2021-02-07 大数据课程笔记 day18

@R星校长
初识 HBase
hbase 介绍
概述
Welcome to Apache HBase™
Apache HBase™ is the Hadoop database, a distributed, scalable, big data store.
Use Apache HBase™ when you need random, realtime read/write access to your Big Data. This project’s goal is the hosting of very large tables – billions of rows X millions of columns – atop clusters of commodity hardware. Apache HBase is an open-source, distributed, versioned, non-relational database modeled after Google’s Bigtable: A Distributed Storage System for Structured Data by Chang et al. Just as Bigtable leverages the distributed data storage provided by the Google File System, Apache HBase provides Bigtable-like capabilities on top of Hadoop and HDFS.
Apache HBase™ 是 Hadoop 数据库,是一个分布式、可伸缩、大数据存储区。
当您需要随机、实时读/写访问大数据时,请使用 Apache HBase™。 该项目的目标是在商用硬件集群之上托管非常大的表----数十亿行X百万列。 Apache HBase 是一个开源的、分布式的、版本化的、非关系的数据库,它参考了Google 的 Bigtable。 正如 Bigtable 利用 Google 文件系统提供的分布式数据存储一样,Apache HBase 在 Hadoop 和 HDFS 之上提供了类似 Bigtable 的功能。
定义:HBase 是 Hadoop Database ,是一个高可靠性、高性能、面向列、可伸缩、实时读写的分布式 NOSQL 数据库。
作用:主要用来存储非结构化、半结构化和结构化的松散数据(列式存储的NoSQL 数据库)
注:MySQL 亿级别的数据,效率极具下降。
tb_order 达到 10 亿条数据,是不是非常慢呢?
阿里又是如何解决的呢。将订单数据横向拆分,平均放到 80 个 MySQL 中:
OrderId.hashCode()%80 来决定数据放到哪个表中。

利用 Hadoop HDFS 作为其文件存储系统,利用 Hadoop MapReduce 来处理 HBase 中的海量数据,利用 Zookeeper 作为其分布式协同服务。正常情况下,HBase 不依赖于 YARN ,用到的时候可以随时开启。从技术上讲,HBase 实际上更像是“数据存储”而不是“数据库”,因为它缺少 RDBMS中的许多功能,例如字段类型,二级索引,触发器和高级查询语言等。
HBase 数据模型
逻辑上,HBase 的数据模型同关系型数据库很类似,数据存储在一张表中,有行有列。但从底层物理存储结构(Key-Value)来看,HBase 更像一个 Map。
HBase 逻辑结构
物理存储结构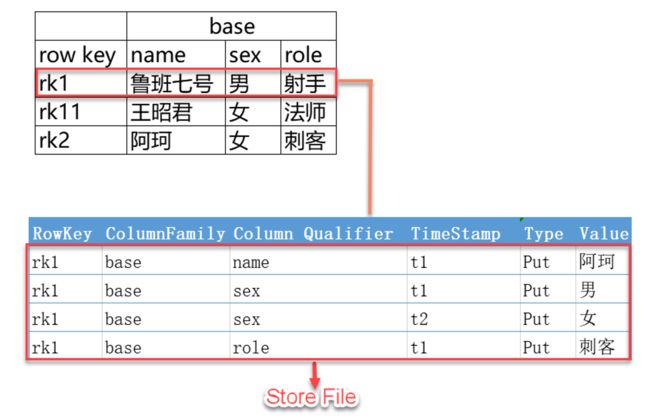
13489854921_92233704903999438078233/basic:dnum/1592979155327/Put/vlen=11/mvcc=0 V: 15973136770
数据模型
- NameSpace
命名空间,相当于关系型数据库中的 database,每个命名空间下有多个表。Hbase 默认自带的命名空间 hbase 和 default ;hbase 中存放的是 HBase 内置的表,default 是用户默认使用的命名空间。 - Region
类似关系型数据库的表,不同之处在于 HBase 定义表示只需要声明列族,不需要声明具体的列。列可以动态的按需要指定;HBase 更加适合自带经常变更的场景。开始创建表是一个表对应一个 region,当表增大到一定值是会被拆分为两个 region。 - Row
HBase 表中的每行数据被称为 Row,由一个 RowKey 和多个 Column 组成,数据是按照 RowKey 的字典顺序存储的,并且查询是只能根据 RowKey 进行检索,所以 RowKey 的设计很关键。 - Column
列是由列族(Column Family)和列限定符(Column Qualifier)进行限定,例如:base:name,base:sex。建表示只需定义列族,而列限定符无需预先定义。 - Cell
某行中的某一列被称为 Cell(单元格),由 {rowkey,column family:column qualifier,time stamp} 确定单元。Cell 中没有具体的类型,全部是字节码的形式(字节数组)存储。 - TimeStamp
用于标识数据的不同版本(version),每条数据写入时,如果不指定时间戳,系统会自动为其加上该字段,值为写入 HBase 的时间。
非关系型数据库知识面扩展
redis,memcached
mongoDB,CouchDB
Hbase、Cassandra 横向扩展 随机读写
hbase 架构
MySQL 存储是 4KB 作为一个小的存储空间。4KB datapage 数据页。查询时会从磁盘上遍历寻址。效率较低。
HBase 引入了列族(面向列族存储,而不是列存储每个列都单独存储)的概念:
CF1 CF2
id,name,age || likes,address
查询列所在的列族即可,其他列族中内字段不查询。
目录表 hbase:meta
目录表 hbase:meta 作为 HBase 表存在,并从 hbase shell 的 list (类似 show tables)命令中过滤掉,但实际上是一个表,就像任何其他表一样。
hbase:meta 表(以前称为.META.),保有系统中所有 region 的列表。hbase:meta 位置信息存储在 zookeeper 中。hbase:meta 表是所有查询的入口
表结构如下:
key:
region的key,结构为:[table],[region start key,end key],[region id]
