大数据实时阶段_Day07_Hbase
HBASE数据库
- Hbase基础
1.1 hbase数据库介绍
1、简介
hbase是基于Google BigTable模型开发的,典型的key/value系统。是建立在hdfs之上,提供高可靠性、高性能、列存储、可伸缩、实时读写nosql的数据库系统。它是Apache Hadoop生态系统中的重要一员,主要用于海量结构化和半结构化数据存储。
它介于nosql和RDBMS之间,仅能通过主键(row key)和主键的range来检索数据,仅支持单行事务(可通过hive支持来实现多表join等复杂操作)。
Hbase查询数据功能很简单,不支持join等复杂操作,不支持复杂的事务(行级的事务)
与hadoop一样,Hbase目标主要依靠横向扩展,通过不断增加廉价的商用服务器,来增加计算和存储能力。
HBase中的表一般有这样的特点:
- 大:一个表可以有上十亿行,上百万列
- 无模式:每行都有一个可排序的主键和任意多的列,列可以根据需要动态的增加,同一张表中不同的行可以有截然不同的列;
- 面向列:面向列(族)的存储和权限控制,列(族)独立检索。
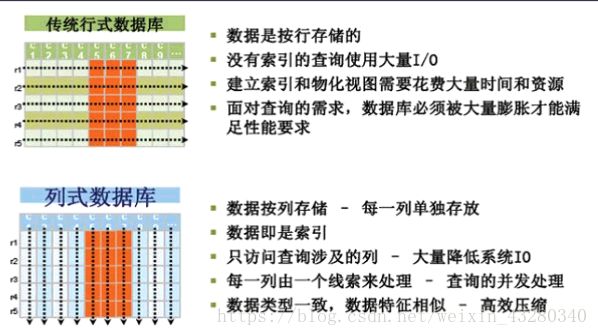
- 稀疏:对于为空(null)的列,并不占用存储空间,因此,表可以设计的非常稀疏。
- 数据多版本:每个单元中的数据可以有多个版本,默认情况下版本号自动分配,是单元格插入时的时间戳
- 数据类型单一:Hbase中的数据都是字节数组 byte[]。
1.2 Hbase表结构
- 表(table):用于存储管理数据,具有稀疏的、面向列的特点。HBase中的每一张表,就是所谓的大表(Bigtable),可以有上亿行,上百万列。对于为值为空的列,并不占用存储空间,因此表可以设计的非常稀疏。
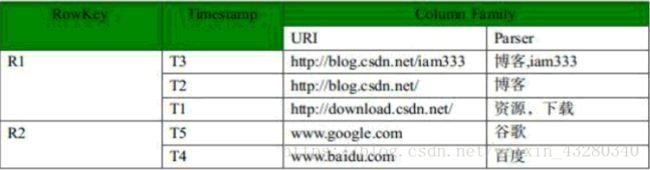
- 行键(RowKey):类似于MySQL中的主键,HBase根据行键来快速检索数据,一个行键对应一条记录。与MySQL主键不同的是,HBase的行键是天然固有的,每一行数据都存在行键。
- 列族(ColumnFamily):是列的集合。列族在表定义时需要指定,而列在插入数据时动态指定。列中的数据都是以二进制形式存在,没有数据类型。在物理存储结构上,每个表中的每个列族单独以一个文件存储(参见图1.2)。一个表可以有多个列簇。
- 时间戳(TimeStamp):是列的一个属性,是一个64位整数。由行键和列确定的单元格,可以存储多个数据,每个数据含有时间戳属性,数据具有版本特性。可根据版本(VERSIONS)或时间戳来指定查询历史版本数据,如果都不指定,则默认返回最新版本的数据。
- 区域(Region):HBase自动把表水平划分成的多个区域,划分的区域随着数据的增大而增多。
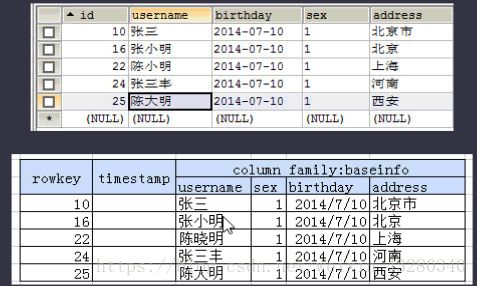
动手实践:将以下用户的信息保存到Hbase中
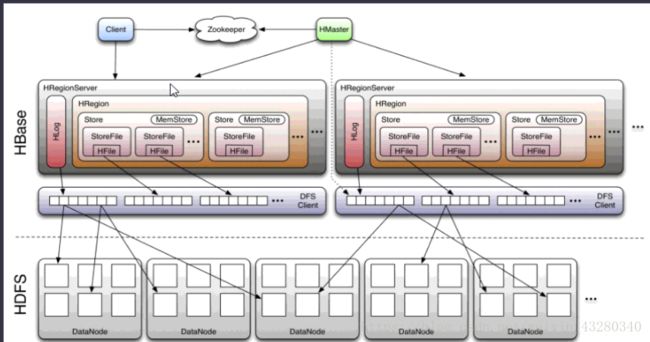
- Hbase的整体架构
2、Hbase集群部署
下载地址
操作步骤说明:
- 下载安装包
- 修改配置文件
- regionservers
- hbase-site.xml
- hbase-env.sh
- 拷贝hadoop配置文件
- 分发配置文件
- 启动集群
2.1 下载安装包
wget http://mirrors.hust.edu.cn/apache/hbase/1.3.1/hbase-1.3.1-bin.tar.gz
tar -zxvf hbase-1.3.1-bin.tar.gz -C /export/servers/
cd ../servers/
