Python 数据处理库 pandas 入门教程
这两行代码输出如下:pandas是一个Python语言的软件包,在我们使用Python语言进行机器学习编程的时候,这是一个非常常用的基础编程库。本文是对它的一个入门教程。
pandas提供了快速,灵活和富有表现力的数据结构,目的是使“关系”或“标记”数据的工作既简单又直观。它旨在成为在Python中进行实际数据分析的高级构建块。
加qq群813622576或vx;tanzhouyiwan免费领取学习资料
入门介绍
pandas适合于许多不同类型的数据,包括:
- 具有异构类型列的表格数据,例如SQL表格或Excel数据
- 有序和无序(不一定是固定频率)时间序列数据。
- 具有行列标签的任意矩阵数据(均匀类型或不同类型)
- 任何其他形式的观测/统计数据集。
由于这是一个Python语言的软件包,因此需要你的机器上首先需要具备Python语言的环境。关于这一点,请自行在网络上搜索获取方法。
关于如何获取pandas请参阅官网上的说明:pandas Installation。
通常情况下,我们可以通过pip来执行安装:

或者通过conda 来安装pandas:

目前(2018年2月)pandas的最新版本是v0.22.0(发布时间:2017年12月29日)。
我已经将本文的源码和测试数据放到Github上: pandas_tutorial ,读者可以前往获取。
另外,pandas常常和NumPy一起使用,本文中的源码中也会用到NumPy。
建议读者先对NumPy有一定的熟悉再来学习pandas,我之前也写过一个NumPy的基础教程,参见这里:Python 机器学习库 NumPy 教程
核心数据结构
pandas最核心的就是Series和DataFrame两个数据结构。
这两种类型的数据结构对比如下:

DataFrame可以看做是Series的容器,即:一个DataFrame中可以包含若干个Series。
注:在0.20.0版本之前,还有一个三维的数据结构,名称为Panel。这也是pandas库取名的原因:pan(el)-da(ta)-s。但这种数据结构由于很少被使用到,因此已经被废弃了。
Series
由于Series是一维结构的数据,我们可以直接通过数组来创建这种数据,像这样:

这段代码输出如下:
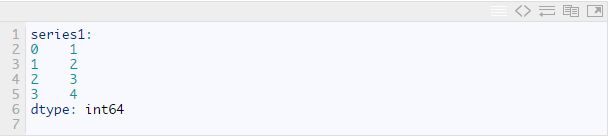
这段输出说明如下:
- 输出的最后一行是Series中数据的类型,这里的数据都是
int64类型的。 - 数据在第二列输出,第一列是数据的索引,在pandas中称之为
Index。
我们可以分别打印出Series中的数据和索引:
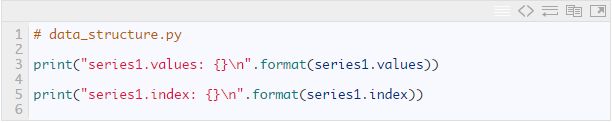
这两行代码输出如下:

如果不指定(像上面这样),索引是[1, N-1]的形式。不过我们也可以在创建Series的时候指定索引。索引未必一定需要是整数,可以是任何类型的数据,例如字符串。例如我们以七个字母来映射七个音符。索引的目的是可以通过它来获取对应的数据,例如下面这样:

这段代码输出如下:

DataFrame
下面我们来看一下DataFrame的创建。我们可以通过NumPy的接口来创建一个4×4的矩阵,以此来创建一个DataFrame,像这样:

这段代码输出如下:

从这个输出我们可以看到,默认的索引和列名都是[0, N-1]的形式。
我们可以在创建DataFrame的时候指定列名和索引,像这样:

这段代码输出如下:

我们也可以直接指定列数据来创建DataFrame:
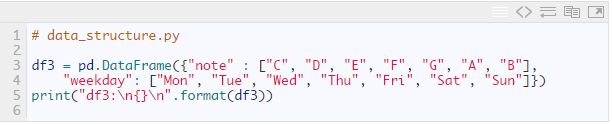
这段代码输出如下:

请注意:
- DataFrame的不同列可以是不同的数据类型
- 如果以Series数组来创建DataFrame,每个Series将成为一行,而不是一列
例如:

df4的输出如下:

我们可以通过下面的形式给DataFrame添加或者删除列数据:

这段代码输出如下:

Index对象与数据访问
pandas的Index对象包含了描述轴的元数据信息。当创建Series或者DataFrame的时候,标签的数组或者序列会被转换成Index。可以通过下面的方式获取到DataFrame的列和行的Index对象:

这两行代码输出如下:

请注意:
- Index并非集合,因此其中可以包含重复的数据
- Index对象的值是不可以改变,因此可以通过它安全的访问数据
DataFrame提供了下面两个操作符来访问其中的数据:
loc:通过行和列的索引来访问数据iloc:通过行和列的下标来访问数据
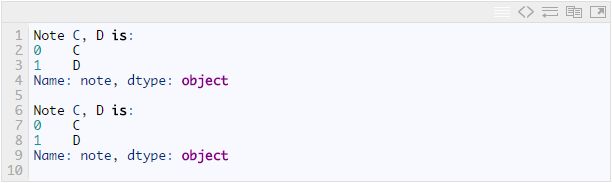
例如这样:

