卷积神经网络:(二)风格迁移——原理部分
引言
本文是在第一步配置完环境后基础上运行的。使用的为系统直装的python环境(在anaconda环境下一样适用,后面注意的点会提示的。)。若想查看环境配置步骤,请点击https://blog.csdn.net/weixin_41108515/article/details/103636284,因原理部分篇幅较多,所以将所有代码,知识部分移到第三篇博客上,若是对于该原理了解熟悉,或只想操作不需深入的,可以直接跳过。所有操作都在第三篇上。
转载请注明出处:https://blog.csdn.net/weixin_41108515/article/details/103650964
这里引用的是:
http://zh.gluon.ai/chapter_computer-vision/neural-style.html
https://blog.csdn.net/aaronjny/article/details/79681080
这两篇都非常详细,并且经调试可以使用。
涉及到的相关原理:
1、神经网络部分原理:
1.1 神经网络基础介绍
神经网络基本可以分成两种:一种为生物神经网络,一种为人工神经网络。
神经网络的研究内容相当广泛,反映了多学科交叉技术领域的特点。主要的研究工作集中在以下几个方面:
(1)生物原型研究。从生理学、心理学、解剖学、脑科学、病理学等生物科学方面研究神经细胞、神经网络、神经系统的生物原型结构及其功能机理。
(2)建立理论模型。根据生物原型的研究,建立神经元、神经网络的理论模型。其中包括概念模型、知识模型、物理化学模型、数学模型等。
(3)网络模型与算法研究。在理论模型研究的基础上构作具体的神经网络模型,以实现计算机模拟或准备制作硬件,包括网络学习算法的研究。这方面的工作也称为技术模型研究。
(4)人工神经网络应用系统。在网络模型与算法研究的基础上,利用人工神经网络组成实际的应用系统,例如,完成某种信号处理或模式识别的功能、构造专家系统、制成机器人等等。
1.2 卷积神经网络基本结构
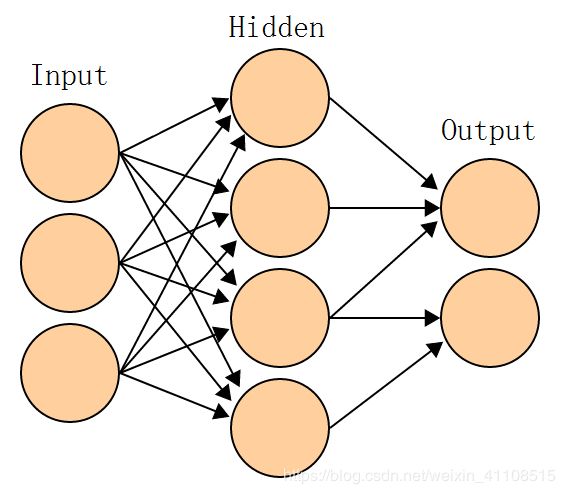
卷积神经网络(Convolutional Neural Network,CNN)是一种前馈神经网络,它的人工神经元可以对周围单元的一部分进行响应,并能很好的处理大型的图片。卷积神经网络是近几年来发展起来的一种高效的识别方法,并引起了广泛的关注[16]。正是由于高效的识别准确率,对卷积神经网络的研究才层出不穷。20世纪60年代,胡贝尔和魏塞尔发现,独特的网络结构可以有效地减少反馈神经网络在大脑皮层神经元研究中的局部敏感性和方向性选择的复杂性,从而提出了卷积神经网络(Convolutional Neural Networks简称CNN)的概念。目前,卷积神经网络已成为许多科学领域的热点话题。由于内部算法避免了对图像进行复杂的预处理,所以它可以直接输入原始图片。
1.2.1 输入层