values:
info:regioninfo(当前region序列化的HRegionInfo实例)
info:server(包含当前region的RegionServer的server:port)
info:serverstartcode(包含当前region的RegionServer进程的开始时间)
当表正在拆分时,将创建另外两列,称为 info:splitA 和 info:splitB 。 这些列代表两个子 region。 这些列的值也是序列化的 HRegionInfo 实例。区域分割后,将删除此行。
a,,endkey
a,startkey,endkey
a,startkey,
空键用于表示表开始和表结束。具有空开始键的 region 是表中的第一个 region。如果某个 region 同时具有空开始和空结束键,则它是表中唯一的 region。
Client
hbase:meta tablea,,100,node2
hbase:meta tablea,101-200,node3
hbase:meta tablea,201-300,node5
hbase:meta tablea,301-400,node237
hbase:meta tablea,401-500,node24
hbase:meta tablea,501,,node896
Client->zookeeper(hbase:meta)->root region(tablea,node3 tableb,node4)->meta region-> regionserver(数据)
包含访问 HBase 的接口并维护 cache 来加快对 HBase 的访问。HBase 客户端查找关注的行范围所在的 regionserver。它通过查询 hbase:meta表来完成此操作。在找到所需的 region 之后,客户端与提供该 region 的 RegionServer 通信,而不是通过 Master,并发出读取或写入请求。此信息缓存在客户端中,以便后续请求无需经过查找过程。如果 Master 的负载均衡器重新平衡或者由于 regionserver 宕机,都会重新指定该 region 的 regionserver 。客户端将重新查询目录表以确定用户 region 的新位置。
通过 Admin 进行管理功能的实现。
Zookeeper
- 保证任何时候,集群中只有一个活跃 master
- 存贮所有 Region 的寻址入口。 root region 的地址 hbase:meta 表的位置
- 实时监控 Region server 的上线和下线信息。并实时通知 Master
- 存储 HBase 的 schema 和 table 元数据
Master
- 为 Region server 分配 region
- 负责 Region server 的负载均衡
- 发现失效的 Region server 并重新分配其上的 region
- 管理用户对 table 的增删改操作 不是数据的增删改(DML) DDL
概括:管理 region 的分配和管理对表的操作
RegionServer
- Region server 维护 region,处理对这些 region 的 IO 请求
- Region server 负责切分在运行过程中变得过大的 region
Region 
- HBase 自动把表水平划分成多个区域 (region),每个 region 会保存一个表里面某段连续的数据 (每条记录都有一个行键,按照行键字典序排列)
- 每个表一开始只有一个 region ,随着数据不断插入表,region 不断增大,当增大到一个阈值的时候,region 就会等分会两个新的 region(裂变)
- 当 table 中的行不断增多,就会有越来越多的 region。这样一张完整的表被保存在多个 Regionserver 上。
- 一个 region 由多个 store 组成,一个 store 对应一个 CF(列族)
- HRegion 是 HBase 中分布式存储和负载均衡的最小单元。最小单元就表示不同的 HRegion 可以分布在不同的 HRegion server 上。HRegion 由一个或者多个 Store 组成,每个 store 保存一个 columns family 。每个 Store 又由一个 memStore 和 0 至多个 StoreFile 组成。如图:StoreFile 以 HFile 格式保存在 HDFS 上。

Memstore 与 storefile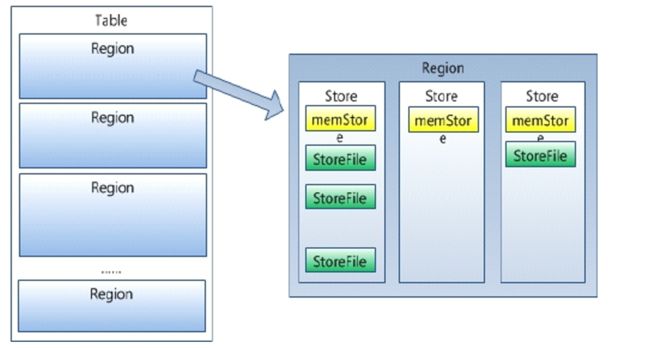
- store 包括位于内存中的 memstore 和位于磁盘的 storefile。
- 写操作先写入 memstore,当 memstore 中的数据达到某个阈值, hregionserver 会启动 flashcache 进程写入 storefile ,每次写入形成单独的一个 storefile。
- 当 storefile 文件的数量增长到一定阈值后,系统会进行合并(minor、major compaction),在合并过程中会进行版本合并和删除工作(majar),形成更大的 storefile
- 当一个 region 所有 storefile 的大小和数量超过一定阈值后,会把当前的 region 分割为两个,并由 hmaster 分配到相应的 regionserver 服务器,实现负载均衡
- 客户端检索数据,先查找 memstore,再 blockcache(查询缓存),找不到再找 storefile
hbase 搭建方式以及搭建流程
独立模式
JDK 版本要求:jdk7 最好,jdk8 也行,官方称未充分测试。
这是默认模式。独立模式是快速入门部分中描述的内容。 在独立模式下,HBase 不使用 HDFS - 它使用本地文件系统 - 它在同一个 JVM 中运行所有HBase 守护进程和本地 ZooKeeper 。 Zookeeper 绑定到端口 2181,因此客户可以与 HBase 通信。
具体操作
将 HBase 与本地文件系统一起使用并不能保证持久性。如果文件未正确关闭,HDFS 本地文件系统实现将丢失编辑。当您尝试使用新软件时,很可能会发生这种情况,经常启动和停止守护进程,而不是总是干净利落。您需要在 HDFS 上运行 HBase 以确保保留所有写入。作为评估的第一阶段,针对本地文件系统运行旨在使您熟悉常规系统的工作方式。
在conf/hbase-env.sh中设置 JAVA_HOME
在conf/hbase-site.xml中,仅需要指定 hbase 和 zookeeper 写数据的本地路径。默认情况下会在 /tmp 下创建新的目录。