第一行代码访问了行索引为0和1,列索引为“note”的元素。第二行代码访问了行下标为0和1(对于df3来说,行索引和行下标刚好是一样的,所以这里都是0和1,但它们却是不同的含义),列下标为0的元素。
这两行代码输出如下:
文件操作
pandas库提供了一系列的read_函数来读取各种格式的文件,它们如下所示:
- read_csv
- read_table
- read_fwf
- read_clipboard
- read_excel
- read_hdf
- read_html
- read_json
- read_msgpack
- read_pickle
- read_sas
- read_sql
- read_stata
- read_feather
读取Excel文件
注:要读取Excel文件,还需要安装另外一个库:
xlrd
通过pip可以这样完成安装:

安装完之后可以通过pip查看这个库的信息:

接下来我们看一个读取Excel的简单的例子:

这个Excel的内容如下:

注:本文的代码和数据文件可以通过文章开头提到的Github仓库获取。
读取CSV文件
下面,我们再来看读取CSV文件的例子。
第一个CSV文件内容如下:

读取的方式也很简单:

我们再来看第2个例子,这个文件的内容如下:

严格的来说,这并不是一个CSV文件了,因为它的数据并不是通过逗号分隔的。在这种情况下,我们可以通过指定分隔符的方式来读取这个文件,像这样:

实际上,read_csv支持非常多的参数用来调整读取的参数,如下表所示:

详细的read_csv函数说明请参见这里:pandas.read_csv
处理无效值
现实世界并非完美,我们读取到的数据常常会带有一些无效值。如果没有处理好这些无效值,将对程序造成很大的干扰。
对待无效值,主要有两种处理方法:直接忽略这些无效值;或者将无效值替换成有效值。
下面我先创建一个包含无效值的数据结构。然后通过pandas.isna函数来确认哪些值是无效的:
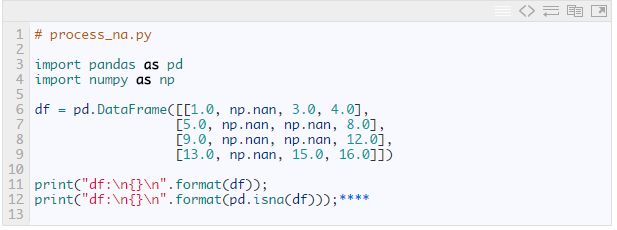
这段代码输出如下:
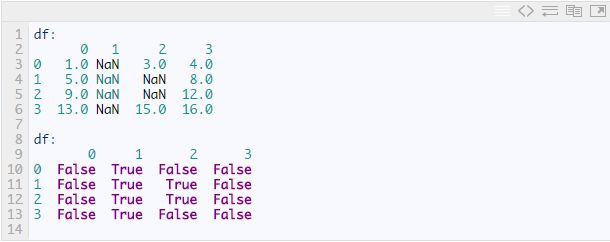
忽略无效值
我们可以通过pandas.DataFrame.dropna函数抛弃无效值:

注:
dropna默认不会改变原先的数据结构,而是返回了一个新的数据结构。如果想要直接更改数据本身,可以在调用这个函数的时候传递参数inplace = True。
对于原先的结构,当无效值全部被抛弃之后,将不再是一个有效的DataFrame,因此这行代码输出如下:

我们也可以选择抛弃整列都是无效值的那一列:

注:
axis=1表示列的轴。how可以取值’any’或者’all’,默认是前者。
这行代码输出如下:

替换无效值
我们也可以通过fillna函数将无效值替换成为有效值。像这样:

这段代码输出如下:

将无效值全部替换成同样的数据可能意义不大,因此我们可以指定不同的数据来进行填充。为了便于操作,在填充之前,我们可以先通过rename方法修改行和列的名称:

这段代码输出如下;

处理字符串
数据中常常牵涉到字符串的处理,接下来我们就看看pandas对于字符串操作。
Series的str字段包含了一系列的函数用来处理字符串。并且,这些函数会自动处理无效值。
下面是一些实例,在第一组数据中,我们故意设置了一些包含空格字符串:

在这个实例中我们看到了对于字符串strip的处理以及判断字符串本身是否是数字,这段代码输出如下:

下面是另外一些示例,展示了对于字符串大写,小写以及字符串长度的处理:

该段代码输出如下:

结束语
本文是pandas的入门教程,因此我们只介绍了最基本的操作。对于
- MultiIndex/Advanced Indexing
- Merge, join, concatenate
- Computational tools
之类的高级功能,以后有机会我们再来一起学习。
加qq群813622576或vx;tanzhouyiwan免费领取学习资料