卷积神经网络的输入层可以处理多维数据,常见地,一维卷积神经网络的输入层接收一维或二维数组,其中一维数组通常为时间或频谱采样;二维数组可能包含多个通道;二维卷积神经网络的输入层接收二维或三维数组;三维卷积神经网络的输入层接收四维数组。
1.2.2 隐含层
1.卷积层
(1)卷积层
利用乘法卷积代替矩阵乘法。在图像处理的过程中,一张“小猫”的图片可以被看作是一个“薄饼”,它包括图片的高度、宽度和深度(即颜色的三原色,以RGB表示)。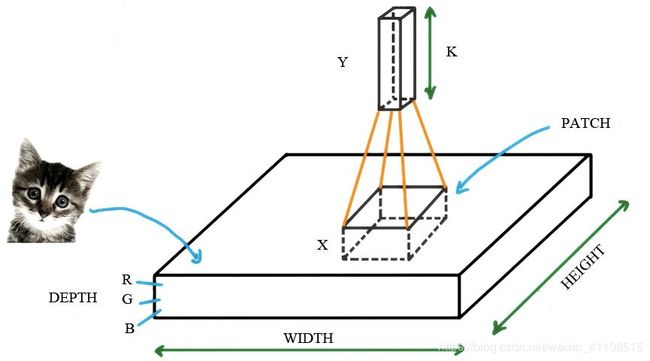
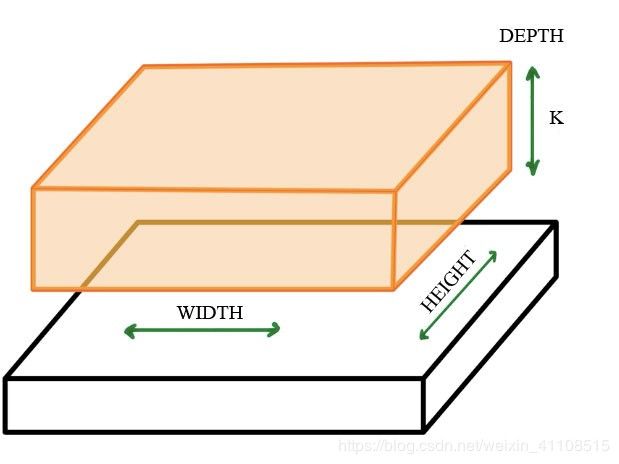
如上图所示,若权重不变,把这个上方具有k个输出的小神经网络对应的小块滑遍整个图像,可以得到一个宽度、高度、深度都不同的新图像。得到的新图像如下图所示。
(2)卷积层参数
卷积层参数包括卷积核大小、步长和填充,三者共同决定了卷积层输出特征图的尺寸,是卷积神经网络的超参数。其中卷积核大小可以指定为小于输入图像尺寸的任意值,卷积核越大,可提取的输入特征越复杂。
卷积步长定义了卷积核相邻两次扫过特征图时位置的距离,卷积步长为1时,卷积核会逐个扫过特征图的元素,步长为n时会在下一次扫描跳过n-1个像素。
由卷积核的交叉相关计算可知,随着卷积层的堆叠,特征图的尺寸会逐步减小,例如16×16的输入图像在经过单位步长、无填充的5×5的卷积核后,会输出12×12的特征图。为此,填充是在特征图通过卷积核之前人为增大其尺寸以抵消计算中尺寸收缩影响的方法。常见的填充方法为按0填充和重复边界值填充。填充依据其层数和目的可分为四类:
有效填充(valid padding):即完全不使用填充,卷积核只允许访问特征图中包含完整感受野的位置。输出的所有像素都是输入中相同数量像素的函数。使用有效填充的卷积被称为“窄卷积”,窄卷积输出的特征图尺寸为(L-f)/s+1。
相同填充/半填充:只进行足够的填充来保持输出和输入的特征图尺寸相同。相同填充下特征图的尺寸不会缩减但输入像素中靠近边界的部分相比于中间部分对于特征图的影响更小,即存在边界像素的欠表达。使用相同填充的卷积被称为“等长卷积。
全填充:进行足够多的填充使得每个像素在每个方向上被访问的次数相同。步长为1时,全填充输出的特征图尺寸为L+f-1,大于输入值。使用全填充的卷积被称为“宽卷积”。
任意填充:介于有效填充和全填充之间,人为设定的填充,较少使用。
(3)激励函数
一个合适的激励函数可以有效地提高卷积神经网络的运行性能。激活函数应当具有的性质:
1)可微性:当优化方法是基于梯度的时候,这个性质是必不可少的。
2)单调性:当激活函数为单调函数时,能够确保单层网络为凸函数。
3)输出值的范围:当激活函数的输出值受到限制时,基于梯度的优化方法将更加稳定,因为特征的表示更受有限权重的影响。当激活函数的输出是无限时,模型的训练将更加油效率,但在这种情形下,通常需要较小的学习速率。
