关于聚类模型的一些理解和总结
简介
本文介绍的聚类模型有三类:K-means聚类算法(Kmeans++算法)、系统(层次聚类算法)、DBSCAN算法。聚类模型的主要思想:物以类聚,人以群分。聚类模型主要用于将某些数据分成几类。
注:(看不懂算法理论没关系,知道怎么样操作就行)
K-means聚类算法
理论流程图:
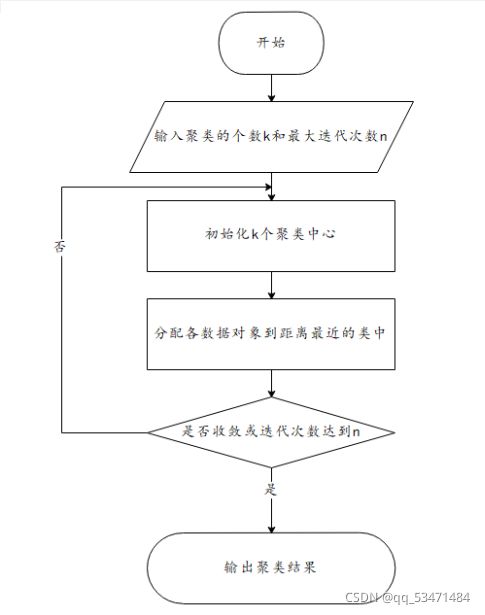
K-means算法的优缺点(写模型评价时写上去):
优点:算法简单快速,对于数据量较大时,效率较高;
缺点:使用者在开始时必须给定生成的种类K;对于初值比较敏感;对于孤立点的数据比较敏感;
在下方介绍的K-means算法可以解决后面两个缺点。
K-means++算法
算法介绍:

看不懂没关系,跟着操作就行
打开SPSS软件(软件版本越高越好),导入Excel的数据→点击“分析”→分类→点击“K-均值聚类”(SPSS里的K-均值聚类默认就是K-means++算法)
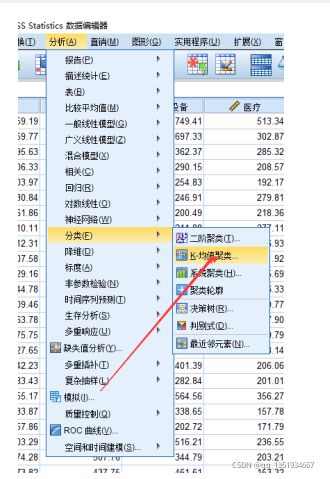
将对应的变量和依据导进去,聚类数(就是K,比如两类,三类)需要自己输入,再点击“迭代”→迭代的次数自己输入(比如10次,2次)→点击“保存”→勾选聚类成员和与聚类中心的距离→点击“选项”→勾选初始聚类中心、与聚类中心的距离→确定
现在就会出现聚类的结果,
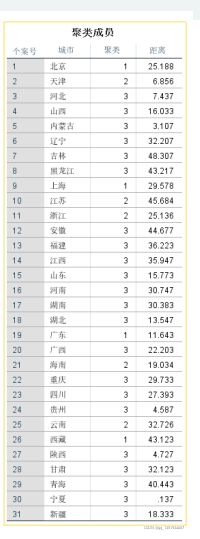
同时在原始数据的最后两列也会将分类的结果呈现出来
关于K-means算法的一些讨论:
聚类的个数也就是K值到底取多少比较合适,可以多尝试几个K值,看分成多少类好解释一点,多少类好解释就取几类。
如果出现数据的量纲不一样(通常为单位不一样,比如一个单位为米,一个单位为千克),出现这种情况时我们就需要消除量纲,如下操作:选中需要消除量纲的数据→点击“分析”→点击描述统计里的“描述”→将数据导入到变量,勾选“将标准化值另存为变量”,然后确定就好
这时就会出现结果,有一个“描述统计”的表格可以放在论文中,同时在原来的数据后面就会出现标准化后(消除量纲后)的数据,这时就可以用这些新数据重复上面的操作了。
系统(层次)聚类
原理如下:
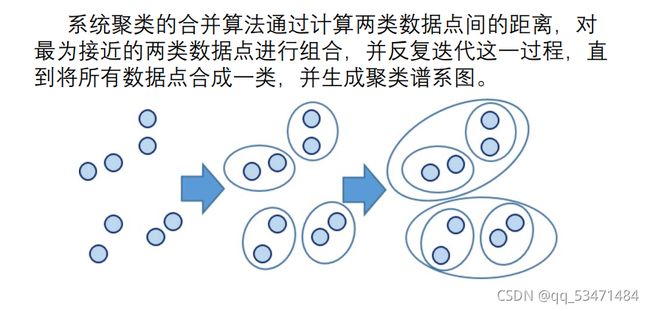
我的理解:在所有数据中选择距离最短的两个数据看作一类,两两一类,再在这些类中选择距离最短的两类看作一类,两两合成一个新的大类,以此类推,不断重复这个过程,直至形成最大的一类。
SPSS软件操作:
打开SPSS软件(软件版本越高越好)→导入Excel的数据→点击“分析”→分类→点击“系统聚类”
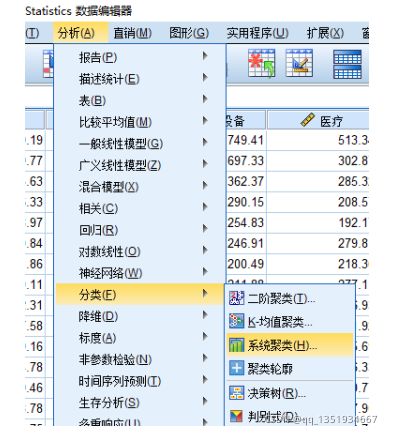
将数据导进变量和个案标注依据
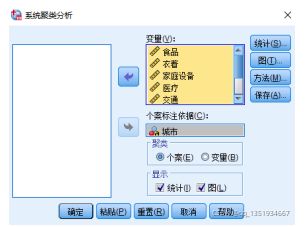
在图里面勾选上谱系图
如果数据有量纲,在方法里的转换值那里有个标准化,标准化里点Z得分就可以去掉量纲了
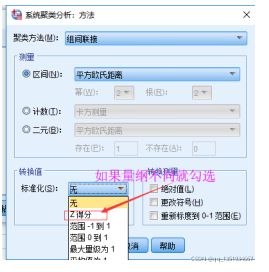
最后一直点确定就OK。
在生成的结果里有个聚类谱系图(树状图),这个图就是我们要的结果,比如下面这个:

