论文地址:基于神经网络的实时语音增强的加权语音失真损失
论文代码:https://github.com/GuillaumeVW/NSNet
引用:Xia Y, Braun S, Reddy C K A, et al. Weighted speech distortion losses for neural-network-based real-time speech enhancement[C]//ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2020: 871-875.
摘要
本文研究了训练RNN(递归神经网络)的几个方面,影响客观和主观的增强语音质量的实时单通道语音增强。具体地说,我们重点研究了一种基于单帧输入、单帧输出的RNN,这是一种被大多数经典信号处理方法所采用的框架。我们提出了两个新颖的均方误差学习target,能够分别控制语音失真和降噪的重要性。提出的损失函数通过广泛接受的客观质量和可理解性度量进行评估,并与其他方法进行比较。此外,我们还研究了特征归一化和不同批量序列长度对增强语音客观质量的影响。最后,我们对所提出的方法和一种先进的实时RNN方法进行了主观评价。
关键词:实时语音增强,递归神经网络,损失函数,语音失真,平均意见评分
1 引言
语音增强(Speech Enhance,SE)算法旨在改善被加性噪声降级的语音信号的语音质量和可理解性[1],以改善人类或机器对语音的理解,典型的语音增强应用包括助听器、自动语音识别和噪声环境中的音视频通信。大多数SE方法将频谱抑制增益或过滤应用于时频域中的有噪语音信号[2]。在最近使用深度神经网络(DNNs)的有监督学习方法中,DNN通常被设置为从来自噪声语音的一组或多组特征中估计这个时变增益函数[3]。
在线处理能力是SE算法的一个吸引人的特征,并且对于实时通信应用是必需的。虽然大多数经典的SE方法必须适应它们的方法[4,5,6,7]来实现因果关系,但文献[3,8,9]中的许多基于DNN的方法并没有强制执行这一约束。几种基于DNN的方法使用宽泛的前瞻[8,9]报告了高质量的增强,但是它们在降低前瞻方面的性能没有得到很好的研究。然而,与经典方法相比,基于DNN的系统具有精确抑制瞬态噪声的能力。在这项工作中,我们研究了基于递归神经网络(RNN)的实时语音增强。最近涉及RNNs的工作显示出令人振奋的结果[10],即使在非常低信噪比(SNR)的情况下也是如此[11,12]。
设计用于音频/视频通信的SE算法的关键挑战是在抑制噪声的同时最大限度地保持感知(主观)语音质量。在经典文献中,优化这样一个复合全局目标可以通过求解一个受约束的目标函数来完成[13]。或者,可以优化更简单的目标,如(对数)均方误差(MSE)[6,14],并采用后处理模块,如残余噪声去除[7]和增益限制[15]。相比之下,深度学习框架的一个主要好处是相对容易纳入复杂的学习目标,人们认为这将推动增强的语音朝着更好的质量和清晰度发展。沿着这条思路的方法包括从异质特征中学习多个目标[16,17,18],联合优化最终目标及其子目标(例如,语音存在概率)[10,12],以及直接针对语音质量或清晰度的客观度量进行优化[19,20]。后者似乎是一种改进客观质量的有前途的方法,尽管由于每个客观测量的频带限制,这两个模型都必须结合标准的MSE。[21]据报道,简单的感知加权宽带MSE本身并不能改善客观语音质量或清晰度,这表明MSE仍然是宽带语音增强的可靠学习目标。
本文提出了一种基于DNN的实时在线语音增强系统。首先,我们将讨论使用RNN促进模式学习的特征和归一化技术。然后,我们描述了一种从单个噪声帧产生增益函数的紧凑RNN。接下来,我们介绍了两个简单的基于均方误差的损失函数,分别控制语音失真和去噪。在评估过程中,我们深入考察了错误加权对主客观语音质量和清晰度的影响。此外,我们还讨论了不同的特征归一化技术和训练策略对客观度量的影响。
2 问题表述
我们假设要在短时傅立叶变换(STFT)域中描述的麦克风信号为:
$$公式1:X[t,k]=S[t,k]+N[t,k]$$
其中$X[t,k]$、$S[t,k]$和$N[t,k]$分别表示观察到的带噪语音、干净语音和噪声在时间帧$t$和频段bin$k$处的STFT。我们的系统在短时傅立叶变换幅度(STFTM)域$G[t,k]$中寻找一个时变增益函数,它可以最大限度地恢复$|S[t,k]|$。
$$公式2:|\hat{S}[t,k]|=G[t,k]|X[t,k]|$$
在实时处理中,$G[t,k]$仅取决于输入的过去和现在信息,并由下式给出
