channelinboundhandler中都包含了哪一类的方法_三种聚类方法的介绍及其R语言实现...
聚类即是将研究对象的集合分成由类似的对象组成的多个类的过程。聚类分析所要求划分的类是未知的,所生成的集合是“簇”,每一簇是一组数据对象的集合,这些对象与同一簇中的对象彼此相似,与其他簇中的对象相异。聚类分析法是研究“物以类聚”的一种现代统计分析方法,在众多的领域中,都需要采用聚类分析作分类研究。聚类分析的类型包括两种Q型聚类(对样品聚类)、R型聚类(对变量聚类)。
一、聚类分析介绍
聚类分析方法包括很多种,例如:系统聚类法、动态聚类法、模糊聚类法、密度聚类法等,本文主要介绍的是系统聚类法、动态聚类法与密度聚类法。
( 一) 系统聚类法 系统聚类法是基于研究对象之间的距离进行分类的,包括euclidean( 欧几里得距离,即数学中常用的点间的距离) 、maximum( 切比雪夫距离) 、manhattan( 绝对值距离) 、canberra Lance 距离、minkowski( 明科夫斯基距离,使用时需指定P 值) 、binary( 定性变量距离) 在R 语言中用来计算距离的函数为:dist(x,method="",diag=FALSE,upper=FALSE,p=) 其中method 为求距离的方法,diag 为TRUE 时表示给出的对角线上的距离,upper 为TRUE 时表示给出上三角矩阵上的值。 系统聚类法中根据簇的不同的合并方法,包括最长距离法(complete) 、最短距离法(single) 、中间距离法(median) 、相似法(mcquitty) 、类平均法(average) 、重心法(centroid) 、离差平方和法(ward) 。 利用R 语言中的函数:hclust(d,method=" ",member=NULL) 来进行系统聚类分析。 ( 二) 动态聚类法 动态聚类在进行分析时先抽取几个点将周围的点聚集起来,然后算每一类的重心或者是平均值,以算出来的结果为分类点,然后将这个过程一直重复下去,直到分类完成。因此动态聚类方法又称为逐步聚类法。动态聚类法具有计算量小,方法简单的优点,适用于大样本的Q 型聚类分析。R 语言中用于动态聚类分析的函数为kmeans( ) 函数。 ( 三) 密度聚类法 密度聚类法是一种有噪声应用的基于密度的空间聚类方法,适合数据稠密的情况,在数据非凸情况下优于kmeans 聚类方法。 密度聚类分析涉及连个重要参数:eps 与minptseps 表示围绕数据点p 的邻域的半径minpts 表示邻域中定义聚类所需样本点个数的下限 基本聚类思想为:任意找到一个没有类别的核心对象,然后找到所有这个核心对象可达的子样本作为一类,接着重复此过程找下一个没有类别的核心对象,直至分类完成。 密度聚类法是基于DBSCAN 算法的,该算法具有很多优点,提前不需要确定簇的数量。当数据点非常不同时,会将它们单纯地引入簇中。DBSCAN 能将异常值识别为噪声。另外,它能够很好地找到任意大小和任意形状的簇。DBSCAN算法的主要缺点是,当数据簇密度不均匀时,它的效果不如其他算法好。这是因为当密度变化时,用于识别邻近点的距离阈值eps和minpts的设置将随着簇而变化。在处理高维数据时也会出现这种缺点,因为难以估计距离阈值。
二、实证分析 以R 语言中rattle 程序包里的wine 数据集为例,根据178 种意大利葡萄酒中的13 种化学成分对葡萄酒进行聚类分析,然后与真实值进行比较。 (一)系统聚类法 在系统聚类中选择最长距离法,聚类为3 类,根据该聚类个数画出最终的聚类结果为:
![]()
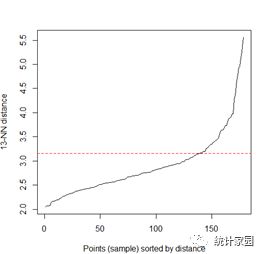
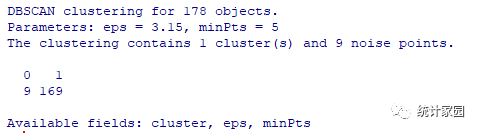 图6 密度聚类法结果
图6 密度聚类法结果
聚类后仅把数据集分为了1类,一共包含178个数据,第0组9个值噪声点。这也说明该数据集不适合利用密度聚类法进行聚类。
附R语言代码:
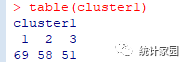
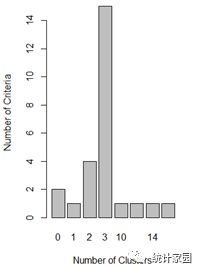
data(wine,package="rattle")head(wine)df=scale(wine[-1])#数据标准化处理##系统聚类分析最长距离法d=dist(df)hc1=hclust(d,method="complete")plot(hc1,hang=-1,cex=.5,main="The furthest linkage method")rect.hclust(hc1,3)##动态聚类法library(NbClust)set.seed(1234)devAskNewPage(ask=TRUE)nc=NbClust(df,min.nc=2,max.nc=15,method="kmeans")table(nc$Best.n[1,])barplot(table(nc$Best.n[1,]),xlab="Number of Clusters",ylab="Number of Criteria",main="Number of Clusters Chosen by 26 Criteria")#决定聚类个数hc2=kmeans(df,3,nstart=25)hc2$size##密度聚类法library(dbscan)kNNdistplot(df,13)#画图,最近距离abline(h=3.15,col="red",lty=2)hc3=dbscan(df,eps=3.15,minPts=5)table(hc3)pairs(df,col=hc3$cluster+1L)