mv hbase-1.3.1 hbase
vi /etc/profile
-
export HBASE_HOME=/export/servers/hbase
export PATH=${HBASE_HOME}/bin:$PATH
-
source /etc/profile
2.2 修改配置文件
进入配置文件所在的目录
cd /export/servers/hbase/conf/
修改第一个配置文件 regionservers
vi regionservers
-
node02
node03
修改第二个配置文件 hbase-site.xml
注意:以下配置集成的是hadoop ha集群。
如果您的集群没有配置ha,hbase.rootdir 配置项目需要修改:hdfs://master:9000/hbase
vi hbase-site.xml
-
<configuration>
<property>
<name>hbase.rootdirname>
<value>hdfs://ns1/hbasevalue>
property>
<property>
<name>hbase.cluster.distributedname>
<value>truevalue>
property>
<property>
<name>hbase.master.portname>
<value>16000value>
property>
<property>
<name>hbase.zookeeper.property.dataDirname>
<value>/export/data/zk/value>
property>
<property>
<name>hbase.zookeeper.quorumname>
<value>node01,node02,node03value>
property>
<property>
<name>hbase.zookeeper.property.clientPortname>
<value>2181value>
property>
configuration>
修改第三个配置文件 hbase-env.sh
HBASE_MANAGES_ZK=false 表示,hbase和大家伙公用一个zookeeper集群,而不是自己管理集群。
vi hbase-env.sh
-
export JAVA_HOME=/export/servers/jdk
export HBASE_MANAGES_ZK=false
修改第四个配置文件 拷贝hadoop配置文件
拷贝hadoop的配置文件到hbase的配置文件目录
![]()
2.3 分发安装文件并启动
分发配置文件
scp -r /export/servers/hbase/ node02:/export/servers/
scp -r /export/servers/hbase/ node03:/export/servers/
启动集群
startzk.sh
start-dfs.sh
start-hbase.sh
有这两个进程表示启动成功
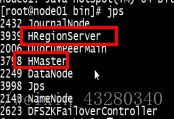
启动异常:
2017-12-27 06:27:54,882 INFO [node01:16000.activeMasterManager] master.ServerManager: Waiting for region servers count to settle; currently checked in 0, slept for 67247 ms, expecting minimum of 1, maximum of 2147483647, timeout of 4500 ms, interval of 1500 ms.
