使用Python基于VGG/CTPN/CRNN的自然场景文字方向检测/区域检测/不定长OCR识别
GitHub:https://github.com/pengcao/chinese_ocr https://github.com/xiaofengShi/CHINESE-OCR
|-angle 基于VGG分类模型的文字方向检测预测 |-bash 环境安装 |----setup-python3.sh 安装python3环境 |----setup-python3-cpu.sh 安装CPU环境 |----setup-python3-gpu.sh 安装CPU环境 |-crnn |-ctpn 基于CTPN模型的文本区域检测模型训练及预测 |-model |----modelAngle.h5 文字方向检测VGG模型 |----my_model_keras.h5 文本识别CRNN模型 |-ocr 基于CRNN的文本识别模型预测 |-result 预测图片 |-test 测试图片 |-train 基于CRNN的文本识别模型训练
环境要求:
python3.6 tensorflow1.7-cpu/gpu graphviz pydot (py)torch torchvision
- 卸载旧版本的pytorch和torchvision
pip uninstall torchvision pip uninstall torch
- 安装pytorch
1)Anaconda搜索torch
2)选择标记处点开
3)Anaconda Prompt - conda install -c peterjc123 pytorch
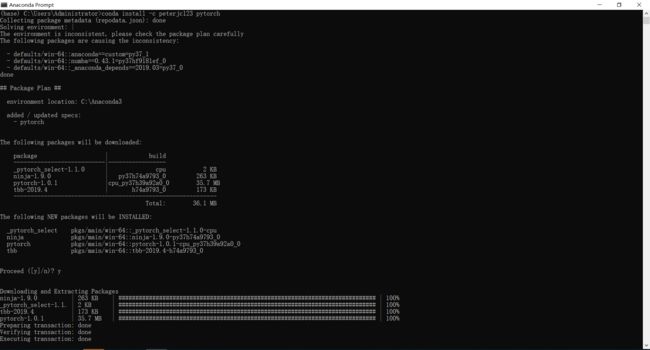
- 安装torchvision
conda install torchvision -c pytorch # TorchVision requires PyTorch 1.1 or newer
离线安装pytorch 1).whl安装
从pytorch官网https://pytorch.org/previous-versions/下载合适版本torch及torchvision的whl
# 直接对whl文件进行编译即可 pip install torch-0.4.0-cp36-cp36m-linux_x86_64.whl pip install torchvision-0.2.1-py2.py3-none-any.whl
2).tar.gz安装
下载对应版本的.tar.gz文件,并解压
# 进入解压目录,执行安装命令 python setup.py install
离线安装GCC(Tensorflow部分第三方模块需要GCC进行编译,所以在安装第三方的依赖包之前先安装GCC)
从https://pkgs.org/download/gcc下载gcc-4.8.5-28.el7_5.1.x86_64.rpm版本,并且在require部分下载所需要的rpm文件(根据报错缺失的rpm下载)
rpm -ivh gcc-4.8.5-28.el7_5.1.x86_64.rpm # 如果已经有旧的版本会报conflicts with错误 rpm -ivh gcc-4.8.5-28.el7_5.1.x86_64.rpm --force
模型
- 文本方向检测网络 - Classify(vgg16)
- 文本区域检测网络 - CTPN(CNN+RNN) - 支持CPU、GPU环境,一键部署 - 文本检测训练Github:https://github.com/eragonruan/text-detection-ctpn
- EndToEnd文本识别网络 - CRNN(CNN+GRU/LSTM+CTC)
文本方向检测
训练:基于图像分类模型 - VGG16分类模型,训练0、90、180、270度检测的分类模型(angle/predict.py),训练图片8000张,准确率88.23%
模型:https://pan.baidu.com/s/1Sqbnoeh1lCMmtp64XBaK9w(n2v4)
文本区域检测
基于深度学习的文本区域检测方法:http://xiaofengshi.com/2019/01/23/%E6%B7%B1%E5%BA%A6%E5%AD%A6%E4%B9%A0-TextDetection/
CTPN(CNN+RNN)网路结构:
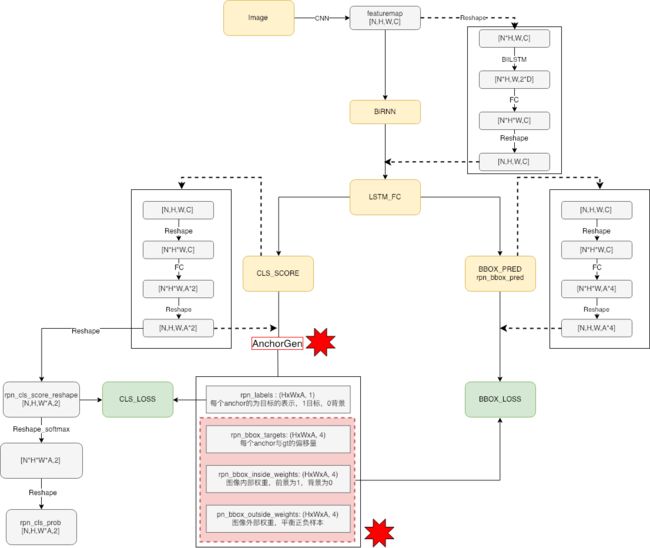
