目标检测--YOLO v3论文阅读笔记
文章目录
- 前文阅读
- 一、前言
-
- 1.1 改进
-
- 1.1.1 新的网络结构
- 1.1.2 真正的多尺度
- 1.1.3 更新分类方式
- 网络结构分析
-
- 1、Bounding Box的预测(与YOLO v2一致)
- 2、分类预测 --- 独立的Logistics回归代替Softmax
- 3、多尺度的预测--专人专事
- 4、新的特征提取网络---DarkNet-53
- Loss函数
- 实验结果
- 一些无效的策略
-
- 1、直接预测 Anchor Box中 x,y的偏移
- 2、预测x,y偏移量,使用线性激活函数代替logistics激活函数
- 3、使用Focal Loss
- 4、双重IOU阈值
- 总结
- 代码阅读(待补充)
前文阅读
一、YOLO v1 论文阅读笔记(附代码)
二、YOLO v2 学习笔记
- 论文:YOLOv3: An Incremental Improvement
一、前言
YOLO v3的主要目的,还是要在不降低检测速度的前提下,提高检测精度。为此,作者做了一系列的尝试。
下图是YOLO v3和其他目标检测的方法对比,可以明显的看出,在性能相似的情况下YOLO v3的速度明显快于其他方法。

1.1 改进
1.1.1 新的网络结构

网 络 结 构 { 按 层 排 列 按 M o d u l e 排 列 网络结构 \begin{cases} 按层排列 \\ 按 Module 排列 \end{cases} 网络结构{ 按层排列按Module排列
1.1.2 真正的多尺度
- 尺度的理念来自于SIFT → \rightarrow → 特征金字塔
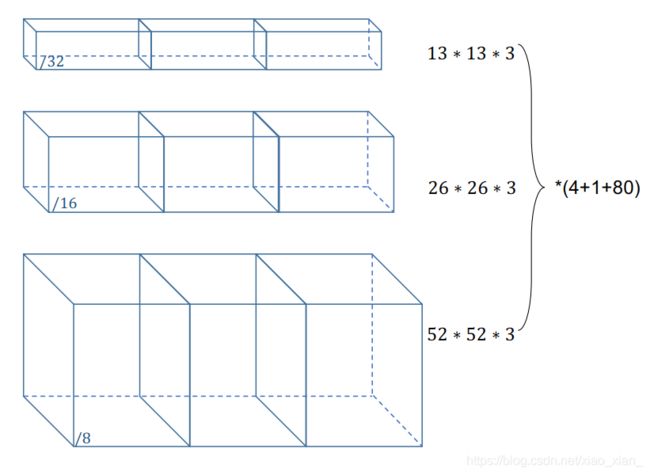
- 3种尺度;3 种Anchor(尺度;cell)
- 1/32;小尺度 feature map(13 ×13) → \rightarrow → 大 Anchor
- 1/16;中尺度 feature map(26 ×26) → \rightarrow → 中 Anchor
- 1/8;大尺度 feature map(52 ×52) → \rightarrow → 小 Anchor
1.1.3 更新分类方式
- 80 个类别,从 Softmax → \rightarrow → 逻辑回归(logistic)
网络结构分析
1、Bounding Box的预测(与YOLO v2一致)
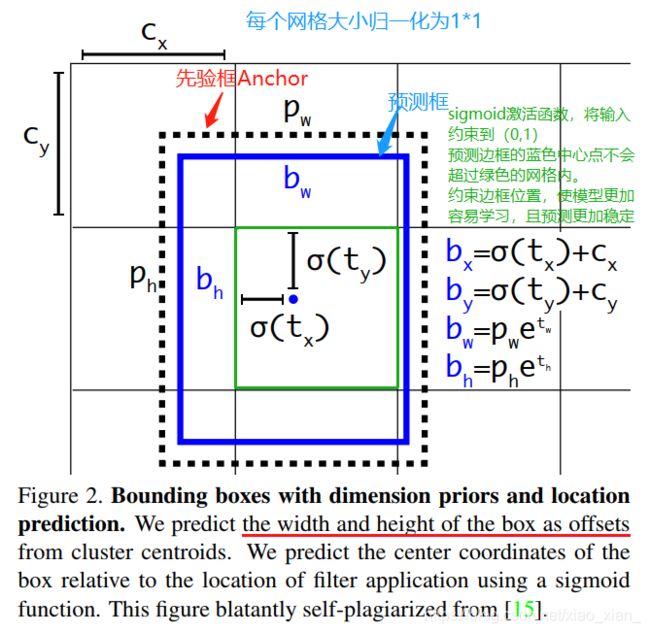
b x = σ ( t x ) + c x { {b_x} = {\sigma}({t_x}) + {c_x}} bx=σ(tx)+cx
b y = σ ( t y ) + c y { {b_y} = {\sigma}({t_y}) + {c_y}} by=σ(ty)+cy
b w = p w e t w {b_w} = {p_w}{e^{t_w}} bw=pwetw
b h = p h e t h {b_h} = {p_h}{e^{t_h}} bh=pheth