经常使用的非线性激活函数有sigmid、tanh、Relu等等,前两者sigmid与tanh在全连接层 比较常见,后者ReLU常见于卷积层。
2.池化层
池化层是卷积神经网络的一个重要组成部分,它通过减少卷积层之间的连接数量来降低计算的困难度。包括以下几种池化:
(1)一般池化(General Pooling)
1)mean-pooling,即只要求邻域中特征点的平均值;
2)max-pooling,即在邻域中提取最大特征点;
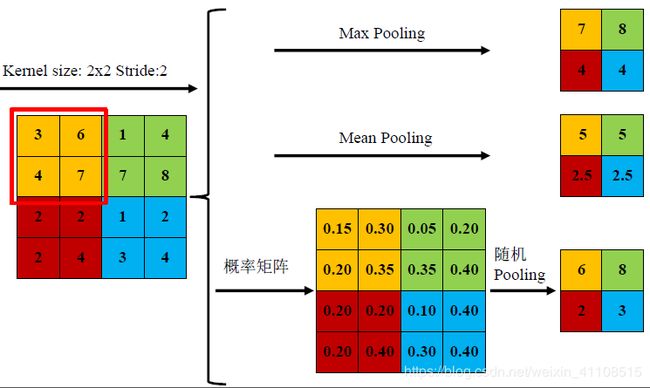
3)Stochastic-pooling,介于两者之间,根据数值给出像素的概率,并根据概率进行二次采样。
特征提取的误差主要来自两个方面:
1)邻域大小受限造成的估计值方差增大;
2)卷积层参数误差导致估计均值的偏移。
一般来说,mean-pooling能减小第一种误差并保留图像的背景信息,max-pooling能减小第二类的错误,并保留更多的纹理信息。在平均意义上,与mean-
pooling近似,在局部意义上,则服从max-pooling的准则。如图下图所示,
(2)空间金字塔池化(Spatial pyramid pooling)
一般的卷积神将网络都需要输入图像的大小是固定的,这是因为全连接层的输入需要一个固定的维度。几乎所有作者提出了空间金字塔池化,先让图像进行卷积,然后变换为要输入到全连接层的维度,这样可以把卷积神经网络扩展到任意大小的图像。
空间金字塔池化可以把任何尺度的卷积特征转化成同一维,这不仅可以让卷积神经网络处理任意大小的图像,还能避免裁剪和扭曲操作,这具有重要意义。
3.全连接层
卷积神经网络中的全连接层等价于传统前馈神经网络中的隐含层。全连接层通常搭建在卷积神经网络隐含层的最后部分,并只向其它全连接层传递信号。特征图在全连接层中会失去三维结构,被展开为向量并通过激励函数传递至下一层。
1.2.3 输出层
卷积神经网络中输出层的上游通常是全连接层,因此其结构和工作原理与传统前馈神经网络中的输出层相同。对于图像分类问题,输出层使用逻辑函数或归一化指数函数输出分类标签。在物体识别问题中,输出层可设计为输出物体的中心标、大小和分类。在图像语义分割中,输出层直接输出每个像素的分类结果。
1.3 卷积神经网络的卷积过程
卷积神经网络的结构有很多种,但是其基本结构是类似的。如下图,它包含三个主要的层——卷积层(convolutional layer)、池化层(pooling layer)、全连接层(fully-connected layer)。
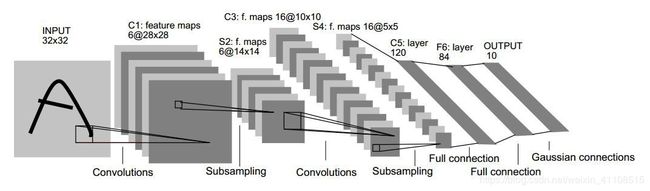
图中的卷积网络工作流程如下, 输入图片是像素是32×32的来组成输入层。然后,计算流程在卷积和抽样之间交替进行,如下所述:
第一隐藏层进行卷积的工作,它由6个特征图组成,每个特征图由28×28个神经元组成,每个神经元指定5×5 的接受域。
