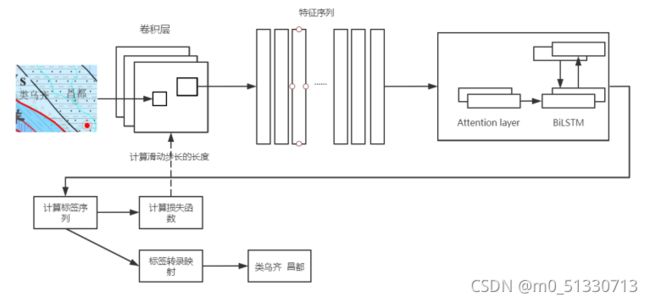
以上是卷积循环神经网络及可变尺度机制的栅格地质图像文本识别网络算法结构图。包括卷积层参数修改,有效特征序列提取,双向LSTM神经网络,以及标签转录映射和端到端的文本识别结果的输出。
过一段时间我会整理出所有代码上传。
以下是对于RNN和LSTM的简单介绍。