hbaseAPI操作
目录
1.创建连接,以及创建一张表
2.put方法插入数据
3.get方法
4.list()方法
5.修改表的结构
6.删除表
7.批量插入数据
8.CellUtil
根据自己用的hbase版本 需要导入的依赖
org.apache.hbase hbase-client 1.4.6
1.创建连接,以及创建一张表
流程如下:
1、创建一个配置文件,查看你安装hbase的conf目录下 有一个 hbase-site.xml文件
里面存储的zookeeper节点信息,以及你的三台主机名称
2、创建连接
3、如果需要对表结构操作 则getAdmin;对数据进行操作,则getTable
4、 创建一张表,并指定一个列簇
5、对列簇可以追加配置,如versions,ttl等,下面图中有详细的,
6、创建表
7、关闭连接

import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.HColumnDescriptor;
import org.apache.hadoop.hbase.HTableDescriptor;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.Admin;
import org.apache.hadoop.hbase.client.Connection;
import org.apache.hadoop.hbase.client.ConnectionFactory;
import org.junit.Before;
import org.junit.Test;
import java.io.IOException;
public class HbaseAPI1 {
//将连接conn,admin设置为全局变量方便下面的测试方法使用
Connection conn;
Admin admin;
@Before
public void GetConn()throws IOException {
Configuration conf= HBaseConfiguration.create();
//配置ZK的地址,通过zookeeper可以找到HBase
conf.set("hbase.zookeeper.quorum", "master:2181,node1:2181,node2:2181");
//获取和hbase的连接,
//如果需要对数据进行操作,
conn = ConnectionFactory.createConnection(conf);
//通过admin可以管理habse上的表结构
admin = conn.getAdmin();
}
/**
*创建一个表
*/
@Test
public void createTable() throws IOException {
//首先,我们确定我们的表名,在hbase中创建表的时候还必须指定一个列簇
HTableDescriptor table = new HTableDescriptor(TableName.valueOf("test3"));
//创建一个列簇对象
HColumnDescriptor info = new HColumnDescriptor("info");
//设置最大versions,这样我们就可以通过get查询到一条数据的不同version
info.setMaxVersions(3);
//像表中添加列簇
table.addFamily(info);
//创建表,通过admin,没啥好说的
admin.createTable(table);
//关闭连接
admin.close();
conn.close();
}
}
运行完成后,list查看一下有没有新创建的表
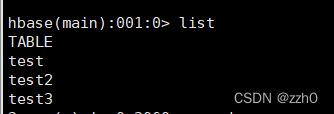
2.put方法插入数据
/**
* put 插入数据
*/
@Test
public void put() throws IOException {
//先获取我们要操作的表
Table table = conn.getTable(TableName.valueOf("test3"));
//向table中插入数据,要求传入的是一个put对象
//我们这里创建put对象的时候,先传入的是行键
Put put = new Put("001".getBytes());
//相当于插入一列(一个cell)数据
//我这里传入三个参数:列簇,列明,存储的值 ;
//都需要用getbytes转换,因为hbase存储数据就只有byte类型
put.addColumn("info".getBytes(),"name".getBytes(),"zhaosi".getBytes());
put.addColumn("info".getBytes(),"age".getBytes(),"24".getBytes());
put.addColumn("info".getBytes(),"gender".getBytes(),"male".getBytes());
table.put(put);
}运行完成查看一下结果,插入成功了

3.get方法
根据row key获取一条数据
@Test
public void get() throws IOException {
//获取表'test3'
Table table = conn.getTable(TableName.valueOf("test3"));
//我们使用get方法,需要传入一个Get类型的对象
//创建对象时需要传入行键
Get get = new Get("001".getBytes());
Result result = table.get(get);
//getRow()方法获取Row key
byte[] row = result.getRow();
//Bytes.toString()是hadoop.hbase里面的一个工具类,能将字节数组转换成String类型
String rowkey = Bytes.toString(row);
System.out.println(rowkey);
//获取cell,就要通过getValue方法
byte[] name = result.getValue("info".getBytes(),"name".getBytes());
byte[] age = result.getValue("info".getBytes(),"age".getBytes());
byte[] gender = result.getValue("info".getBytes(),"gender".getBytes());
String name1=Bytes.toString(name);
String age1=Bytes.toString(age);
String gende1r=Bytes.toString(gender);
System.out.println("rowkey:"+rowkey+"\t"+"name:"+name1+"\t"+"age:"+age1+"\t"+"gender:"+gender1);
}看一下运行结果
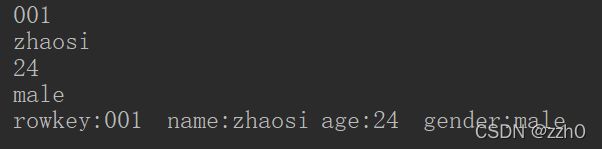
4.list()方法
@Test
public void list() throws IOException {
//通过名字不难看出这个操作是获取表名的列表,所以这获取的结果是一个数组
TableName[] tableNames = admin.listTableNames();
//遍历数组,但是这类型是TableName,我们通过getNameAsString()转化成String类型
for (TableName name : tableNames) {
System.out.println(name.getNameAsString());
}
}运行结果