解决办法:
保证每台机器时间一致。
ntpdate -u 0.uk.pool.ntp.org
ntpdate -u 1.uk.pool.ntp.org
3、Hbase Shell操作
3.1 连接集群
hbase shell
3.2 创建表
create 'user','base_info'
3.3 插入数据
put 'user','rowkey_10','base_info:username','张三'
put 'user','rowkey_10','base_info:birthday','2014-07-10'
put 'user','rowkey_10','base_info:sex','1'
put 'user','rowkey_10','base_info:address','北京市'
put 'user','rowkey_16','base_info:username','张小明'
put 'user','rowkey_16','base_info:birthday','2014-07-10'
put 'user','rowkey_16','base_info:sex','1'
put 'user','rowkey_16','base_info:address','北京'
put 'user','rowkey_22','base_info:username','陈小明'
put 'user','rowkey_22','base_info:birthday','2014-07-10'
put 'user','rowkey_22','base_info:sex','1'
put 'user','rowkey_22','base_info:address','上海'
put 'user','rowkey_24','base_info:username','张三丰'
put 'user','rowkey_24','base_info:birthday','2014-07-10'
put 'user','rowkey_24','base_info:sex','1'
put 'user','rowkey_24','base_info:address','河南'
put 'user','rowkey_25','base_info:username','陈大明'
put 'user','rowkey_25','base_info:birthday','2014-07-10'
put 'user','rowkey_25','base_info:sex','1'
put 'user','rowkey_25','base_info:address','西安'
3.4 查询表中的所有数据
scan 'user'
3.5 查询某个rowkey的数据
get 'user','rowkey_16'
3.6 查询某个列簇的数据
get 'user','rowkey_16','base_info'
get 'user','rowkey_16','base_info:username'
get 'user', 'rowkey_16', {
COLUMN => ['base_info:username','base_info:sex']}
3.7 删除表中的数据
delete 'user', 'rowkey_16', 'base_info:username'
3.8 清空数据
truncate 'user'
3.9 操作列簇
alter 'user', NAME => 'f2'
alter 'user', 'delete' => 'f2'
3.10 删除表
disable 'user'
drop 'user'
3.11 命令表
可以通过HbaseUi界面查看表的信息
端口60010打不开的情况,是因为hbase 1.0 以后的版本,需要自己手动配置,在文件 hbase-site
<property>
<name>hbase.master.info.portname>
<value>60010value>
property>
4、HBase Java API
4.1 导入pom依赖
<dependency>
<groupId>org.apache.hbasegroupId>
<artifactId>hbase-clientartifactId>
<version>1.3.1version>
dependency>
4.2 添加配置文件
在resource目录下创建hbase-site.xml
<configuration>
<property>
<name>hbase.zookeeper.quorumname>
<value>zk01,zk02,zk03value>
<description>The directory shared by region servers.
description>
property>
configuration>
4.3 连接Hbase
// hbase的两种连接方式:1)读取配置文件 只需要配置zookeeper
Configuration config = HBaseConfiguration.create();
Connection connection = ConnectionFactory.createConnection(config);
//2)通过代码配置
Configuration configuration = new Configuration();
configuration.set("hbase.zookeeper.quorum", "zk01:2181,zk02:2181,zk03:2181");
connection = ConnectionFactory.createConnection();
4.4 创建表
public static void main(String[] args) throws IOException {
// 1.连接HBase
// 1.1 HBaseConfiguration.create();
Configuration config = HBaseConfiguration.create();
// 1.2 创建一个连接
Connection connection = ConnectionFactory.createConnection(config);
// 1.3 从连接中获得一个Admin对象
Admin admin = connection.getAdmin();
// 2.创建表
// 2.1 判断表是否存在
TableName tableName = TableName.valueOf("user");
if (!admin.tableExists(tableName)) {
//2.2 如果表不存在就创建一个表
HTableDescriptor hTableDescriptor = new HTableDescriptor(tableName);
hTableDescriptor.addFamily(new HColumnDescriptor("base_info"));
admin.createTable(hTableDescriptor);
System.out.println("创建表");
}
}
。
4、HBase Java API
4.1 导入pom依赖
<dependency>
<groupId>org.apache.hbasegroupId>
<artifactId>hbase-clientartifactId>
<version>1.3.1version>
dependency>
4.2 添加配置文件
在resource目录下创建hbase-site.xml
<configuration>
<property>
<name>hbase.zookeeper.quorumname>
<value>zk01,zk02,zk03value>
<description>The directory shared by region servers.
