Spark MLlib 机器学习算法库
✎ 学习目标
- 了解什么是机器学习及Spark MLlib的基本使用方式
- 掌握机器学习的工作流程
- 了解电影推荐系统的构建流程
- 理解MLlib的数据类型
概要
MLlib是Spark提供的处理机器学习方面的功能库,该库包含了许多机器学习算法,开发者可以不需要深入了解机器学习算法就能开发出相关程序。
初识机器学习
什么是实时计算
机器学习是一门多领域交叉学科,涉及概率论、统计学、逼近论、凸分析、算法复杂度理论等多门学科,专门研究计算机如何模拟或实现人类的学习行为,以获取新的知识或技能,重新组织已有的知识结构使之不断改善自身的性能。
机器学习是一种能够赋予机器进行自主学习,不依靠人工进行自主判断的技术,它和人类对历史经验归纳的过程有着相似之处。
什么是机器计算
- 人类思考
人类在学习成长的过程中,积累了很多历史经验,将经验进行归纳总结,得到规律,因此当我们遇到一些问题时,总能从事物的发展规律找到方向,进行推测。 - 机器学习
机器学习是对人类思考过程一个抽象,由于机器学习不是通过编程的形式得出结果,因此它的处理过程不是因果的逻辑,而是通过归纳思想得出的相关结论。
在机器学习领域中,按照学习方式分类,可以让研究人员在建模和算法选择的时候,考虑根据输入数据来选择合适的算法从而得到更好的效果,通常机器学习可以分为有监督学习和无监督学习两种。
- 有监督学习
通过已有的训练样本(即已知数据以及其对应的输出)训练得到一个最优模型,再利用这个模型将所有的输入映射为相应的输出,对输出进行简单的判断从而实现分类的目的。例如分类、回归和推荐算法都属于有监督学习。 - 无监督学习
根据类别未知(没有被标记)的训练样本,而需要直接对数据进行建模,我们无法知道要预测的答案。例如聚类、降维和文本处理的某些特征提取都属于无监督学习。
机器学习的应用
- 电子商务
机器学习在电商领域的应用主要涉及搜索、广告、推荐三个方面,在机器学习的参与下,搜索引擎能够更好的理解语义,对用户搜索的关键词进行匹配,同时它可以对点击率与转化率进行深度分析,从而利于用户选择更加符合自己需求的商品。 - 医疗
普通医疗体系并不能永远保持精准且快速的诊断,在目前研究阶段中,技术人员利用机器学习对上百万个病例数据库的医学影像进行图像识别分析数据,并训练模型,帮助医生做出更精准高效的诊断。 - 金融
机器学习正在对金融行业产生重大的影响,例如在金融领域最常见的应用是过程自动化,该技术可以替代体力劳动,从而提高生产力,例如摩根大通推出了利用自然语言处理技术的智能合同的解决方案,该解决方案可以从文件合同中提取重要数据,大大节省了人工体力劳动成本;机器学习还可以应用于风控领域,银行通过大数据技术,监控账户的交易参数,分析持卡人的用户行为,从而判断该持卡人信用级别。
Spark 机器学习库MLlib的概述
MLlib的简介
MLlib是Spark提供的可扩展的机器学习库,其中封装了一些通用机器学习算法和工具类,包括分类、回归、聚类、降维等,开发人员在开发过程中只需要关注数据,而不需要关注算法本身,只需要传递参数和调试参数。

Spark机器学习工作流程
Spark中的机器学习流程大致分为三个阶段,即数据准备阶段、训练模型评估阶段以及部署预测阶段。
- 数据准备阶段
在数据准备阶段,将数据收集系统采集的原始数据进行预处理,清洗后的数据便于提取特征字段与标签字段,从而生产机器学习所需的数据格式,然后将数据随机分为3个部分,即训练数据模块、验证数据模块和测试数据模块。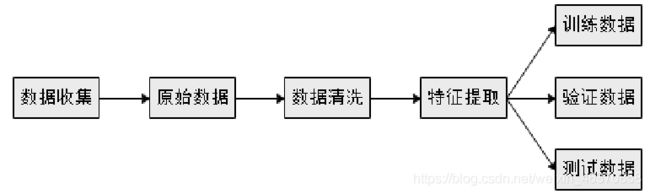
- 训练模型评估阶段
通过Spark MLlib库中的函数将训练数据转换为一种适合机器学习模型的表现形式,然后使用验证数据集对模型进行测试来判断准确率,这个过程需要重复许多次,才能得出最佳模型,最后使用测试数据集再次检验最佳模型,以避免过渡拟合的问题。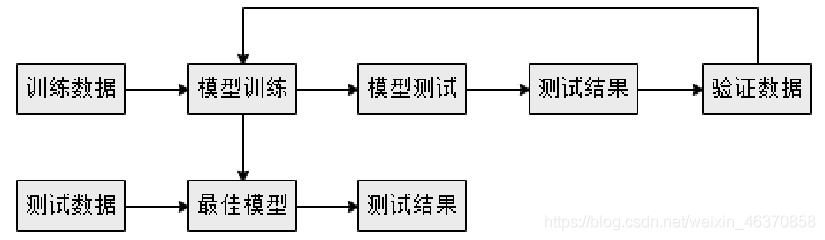
- 部署预测阶段
通过多次训练测试得到最佳模型后,就可以部署到生产系统中,在该阶段的生产系统数据,经过特征提取产生数据特征,使用最佳模型进行预测,最终得到预测结果。这个过程也是重复检验最佳模型的阶段,可以使生产系统环境下的预测更加准确。