<configuration>
<property>
<name>hbase.rootdir</name>
<value>file:///var/bjsxt/only/hbase</value>
</property>
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/var/bjsxt/only/zookeeper</value>
</property>
</configuration>
我们不需要创建任何目录,hbase 会创建。如果手动创建了,hbase 会做一个迁移,这不是我们想要的。
bin/start-hbase.sh脚本用于启动 hbase。启动成功,hbase 会在标准输出打印成功启动的信息。使用 jps 查看进程,会只有一个 HMaster 进程。这个进程中包含了一个 HMaster、一个 HRegionServer 以及一个 zookeeper 的 daemon。它们在同一个进程中。
网页访问:http://node1:60010/
1、连接HBase:
shell> ./bin/hbase shell
2、在 hbase 的 shell 中输入 help 并回车,获取帮助:
hbase(main):001:0> help
3、创建表
使用 create 命令创建表,必须指定表名和列族的名称
hbase(main):001:0> create 'test', 'cf'
0 row(s) in 0.4170 seconds
=> Hbase::Table - test
4、列出表的信息
使用 list 命令列出信息。
hbase(main):002:0> list 'test'
TABLE
test
1 row(s) in 0.0180 seconds
=> ["test"]
5、向 table 插入数据
使用 put 命令。
hbase(main):003:0> put 'test', 'row1', 'cf:a', 'value1'
0 row(s) in 0.0850 seconds
hbase(main):004:0> put 'test', 'row2', 'cf:b', 'value2'
0 row(s) in 0.0110 seconds
hbase(main):005:0> put 'test', 'row3', 'cf:c', 'value3'
0 row(s) in 0.0100 seconds
以上,插入了三个值,每次一个。第一次在 row1 的位置,cf:a 列插入值 value1。hbase 中的列由列族前缀cf跟一个冒号,再跟一个列标识符后缀比如 a。
6、一次性扫描表中的所有数据
要查询表中的数据,可以使用 scan 命令。可以在该命令中使用限定条件,下面获取了表中的所有数据:
hbase(main):016:0> scan 'test'
ROW COLUMN+CELL
row1 column=cf:a, timestamp=1568514191889, value=value1
row2 column=cf:b, timestamp=1568514198429, value=value2
row3 column=cf:c, timestamp=1568514205341, value=value3
3 row(s) in 0.0350 seconds
7、查询一行记录
使用 get 命令一次获取一行记录
hbase(main):017:0> get 'test', 'row1'
COLUMN CELL
cf:a timestamp=1568514191889, value=value1
1 row(s) in 0.0140 seconds
8、禁用一张表
如果要删除表或更改表的设置,需要先使用 disable 命令禁用该表,之后也可以使用 enable 命令重新使用该表。
hbase(main):018:0> disable 'test'
0 row(s) in 1.3350 seconds
hbase(main):019:0> enable 'test'
0 row(s) in 0.2520 seconds
#再次使用disable命令禁用该表:
hbase(main):020:0> disable 'test'
0 row(s) in 1.2580 seconds
9、删除表
在表已经禁用的情况下,使用 drop 命令删除表
hbase(main):021:0> drop 'test'
0 row(s) in 0.1550 seconds
10、退出 HBase 的 shell
退出 shell 断开到集群的连接,可以使用 quit 命令。但是 hbase 服务进程仍然在后台运行。
hbase(main):022:0> quit
[root@node1 hbase-0.98.12.1-hadoop2]#
11、停止 hbase 服务进程
bin/start-hbase.sh开启 hbase 的所有进程,bin/stop-hbase.sh 用于停止所有 hbase 进程。
[root@node1 hbase-0.98.12.1-hadoop2]# bin/stop-hbase.sh
stopping hbase..................
[root@node1 hbase-0.98.12.1-hadoop2]#
12、使用 jps 查看进程信息,确保 hbase 的 HMaster 和 HRegionServer 进程成功关闭:
[root@node1 hbase-0.98.12.1-hadoop2]# jps
2831 Jps
[root@node1 hbase-0.98.12.1-hadoop2]#
伪分布式
伪分布式模式只是在单个主机上运行的完全分布式模式。在 HBase 上使用此配置测试和原型设计。请勿将此配置用于生产,也不要用于评估 HBase 性能。
通过快速入门后,您可以重新配置 HBase 以在伪分布式模式下运行。伪分布模式意味着 HBase 仍然在单个主机上完全运行,但每个 HBase 守护程序(HMaster,HRegionServer和Zookeeper)作为单独的进程运行。默认情况下,除非您按照快速入门中的说明配置 hbase.rootdir 属性,否则您的数据仍存储在 /tmp/ 中。在本演练中,我们将您的数据存储在 HDFS 中,假设您有 HDFS 可用。您可以跳过 HDFS 配置以继续将数据存储在本地文件系统中。
具体操作
1、 如果前面的独立模式的 hbase 还在运行,停止 hbase。
2、 配置 hbase