$$公式3:G[t, k]=n(g(f(|X[l, k]|)) ; \Theta), l \leq t$$
其中,$f$是应用于noisy信号的STFTM上的变换函数,$g$是归一化函数,以及$n$是其自适应参数一起由$\Theta $表示的DNN。最后,将$X[t,k]$noisy相位应用于$|\hat{S}[t,k]|$以获得增强的信号。
在接下来的几节中,我们将回顾最先进的方法,然后讨论我们对$f$和$g$的选择,$n$的架构,$\Theta $的两个学习目标,以及我们认为会影响增强语音质量的培训方面的进一步考虑。
3 最先进的在线降噪技术
经典的在线SE方法通常通过优化一些统计意义上的目标函数来寻找最优增益函数,这类方法中最有效的方法之一是假设噪声和噪声的STFT是不相关的复高斯分布,并通过最小化clean和增强的STFTM[6]或log-STFTM[14]之间的均方误差来求解G[t,k]。虽然可以结合更先进的噪声和语音存在概率模型来提高语音质量和防止音乐噪声[4,5],但在去除高度非平稳噪声的同时保持语音质量仍然是一项艰巨的任务。
在最近的基于DNN的方法中,通常放弃了关于有噪声的和干净的STFTM分布的统计假设,而最小均方误差(MMSE)目标变成了DNN通过随机梯度下降来优化的损失函数。最流行的损耗函数之一是介于清洁和增强STFTM之间的MSE
$$公式4:L(\vec{G} ; \vec{S}, \vec{X})=\operatorname{mean}\left(\|\vec{S}-\vec{G} \odot \vec{X}\|_{2}^{2}\right)$$
其中$\vec{A}$表示向量形式的$|A[t,k]|$,$\odot $是元素形式的乘积。最近提出的一种方法[10]使用RNN估计平滑能量轮廓的最佳增益函数,并通过基音滤波内插频谱细节。实验[10,22]报告了该RNNoise系统产生的增强语音具有很强的客观和主观语音质量。
4 提出的方法
4.1 特征表示
选择合适的特征和归一化是成功训练DNN的关键。我们考虑了STFTM和对数功率谱(LPS)的两个基本特征,并分别应用全局、频率依赖(Frequency Dependent,FD)和频率独立(Frequency Independent,FI)归一化来训练我们的网络。
在我们所有的系统中使用的STFTM是基于32 ms的汉明窗口(帧之间有75%的重叠)和512点离散傅里叶变换计算的。LPS采用自然对数,地板在-120 dB,即:
$$公式5:f_{L P S}(|X[t, k]|)=\log \left(\max \left(|X[t, k]|^{2}, 10^{-12}\right)\right)$$
我们探索了三种类型的归一化,分别与上述STFTM或LPS单独结合。首先,我们考虑全局归一化,在这种情况下,每个频率bin通过其均值和从训练集累积的标准差进行标准化
$$公式6:g_{G}(f(|X[t, k]|))=\left[f(|X[t, k]|)-\mu_{f(x)}[k]\right] / \sigma_{f(x)}[k]$$
其次,我们考虑在线(online) FD均值和方差标准化,在这种情况下,运行均值和方差被一个衰减指数平滑
$$公式7:\mu_{f(x)}[t, k]=c \mu_{f(x)}[t-1, k]+(1-c) f(|X[t, k]|)$$
$$公式8:\sigma_{f(x)}^{2}[t, k]=c \sigma_{f(x)}^{2}[t-1, k]+(1-c) f(|X[t, k]|)^{2}$$
$$公式9:g_{F D}(f(|X[t, k]|))=\frac{f(|X[t, k]|)-\mu_{f(x)}[t, k]}{\sqrt{\sigma_{f(x)}^{2}[t, k]-\mu_{f(x)}^{2}[t, k]}}$$
其中$c=exp(-\triangle t/\tau )$,$\triangle t$是以秒为单位的帧移位(在我们的设置中是8毫秒),$\tau $是一个时间常数,用来控制适应速度。其思想是,归一化的频谱将促进神经网络的长期循环学习模式。最后,我们还进行了FI在线归一化,在这种情况下,平均每个频率的均值和方差并应用于所有频率。该方法保持了频率箱之间的相对动态,但可能会给学习机带来更大的学习挑战。在我们所有的实验中,除了特征实验,我们使用FD在线归一化,$\tau = 3s$。
4.2 学习机制
我们的学习机器以门控循环单元(GRU)[23]为基础,接收一帧带噪语音谱,输出一帧幅度增益函数。考虑到GRU的计算效率和实时SE任务的优越性能,它比长短期内存(LSTM)[24]更受青睐。我们将三个GRU层堆叠起来,然后是一个具有sigmoid激活的全连接(FC)输出层,以预测增益函数$G[t, k]$。
