解决工业检测的痛点——变化检测网络Siam-NestedUNet
1、问题介绍
工业检测
如今深度学习的发展如火如荼,各类神奇的技术如人脸识别、换脸技术啥的,似乎什么问题都只需要Deep Learning一下就可以解决了。但这都是属于民用级别的技术,而真正想要在实际业务中落地,更多的是要渗透到工业中去。
常见的工业检测有如下特点:
- 良品多,次品少。如果一个工厂生产的大部分都是坏品,那这个工厂就离倒闭不远了。而恰恰深度学习则需要大量的坏品数据。
- 产品换批次,产线更新。经常一换产品,之前优化过的模型就没办法再用了。
就针对这两个问题,目前学术界较为成熟的目标检测、图像分割方法都无法从根本解决这个问题。近几年开始流行的few-shot learning注意到了这个情况,但可惜技术还不是很成熟。
2、模型结构
模型的整体架构如下图所示,看上去非常复杂,但看完下面的讲解你就一定明白了。模型的结构可以拆成四个部分来讲解,设计非常精巧。
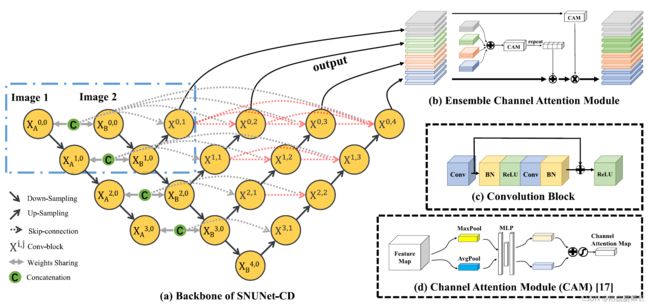
1、Backbone
Unet++
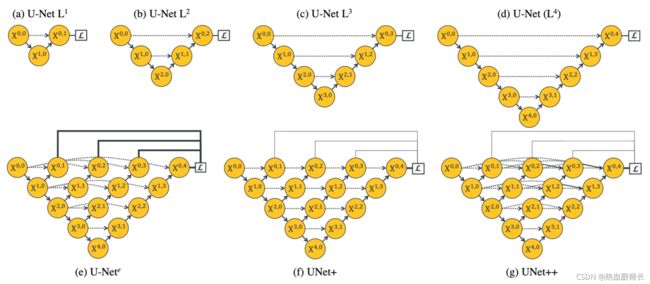
模型的主干由UNet++衍生而来。我们不看双输入部分,只看backbone,从 x 0 , 0 x^{0,0} x0,0下采样到 x 4 , 0 x^{4,0} x4,0,然后上采样到 x 0 , 4 x^{0,4} x0,4这一部分,它是呈现一个U型结构,熟悉医学图像分割的同学一定知道,这就是UNet网络。这是分割中非常经典的Encoder-Decoder结构。
DenseNet
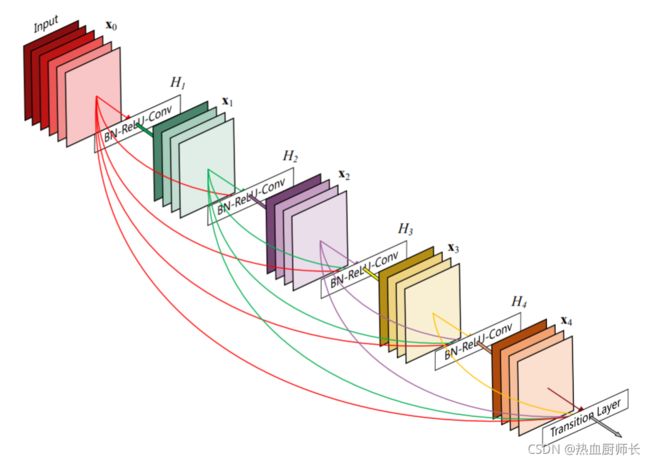
而UNet++则参考DenseNet一步步进化而来。DenseNet采用了密集残差边,作为图像分类的backbone有效提高了分类准确率,这种小而美的结构也被采用到了UNet++中。这么做的好处是:1、解决梯度回传时,浅层网络难以优化的问题。2、加强特征融合,使得深层网络可以结合浅层网络的特征,同时融合了低层的细节信息和高层的语义信息,增大了低层的感受野,使得低层在做小目标检测时能获得更多上下文信息。
2、Siamese Network - 孪生网络
孪生网络有两个输入,其诞生的初衷是为了解决小数据集泛化性差的问题。从下图看一个输入对应一个网络,最终会的得到两个输出,这两个输出对应这两个输入的高维特征,对其简单做差可近似看为二者的loss,loss越小代表差异越小,loss越大代表差异越大。通常情况下,两个输入的网络权重是共享的,所以是实质上就是一个网络。