P r ( o b j e c t ) ∗ I O U ( b , o b j e c t ) = σ ( t o ) Pr(object) * IOU(b, object)={\sigma}({t_o}) Pr(object)∗IOU(b,object)=σ(to)
其中, b x , b y , b w , b h {b_x,b_y,b_w,b_h} bx,by,bw,bh是预测边框的中心和宽高。【最终的检测结果】
c x , c y {c_x,c_y} cx,cy是当前网格(grid)左上角到图像左上角的距离,要先将网格大小归一化,即令一个网络的 宽 = 1 , 高 = 1 宽=1,高=1 宽=1,高=1。
p w , p h {p_w,p_h} pw,ph是先验框(Anchor)的宽和高。 σ {\sigma} σ是Sigmoid激活函数。 t x , t y , t w , t h , t o {t_x,t_y,t_w,t_h,t_o} tx,ty,tw,th,to是要学习的参数,分别用于预测边框的中心和宽高,以及置信度。
P r ( o b j e c t ) ∗ I O U ( b , o b j e c t ) Pr(object) * IOU(b, object) Pr(object)∗IOU(b,object)是预测边框的置信度,这里对预测参数 t o {t_o} to 进行 σ {\sigma} σ变换后作为置信度的值。
2、分类预测 — 独立的Logistics回归代替Softmax
没有使用Softmax 而是使用独立的逻辑回归分类。
因为Softmax假设每个框都有一个类,而现实情况通常不是这样的。
多标签方法可以很好地建模数据。
3、多尺度的预测–专人专事
-
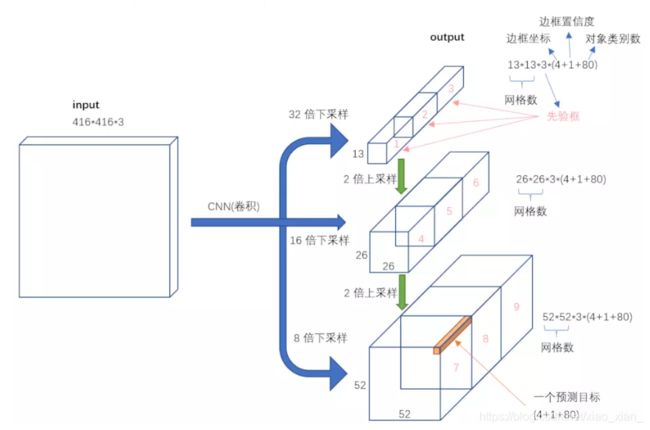
输出是 N ∗ N ∗ [ 3 ∗ ( 4 + 1 + 80 ) ] {N*N*[3*(4+1+80)]} N∗N∗[3∗(4+1+80)]
3 3 3表示的含义是,每个尺度下有3个不同的先验框 -
从3个尺度【1/32(32倍下采样),1/16(16倍下采样),1/8(8倍下采样)】进行预测,
-
Bouding Box 偏移量(4个);Objectness预测–置信度(1个);类别预测—(80维的one-hot向量)
-
在第79层之后经过几个卷积操作得到的是
1/32 (13*13)的预测结果,下采样倍数高,这里特征图的每个特征点感受野比较大,因此适合检测图像中尺寸比较大的对象。
K-means聚类得到先验框的尺寸:在最小的13*13特征图上(有最大的感受野)应用较大的先验框(116x90),(156x198),(373x326),适合检测较大的对象。 -
然后这个结果通过上采样与第61层的结果进行concat,再经过几个卷积操作得到1/16的预测结果;它具有中等尺度的感受野,适合检测
中等尺度的对象。
K-means聚类得到先验框的尺寸:中等的26*26特征图上(中等感受野)应用中等的先验框(30x61),(62x45),(59x119),适合检测中等大小的对象。 -
91层的结果经过上采样之后在于第36层的结果进行concat,经过几个卷积操作之后得到的是1/8的结果,