第二隐藏层实现子采样和局部平均,它同样由 6个特征图组成,但其每个特征图由14×14 个神经元组成。每个神经元具有2×2 的接受域。
第三隐藏层进行第二次卷积,它由 16个特征图组成,每个特征图由 10×10个神经元组成。隐藏层中的每个神经元可以具有与下一隐藏层的多个特征图相关联的突触连接,其操作方式类似于第一层隐藏层的卷积过程。
第四个隐藏层进行第二次子采样和局部平均计算。它由 16个特征图组成,但每个特征图由 5×5个神经元构成,它以与第一次采样相同的方式进行工作。
第五个隐藏层实现了卷积的最后阶段,它由 120个神经元组成,每个神经元指定5×5 的接受域。
端部是个全连接层,得到输出向量。
卷积和采样之间的计算层的连续交替是“双尖塔”的结果,即在每个卷积或采样层中,与先前的层相比,特征图的数目随着空间分辨率的减小而增加[17]。
卷积层研究输入数据的特征。卷积层由卷积核(convolutional kernel)组成,卷积核用来计算不同的特征图;激励函数(activation function)给卷积神经网络引入了非线性,常用的有sigmid、tanh、 ReLU函数;池化层减少了卷积层输出的特征向量,改良结果(使结构不易过拟合),典型应用有average pooling 和 max pooling;全连接层将卷积层和池化层组合起来以后,然后可以形成层或多层全连接层,从而可以完成更高水平的特征取得。
2、迁移学习相关原理
2.1 迁移学习
在深度学习中,所谓的迁移学习是将一个问题A上训练好的模型通过简单的调整使其适应一个新的问题B。在实际使用中,往往是完成问题A的训练出的模型有更完善的数据,而问题B的数据量偏小。而调整的过程根据现实情况决定,可以选择保留前几层卷积层的权重,以保留低级特征的提取;也可以保留全部的模型,只根据新的任务改变其fc层。被迁移的模型往往是使用大量样本训练出来的,比如Google提供的Inception V3网络模型使用ImageNet数据集训练,而ImageNet中有120万标注图片,然后在实际应用中,很难收集到如此多的样本数据。而且收集的过程需要消耗大量的人力无力,所以一般情况下来说,问题B的数据量是较少的。所以,同样一个模型在使用大样本很好的解决了问题A,那么有理由相信该模型中训练处的权重参数能够很好的完成特征提取任务。迁移学习具有如下优势:更短的训练时间,更快的收敛速度,更精准的权重参数。但是一般情况下如果任务B的数据量是足够的,那么迁移来的模型效果会不如训练的到,但是此时起码可以将底层的权重参数作为初始值来重新训练。
2.2TensorFlow
TensorFlow是谷歌基于DistBelief进行研发的第二代人工智能学习系统。Tensor(张量)意味着N维数组,Flow(流)意味着基于数据流图的计算,TensorFlow为张量从流图的一端流动到另一端计算过程。TensorFlow是将复杂的数据传递到人工智能神经网络进行处理和分析的系统。