a) 编辑hbase-site.xml。添加如下的配置,让 hbase 在分布式模式运行,一个 daemon 一个 JVM 进程:
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
b) 更改hbase.rootdir,将其设置为 HDFS 实例的地址,hdfs://。
<property>
<name>hbase.rootdir</name>
<value>hdfs://mycluster/hbase</value>
</property>
我们不需要在 hdfs 上创建该目录,hbase 会自己创建。如果我们手动创建,hbase 会做迁移,这不是我们要看到的。
c) 指定 zookeeper 写的目录
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/var/bjsxt/pseudo/zookeeper</value>
</property>
注意:由于 HBase 要使用 HDFS 的客户端,HDFS 客户端的配置必须让 hbase 看到并使用。有三种方式做到这一点:
i. 在hbase-env.sh中,将 HADOOP_CONF_DIR 添加到 HBASE_CLASSPATH 环境变量中,HADOOP_CONF_DIR 指向 HADOOP 的 etc/hadoop 目录。
ii. 拷贝hdfs-site.xml到 HBASE_HOME/conf ,当然,最好是做一个符号链接。
[root@node1 conf]# ln /opt/hadoop-2.6.5/etc/hadoop/hdfs-site.xml hdfs-site.xml
iii. 如果 HDFS 客户端配置很少,可以直接添加到 hbase-site.xml 中。
3、 启动 hbase
要保证 hadoop 先启动。hfds 一定要启动,YARN 可以不启动
a) 使用bin/start-hbase.sh启动 hbase。启动成功后使用 jps 可以看到 HMaster 和 HRegionServer 的进程在运行。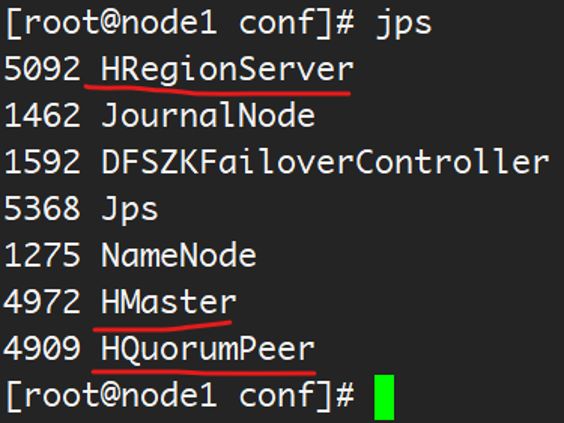
4、 在 HDFS 检查 Hbase 的目录
a) http://node1:60010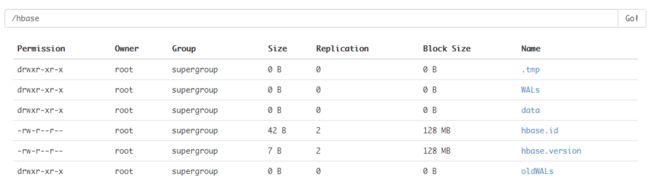
5、 hbase shell 操作
a、连接 HBase:
shell> ./bin/hbase shell
b、在 hbase 的 shell 中输入 help 并回车,获取帮助:
hbase(main):001:0> help
c、创建表
使用 create 命令创建表,必须指定表名和列族的名称
hbase(main):001:0> create 'test', 'cf'
0 row(s) in 0.4170 seconds
=> Hbase::Table - test
d、列出表的信息
使用 list 命令列出信息。
hbase(main):002:0> list 'test'
TABLE
test
1 row(s) in 0.0180 seconds
=> ["test"]
e、向 table 插入数据
使用 put 命令。
hbase(main):003:0> put 'test', 'row1', 'cf:a', 'value1'
0 row(s) in 0.0850 seconds
hbase(main):004:0> put 'test', 'row2', 'cf:b', 'value2'
0 row(s) in 0.0110 seconds
hbase(main):005:0> put 'test', 'row3', 'cf:c', 'value3'
0 row(s) in 0.0100 seconds
以上,插入了三个值,每次一个。第一次在 row1 的位置,cf:a 列插入值 value1。hbase 中的列由列族前缀 cf 跟一个冒号,再跟一个列标识符后缀比如 a。
f、一次性扫描表中的所有数据
要查询表中的数据,可以使用 scan 命令。可以在该命令中使用限定条件,下面获取了表中的所有数据:
hbase(main):016:0> scan 'test'
ROW COLUMN+CELL
row1 column=cf:a, timestamp=1568514191889, value=value1
row2 column=cf:b, timestamp=1568514198429, value=value2
row3 column=cf:c, timestamp=1568514205341, value=value3
3 row(s) in 0.0350 seconds
g、查询一行记录
使用 get 命令一次获取一行记录
hbase(main):017:0> get 'test', 'row1'
COLUMN CELL
cf:a timestamp=1568514191889, value=value1
1 row(s) in 0.0140 seconds
h、禁用一张表
如果要删除表或更改表的设置,需要先使用 disable 命令禁用该表,之后也可以使用 enable 命令重新使用该表。
hbase(main):018:0> disable 'test'
0 row(s) in 1.3350 seconds
hbase(main):019:0> enable 'test'
0 row(s) in 0.2520 seconds
再次使用 disable 命令禁用该表:
hbase(main):020:0> disable 'test'
0 row(s) in 1.2580 seconds
i、删除表
在表已经禁用的情况下,使用 drop 命令删除表
hbase(main):021:0> drop 'test'
0 row(s) in 0.1550 seconds
j、退出 HBase 的 shell
退出 shell 断开到集群的连接,可以使用 quit 命令。但是 hbase 服务进程仍然在后台运行。
hbase(main):022:0> quit
[root@node1 hbase-0.98.12.1-hadoop2]#
k、停止 hbase 服务进程
bin/start-hbase.sh开启 hbase 的所有进程,bin/stop-hbase.sh用于停止所有 hbase 进程。
[root@node1 hbase-0.98.12.1-hadoop2]# bin/stop-hbase.sh
stopping hbase..................
