大数据之hadoop环境搭建
Hadoop的环境搭建
1. 安装虚拟机
将事先准备好的虚拟机导入
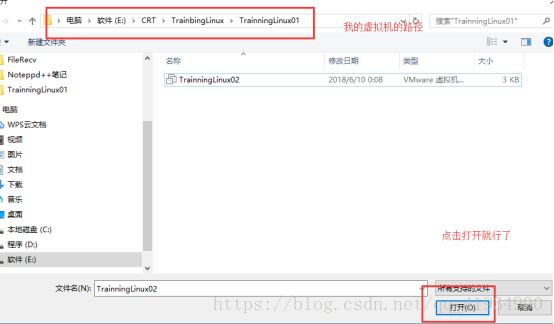
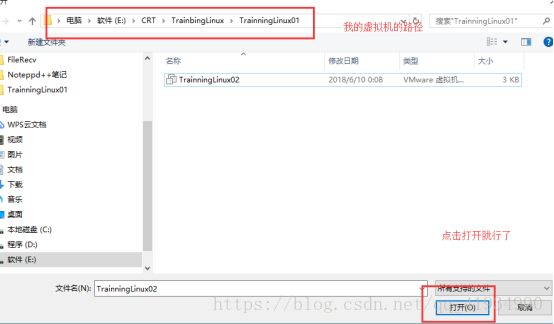
这时虚拟机就启动了。
为了职业化:我们就创建一个普通用户
Useradd username(名字可以随意取)
设置密码:passwd 密码不会显示
用户和密码创建好以后
下面进行虚拟机的配置了
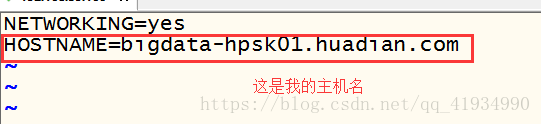
修改主机名:通过vi /etc/sysconfig/network你会进入以下页面
然后设置你的主机名
配置ip和主机名映射
主机名映射: vi /etc/hosts

添加好以后,可以检测一下
ping 主机名
如果ping通了说明添加成功
同时:本机上也要改一下
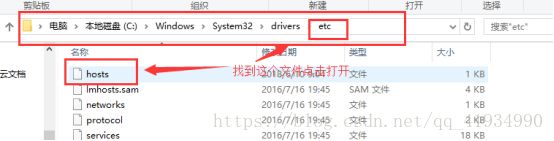



然后保存退出
关闭防火墙
当前关闭 sudo service iptables stop
开机不启动 sudo chkconfig iptables off
检查设置是否成功 chkconfig iptables --list

关闭selinux
vi /etc/selinux/config
Vi /etc/syscnfig/selinux
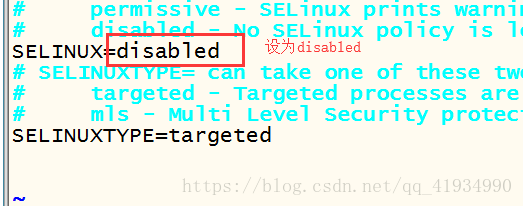
设置好selinux=disabled后,必须重启才能生效
关闭虚拟机
init 0 / halt
到这记住虚拟机快照
然后开机开始工作
由于没有还没有正式工作,就用伪分布式安装部署,安装前的准备
规划Linux系统的目录结构
以系统/opt目录为主安装软件包
/opt
/datas测试数据
/softwares软件包,上传的软件包
/modules软件安装目录
/tools开发的IDE及工具
将上述目录所属者和所属组改成普通用户
chown 普通用户:普通用户 /datas /softwares /modules /tools

安装jdk
安装之前先下载系统自带的openjdk
查看: sudo rpm -qa |grep java
下载: sudo rpm -e --nodeps
java-1.6.0-openjdk-1.6.0.0-1.50.1.11.5.el6_3.x86_64 \
tzdata-java-2012j-1.el6.noarch \
java-1.7.0-openjdk-1.7.0.9-2.3.4.1.el6_3.x86_64
上传文件和下载文件
Sudo yum install -y lrzsz
rz :上传文件,上传当前执行rz命令的路径
sz :下载文件
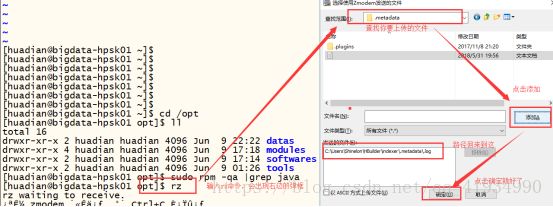
需要注意的是:你在/opt上传的文件,文件就会在/opt目录下
安装jdk
使用rz将jdk上传到/opt/softwares目录下
稍等一下,查看一下就会出现jdk的压缩包