TensorFlow 表达了高层次的机器学习计算,大幅简化了第一代系统,并且具备更好的灵活性和可延展性。TensorFlow一大亮点是支持异构设备分布式计算,它能够在各个平台上自动运行模型,从手机、单个CPU / GPU到成百上千GPU卡组成的分布式系。TensorFlow支持CNN、RNN和LSTM算法,这都是目前在Image,Speech和NLP最流行的深度神经网络模型。
TensorFlow可被用于像机器学习和深度学习的许多领域,如语音识别或者是图像处理,以及对深度学习的基础设施的各个方面进行改进。它能够运行在小到一个只能电话或数以百万计的CEN上。TensorFlow将是完全开源的,可以被任何人使用。这也是选择TensorFlow这个平台的主要原因。
(1)支持多种硬件的平台
例如,它支持CPU、GPU混合数据中心的训练平台,并且还支持数据中心的训练模型,它相对方便地部署到不同的移动端应用程序,并且可以支持由谷歌自主开发的TPU处理器。这种多硬件支持平台会大大给用户带来方便。
(2)支持多种开发环境
支持各种硬件的平台是基础,也是TensorFlow始终能够帮助尽可能多的开发人员利用深度学习技术并最终受益于广大用户的原因。基于这一思想,TensorFlow一直都非常重视各种程序员开发环境。例如,开发人员可以在各式各样的、位于主要的位置的开发环境中使用TensorFlow环境。
目前TensorFlow仍处于快速开发迭代中,有大量新功能及性能优化在次持续研发。
2.3VGG卷积神经网络模型
VGG全称是Visual Geometry Group属于牛津大学科学工程系,其发布了一些列以VGG开头的卷积网络模型,可以应用在人脸识别、图像分类等方面,分别从VGG16~VGG19[20]。VGG研究卷积网络深度的初衷是想搞清楚卷积网络深度是如何影响大规模图像分类与识别的精度和准确率的,最初是VGG-16号称非常深的卷积网络全称为(GG-Very-Deep-16 CNN),VGG在加深网络层数同时为了避免参数过多,在所有层都采用3x3的小卷积核,卷积层步长被设置为1。VGG的输入被设置为224x244大小的RGB图像,在训练集图像上对所有图像计算RGB均值,然后把图像作为输入传入VGG卷积网络,使用3x3或者1x1的filter,卷积步长被固定1。VGG全连接层有3层,根据卷积层+全连接层总数目的不同可以从VGG11 ~ VGG19,最少的VGG11有8个卷积层与3个全连接层,最多的VGG19有16个卷积层+3个全连接层,此外VGG网络并不是在每个卷积层后面跟上一个池化层,还是总数5个池化层,分布在不同的卷积层之下,下图是VGG11 ~GVV19的结构图:
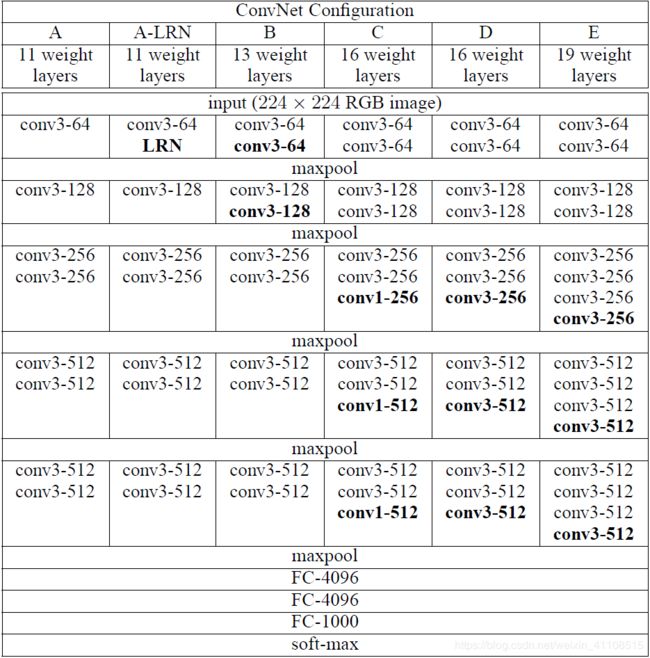