值得一提的是,我们没有像在其他相关工作中经常做的那样应用卷积层[11,25],因为在选择频率跨度和滤波器抽头的数量时涉及到相对任意的过程。先前的研究[26]已经表明一个naive卷积层应用于过去和现在的输入噪声帧并没有改善增强语音的客观质量。相反,我们通过训练不同长度、特征和损失函数的序列来探索网络的时间建模能力。
4.3 损失函数
我们使用三个损失函数来训练我们的系统。首先,我们在(4)中使用纯净STFTM和增强STFTM之间的regular MSE。为了更好地控制损失,我们建议将error分为语音失真和降噪项
$$公式10:L_{\text {speech }}=\operatorname{mean}\left(\left\|\vec{S}_{\mathrm{SA}}-(\vec{G} \odot \vec{S})_{\mathrm{SA}}\right\|_{2}^{2}\right)$$
$$公式11:L_{\text {noise }}=\operatorname{mean}\left(\|\vec{G} \odot \vec{N}\|_{2}^{2}\right)$$
其中下标SA表示语音处于活动状态的框架子集。在我们的实验中,我们采用了一个简单的基于能量的帧级语音活动检测器,它对纯净语音的功率谱进行操作。短时语音能量在300hz和5000 Hz之间积累,并通过移动平均滤波器平滑3帧。最后,决定在低于整个语音峰值能量30分贝的阈值上发声一帧。
当估计增益接近all-pass时,语音失真误差最小,噪声误差最大,反之亦然。因此,我们可以用一个固定的加权损失来控制语音失真对降噪的相对重要性
$$公式12:L\left(\vec{G} ; \vec{S}_{\mathrm{SA}}, \vec{N}\right)=\alpha L_{\text {speech }}+(1-\alpha) L_{\text {noise }}$$
式中$\alpha$为[0,1]范围内的常数。我们注意到一个类似的损失是独立发展的,被称为双组分损失(2CL)[27]。接下来,我们讨论了这个固定权重的扩展。
在经典的语音增强文献中,抑制规则通常是根据信噪比来调整的[15,13]。具体来说,抑制应限制在高信噪比,以避免伪影,并在低信噪比是积极。基于这一原则,我们的第二个信噪比加权损失在(12)中使用每个语音的全局信噪比进行调整
$$公式13:\alpha=\frac{SNR}{SNR+\beta }$$
其中,$SNR=\frac{||\vec{S}||_2^2}{||\vec{N}||_2^2}$和$\beta$为常数。请注意,当SNR=$\beta$时,$d\alpha/d[10log+{10}(SNR)]$最大化。$\beta$控制全局 SNR,在该位置固定量的偏差会导致语音失真加权的最大漂移。 此外,还表示全局 SNR,其中两个损失项的权重相等。 我们在图 1 中说明了这一点。

图1 选择信噪比加权的语音失真加权。水平线表示$L_{speech}$和$L_{noise}$的权重相等
所提出的方法如图2所示的流程图所示。在训练过程中,计算加权损失既需要纯净语音,也需要噪声。训练后的模型每次一帧增强带噪声的STFTM,利用带噪声的相位重构增强后的语音波形。
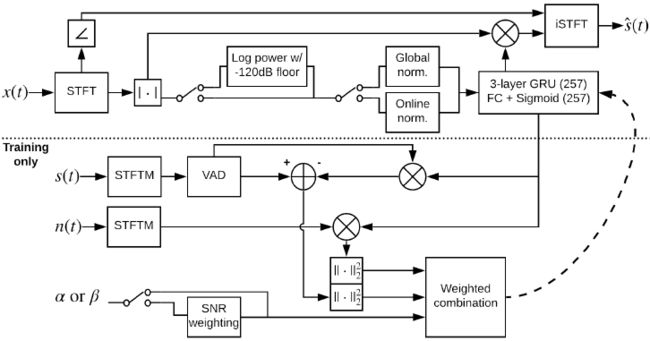
图2 提出的系统流程图
5 实验结果与讨论
5.1 语料库与实验设置
我们使用MS-SNSD数据集[22]和工具包1使用从公开可用的语音和噪声语料库合成的数据集来训练和评估所有基于DNN的系统。14种不同的噪声类型被选择用于训练,而来自9种不包括在训练集中的噪声类型的样本被用于评估。我们的测试集包括挑战性和高度非平稳的噪音类型,如咀嚼、多人交谈、键盘打字等。所有音频片段都被重新采样到16 kHz。训练集包括84小时的干净语音和噪声,而18小时(5500个片段)的有噪语音构成评估集。所有语音片段在每个话语的基础上被电平归一化,而每个噪声片段被缩放以具有来自f40、30、20、10、0gdB的五个全局SNR中的一个。在下面描述的所有基于DNN的系统的训练过程中,我们分别随机选择干净语音和噪声的摘录,然后将它们混合来创建有噪声的话语。