数据类型
- 密集向量(Dense)
密集向量是由Double类型的数组支持,例如,向量(1.0,0.0,3.0)的密集向量表示的格式为[1.0,0.0,3.0]。
# 创建一个密集本地向量
val dv:Vector = Vectors.dense(1.0,0.0,3.0)
dv: org.apache.spark.mllib.linalg.Vector = [1.0,0.0,3.0]
- 稀疏向量(Sparse)
稀疏向量是由两个并列的数组支持,例如向量(1.0,0.0,3.0)的稀疏向量表示的格式为(3,[0,2],[1.0,3.0]),其中3是向量(1.0,0.0,3.0)的长度,[0,2]是向量中非0维度的索引值,即向量索引0和2的位置为非0元素,[1.0,3.0]是按索引排列的数组元素值。
# 创建一个稀疏本地向量
val sv1: Vector = Vectors.sparse(3, Array(0, 2), Array(1.0, 3.0))
sv1: org.apache.spark.mllib.linalg.Vector = (3,[0,2],[1.0,3.0])
标注点
标注点是一种带有标签的本地向量,标注点通常用于监督学习算法中,MLlib使用Double数据类型存储标签,因此可以在回归和分类中使用标记点。
标注点实现类org.apache.spark.mllib.regression.LabeledPoint 创建带有正标签和密集向量的标注点 val pos = LabeledPoint(1.0, Vectors.dense(1.0, 0.0, 3.0)) 创建带有负标签和稀疏向量的标注点 val neg = LabeledPoint(0.0, Vectors.sparse(3, Array(0, 2), Array(1.0, 3.0)))
本地矩阵
- 密集矩阵
密集矩阵将所有元素的值存储在一个列优先的双精度数组中。
创建一个3行2列的密集矩阵
scala>val dm: Matrix =Matrices.dense(3, 2, Array(1.0, 3.0, 5.0, 2.0, 4.0, 6.0))
- 稀疏矩阵
稀疏矩阵则将以列优先的非零元素压缩到稀疏列(CSC)格式中。
创建一个3行2列的密集矩阵
scala> val sm: Matrix = Matrices.sparse(3, 2, Array(0, 1, 3), Array(0, 2, 1),
Array(9, 6, 8))
Spark MLlib基本统计
摘要统计
MLlib提供了很多统计方法,包含摘要统计、相关统计、分层抽样、假设检验、随机数生成等统计方法,利用这些统计方法可帮助用户更好地对结果数据进行处理和分析。统计量的计算用到Statistics类,摘要统计主要方法如下所示。
相关统计
相关系数是反应两个变量之间相关关系密切程度的统计指标,这也是统计学中常用的统计方式,MLlib提供了计算多个序列之间相关统计的方法,目前MLlib默认采用皮尔森相关系数计算方法。皮尔森相关系数也称皮尔森积矩相关系数,它是一种线性相关系数。
分层抽样
分层抽样法也叫类型抽样法,将总体按某种特征分为若干层级,再从每一层内进行独立取样,组成一个样本的统计学计算方法。
例如某手机厂家估算当地潜在用户,可以将当地居民消费水平作为分层基础,减少样本中的误差,如果不采取分层抽样,仅在消费水平较高的用户中做调查,是不能准确的估算出潜在的用户。
分类
分类算法
分类是指将事物分成不同类别,在分类模型中,可根据一组特征来判断类别,这些特征代表了物体、事物或上下文的相关属性。分类算法又被称为分类器,它是数据挖掘和机器学习领域中的一个重要分支。
MLlib支持多种分类分析方法,例如二元分类、多元分类,表中列出了不同种类的问题可采用不同的分类算法。

线性支持向量机
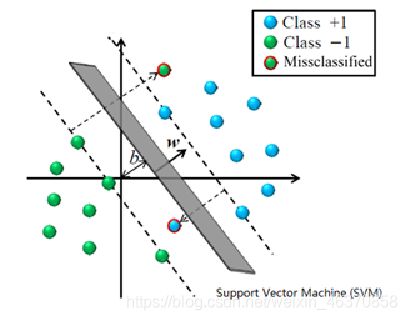
- 线性支持向量机