[root@node1 hbase-0.98.12.1-hadoop2]#
l、使用jps查看进程信息,确保 hbase 的 HMaster 和 HRegionServer 进程成功关闭:
[root@node1 hbase-0.98.12.1-hadoop2]# jps
2831 Jps
[root@node1 hbase-0.98.12.1-hadoop2]#
完全分布式
实际上,您需要完全分布式配置才能完全测试 HBase 并在实际场景中使用它。在分布式配置中,群集包含多个节点,每个节点运行一个或多个 HBase 守护程序。其中包括主要和备用 Master,多个 Zookeeper 节点和多个 RegionServer 节点。
规划如下:
具体操作
1、 配置四台主机免密钥
2、 将 hbase 解压到 node1 的 /opt
3、 在 /etc/profile 中配置 HBASE_HOME,并将 HBase 的 bin 目录添加到 PATH 中
4、 删除 /opt/hbase-0.98.12.1-hadoop2 中的 docs 目录
5、 进入 conf,编辑 regionservers
a) 配置如下:
node2
node3
node4
6、 配置 node2 为 backup master
a) 在 conf 中添加一个文件 backup-masters ,并配置如下
[root@node1 conf]# echo "node2" >> backup-masters
7、 在conf/hbase-env.sh中设置 JAVA_HOME
a) 
8、 配置 zookeeper
a) 设置使用外部的zookeeper
在conf/hbase-env.sh中设置HBASE_MANAGES_ZK=false
b) 要么将 zoo.cfg 拷贝到 HBASE 的 CLASSPATH,要么在 hbase-site.xml 中配置 zookeeper 的信息。hbase 会优先使用 zoo.cfg 的配置。在hbase-site.xml中配置如下:
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<name>hbase.rootdir</name>
<value>hdfs://mycluster/hbase_ha</value>
</property>
<property>
<!-- 默认端口号可以不写,也可以添加:node2:2181,node3:2181,node4:2181 -->
<name>hbase.zookeeper.quorum</name>
<value>node2,node3,node4</value>
</property>
<property>
<!-- 可以不配置 -->
<name>hbase.zookeeper.property.dataDir</name>
<value>/var/bjsxt/zookeeper/data</value>
</property>
9、 将 hadoop 的hdfs-site.xml拷贝到$HBASE_HOME/conf目录下。
10、 将/opt/hadoop-0.98拷贝到 node2,node3 和 node4。确保没有任意一个节点运行 hbase
11、 在 node2 上配置 hbase 的环境变量,生效后并将之拷贝 node3 和 node4 上。
12、 要保证 hadoop 先启动。hfds 一定要启动,YARN 可以不启动
13、 启动集群
在 node1 上执行 start-hbase.sh
14、 在各个节点使用 jps 验证运行的进程
a) 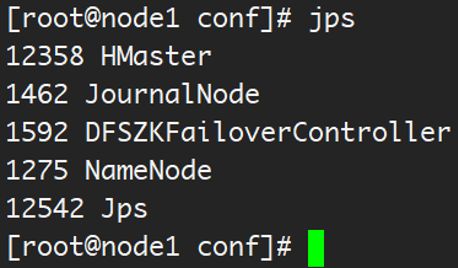
b) 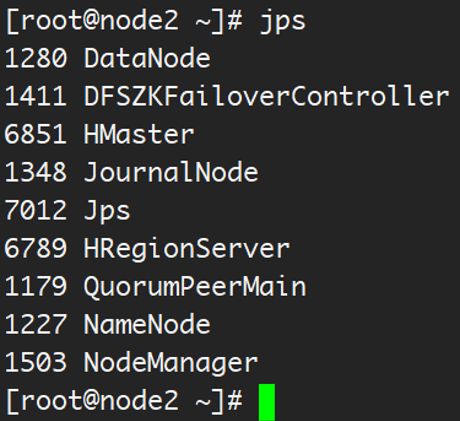
c) 
d) 
15、 浏览 HBase 的 Web UI。
a) http://node1:60010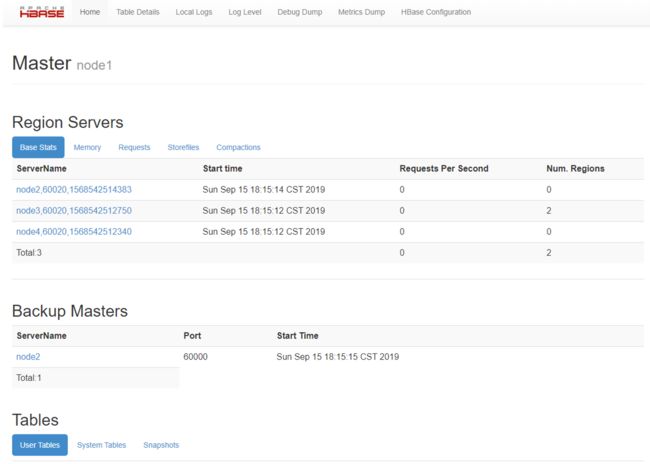

16、 测试一下如果节点或服务消失会发生什么。
如果只配置了四个节点,HBase 还不是太有弹性。不过依然可以测试如果主 HMaster 或者 HRegionServer 消失会发生什么。比如可以 kill 掉进程,查看 log 日志等。
a) 杀死 node1 上的 HMaster 观察 web ui
http://node2:60010/master-status
b) 在 node1 启动 HMaster:hbase-daemon.sh start master
访问 node1 的 web ui 界面:
http://node1:60010/master-status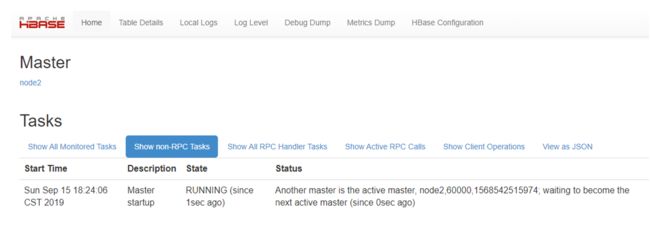
c) 在 node2 上 kill 掉 HRegionServer,查看 web ui:
d) 在 node2 上启动 HRegionServer:hbase-daemon.sh start regionserver,查看 web ui:
hbase 数据模型进阶
rowkey cf1:q2 获取最新数据
row key , CF1, q2, t2 四维数据库,获取指定列族指定列指定时间戳的数据
rowkey 列族 列名 时间戳 四个纬度
row key
- 决定一行数据
- 按照字典顺序排序的。
- Row key只能存储 64k 的字节数据(UTF-8 编码格式下 2.133w 多个汉字)
Column Family 列族 & qualifier 列
- HBase表中的每个列都归属于某个列族,列族必须作为表模式(schema)定义的一部分预先给出。 create ‘tb_user’, ‘cf’ 或 create ‘test’, ‘course’;
- 列名以列族作为前缀,每个“列族”都可以有多个列成员(column);如course:math, course:english , 新的列族成员(列)可以随后按需、动态加入;
- 权限控制、存储以及调优都是在列族层面进行的;
- HBase 把同一列族里面的数据存储在同一目录下,由几个文件保存。
Cell 单元格
由行和列的坐标交叉决定;
单元格是有版本的;
单元格的内容是未解析的字节数组;
由 {row key, column( = +), version} 唯一确定的单元。
cell中的数据是没有类型的,全部是字节数组形式存贮。
Timestamp 时间戳
rowkey - liezu:biaozhifu version cell value
在 HBase 每个 cell 存储单元对同一份数据有多个版本,根据唯一的时间戳来区分每个版本之间的差异,不同版本的数据按照时间倒序排序,最新的数据版本排在最前面。 rowkey cf name
时间戳的类型是 64 位整型。
时间戳可以由 HBase(在数据写入时自动)赋值,此时时间戳是精确到毫秒的当前系统时间。
时间戳也可以由客户显式赋值,如果应用程序要避免数据版本冲突,就必须自己生成具有唯一性的时间戳。
在 HBase 0.96 之前,保留的默认版本数为 3,但是在 0.96 中,更新版本已更改为 1。
hbase 可以容忍不同 regionserver 之间的时间差 30s,否则失败。
做时间同步
yum install ntp -y
service ntpd start
chkconfig ntpd on
HLog(WAL log)
WAL:WRITE AHEAD LOG