description>
property>
configuration>
4.3 连接Hbase
// hbase的两种连接方式:1)读取配置文件 只需要配置zookeeper
Configuration config = HBaseConfiguration.create();
Connection connection = ConnectionFactory.createConnection(config);
//2)通过代码配置
Configuration configuration = new Configuration();
configuration.set("hbase.zookeeper.quorum", "zk01:2181,zk02:2181,zk03:2181");
connection = ConnectionFactory.createConnection();
4.4 创建表
public static void main(String[] args) throws IOException {
// 1.连接HBase
// 1.1 HBaseConfiguration.create();
Configuration config = HBaseConfiguration.create();
// 1.2 创建一个连接
Connection connection = ConnectionFactory.createConnection(config);
// 1.3 从连接中获得一个Admin对象
Admin admin = connection.getAdmin();
// 2.创建表
// 2.1 判断表是否存在
TableName tableName = TableName.valueOf("user");
if (!admin.tableExists(tableName)) {
//2.2 如果表不存在就创建一个表
HTableDescriptor hTableDescriptor = new HTableDescriptor(tableName);
hTableDescriptor.addFamily(new HColumnDescriptor("base_info"));
admin.createTable(hTableDescriptor);
System.out.println("创建表");
}
}
4.5 打印表的信息
@Before
public void initConnection() {
try {
connection = ConnectionFactory.createConnection(config);
} catch (IOException e) {
System.out.println("连接数据库失败");
}
}
@Test
public void tableInfo() throws IOException {
// 1.定义表的名称
TableName tableName = TableName.valueOf("user");
// 2.获取表
Table table = connection.getTable(tableName);
// 3.获取表的描述信息
HTableDescriptor tableDescriptor = table.getTableDescriptor();
// 4.获取表的列簇信息
HColumnDescriptor[] columnFamilies = tableDescriptor.getColumnFamilies();
for (HColumnDescriptor columnFamily : columnFamilies) {
// 5.获取表的columFamily的字节数组
byte[] name = columnFamily.getName();
// 6.使用hbase自带的bytes工具类转成string
String value = Bytes.toString(name);
// 7.打印
System.out.println(value);
}
}
4.6 添加数据(PUT)
@Before
public void initConnection() {
try {
connection = ConnectionFactory.createConnection(config);
} catch (IOException e) {
System.out.println("连接数据库失败");
}
}
@Test
public void put() throws IOException {
// 1.定义表的名称
TableName tableName = TableName.valueOf("user");
// 2.获取表
Table table = connection.getTable(tableName);
// 3.准备数据
String rowKey = "rowkey_10";
Put zhangsan = new Put(Bytes.toBytes(rowKey));
zhangsan.addColumn(Bytes.toBytes("base_info"), Bytes.toBytes("username"), Bytes.toBytes("张三"));
zhangsan.addColumn(Bytes.toBytes("base_info"), Bytes.toBytes("sex"), Bytes.toBytes("1"));
zhangsan.addColumn(Bytes.toBytes("base_info"), Bytes.toBytes("address"), Bytes.toBytes("北京市"));
zhangsan.addColumn(Bytes.toBytes("base_info"), Bytes.toBytes("birthday"), Bytes.toBytes("2014-07-10"));
// 4. 添加数据
table.put(zhangsan);
table.close();
}
4.7 获取数据(Get)
@Test
public void get() throws IOException {
// 1.定义表的名称
TableName tableName = TableName.valueOf("user");
// 2.获取表
Table table = connection.getTable(tableName);
// 3.准备数据
String rowKey = "rowkey_10";
// 4.拼装查询条件
Get get = new Get(Bytes.toBytes(rowKey));
// 5.查询数据
Result result = table.get(get);
// 6.打印数据 获取所有的单元格
List<Cell> cells = result.listCells();
for (Cell cell : cells) {
// 打印rowkey,family,qualifier,value
System.out.println(Bytes.toString(CellUtil.cloneRow(cell))
+ "==> " + Bytes.toString(CellUtil.cloneFamily(cell))
+ "{" + Bytes.toString(CellUtil.cloneQualifier(cell))
+ ":" + Bytes.toString(CellUtil.cloneValue(cell)) + "}");
}
}
4.8 全表扫描(scan 慎用)

@Test
public void scan() throws IOException {
// 1.定义表的名称
TableName tableName = TableName.valueOf("user");
// 2.获取表
Table table = connection.getTable(tableName);
// 3.全表扫描
Scan scan = new Scan();
// 4.获取扫描结果
ResultScanner scanner = table.getScanner(scan);
Result result = null;
// 5. 迭代数据
while ((result = scanner.next()) != null) {
// 6.打印数据 获取所有的单元格
List<Cell> cells = result.listCells();
for (Cell cell : cells) {
// 打印rowkey,family,qualifier,value
System.out.println(Bytes.toString(CellUtil.cloneRow(cell))
+ "==> " + Bytes.toString(CellUtil.cloneFamily(cell))
+ "{" + Bytes.toString(CellUtil.cloneQualifier(cell))
+ ":" + Bytes.toString(CellUtil.cloneValue(cell)) + "}");
}
}
}
4.9 范围查询(开始行-结束行)
在4.8的基础上修改代码如下
Scan scan = new Scan();
scan.setStartRow(Bytes.toBytes("rowkey_1"));
scan.setStopRow(Bytes.toBytes("rowkey_2"));

5、使用过滤器进行查询
5.1 比较过滤器有几种?