每个特征点的感受野最小,适合检测小尺寸的对象。
K-means聚类得到先验框的尺寸:较大的52*52特征图上(较小的感受野)应用较小的先验框(10x13),(16x30),(33x23),适合检测较小的对象。
-
-
concat:张量拼接。将darknet中间层和后面的某一层的上采样进行拼接。拼接的操作和残差层add的操作是不一样的,拼接会扩充张量的维度,而add只是直接相加不会导致张量维度的改变。
对于多尺度检测来说,采用多个尺度进行预测,具体形式是在网络预测的最后某些层进行上采样拼接的操作来达到;对于分辨率对预测的影响如下解释:
分辨率信息直接反映的就是构成object的像素的数量。一个object,像素数量越多,它对object的细节表现就越丰富越具体,也就是说分辨率信息越丰富。这也就是为什么大尺度feature map提供的是分辨率信息了。语义信息在目标检测中指的是让object区分于背景的信息,即语义信息是让你知道这个是object,其余是背景。在不同类别中语义信息并不需要很多细节信息,分辨率信息大,反而会降低语义信息,因此小尺度feature map在提供必要的分辨率信息下语义信息会提供的更好。(而对于小目标,小尺度feature map无法提供必要的分辨率信息,所以还需结合大尺度的feature map)
4、新的特征提取网络—DarkNet-53
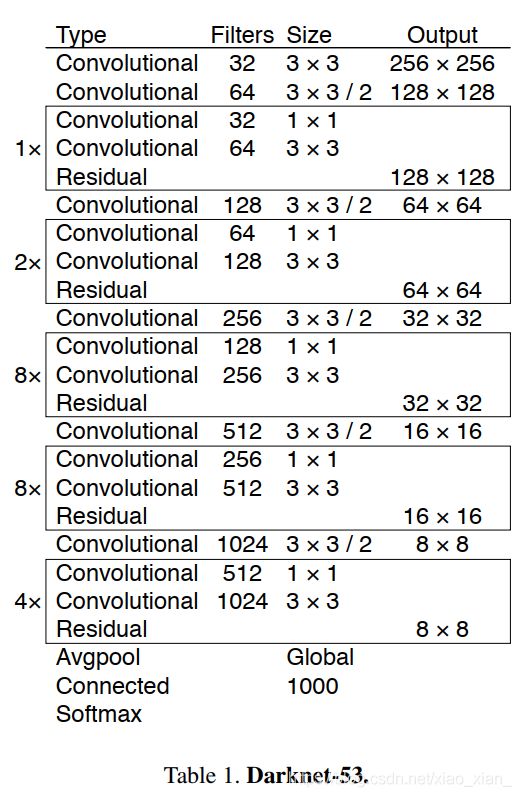
Darknet-53与其他网络的对比:
- Top-1 和 Top-5 代表的是精度信息
- Bn Ops
- BFL OP/s
- FPS

Loss函数

l b o x = λ c o o r d ∑ i = 0 s 2 ∑ j = 0 B 1 i , j o b j ( 2 − w i ∗ h i ) [ ( x i − x i ^ ) 2 + ( y i − y i ^ ) 2 + ( w i − w i ^ ) 2 + ( h i − h i ^ ) 2 ] − ( 1 ) l c l s = λ c l a s s ∑ i = 0 s 2 ∑ j = 0 B 1 i , j o b j ∑ c ∈ c l a s s e s p i ( c ) l o g ( p i ^ ( c ) ) − ( 2 ) l o b j = λ n o o b j ∑ i = 0 s 2 ∑ j = 0 B 1 i , j n o o b j ( c i − c i ^ ) 2 + λ o b j ∑ i = 0 s 2 ∑ j = 0 B 1 i , j o b j ( c i − c i ^ ) 2 − ( 3 ) l o s s = l b o x + l c l s + l o b j − ( 4 ) lbox = \lambda_{coord}\sum_{i=0}^{s^2}\sum_{j=0}^B 1_{i,j}^{obj}(2-w_i*h_i)[(x_i- \hat{x_i})^2 + (y_i- \hat{y_i})^2 + (w_i- \hat{w_i})^2 + (h_i- \hat{h_i})^2] \ \ \ -(1)\\ lcls = \lambda_{class}\sum_{i=0}^{s^2}\sum_{j=0}^B 1_{i,j}^{obj} \sum_{c\in classes}p_i(c)log(\hat{p_i}(c)) \ \ \ -(2)\\ lobj = \lambda_{noobj}\sum_{i=0}^{s^2}\sum_{j=0}^B 1_{i,j}^{noobj}(c_i - \hat{c_i})^2 +\lambda_{obj}\sum_{i=0}^{s^2}\sum_{j=0}^B 1_{i,j}^{obj}(c_i - \hat{c_i})^2 \ \ \ -(3)\\ loss = lbox + lcls + lobj\ \ \ -(4) lbox=λcoordi=0∑s2j=0∑B1i,jobj(2−wi∗hi)[(xi−xi^)2+(yi−yi^)2+(wi−wi^)2+(hi−hi^)2] −(1)lcls=λclassi=0∑s2j=0∑B1i,jobjc∈classes∑pi(c)log(pi^(c)) −(2)lobj=λnoobji=0∑s2j=0∑B1i,jnoobj(ci−ci^)2+λobji=0∑s2j=0∑B1i,jobj(ci−ci^)2 −(3)loss=lbox+lcls+lobj −(4)
从公式4可以看出,loss共包含3部分。
box_loss,S代表13,26,52,就是grid是几乘几的。B=5,平方差损失。
class_loss,和YOLO v2的区别是改成了交叉熵。
obj_confidence_loss,和YOLO v2一模一样。
实验结果

一些无效的策略
这些方法中的一些可能会产生良好的效果,它们只需要一些调整来稳定训练。
1、直接预测 Anchor Box中 x,y的偏移
使用线性激活函数,预测偏移x,y作为box宽或高的倍数。
无效的原因:
降低了模型的稳定性。
2、预测x,y偏移量,使用线性激活函数代替logistics激活函数
使准确率下降。
3、使用Focal Loss
准确率降低了2个MAP
因为它有单独的对象性预测和条件类预测。所以鲁棒性较好。
4、双重IOU阈值
Faster R-CNN使用双重阈值。
I O U > 0.7 IOU > 0.7 IOU>0.7:是简单有效的目标。
0.3 < I O U < 0.7 0.3
0.3 < I O U 0.3
总结
Y O L O v 3 的 主 要 改 进 { 设 计 了 新 的 分 类 网 络 − D a r k n e t − 53 设 计 了 多 尺 度 检 测 头 − 专 人 专 事 用 L o g i s t i c s 回 归 代 替 S o f t m a x 分 类 YOLO v3 的主要改进 \begin{cases} 设计了新的分类网络-Darknet-53 \\ 设计了多尺度检测头-专人专事 \\ 用Logistics回归代替Softmax分类 \end{cases} YOLOv3的主要改进⎩⎪⎨⎪⎧设计了新的分类网络−Darknet−53设计了多尺度检测头−专人专事用Logistics回归代替Softmax分类