CTPN是一种基于目标检测方法的文本检测模型,在repo的CTPN中anchor的设置为固定宽度,高度不同,相关代码如下:
def generate_anchors(base_size=16, ratios=[0.5, 1, 2],
scales=2 ** np.arange(3, 6)):
heights = [11, 16, 23, 33, 48, 68, 97, 139, 198, 283]
widths = [16]
sizes = []
for h in heights:
for w in widths:
sizes.append((h, w))
return generate_basic_anchors(sizes)
基于这种设置,CTPN只能检测水平方向的文本,如果想要CTPN可以支持垂直文本检测,可以在anchor生成函数上进行修改
对CTPN进行训练:
- 训练脚本 - 定位到路径:./ctpn/ctpn/train_net.py
- 预训练的VGG网络路径[VGG_imagenet.npy]:https://pan.baidu.com/s/1jzrcCr0tX6xAiVoolVRyew(a5ze) - 将预训练权重下载下来,pretrained_model指向该路径即可
- 模型的预训练权重[checkpoint]:https://pan.baidu.com/s/1oS6_kqHgmcunkooTAXE8GA(xmjv)
- CTPN数据集[VOCdevkit.zip]:https://pan.baidu.com/s/1NXFmdP_OgRF42xfHXUhBHQ - 下载解压后将.ctpn/lib/datasets/pascal_voc.py文件中的pascal_voc类中的参数self.devkit_path指向数据集的路径即可
端到端(EndToEnd)文本识别
OCR识别采用GRU+CTC[CRNN(CNN+GRU/LSTM+CTC)]端到端识别技术,实现不分隔识别不定长文字
CTC - CTC算法原理
CTC是一种解码机制,在使用CTPN提取到待检测文本行之后,需要识别提取到的区域内的文本内容,目前广泛存在两种解码机制。
- 一种是Seq2Seq机制,输入的是图像,经过卷积编码之后再使用RNN解码,为了提高识别的准确率,一般会加入Attention机制;
- 另一种就是CTC解码机制,但是对于CTC解码要满足一个前提,那就是输入序列的长度不小于输出序列的长度。CTC主要用于序列解码,不需要对序列中的每个元素进行标记,只需要知道输入序列对应的整个Label是什么即可,针对OCR项目,也就是输入一张图像上面写着“欢迎来到中国”这几个字,只需要是这几个字,而没必要知道这几个字在输入图像中所在的具体位置,实际上如果知道每个字所在的位置,就是单字符识别了,的确会降低任务的复杂多,但是现实中我们没有这么多标记号位置的数据,这个时候CTC就显得很重要了。
对CRNN进行训练:
- keras版本:./train/keras_train/train_batch.py(model_path-指向预训练权重位置,MODEL_PATH-指向模型训练保存的位置)
- pythorch版本:./train/pytorch-train/crnn_main.py
parser.add_argument(
'--crnn',
help="path to crnn (to continue training)",
default=预训练权重的路径)
parser.add_argument(
'--experiment',
help='Where to store samples and models',
default=定义的模型训练的权重保存位置)
模型:
keras模型预训练权重:https://pan.baidu.com/s/14cTCedz1ESnj0mM9ISm__w(1kb9)
pytorch预训练权重:https://pan.baidu.com/s/1kAXKudJLqJbEKfGcJUMVtw(9six)
预测测试
运行predict.predict(demo).py:写入测试图片的路径即可
如果想要显示CTPN的结果,修改文件./ctpn/ctpn/other.py的draw_boxes函数的最后部分,cv2.inwrite('dest_path',img),如此可以得到CTPN检测的文字区域框以及图像的OCR识别结果