线性支持向量机是一种常见判别方法,在机器学习领域中是一个有监督学习模型,用来进行模式识别、分类以及回归分析。使用MLlib提供的线性支持向量机算法训练模型,需要导入线性支持向量机所需包。
- 逻辑回归
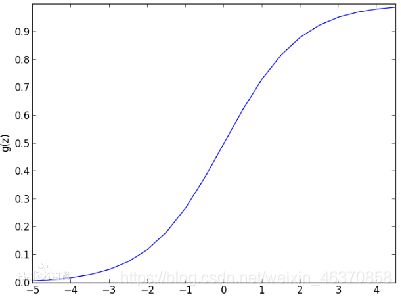
逻辑回归又称为逻辑回归分析,是一个概率模型的分类算法,用于数据挖掘、疾病自动诊断及经济预测等领域。例如在流行病学研究中,探索引发某一疾病的危险因素,根据模型预测在不同自变量情况下,推测发生某一疾病。
案例——构建推荐系统
推荐模型分类
推荐系统的研究已相当广泛,也是最为大众所知的一种机器学习模型,目前最为流行的推荐系统所应用的算法是协同过滤,协同过滤用于推荐系统,这项技术是为填补关联矩阵的缺失项而实现推荐效果。简单的说,协同过滤是利用大量已有的用户偏好,来估计用户对其未接触过的物品的喜好程度。
在协同过滤算法中有着两个分支:基于群体用户的协同过滤(UserCF)和基于物品的协同过滤(ItemCF)。
- 基于物品的推荐(ItemCF)
基于物品的推荐是利用现有用户对物品的偏好或是评级情况,计算物品之间的某种相似度,以用户接触过的物品来表示这个用户,再寻找出和这些物品相似的物品,并将这些物品推荐给用户。 - 基于用户的推荐(UserCF)
基于用户的推荐,可用“志趣相投”一词所表示,通常是对用户历史行为数据分析,如购买、收藏商品或搜索内容,通过某种算法将用户喜好物品进行打分。根据不同用户对相同物品或内容数据的态度和偏好程度计算用户间关系程度,在相同喜好用户间进行商品推荐。
利用MLlib实现电影推荐
在电影推荐系统中,通常分为针对用户推荐电影和针对电影推荐用户两种方式。若采用基于用户的推荐模型,则会利用相似用户的评级来计算对某个用户的推荐。若采用基于物品的推荐模型,则会依靠用户接触过的物品与候选物品之间的相似度来获得推荐。
在Spark MLlib实现了交替最小二乘(ALS)算法,它是机器学习的协同过滤式推荐算法,机器学习的协同过滤式推荐算法是通过观察所有用户给产品的评分来推断每个用户的喜好,并向用户推荐合适的产品。
- 准备训练模型数据

用户评分文件,即u.data文件
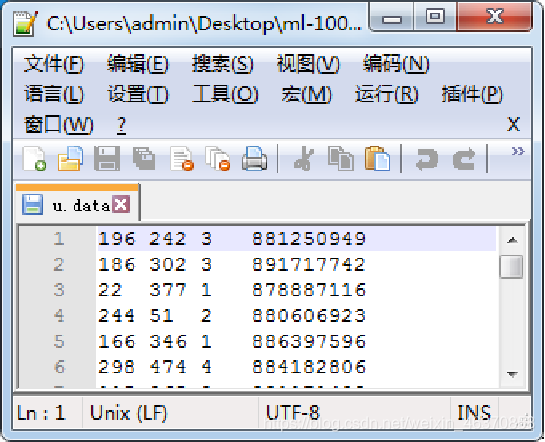
电影数据文件,即u.item文件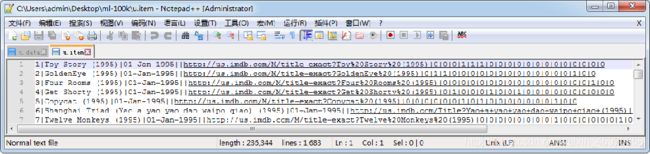
- 编写程序,训练模型
(1) 采用Spark-Shell读取u.data数据文件,将其转换为RDD
$ spark-shell --master local[2]
scala> val dataRdd = sc.textFile("/spark/mldata/ml-100k/u.data")
scala> dataRdd.first()
res0: String = 196 242 3 881250949
(2) 使用take()方法提取前三个字段
scala> val dataRdds = dataRdd.map(_.split("\t").take(3))
scala> dataRdds.first()
res1: Array[String] = Array(196, 242, 3)
(3) 导入MLlib实现的ALS算法模型库
scala> import org.apache.spark.mllib.recommendation.ALS
(4) 将dataRdds转换成Rating格式的数据
scala> import org.apache.spark.mllib.recommendation.Rating
scala> val ratings = dataRdds.map {
case Array(user,movie,rating) =>
Rating(user.toInt,movie.toInt,rating.toDouble)}
scala> ratings.first()
res6: org.apache.spark.mllib.recommendation.Rating = Rating(196,242,3.0)
(5) 使用train()函数训练模型
scala> val model = ALS.train(ratings,50,10,0.01)