- RowFilter 基于RowKey的过滤
- FamilyFilter 基于列簇的过滤
- QualifierFilter 基于字段的过滤
- ValueFilter 基于值的过滤
- DependentColumnFilter 参考值过滤器

5.2 比较运算符?
- LESS 匹配小于设定值的值
- LESS_OR_EQUAL 匹配小于或等于设定值的值
- EQUAL 匹配等于设定值的值
- NOT_EQUAL 匹配与设定值不相等的值
- GREATER_OR_EQUAL 匹配大于或等于设定值的值
- GREATER 匹配大于设定值的值
- NO_OP 排除一切值
5.3 比较器有哪些?
- BinaryComparator 使用Bytes.compareTo()比较当前的阈值
- BinaryPrefixComparator 与上面的相似,使用Bytes.compareTo()进行匹配,但是是从左端开始前缀匹配
- NullComparator 不做匹配,只判断当前值不是null
- BitComparator 通过BitWiseOp类提供的按位与(AND)、或(OR)、异或(XOR)操作执行位级比较。
- RegexStringComparator 根据一个正则表达式,在实例化这个比较器的时候去匹配表中的数据。
- SubStringComparator 把阈值和表中数据String实例,同时通过contains()操作匹配字符串
5.4 示例代码
//创建RowFilter过滤器
RowFilter rowFilter = new RowFilter(CompareFilter.CompareOp.EQUAL
, new BinaryComparator("rowkey_10".getBytes()));
//创建familyFilter过滤器
FamilyFilter familyFilter = new FamilyFilter(CompareFilter.CompareOp.NO_OP,
new BinaryComparator("base_Info".getBytes()));
//创建qualifierFilter过滤器
QualifierFilter qualifierFilter = new QualifierFilter(CompareFilter.CompareOp.EQUAL,
new BinaryComparator("username".getBytes()));
//创建valueFilter过滤器
ValueFilter valueFilter = new ValueFilter(CompareFilter.CompareOp.EQUAL,
new BinaryComparator("张三".getBytes()));
5.5、查询值等于张三的所有数据
@Test
public void tesValueFilter() throws IOException {
//1、创建过滤器
ValueFilter filter = new ValueFilter(CompareFilter.CompareOp.EQUAL, new BinaryComparator("张三".getBytes()));
//2、创建扫描器
Scan scan = new Scan();
//3、将过滤器设置到扫描器中
scan.setFilter(filter);
//4、获取HBase的表
Table table = connection.getTable(TableName.valueOf("user"));
//5、扫描HBase的表(注意过滤操作是在服务器进行的,也即是在regionServer进行的)
ResultScanner scanner = table.getScanner(scan);
for (Result result : scanner) {
// 6.打印数据 获取所有的单元格
List<Cell> cells = result.listCells();
for (Cell cell : cells) {
// 打印rowkey,family,qualifier,value
System.out.println(Bytes.toString(CellUtil.cloneRow(cell))
+ "==> " + Bytes.toString(CellUtil.cloneFamily(cell))