HLog 文件就是一个普通的 Hadoop Sequence File,Sequence File 的 Key 是 HLogKey 对象,HLogKey 中记录了写入数据的归属信息,除了table 和 region 名字外,同时还包括 sequence number 和 timestamp,timestamp 是”写入时间”,sequence number 的起始值为0,或者是最近一次存入文件系统中 sequence number。
HLog SequeceFile 的 Value 是 HBase 的 KeyValue 对象,即对应 HFile 中的 KeyValue。
键(四个维度)value(单元格的值)
该文件作用是保证数据不丢失。
目录表
目录表 hbase:meta 作为 HBase 表存在,并从 hbase shell 的 list 命令中过滤掉,但实际上是一个表,就像任何其他表一样。
hbase:meta 表(以前称为 .META.),保有系统中所有 region 的列表。hbase:meta 存储在 zookeeper 中。
表结构如下:
key:
region的key,结构为:[table],[region start key],[region id]
values:
info:regioninfo(当前region序列化的HRegionInfo实例)
info:server(包含当前region的RegionServer的server:port)
info:serverstartcode(包含当前region的RegionServer进程的开始时间)
当表正在拆分时,将创建另外两列,称为 info:splitA 和 info:splitB。 这些列代表两个子 region。 这些列的值也是序列化的 HRegionInfo 实例。区域分割后,将删除此行。
空键用于表示表开始和表结束。具有空开始键的 region 是表中的第一个 region。如果某个 region 同时具有空开始和空结束键,则它是表中唯一的 region。
启动顺序:首先,在 zookeeper 中查找 hbase:meta 的位置。其次,使用服务器和启动代码更新 hbase:meta 的值。
给 RegionServer 赋值 region(最好理解)
当 hbase 启动的时候,region 通过如下步骤赋值给 regionserver:
1、 系统启动的时候,master 调用 AssignmentManager(赋值管理器)
2、 AssignmentManager 在 hbase:meta 中查找已经存在的 region 条目
3、 如果 region 条目依旧是正确的(比如说 regionserver 依然在线),就保留该赋值信息
4、 如果赋值不正确,就调用 LoadBalancerFactory 对 region 进行赋值。负载平衡器将 region 赋值给一个 regionserver。hbase1.0 中默认的负载均衡器是 StochasticLoadBalancer。
5、 在 regionserver 打开 region 的时候使用 regionserver 的开始代码更新 hbase:meta 中 regionserver 的赋值。
当客户端访问的时候,regionserver 失败的时候:
1、 由于 regionserver 宕机,region 立即不可用
2、 master 检测到该 regionserver 的失败
3、 认为 region 的赋值不正确,使用启动顺序的流程重新给 region 赋值
4、 正在进行的查询会重试,而不是丢失。
5、 在下述时间内操作会转移到新的 regionserver:zookeeper session timeout+split time+assignment/replay time
Client->regionserver1(宕机了,在zk上对应的临时节点一定时间后消失)
Client->hbase:meta-->regionserver2(重新分配一个regionserver)
Client->regionserver2->对应的region
客户端
HBase 客户端查找关注的行范围所在的 regionserver。它通过查询 hbase:meta 表来完成此操作。在找到所需的 region 之后,客户端联系提供该 region 的 RegionServer ,而不是通过 Master,并发出读取或写入请求。此信息缓存在客户端中,以便后续请求无需经过查找过程。如果 Master 的负载均衡器重新平衡或者由于 regionserver 宕机,都会重新指定该 region 的 regionserver。客户端将重新查询目录表以确定用户 region 的新位置。
通过 Admin 进行管理功能的实现。
HBase 的特点
- 强大的一致读/写:HBase 不是“最终一致”的 DataStore。它非常适合高速计数器聚合等任务。
- 自动分片:HBase 表通过 region 分布在群集上,并且随着数据的增长,region 会自动分割和重新分配。
- 自动的 RegionServer 故障转移。
- Hadoop/HDFS 集成:HBase 支持 HDFS 作为其分布式文件系统。
- MapReduce:HBase 支持通过 MapReduce 进行大规模并行处理,将 HBase 用作源和漏。
HBASE->MR->HDFSHBASE->MR->HBASE HDFS->MR->HBASE - Java 客户端 API:HBase 支持易于使用的 Java API 以进行编程访问。
- Thrift/REST API:HBase 还支持非 Java 前端的 Thrift 和 REST。
- 块缓存和布隆过滤器:HBase 支持块缓存和布隆过滤器,以实现大容量查询优化。
- 运维管理:HBase 提供内置网页,用于运维监控和 JMX 指标。
HBase 不支持行间事务(情侣转账 520) HBase 支持行内事务
hbase 读写流程
LSMTree
LSM 树(log-structured merge-tree)。输入数据首先被存储在日志文件(HLog),这些文件内的数据完全有序。当有日志文件被修改时,对应的更新会被先保存在内存中来加速查询。
当系统经历过许多次数据修改,且内存(存放数据)空间被逐渐被占满后,LSM 树会把有序的 “键-记录” 对写到磁盘中,同时创建一个新的数据存储文件(storefile)。此时,因为最近的修改都被持久化了,内存中保存的最近更新就可以被丢弃了。
存储文件的组织与 B 树(课后研究一下)相似,不过其为磁盘顺序读取做了优化,所有节点都是满的并按页存储。修改数据文件的操作通过滚动合并完成,也就是说,系统将现有的页与内存刷写数据混合在一起进行管理,直到数据块达到它的容量(region 的阈值,达到阈值进行 region 的切割,重新分配 hregionserver)。
多次数据刷写之后会创建许多数据存储文件,后台线程就会自动将小文件聚合成大文件,这样磁盘查找就会被限制在少数几个数据存储文件中。磁盘上的树结构也可以拆分成独立的小单元,这样更新就可以被分散到多个数据存储文件中。所有的数据存储文件都按键排序,所以没有必要在存储文件中为新的键预留位置。
查询时先查找内存中的存储,然后再查找磁盘上的文件。这样在客户端看来数据存储文件的位置是透明的。
删除是一种特殊的更改,当一条记录被删除标记之后,查找会跳过这些删除过的键。当页被重写时,有删除标记的键会被丢弃。
大合并(major)和小合并(minor):