我们基于几个客观的语音质量和清晰度指标和主观测试,对所提出的方法进行了三个基线的比较研究。具体地说,我们包括语音质量感知评估(PESQ)[28]、短时客观清晰度(STOI)[29]、倒谱距离(CD)和尺度不变信噪比(SI-SDR)[30],用于在时间域、频谱域和倒谱域对增强语音进行客观评估。我们使用[22]中提出的基于网络的主观框架进行了主观听力测试。每个剪辑都由20位众包听众以1(非常差的语音质量)到5(极好的语音质量)之间的离散评级进行评级。在向这些听众展示测试剪辑之前,要确保培训和资格认证。所有20个收视率的平均值是该剪辑的平均意见分数(MOS)。我们还删除了在整个MOS测试中选择相同评级的明显垃圾邮件发送者。我们的主观测试与其他客观评估相辅相成,从而为评估所研究的降噪算法提供了一个平衡的基准。
我们将我们提出的方法与三种基线方法进行了比较。我们使用了经典的增强器,它是对[31]中描述的MMSE对数谱振幅(LSA)估计器[14]的略微优化的实现。基于DNN的基线包括改进的RNNoise(RNNoiseI)[22]和RNN(RNNoise257),该RNN复制RNNoise[10]的网络体系结构,但是在257点频谱上操作,在(4)上进行训练,并且不具有最初提出的后处理组件。RNNoise257实现了一个具有与所提出的方法相当数量的参数的系统。
在下一节中,我们讨论了不同序列长度上的特征归一化和训练对增强语音的客观质量的影响。然后,我们探讨了所提出的固定加权损失函数和信噪比加权损失函数的最优加权。最后,我们将我们的系统生成的增强语音的主客观质量与几种好胜在线方法进行了比较。
5.2 结果和讨论
我们想要评估用长序列或短序列训练如何影响RNN中的时间建模。虽然长序列有望帮助处理长期噪声模式,但它也可能潜在地降低只是短期静止的语音。表1总结了序列长度对客观语音质量的影响。对于每个设置,我们调整小批量中的序列数量,以便一批始终包含一分钟的嘈杂语音。我们观察到,随着每个数据段增加到5秒,性能有了显著的改善,超过5秒后,性能改善开始减弱。由于篇幅限制,我们没有给出特征测试的结果,但总的来说,STFTM和LPS特征的所有归一化变体之间几乎没有区别,而没有归一化会导致退化。一般来说,我们推荐FD在线归一化,因为它对不同的信号电平具有不变性。我们还建议在训练期间使用每个不少于5秒的片段。
表1 一分钟小批量中序列长度的影响

语音失真加权的效果如图3所示,其中改变$\alpha$或$\beta $以搜索每个客观测量的最佳点。奇怪的是,在这两种情况下,只有STOI和CD在相同的系数上达成一致,而PESQ和SI-SDR都表明语音失真的权重较小。所有指标的最佳信噪比权重都集中在20dB左右,这意味着只有在噪声信号相对干净的情况下,语音失真权重才应该迅速增加。总体而言,在所有指标中,固定权重都略好于SNR权重。

图3 固定加权和信噪比加权对客观语音质量和清晰度测量的影响。
黑色虚线垂直线表示每个度量的最佳系数。
注意,STOI和CD的最佳点在$\alpah = 0.65$和$\beta =18.2 $dB处重合。
在实验中,我们注意到,即使我们的系统在MSE(例如,表1中的第4行)上训练的系统可以达到与那些基于拟议的加权损失(12)训练的系统类似的客观度量,但基于加权损失训练的系统的相应主观质量要好得多。基于我们的损失函数训练的系统,特别是在小的情况下,最显著的改进是估计的增益函数比基于规则MSE训练的系统具有更强的频率选择性,导致更高的噪声抑制,特别是在高信噪比的情况下。为了证明这一点,我们在表2中给出了在线主观听力测试的结果。我们选择的所有系统不仅显著优于[22]中提出的基于MSE的改进的RNNoise(RNNoiseI),而且令我们惊讶的是,听力测试对象更喜欢相当低的语音失真权重设置。所有客观指标以及作者的主观偏好约$\alpha$=0.35都错误地预测了这一趋势。当低于0.35时,我们观察到明显的语音失真,而噪声变得更受抑制。显然,在未来的工作中需要进行更详细的调查,以更好地揭示不同听众群体的语音失真和降噪偏好。
表2 主观MOS从5500个剪辑和20个评级的剪辑

最后,我们报告了从每个基线方法、带噪参考和甲骨文维纳过滤作为上界的客观评估,如表3所示。从我们的方法中选择的系统使用固定的语音失真加权(α=0.35时)进行训练,我们认为该方法在语音失真和去噪之间取得了很好的平衡。虽然这种设置可能不是人类监听器最喜欢的,但是可以很容易地调优到不同的应用程序。尽管如此,重要的是要证明它在所有客观度量上都优于所有测试的经典或基于DNN的方法。
表3 比较客观的度量与基线在线SE系统。有关每个设置的详细信息,请参阅文本

6 总结