+ "{" + Bytes.toString(CellUtil.cloneQualifier(cell))
+ ":" + Bytes.toString(CellUtil.cloneValue(cell)) + "}");
}
}
}
6、HBase的rowkey的设计原则
HBase是三维有序存储的,通过rowkey(行键),column key(column family和qualifier)和TimeStamp(时间戳)这个三个维度可以对HBase中的数据进行快速定位。
HBase中rowkey可以唯一标识一行记录,三种查询方式
- 通过get方式,指定rowkey获取唯一一条记录
- 通过scan方式,设置startRow和stopRow参数进行范围匹配
- 全表扫描,即直接扫描整张表中所有行记录
6.1 Rowkey长度原则
rowkey是一个二进制码流,可以是任意字符串,最大长度64kb,实际应用中一般为10-100bytes,以byte[]形式保存,一般设计成定长。
建议越短越好,不要超过16个字节
数据的持久化文件HFile中是按照KeyValue存储的,如果rowkey过长,比如超过100字节,1000w行数据,光rowkey就要占用100*1000w=10亿个字节,将近1G数据,这样会极大影响HFile的存储效率;
MemStore将缓存部分数据到内存,如果rowkey字段过长,内存的有效利用率就会降低,系统不能缓存更多的数据,这样会降低检索效率。
目前操作系统都是64位系统,内存8字节对齐,控制在16个字节,8字节的整数倍利用了操作系统的最佳特性。
6.2 Rowkey 散列原则
如果rowkey按照时间戳的方式递增,不要将时间放在二进制码的前面,建议将rowkey的高位作为散列字段,由程序随机生成,低位放时间字段,这样将提高数据均衡分布在每个RegionServer,以实现负载均衡的几率。如果没有散列字段,首字段直接是时间信息,所有的数据都会集中在一个RegionServer上,这样在数据检索的时候负载会集中在个别的RegionServer上,造成热点问题,会降低查询效率。
6.3 Rowkey唯一原则
必须在设计上保证其唯一性,rowkey是按照字典顺序排序存储的,因此,设计rowkey的时候,要充分利用这个排序的特点,将经常读取的数据存储到一块,将最近可能会被访问的数据放到一块。
6.4 什么是热点
HBase中的行是按照rowkey的字典顺序排序的,这种设计优化了scan操作,可以将相关的行以及会被一起读取的行存取在临近位置,便于scan。然而糟糕的rowkey设计是热点的源头。热点发生在大量的client直接访问集群的一个或极少数个节点(访问可能是读,写或者其他操作)。大量访问会使热点region所在的单个机器超出自身承受能力,引起性能下降甚至region不可用,这也会影响同一个RegionServer上的其他region,由于主机无法服务其他region的请求。设计良好的数据访问模式以使集群被充分,均衡的利用。
为了避免写热点,设计rowkey使得不同行在同一个region,但是在更多数据情况下,数据应该被写入集群的多个region,而不是一个。
6.5 避免热点
6.5.1 加盐
这里所说的加盐不是密码学中的加盐,而是在rowkey的前面增加随机数,具体就是给rowkey分配一个随机前缀以使得它和之前的rowkey的开头不同。分配的前缀种类数量应该和你想使用数据分散到不同的region的数量一致。加盐之后的rowkey就会根据随机生成的前缀分散到各个region上,以避免热点。
6.5.2 哈希
哈希会使同一行永远用一个前缀加盐。哈希也可以使负载分散到整个集群,但是读却是可以预测的。使用确定的哈希可以让客户端重构完整的rowkey,可以使用get操作准确获取某一个行数据
6.5.3 反转
第三种防止热点的方法时反转固定长度或者数字格式的rowkey。这样可以使得rowkey中经常改变的部分(最没有意义的部分)放在前面。这样可以有效的随机rowkey,但是牺牲了rowkey的有序性。
以手机号为rowkey,可以将手机号反转后的字符串作为rowkey,这样的就避免了以手机号那样比较固定开头导致热点问题
7、扩展阅读
- Hive与Hbase整合
- Hbase协处理器(一)
- Hbase协处理器(二)
- Hbase二级索引
- 来自华为的 HBase 二级索引
- Phoenix hbase