1.崩溃的一天
12月20号,算得上西安崩溃的一天。
12月19号新增病例21个,20号新增病例42个,并且有部分病例已经在社区内传播...
西安防疫压力巨大,各单位公司要求,需48小时核酸检测报告上班。
在这样严峻的情况下,作为防控最核心的系统:西安一码通竟然崩溃了,并且崩溃得是那么的彻底。
足足瘫痪超过 15+ 个小时!
整整一天的时间呀,多少上班族被堵在地铁口,多少旅客被冻在半路上,进退不能...
到了下午,新闻甚至提示:
为了减轻系统压力,建议广大市民非必要不展码、亮码,在出现系统卡顿时,请耐心等待,尽量避免反复刷新,也感谢广大市民朋友们的理解配合。
这是解决问题的方法吗?
如果真的需要限流来防止系统崩溃,用技术手段来限流是不是会更简单一些,甚至前面加一个 nginx 就能解决的问题。
今天,我们就试着分析一下这个业务、以及对应的技术问题。
2.产品分析
西安一码通其它业务我们暂且不分析,那并不是重点,并且当天也没有完全崩溃,崩溃的仅有扫码功能。
其实这是一个非常典型的大量查询、少数更新的业务,闭着眼睛分析一下,可以说, 90% 以上的流量都是查询。
我们先来看看第一版的产品形态,扫码之后展示个人部分姓名和身份证信息,同时下面展示绿、黄、红码。

这是西安一码通最开始的样子,业务流程仅仅只需要一个请求,甚至一个查询的 SQL 就可以搞定。
到了后来,这个界面做了2次比较大的改版。
第一次改版新增了疫苗接种信息,加了一个边框;第二次改版新增了核酸检测信息,在最下方展示核酸检测时间、结果。

整个页面增加了2个查询业务,如果系统背后使用的是关系数据库,可能会多增加至少2个查询SQL。
基本上就是这样的一个需求,据统计西安有1300万人口,按照最大10%的市民同时扫码(我怀疑不会有这么多),也就是百万的并发量。
这样一个并发量的业务,在互联网公司很常见,甚至比这个复杂的场景也多了去了。
那怎么就崩了呢?
3.技术分析
在当天晚上的官方回复中,我们看到有这样一句话:
12月20日早7:40分左右,西安“一码通”用户访问量激增,每秒访问量达到以往峰值的10倍以上,造成网络拥塞,致使包括“一码通”在内的部分应用系统无法正常使用。“
一码通”后台监控第一时间报警,各24小时驻场通信、网络、政务云、安全和运维团队立即开展排查,平台应用系统和数据库运行正常,判断问题出现在网络接口侧。
根据上面的信息,数据库和平台系统都正常,是网络出现了问题。
我之前在文章《一次dns缓存引发的惨案》画过一张访问示意图,用这个图来和大家分析一下,网络出现问题的情况。
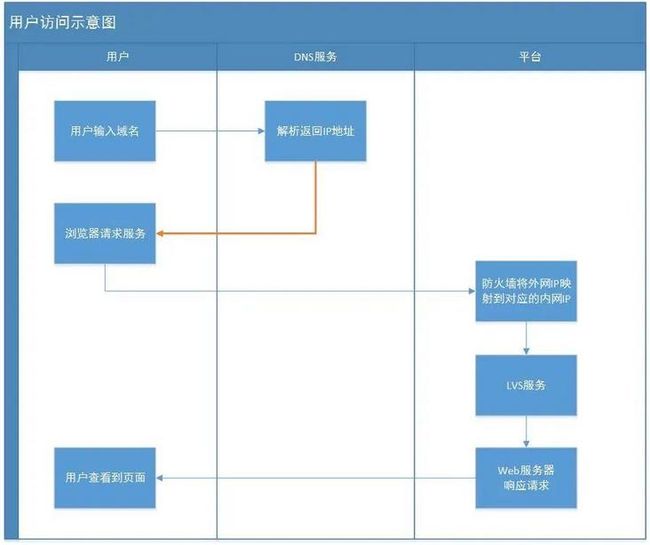
一般用户的请求,会先从域名开始,经过DNS服务器解析后拿到外网IP地址,经过外网IP访问防火墙和负载之后打到服务器,最后服务器响应后将结果返回到浏览器。
如果真的是网络出现问题,一般最常见的问题就是 DNS 解析错误,或者外网的宽带被打满了。
DNS解析错误一定不是本次的问题,不然可能不只是这一个功能出错了;外网的宽带被打满,直接增加带宽就行,不至于一天都没搞定。
如果真的是网络侧出现问题,一般也不需要改动业务,但实际上系统恢复的时候,大家都发现界面回到文章开头提到了第一个版本了。