5.修改表的结构
能修改的还有不少,我这里就写2个
给指定的列簇设置ttl
新增一个列簇
@Test
public void modifyTable() throws IOException {
//首先还是获取这个表
TableName table = TableName.valueOf("test3");
//添加表结构,需要传入表名,表结构
//step1:获取原来的表结构,我们要在原来的表结构上修改列簇的属性
HTableDescriptor tableDescriptor = admin.getTableDescriptor(table);
//获取表的全部列簇,返回一个数组
HColumnDescriptor[] columnFamilies = tableDescriptor.getColumnFamilies();
//遍历这些结构,将info列簇的生存周期设置成10000
for (HColumnDescriptor cf : columnFamilies) {
if("info".equals(cf.getNameAsString())){
cf.setTimeToLive(10000);
}
}
//新增一个列簇
HColumnDescriptor info1 = new HColumnDescriptor("info1");
tableDescriptor.addFamily(info1);
//传入表名,和表的结构
admin.modifyTable(table,tableDescriptor);
}运行结果,确实增加了新的列簇info1,列簇info的ttl也更改成了10000

6.删除表
先判断是否存在,直接删的,如果不存在可能会报错
@Test
public void dropTable() throws IOException {
//获取这个表
TableName table = TableName.valueOf("test3");
//先判断这个表存不存在,存在的话先disable,再删除
if(admin.tableExists(table)){
admin.disableTable(table);
admin.deleteTable(table);
}
}7.批量插入数据
几条数据,用put方法还说的过去,几千条难道还手打吗?
这里演示将文本的数据导入到表中

根据我们的数据确定怎么建表
首先确定行键,这第一个数据是学生id就直接作为行键了
后面的内容分为4个列插入
/**
* 导入数据,通过IO流
* 在插入数据的时候考虑:数据不能读一行就向hbase中put一次
* 这样效率太低,应该将读取的数据先存储起来
* 到达一定的规模,再写入到hbase中(批处理),这就减少了很多写入的次数
* 所以完成的速度会快很多
*/
@Test
public void putALL() throws IOException {
BufferedReader br = new BufferedReader(new FileReader("data/students.txt"));
Table table = conn.getTable(TableName.valueOf("student"));
String line=null;
//既然要数据到达一定规模才能写入,我们就先创建一个集合存储插入hbase的数据
ArrayList puts = new ArrayList();
int batchSize=11;
while((line=br.readLine())!=null){
//按行读取数据,通过","分割
String[] split = line.split(",");
String id = split[0];
String name = split[1];
String age = split[2];
String gender = split[3];
String clazz = split[4];
Put put = new Put(id.getBytes());
byte[] info = "info".getBytes();
put.addColumn(info,"name".getBytes(),name.getBytes());
put.addColumn(info,"age".getBytes(),age.getBytes());
put.addColumn(info,"gender".getBytes(),gender.getBytes());
put.addColumn(info,"clazz".getBytes(),clazz.getBytes());
puts.add(put);
if(puts.size()==batchSize){
table.put(puts);
//插入完成后清空集合内容,还需要给下面的数据使用
puts.clear();
}
//如果最后几条数据没有到达上面设置的大写就不会被写入,
//所以我们还得再将没有插入的数据put进去
if(!puts.isEmpty()){
table.put(puts);
}
// br.close();
} 查看一下数据有没有插入成功

打印一下10行看看结果,没有问题
@Test
public void scan() throws IOException {
Table student = conn.getTable(TableName.valueOf("student"));
Scan scan = new Scan();
scan.setLimit(10);
for (Result result : student.getScanner(scan)) {
String id = Bytes.toString(result.getRow());
String name= Bytes.toString(result.getValue("info".getBytes(),"name".getBytes()));
String age = Bytes.toString(result.getValue("info".getBytes(),"age".getBytes()));
String gender= Bytes.toString(result.getValue("info".getBytes(),"gender".getBytes()));
String clazz = Bytes.toString(result.getValue("info".getBytes(),"clazz".getBytes()));
System.out.println(id+","+name+","+age+","+gender+","+clazz);
}
}
8.CellUtil
不知道你有你没有注意到:我们再上面获取数据的时候,每一条都要指定列名,
String name= Bytes.toString(result.getValue("info".getBytes(),"name".getBytes()));
String age = Bytes.toString(result.getValue("info".getBytes(),"age".getBytes()));
String gender= Bytes.toString(result.getValue("info".getBytes(),"gender".getBytes()));
String clazz = Bytes.toString(result.getValue("info".getBytes(),"clazz".getBytes())); 其实有个方法可以直接获取每条数据,不用考虑每条数据具体的结构是什么
CellUtil:hbase中的工具类
从每一个cell中取出数据,不考虑具体结构
与get方法相比,设置最大versions后就可以查看所有版本的数据
/**
* CellUtil
*/
@Test
public void ScanCellUtil() throws IOException {
Table student = conn.getTable(TableName.valueOf("student"));
Scan scan = new Scan();
//scan扫描指定开始位置的Row key
scan.withStartRow("1500100980".getBytes());
//扫描student表,获取result数组,里面是按row key存储的数据
for (Result result : student.getScanner(scan)) {
String id = Bytes.toString(result.getRow());
// 将一条数据的所有的cell列举出来
// 使用CellUtil从每一个cell中取出数据
// 每一个cell由行键,列簇,列可以确定处理,所以一条数据多少列就多少cell(按最新的version算的)
// 每个单元格可以对应多个version,我这里就不指定了,默认显示最新的数据
List| cells = result.listCells();
for (Cell cell : cells) {
String value = Bytes.toString(CellUtil.cloneValue(cell));
System.out.print(value+" ");
}
//输出完一整条数据就换行
System.out.println();
}
} |