随着 memstore 的刷写会生成很多磁盘文件。如果文件的数目达到阈值,合并(compaction)过程将把它们合并成数量更少的体积更大的文件。这个过程持续到这些文件中最大的文件超过配置的最大存储文件大小,此时会触发一个 region 拆分。
minor 合并负责重写最后生成的几个文件到一个更大的文件中。文件数量是由hbase.hstore.compaction.min属性设置的。它的默认值为 3,并且最小值需要大于或等于 2。过大的数字将会延迟 minor 合并的执行,同时也会增加执行时消耗的资源及执行的时间。minor 合并可以处理的最大文件数量默认为 10,用户可以通过hbase.hstore.compaction.max来配置。(课后思考?)
hbase.hstore.compaction.min.size(默认设置为 region 的 memstore 刷写大小)和hbase.hstore.compaction.max.size(默认设置为 Long.MAX_VALUE)配置项属性进一步减少了需要合并的文件列表。任何比最大合并大小大的文件都会被排除在外。
major 合并:它们把所有文件压缩成一个单独的文件。默认情况下,major 合并间隔是 7 天,看情况随机的加上或减去 4.8 小时。
如果要删除数据,不会直接修改 storefile,因为 hadoop 不允许修改。hbase 会将删除的数据标志为已删除(给该数据添加墓碑标记),如果添加了墓碑标记,查询不到该数据。在大合并的时候,将标记了墓碑标记的数据真正删除。
读路径
- Client 访问 Zookeeper,查找 hbase:meta 表位置,看他在哪个 regionserverR 上。
- Client 访问 regionserverR 上 hbase:meta 表中的数据,查找要操作的表对应 region 所在的 regionserverX
- Client 读取 regionserverX 上的 region 数据
定位到真正的数据所在的 region 的时候,按照下述步骤进行操作:
先查找 memstore,如果 memstore 没有,查找 blockcache;如果 blockcache 没有,则查找 storefile 的数据,同时将数据缓存与 blockcache 中。
写路径
当用户向 HRegionServer 发起 HTable.put(Put) 请求时,其会将请求交给对应的 HRegion 实例来处理。
第一步是要决定数据是否需要写到由 HLog 类实现的预写日志中。WAL 是标准的 Hadoop SequenceFile,并且存储了 HLogKey 实例。这些键包括序列号和实际数据,所以在服务器崩溃时可以回滚还没有持久化的数据。
一旦数据被写入到 WAL 中,数据就会被放到 MemStore 中。同时还会检查 MemStore 是否已经满了,如果满了,就会被请求刷写到磁盘中去。刷写请求由另外一个 HRegionServer 的线程处理,它会把数据写成 HDFS 中的一个新 HFile。同时也会保存最后写入的序号,系统就知道哪些数据现在被持久化了。
hbase 客户端操作
查看帮助信息
直接在 hbase shell 输入 help 并回车查看如何使用帮助。
在 hbase shell 中输入 'help “COMMAND” ’ 查看指定命令的帮助信息。(如,'help “get” ’ – get 的引号是必须的)
命令是分组的,输入’help “COMMAND_GROUP” '查看命令组帮助信息。(如,'help “general” ')
命令组:
组名:general
命令:status, table_help, version, whoami
组名:ddl
命令:alter, alter_async, alter_status, create, describe, disable, disable_all, drop, drop_all, enable, enable_all, exists, get_table, is_disabled, is_enabled, list, show_filters
组名:namespace
命令:alter_namespace, create_namespace, describe_namespace, drop_namespace, list_namespace, list_namespace_tables
组名:dml
命令:append, count, delete, deleteall, get, get_counter, get_splits, incr, put, scan, truncate, truncate_preserve
组名:tools
命令:assign, balance_switch, balancer, catalogjanitor_enabled, catalogjanitor_run, catalogjanitor_switch, close_region, compact, compact_rs, flush, hlog_roll, major_compact, merge_region, move, split, trace, unassign, zk_dump
组名:replication
命令:add_peer, disable_peer, disable_table_replication, enable_peer, enable_table_replication, list_peers, list_replicated_tables, remove_peer, set_peer_tableCFs, show_peer_tableCFs
组名:snapshots
命令:clone_snapshot, delete_all_snapshot, delete_snapshot, list_snapshots, restore_snapshot, snapshot
组名:security
命令:grant, revoke, user_permission
组名:visibility labels
命令:add_labels, clear_auths, get_auths, list_labels, set_auths, set_visibility
SHELL USAGE:
shell 用法:
将所有的名称如表名列名,用引号引起来。逗号分隔命令参数。回车执行命令。
在创建表或修改表的时候使用配置字典。配置字典是 Ruby 的 Hashes 。看起来像这样:
{‘key1’ => ‘value1’, ‘key2’ => ‘value2’, …}
用大括号引起来,键值分隔符是=>。通常键是预定义的常量,比如:NAME, VERSIONS, COMPRESSION 等。常量不需要括起来。输入 ‘Object.constants’ 查看环境中所有常量。
如果用到了二进制的 key,使用双引号引起来的十六进制表示。例如:
hbase> get 't1', "key\x03\x3f\xcd"
hbase> get 't1', "key\003\023\011"
hbase> put 't1', "test\xef\xff", 'f1:', "\x01\x33\x40"
hbase java api 操作
1、创建 java 项目
2、添加依赖 jar 包
hadoop 和 hbase 的 jar 包,$HBASE_HOME/lib
3、编写示例程序
1. package com.bjsxt.hbase;
2.