也就是说系统“回滚”了。
界面少了接种信息和核酸检测信息的内容,并且在一码通的首页位置,新增加了一个核酸查询的页面。

所以,仅仅是网络接口侧出现问题吗?我这里有一点点的疑问。
4.个人分析
根据我以往的经验,这是一个很典型的系统过载现象,也就是说短期内请求量超过服务器响应。
说人话就是,外部请求量超过了系统的最大处理能力。
当然了,系统最大处理能力和系统架构息息相关,同样的服务器不同的架构,系统负载量差异极大。
应对这样的问题,解决起来无非有两个方案,一个是限流,另外一个就是扩容了。
限流就是把用户挡在外面,先处理能处理的请求;扩容就是加服务器、增加数据库承载能力。
上面提到官方让大家没事别刷一码通,也算是人工限流的一种方式;不过在技术体系上基本上不会这样做。
技术上的限流方案有很多,但最简单的就是前面挂一个 Nginx 配置一下就能用;复杂一点就是接入层自己写算法。
当然了限流不能真正的解决问题,只是负责把一部分请求挡在外面;真正解决问题还是需要扩容,满足所有用户。
但实际上,根据解决问题的处理和产品回滚的情况来看,一码通并没有第一时间做扩容,而是选择了回滚。
这说明,在系统架构设计上,没有充分考虑扩容的情况,所以并不能支持第一时间选择这个方案。
5.理想的方案?
上面说那么多也仅仅是个人推测,实际上可能他们会面临更多现实问题,比如工期紧张、老板控制预算等等...
话说回来,如果你是负责一码通公司的架构师,你会怎么设计整个技术方案呢?欢迎大家留言,这里说说我的想法。
第一步,读写分离、缓存。
至少把系统分为2大块,满足日常使用的读业务单独抽取出来,用于承接外部的最大流量。
单独抽出一个子系统负责业务的更新,比如接种信息的更新、核酸信息的变化、或者根据业务定时变更码的颜色。
同时针对用户大量的单查询,上缓存系统,优先读取缓存系统的信息,防止压垮后面的数据库。
第二步,分库分表、服务拆分。
其实用户和用户之间的单个查询是没有关系的,完全可以根据用户的属性做分库分表。
比如就用用户ID取模分64个表,甚至可以分成64个子系统来查询,在接口最前端将流量分发掉,减轻单个表或者服务压力。
上面分析没有及时扩容,可能就是没有做服务拆分,如果都是单个的业务子服务的话,遇到过载的问题很容易做扩容。
当然,如果条件合适的话,上微服务架构就更好了,有一套解决方案来处理类似的问题。
第三步,大数据系统、容灾。
如果在一个页面中展示很多信息,还有一个技术方案,就是通过异步的数据清洗,整合到 nosql 的一张大表中。
用户扫描查询等相关业务,直接走 nosql 数据库即可。
这样处理的好处是,哪怕更新业务完全挂了,也不会影响用户扫码查询,因为两套系统、数据库都是完全分开的。
使用异地双机房等形式部署服务,同时做好整体的容灾、备灾方案,避免出现极端情况,比如机房光缆挖断等。
还有很多细节上的优化,这里就不一一说明了,这里也只是我的一些想法,欢迎大家留言补充。
6.最后
不管怎么分析,这肯定是人祸而不是天灾。
系统在没有经过严格测试之下,就直接投入到生产,在强度稍微大一点的环境中就崩溃了。
比西安大的城市很多,比西安现在疫情还要严重的情况,其它城市也遇到过,怎么没有出现类似的问题?
西安做为一个科技大省,出现这样的问题真的不应该,特别是我看了这个小程序背后使用的域名地址之后。
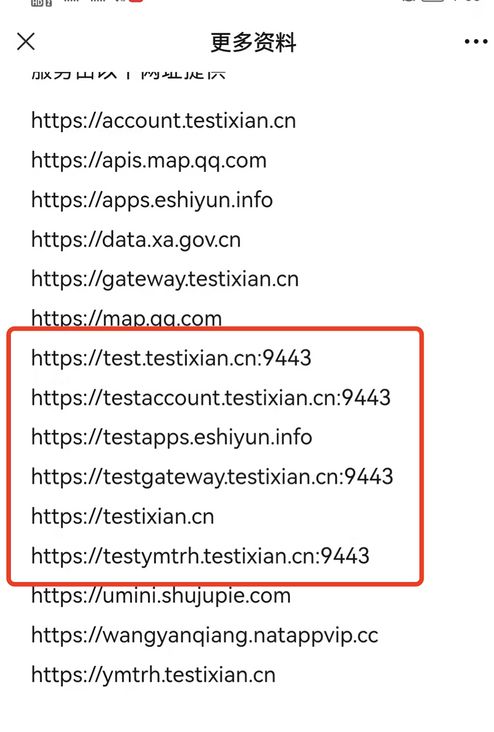
有一种无力吐槽的感觉,虽然说这和程序使用没有关系,但是从细节真的可以看出一个技术团队的实力。
希望这次能够吸取教训,避免再次出现类似的问题!