可以看到,最终结果是分成了一个大类的,在这里面你想分成几类,就可以分成几类。右边的第一条红色竖线就将所有的数据分成了两类,一类是山西—海南,一类是福建—广东;第二条竖线就分成了三类,一类是山西—海南,一类是福建—北京,一类是上海—广东;以此类推......
但这里也没有给定合适的K 值,下面就介绍“肘部法则”可以确定K 值到底取多少
肘部法则
大致内容如下:

关于他的原理,反正我是没看懂,有想知道的自己去搜吧,不影响后面操作。
在之前生成的结果里有个“集中计划”表,将表里的系数那列复制到Excel并降序,生成一个散点图,可以适当的调整一下坐标轴,方便观察,最终呈现在论文里的结果如上面截图的那张散点图就可。分析也就照着截图的那样依葫芦画瓢,现在就可以确定K的取值了。
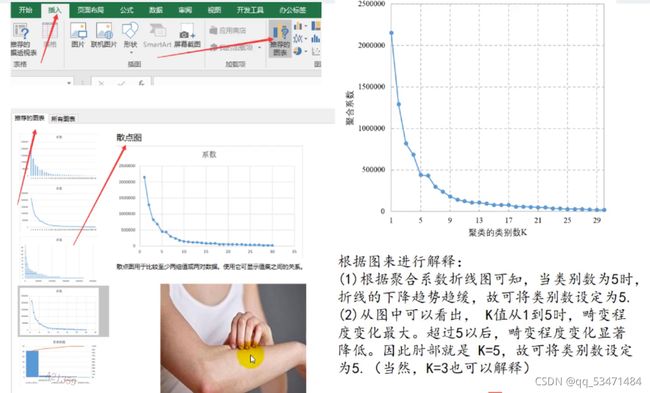
在确定K的取值后,便再次重复上面的操作,不过在保存那里就需要输入K的取值了,如下面这张图
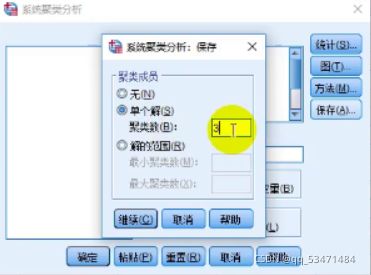
这里取的K 值是3,实际的K 取决于那张聚合系数散点图,,剩下的步骤都是一样的,最终就会在原始数据的后面出现聚类的结果(呈现在论文里的时候自己解释这三类分别是什么什么)接下来就画聚类的结果图。
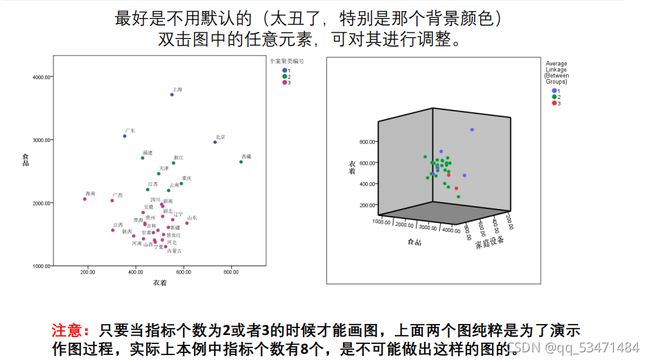
聚类结果图(指标如果是两个或三个就用这个图,三个以上就别用了,把这个放在论文里是个加分点)
步骤如下:
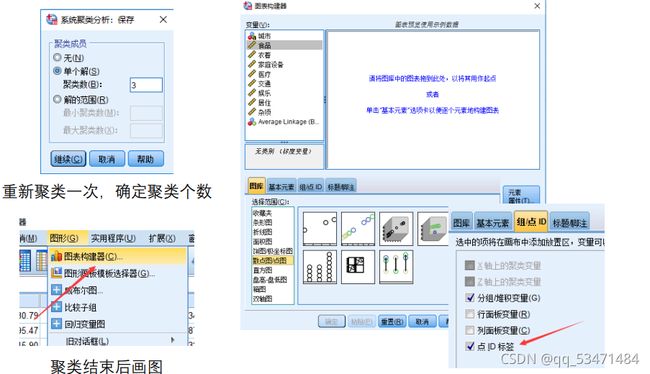
步骤:点击“图形"→图表构造器→图库里选择第二个或第四个图就好(两个指标选择第二个,三个指标选择第四个)→将对应的指标拖进坐标轴与设置颜色→在组、点里把点ID标签勾选上(方便观看)也把对应的元素托过去→确定