3. import org.apache.hadoop.conf.Configuration;
4. import org.apache.hadoop.hbase.*;
5. import org.apache.hadoop.hbase.client.*;
6. import org.apache.hadoop.hbase.util.Bytes;
7. import org.junit.After;
8. import org.junit.Before;
9. import org.junit.Test;
10.
11. public class HBaseDemo {
12.
13. //表的管理类
14. HBaseAdmin admin = null;
15. //数据的管理类
16. HTable table = null;
17. //表名
18. String tm = "phone";
19. /**
20. * 完成初始化功能
21. * @throws Exception
22. */
23. @Before
24. public void init() throws Exception{
25. Configuration conf = new Configuration();
26. conf.set("hbase.zookeeper.quorum", "node2,node3,node4");
27. admin = new HBaseAdmin(conf);
28. table = new HTable(conf,tm.getBytes());
29. }
30. @After
31. public void destory() throws Exception{
32. if(admin!=null){
33. admin.close();
34. }
35. }
36. /**
37. * 创建表
38. * @throws Exception
39. */
40. @Test
41. public void createTable() throws Exception{
42. //表的描述类
43. HTableDescriptor desc = new HTableDescriptor(TableName.valueOf(tm));
44. //列族的描述类
45. HColumnDescriptor family = new HColumnDescriptor("cf".getBytes());
46. desc.addFamily(family);
47. if(admin.tableExists(tm)){
48. admin.disableTable(tm);
49. admin.deleteTable(tm);
50. }
51. admin.createTable(desc);
52. }
53.
54. @Test
55. public void insert() throws Exception{
56. Put put = new Put("1111".getBytes());
57. put.add("cf".getBytes(), "name".getBytes(), "zhangsan".getBytes());
58. put.add("cf".getBytes(), "age".getBytes(), "12".getBytes());
59. put.add("cf".getBytes(), "sex".getBytes(), "man".getBytes());
60. table.put(put);
61. }
62. @Test
63. public void get() throws Exception{
64. Get get = new Get("1111".getBytes());
65. //添加要获取的列和列族,减少网络的io,相当于在服务器端做了过滤
66. get.addColumn("cf".getBytes(), "name".getBytes());
67. get.addColumn("cf".getBytes(), "age".getBytes());
68. get.addColumn("cf".getBytes(), "sex".getBytes());
69. Result result = table.get(get);
70. Cell cell1 = result.getColumnLatestCell("cf".getBytes(), "name".getBytes());
71. Cell cell2 = result.getColumnLatestCell("cf".getBytes(), "age".getBytes());
72. Cell cell3 = result.getColumnLatestCell("cf".getBytes(), "sex".getBytes());
73. System.out.println(Bytes.toString(CellUtil.cloneValue(cell1)));
74. System.out.println(Bytes.toString(CellUtil.cloneValue(cell2)));
75. System.out.println(Bytes.toString(CellUtil.cloneValue(cell3)));
76. }
77.
78. @Test
79. public void scan() throws Exception{
80. Scan scan = new Scan();
81. // scan.setStartRow(startRow);
82. // scan.setStopRow(stopRow);
83. ResultScanner rss = table.getScanner(scan);
84. for (Result result : rss) {
85. Cell cell1 = result.getColumnLatestCell("cf".getBytes(), "name".getBytes());
86. Cell cell2 = result.getColumnLatestCell("cf".getBytes(), "age".getBytes());
87. Cell cell3 = result.getColumnLatestCell("cf".getBytes(), "sex".getBytes());
88. System.out.println(Bytes.toString(CellUtil.cloneValue(cell1)));
89. System.out.println(Bytes.toString(CellUtil.cloneValue(cell2)));
90. System.out.println(Bytes.toString(CellUtil.cloneValue(cell3)));
91. }
92. }
93. @Test
94. public void addFamily() throws IOException {
95. TableName tableName = TableName.valueOf(tn);
96. admin.disableTable(tableName);
97. HTableDescriptor hDescriptor= admin.getTableDescriptor(tableName);
98. HColumnDescriptor hColumnDescriptor=new HColumnDescriptor("cf2".getBytes());
99. hDescriptor.addFamily(hColumnDescriptor);
100. admin.modifyTable(tableName, hDescriptor);
101. admin.enableTable(tableName);
102. //describe 'phone' 查看
103. }
104. @Test
105. public void deleteData() throws IOException {
106. Delete delete = new Delete(Bytes.toBytes("1111"));
107. //delete.deleteColumn(Bytes.toBytes("cf"),Bytes.toBytes("cf:name"));
108. delete.deleteFamily(Bytes.toBytes("cf"));//删除rowkey 1111这行数据在cf列族下全部数据
109. table.delete(delete);
110. }
111. }
作业:通话记录
电话号码,时间
1、按照电话号码和时间查询通话记录
2、按照电话号码和主被叫类型查询通话记录
手机号 通话时长 对方手机号 日期 类型(主叫,被叫)
rowkey: cf:(通话记录信息)
手机号
时间(倒序)
需求:按照手机号和时间段查询记录,rowkey如何设计?
phonenum_(Long.MAX_VALUE-timestamp)
cf:length=,cf:onum=,cf:date=,cf:type= 0表示主叫 1表示被叫