本文提出并评估了一种基于紧凑递归神经网络的实时语音增强方法,该网络采用一种简单的基于MSE的语音失真加权损失函数进行训练,并展示了各种特征归一化技术和序列长度对增强语音客观质量的影响。我们还演示了如何利用损失函数中的固定加权系数和信噪比加权系数来控制语音失真量,客观和主观测试都表明,我们的方法比其他好胜在线方法具有更好的性能。在未来,我们将探索时变的语音失真权重及其对主客观语音质量的影响。
7 参考文献
[1] P. C. Loizou, Speech enhancement: theory and practice, CRC press, 2013.
[2] J. Benesty, S. Makino, and J. Chen, Eds., Speech Enhancement, Springer, 2005.
[3] Y.Wang, A. Narayanan, and D.Wang, On training targets for supervised speech separation, IEEE/ACM Trans. on audio, speech, and language processing, vol. 22, no. 12, pp. 1849 1858, 2014.
[4] I. Cohen and B. Berdugo, Noise estimation by minima controlled recursive averaging for robust speech enhancement, IEEE signal processing letters, vol. 9, no. 1, pp. 12 15, 2002.
[5] I. Cohen and B. Berdugo, Speech enhancement for nonstationary noise environments, Signal processing, vol. 81, no. 11, pp. 2403 2418, 2001.
[6] Y. Ephraim and D. Malah, Speech enhancement using a minimum-mean square error short-time spectral amplitude estimator, IEEE Trans. on acoustics, speech, and signal processing, vol. 32, no. 6, pp. 1109 1121, 1984.
[7] S. Boll, Suppression of acoustic noise in speech using spectral subtraction, IEEE Trans. on acoustics, speech, and signal processing, vol. 27, no. 2, pp. 113 120, 1979.
[8] A. Ephrat, I. Mosseri, O. Lang, T. Dekel, K. Wilson, A. Hassidim, W. T. Freeman, and M. Rubinstein, Looking to listen at the cocktail party: a speaker-independent audio-visual model for speech separation, ACM Trans. on Graphics (TOG), vol. 37, no. 4, pp. 112, 2018.
[9] S. Pascual, A. Bonafonte, and J. Serr`a, SEGAN: Speech enhancement generative adversarial network, in ISCA INTERSPEECH 2017, 2017, pp. 3642 3646.
[10] J.-M. Valin, A hybrid DSP/deep learning approach to realtime full-band speech enhancement, in 2018 IEEE 20th International Workshop on Multimedia Signal Processing (MMSP), 2018, pp. 1 5.
[11] K. Tan and D. Wang, A convolutional recurrent neural network for real-time speech enhancement., in ISCA INTERSPEECH, 2018, pp. 3229 3233.