在生成的图里点击小圆点、文本、背景可以修改颜色,文本、颜色,搞成如下两个图就差不多了
DBSCAN算法
介绍:
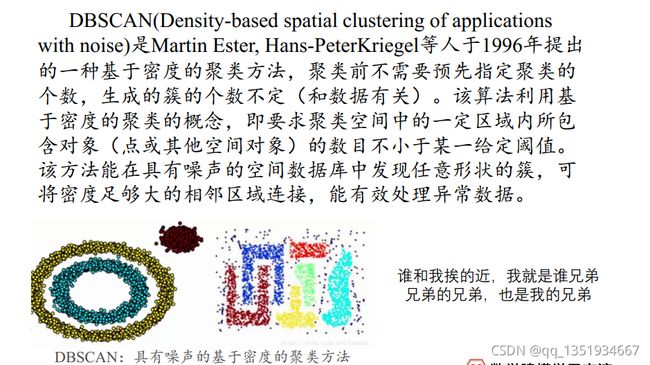
简洁的话来说就是:谁和我挨得近,谁是我兄弟,兄弟的兄弟,也是我的兄弟。
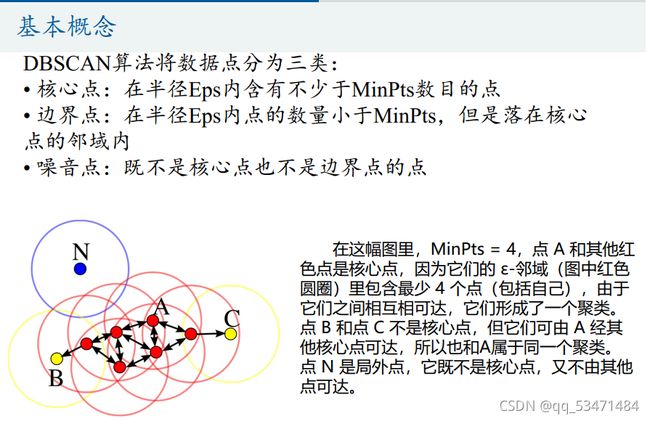
我的理解:Eps(到时候会让你自己取一个)就是半径的意思;Minpts(到时候也会让你自己取一个)就是在所有的数据中随即抽一个幸运儿数据,以这个幸运儿数据为圆点形成一个圆(半径就是自己取的那个半径),Minpts就是这个圆里面数据的个数。核心点,边界点,噪音点,就不解释了,应该看得懂吧。
代码
下面给出伪代码(想研究的自己研究,不影响后面,反正我不研究):

下面是Matlab代码:
clc;
clear;
close all;
%% Load Data
load mydata;
%% Run DBSCAN Clustering Algorithm
epsilon=0.5;
MinPts=10;
IDX=DBSCAN(X,epsilon,MinPts);
%% Plot Results
% 如果只要两个指标的话就可以画图啦
% PlotClusterinResult(X, IDX);
% title(['DBSCAN Clustering (\epsilon = ' num2str(epsilon) ', MinPts = ' num2str(MinPts) ')']);Minpts和Eosilon自己确定选择多少合适。
优缺点

图上说的很”DBSCAN“就是作出的散点图是呈现出来一个形状的话就用这个算法。
注:代码不要直接抄下来,怕查重,可加上自己的注释,或者将变量名这些给改了,这样就是自己的了,流程图这些也是的,自己画,也可以加深理解。