解压成功后,下面需要配置环境变量


Jdk环境变量配置好后,使其生效
Source /etc/profile
验证一下
java -version

做到这记得要快照一下
下面上传Hadoop压缩包
解压Hadoop压缩包
tar -zxvf hadoop-2.7.3.tar.gz -C /opt/modules/
查看目录结构
进入以下文件夹(bin/sbin)删除后缀为 .cmd的文件
文件路径/opt/modules/hadoop-2.7.3/etc/hadoop
rm -rf bin/*.cmd
rm -rf sbin/*.cmd
进入share删除为doc文件
下面进行3个模块的环境变量修改后缀为(*.env)
hadoop-env.sh

yarn-env.sh
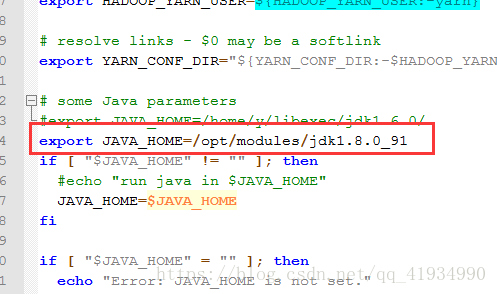
Mapred-env.sh
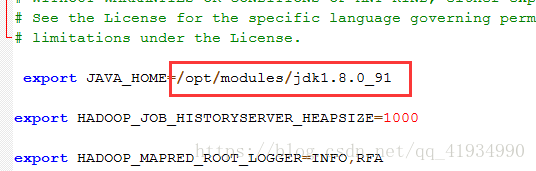
以上三个环境变量设置好后
配置xml文件
common:
core-site.xml
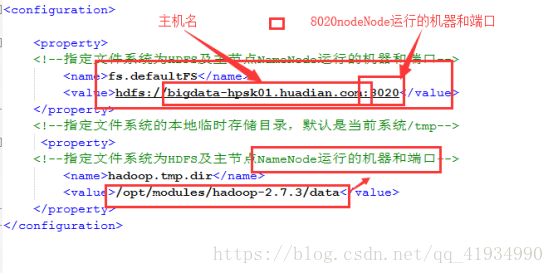
HDFS
Hdfs-site.xml

配置slaves文件
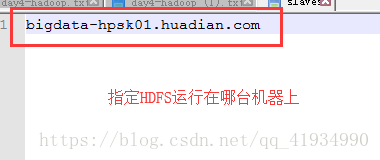
上面文件配置好了
然后启动HDFS
第一次使用文件系统,需要格式化
格式化系统
cd /opt/modules/hadoop-2.7.3
bin/hdfs namenode -format
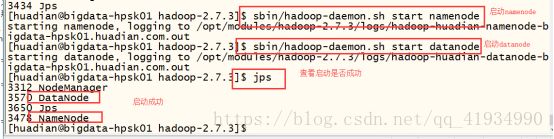
启动
主节点
sbin/hadoop-daemon.sh start namenode
从节点
sbin/hadoop-daemon.sh start datanode
关闭
主节点
sbin/hadoop-daemon.sh stop namenode
从节点
sbin/hadoop-daemon.sh stop datanode
验证是否启动成功
方式一:
jps
ps -ef |grep java