model: org.apache.spark.mllib.recommendation.MatrixFactorizationModel =
org.apache.spark.mllib.recommendation.MatrixFactorizationModel@6580f76c
- 为用户推荐多个电影
# 定义用户id
scala> val userid = 100
# 定义推荐数量
scala> val num = 10
scala> val topRecoPro = model.recommendProducts(userid,num)
topRecoPro: Array[org.apache.spark.mllib.recommendation.Rating] = Array(
Rating(100,207,5.704436943409341),Rating(100,845,4.957373351732721),
Rating(100,489,4.955561012970148),Rating(100,242,4.930681946988706),
Rating(100,315,4.927258436518516),Rating(100,316,4.905582861372857),
Rating(100,313,4.8170984786843265),Rating(100,12,4.795107793201218),
Rating(100,451,4.760165688538673),Rating(100,485,4.7560380607401))
为了更直观的检测推荐效果,将u.item文件中的电影id与电影名称进行映射。
(1)先读取u.item文件并转换为RDD
scala> val moviesRdd =sc.textFile("/spark/mldata/ml-100k/u.item")
(2)使用map()函数针对每一项数据进行转换
val titles = moviesRdd.map(line => line.split("\\|").take(2)).map(array=>
(array(0).toInt,array(1))).collectAsMap()
(3)通过Rating对象的rating属性来对推荐的电影名称进行匹配
scala> topRecoPro.map(rating => (titles(rating.product),rating.rating))
.foreach(println)
(Cyrano de Bergerac (1990),5.704436943409341)
(That Thing You Do! (1996),4.957373351732721)
(Notorious (1946),4.955561012970148)
(Kolya (1996),4.930681946988706)
(Apt Pupil (1998),4.927258436518516)
(As Good As It Gets (1997),4.905582861372857)
(Titanic (1997),4.8170984786843265)
(Usual Suspects, The (1995),4.795107793201218)
(Grease (1978),4.760165688538673)
(My Fair Lady (1964),4.7560380607401)
- 将物品推荐给用户
scala> model.recommendUsers(100,5)
res1: Array[org.apache.spark.mllib.recommendation.Rating] = Array(
Rating(495,100,6.541442448267074),
Rating(30,100,6.538178750321883),
Rating(272,100,6.398878858473),
Rating(8,100,6.372883993450857),
Rating(68,100,6.37055453407313))