[12] Y. Xia and R. Stern, A priori SNR estimation based on a recurrent neural network for robust speech enhancement, in ISCA INTERSPEECH, 2018, pp. 3274 3278.
[13] S. Braun, K. Kowalczyk, and E. Habets, Residual noise control using a parametric multichannel wiener filter, in IEEE ICASSP, 2015, pp. 1 5.
[14] Y. Ephraim and D. Malah, Speech enhancement using a minimum mean-square error log-spectral amplitude estimator, IEEE Trans. on acoustics, speech, and signal processing, vol. 33, no. 2, pp. 443 445, 1985.
[15] T. Esch and P. Vary, Efficient musical noise suppression for speech enhancement system, in IEEE ICASSP, 2009, pp. 1 5.
[16] L. Sun, J. Du, L.-R. Dai, and C.-H. Lee, Multiple-target deep learning for LSTM-RNN based speech enhancement, in IEEE Hands-free Speech Communications and Microphone Arrays (HSCMA), 2017, pp. 136 140.
[17] Y. Xu, J. Du, Z. Huang, L.-R. Dai, and C.-H. Lee, Multiobjective learning and mask-based post-processing for deep neural network based speech enhancement, in ISCA INTERSPEECH 2015, pp. 1508 1512.
[18] F. G. Germain, Q. Chen, and V. Koltun, Speech Denoising with Deep Feature Losses, in Proc. Interspeech 2019, 2019, pp. 2723 2727.
[19] J. M. Mart ın-Do nas, A. M. Gomez, J. A. Gonzalez, and A. M. Peinado, A deep learning loss function based on the perceptual evaluation of the speech quality, IEEE Signal processing letters, vol. 25, no. 11, pp. 1680 1684, 2018.
[20] Y. Zhao, B. Xu, R. Giri, and T. Zhang, Perceptually guided speech enhancement using deep neural networks, in IEEE ICASSP, 2018, pp. 5074 5078.
[21] A. Kumar and D. Florencio, Speech enhancement in multiplenoise conditions using deep neural networks, in ISCA INTERSPEECH 2016, 2016, pp. 3738 3742.
[22] C. K. Reddy, E. Beyrami, J. Pool, R. Cutler, S. Srinivasan, and J. Gehrke, A Scalable Noisy Speech Dataset and Online Subjective Test Framework, in ISCA INTERSPEECH 2019, 2019, pp. 1816 1820.
[23] K. Cho, B. van Merrienboer, C. Gulcehre, D. Bahdanau, F. Bougares, H. Schwenk, and Y. Bengio, Learning phrase representations using RNN encoder decoder for statistical machine translation, in Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), 2014, pp. 1724 1734.
[24] S. Hochreiter and J. Schmidhuber, Long short-term memory, Neural computation, vol. 9, no. 8, pp. 1735 1780, 1997.
[25] H. Zhao, S. Zarar, I. Tashev, and C.-H. Lee, Convolutionalrecurrent neural networks for speech enhancement, in IEEE ICASSP, 2018, pp. 2401 2405.
[26] D. Liu, P. Smaragdis, and M. Kim, Experiments on deep learning for speech denoising, in ISCA INTERSPEECH, 2014.
[27] Z. Xu, S. Elshamy, Z. Zhao, and T. Fingscheidt, Components loss for neural networks in mask-based speech enhancement, arXiv preprint arXiv:1908.05087, 2019.
[28] A. W. Rix, J. G. Beerends, M. P. Hollier, and A. P. Hekstra, Perceptual evaluation of speech quality (PESQ)-a new method for speech quality assessment of telephone networks and codecs, in 2001 IEEE International Conference on Acoustics, Speech, and Signal Processing. Proceedings (Cat. No. 01CH37221), 2001, vol. 2, pp. 749 752.
[29] C. H. Taal, R. C. Hendriks, R. Heusdens, and J. Jensen, A short-time objective intelligibility measure for time-frequency weighted noisy speech, in IEEE International Conference on Acoustics, Speech and Signal Processing, 2010, pp. 4214 4217.
[30] J. Le Roux, S.Wisdom, H. Erdogan, and J. R. Hershey, SDR half-baked or well done?, in IEEE ICASSP, 2019, pp. 626 630.
[31] I. J. Tashev, Sound capture and processing: practical approaches, John Wiley & Sons, 2009.