方式二:
通过webUI界面查看
Bigdata-hpsk01.huadian.com:50070
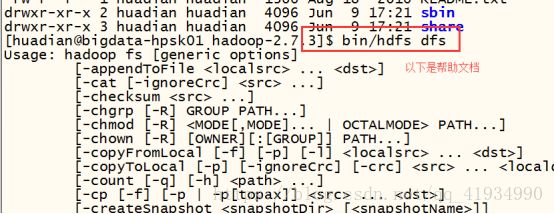
测试HDFS
帮助文件
bin/hdfs dfs
HDFS文件系统目录和linux目录系统结构相似,命令也类似
创建目录:
bin/hdfs dfs mkdir /datas
查看目录:
bin/hdfs dfs -ls /datas
上传文件:
bin/hdfs dfs -text /datas/input.data
bin/hdfs dfs -cat /datas/input.data
下载文件:
bin/hdfs dfs -get /datas/input.data ./
删除文件:
bin/hdfs dfs -rm -r /datas/input.data
配置YARN
对于分布式资源管理和任务调度来说
哪些程序可以运行在yarn上
MapReduce
并行数据处理框架
spark
基于内存分布式处理框架
storm/flink
实时流式处理框架
TeZ
分析数据,比MapReduce速度快
主节点
resourceManager
从节点
nodeManager
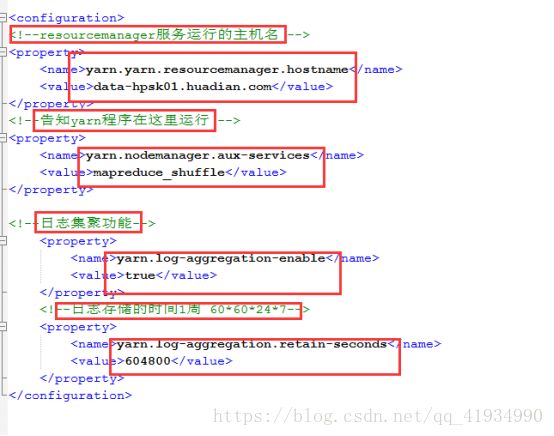
需要修改的配置
yarn-site.xml
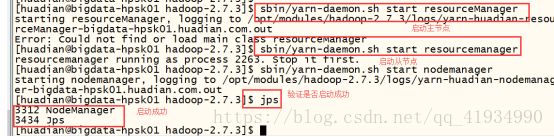
启动:
主节点:resourceManager
sbin/yarn-daemon.sh start resoucemanager
从节点:nodemanager
Sbin/yarn-daemon.sh start nodemanager
验证:
方式一:jps === ps -ef |grep java
方式二:bigdata-hpsk01.huadian.com:8088
MapReduce:
并行计算框架(2.x)
思想:分而治之
核心
Map
并行处理数据,将数据分割,一部分一部分的处理
Reduce
将Map的处理结果进行合并
配置
cd {hadoop_home}/etc/hadoop
修改文件(复制mapred-site.xml并重命名为mapred-site.xml)
cd mapred-site.xml.xml template mapres-site.xml
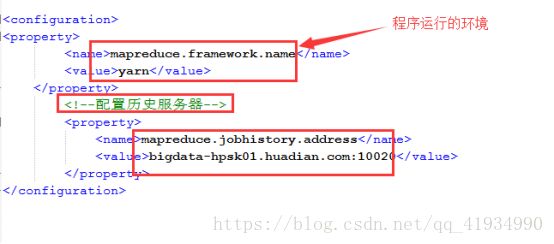
配置历史服务器
查看监听已经运行完成的MapReduce任务的执行情况
配置mapred-site.xml
启动
sbin/mr-jpbhistory-daemon.sh start historyserver
注意:在启动historyServer服务之前运行的job相关信息已经没了,只有后面运行的才有
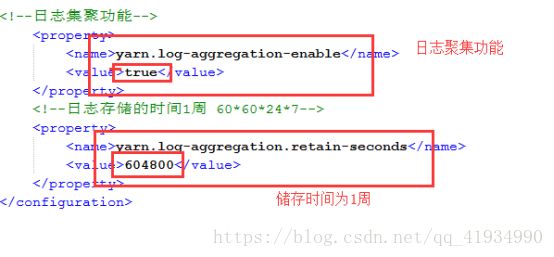
日志聚集功能
当MapReduce程序在YARN上运行完成之后,将产生的日志文件上传到HDFS目录中,以便以后继续查看
配置:
yarn-site.xml
重启YARN和jobHistoryServer
这时候你需要快照或克隆一下,做备份
日志信息
{Hadoop_home}/logs
组件名称-用户名-服务名称-主机名
hadoop-huadian-datanode-bigdata-hpsk01.huadian.com.log
根据后缀名:
.log
程序启动相关信息会在里面,
进程启动失败
.out
程序运行相关的输出
system.out.print
system.out.error
查看日志
tail -100f name