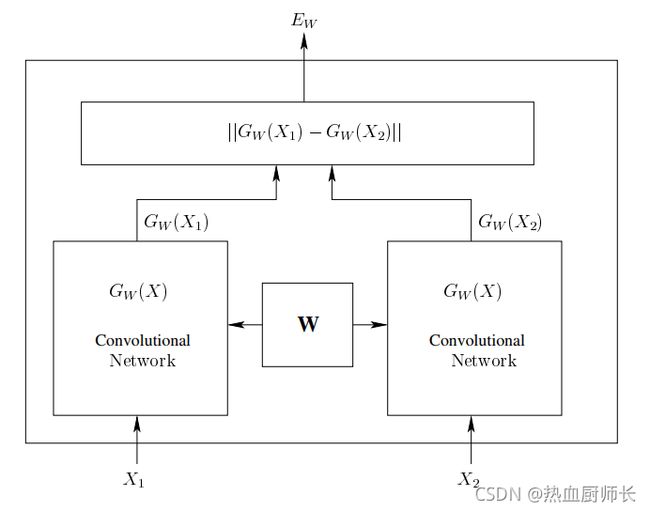
Siam-NestedUNet画蓝色虚线框内采用的就是这样的双输入结构,利用UNet++进行特征提取,只不过它提取的已不是物体的特征,而是两张图的差异信息。如果我们把变化的类别(在检测或分割中对应未知异物)当作要检出的目标,那么Siam-NestedUNet就是将两张图中有差异的部分当作目标进行检出。
3、SENet + ResNet
Siam-NestedUNet的backbone将各个不同层级的特征层concat在一起之后有一个残差Ensemble Channel Attention Module,这个模块可以看成是一个残差块 + 两个CAM构成。其中残差块就是我们熟知的ResNet这里不多赘述,CAM则是取自SENet,也就是我们常说的注意力机制。它将每个特征层(无论多大)统一缩放成1x1的大小,然后经过一个1x1的卷积和relu函数,再经过一个1x1卷积和Sigmoid激活,此时的得到的是一个 F F F值,这个 F F F值就可以认为是缩放前特征层的占比权重,如果模型认为这一层很有用,那 F F F值就会很大,放大它的作用。反之,模型认为这一层没什么用, F F F就会很小,起到抑制作用。
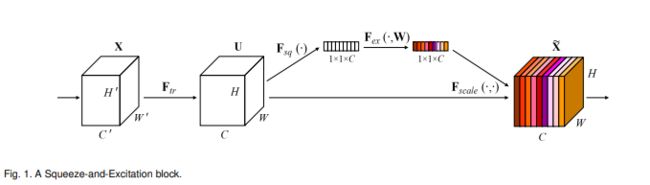
同理,Siam-NestedUNet也就是将这个结构当成一个组件,把所有骨干网络叠加在一起的特征层计算了一组注意力值,进而得出了不同时期特征层的作用。
3、Loss Function
损失函数由bce + dice loss组成。
bce
论文原文中,作者将weight cross entropy的公式看成一个二分类问题,其中 L w c e L_{wce} Lwce公式为
L w c e = 1 H ∗ W ∑ k = 1 H ∗ W w e i g h t [ c l a s s ] ∗ ( l o g ( e x p ( y [ k ] [ c l a s s ] ) ) ∑ l = 0 1 e x p ( y [ k ] [ l ] ) ) L_{wce} = \frac{1}{H * W}\sum^{H*W}_{k=1}{weight[class]}*(log(\frac{exp(y[k][class]))}{\sum_{l=0}^{1}{exp(y[k][l])}}) Lwce=H∗W1k=1∑H∗Wweight[class]∗(log(∑l=01exp(y[k][l])exp(y[k][class])))
其中class在变化检测中只为2,分别是变化类和非变化类,y代表预测。bce为wce的一种特例情况。
dice loss
Dice系数,是一种集合相似度度量函数,通常用于计算两个样本的相似度(值范围为 [0, 1]):
L d i c e = 2 ∣ X ∩ Y ∣ ∣ X ∣ + ∣ Y ∣ L_{dice} = \frac{2 |X\cap Y|}{|X| + |Y|} Ldice=∣X∣+∣Y∣2∣X∩Y∣
这也是语义分割中常用的交并比,X代表Ground Truth,Y代表Prediction。而在实际的变化检测问题中,我们也会将变化类以语义分割的方式进行标注。
4、应用场景
原文中,作者将其应用到了地质勘测的遥感图像中,是一个场景中,五年前和五年后的建筑物变化(道路、房屋的修建)。

虽然常用的语义分割、目标检测网络都已经很强悍了。但任然存在些许的漏检情况,所以我们经常看到的深度学习都是应用在安防安监领域,这些场景下,漏检率5%都可容忍的。但在要求更为严格的工业检测中,漏检是非常不能容忍的,即使你在为你的算法识别准确率达到96%而欢呼雀跃的时候,客户也会拿着那仅有的几个漏检样本问你:“为什么这个检测不出来?”,工厂流水线对漏检率是非常严格的,漏掉一个坏掉的零部件到下游厂商中,做出了一个成品损失可是好几千块。所以这也是为什么深度学习总在工业检测的外围,而不能在核心领域发挥作用的原因。
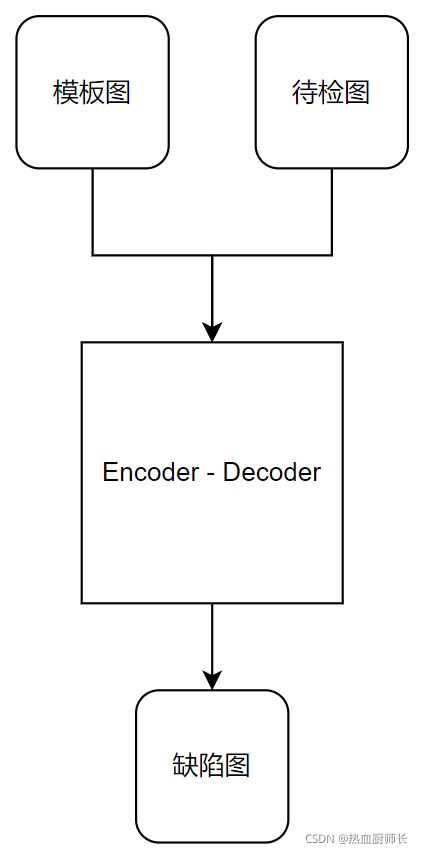
而Siam-NestedUNet虽然不能对工业的缺陷进行详细的分类,但他能保证不漏检,如果我们将问题具体化,则可以将良品当作模板图,待测样品当成待检图。这样通过变化检测,就有效的得出了异常的位置。
5、复现代码
作者开源的代码库在:https://github.com/likyoo/Siam-NestedUNet
笔者对其进行了修改,数据集是作者使用的遥感分割数据集,原图是1900x1000大小的。原作者将其改成了256x256大小的,代码库在:https://github.com/Runist/Siam-NestedUNet
- paper: Change detection in remote sensing images using conditional adversarial networks
- CDD (Change Detection Dataset)