在图中,A列是最基本的模型,有8个卷积层,3个全连接层,一共11层。B列是在A列的基础上,在stage1和stage2基础上分别增加了一层33卷积层,一共13层。C列是在B的基础上,在stage3,stage4和stage5基础上分别增加了一层11的卷积层。一共16层。D列是在B的基础上,在stage3,stage4和stage5基础上分别增加了一层33的卷积层,一共16层。E层是在D的基础上,在stage3,stage4和stage5基础上分别增加33的卷积层,一共19层。模型E就是VGG19网络。
3、通过VGG实现风格迁移
3.1 图像风格迁移的原理
VGGNET是一种图像识别模型,它也拥有者卷积层和全连接层。可以这样理解VGG的结构:前面的卷积层是从图像中提取“特征”,而后面的全连接层把图片的“特征”转换为类别概率。其中VGGNET中的浅层(conv1_1,conv1_2 ),提取的特征往往是比较简单的(比如提取检测点、线、亮度),VGGNET中的深层(c比如onv5_1,conv5_2),提取的特征往往比较复杂(如是否存在人脸、某种特定物体)。
VGGNET的本意是输入图像,提取特征,然后输出图像类别。图像风格迁移恰好与其相反,输入特征,之后输出对应这种特征的图片。两种过程的对比图片如下图所示:
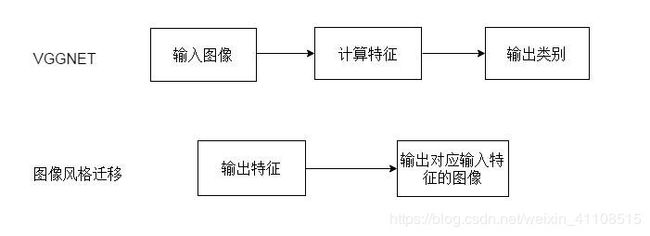
具体来说,风格迁移使用卷积层的中间特征还原出对应这种特征的原始图像。具体过程就是:先选取一副原始图像,经过VGGNET计算后得到各个卷积层的特征。之后,根据这些卷积层的特征,还原出对应这种特征的原始图像.研究发现:浅层的还原效果往往比较好,卷积特征基本保留了所有原始图像中形状、位置、颜色、纹理等信息;深层对应的还原图像丢失了部分颜色和纹理信息,但大体保留原始图像中物体的形状和位置。
3.2 代价函数
要构建一个神经风格迁移系统,首先需要为生成的图像定义一个代价函数,通过最小化代价函数,可以大大缩短图片生成所需要的时间。为了实现神经风格迁移,需要定义一个关于G的代价函数,J用来评判某个生成图像的好坏,我们将使用梯度下降法去最小化J(G),以便于生成这个图像。那么如何去判断生成图像的好坏,在这里把这个代价函数定义为两个部分。
Jcontent(C,G)
第一部分被称作内容代价,这是一个关于内容图片和生成图片的函数,它是用来度量生成图片G的内容与内容图片C的内容有多相似。
Jstyle(S,G)
然后会把结果加上一个风格代价函数,也就是关于S和G的函数,用来度量图片G的风格和图片S的风格的相似度。
J(G)=αJcontent(C,G)+βJstyle(S,G)
最后用两个超参数α和β来来确定内容代价和风格代价,两者之间的权重用两个超参数来确定。
3.3 内容代价函数
风格迁移网络的代价函数有一个内容代价部分,还有一个风格代价部分。
首先定义内容代价部分。
用隐含层m来计算内容代价,如果m是个很小的数,比如用隐含层 1,这个代价函数就会使生成图片像素上非常接近内容图片。然而如果使用很深的层,那么可能在内容图片里面有一个具体的物体,在生成的图片里就会存在这个物体。比如是一只小猫,那么在生成的图片里就一定会有一个小猫。所以在实际中,这个层m在网络中既不会选的太浅也不会选的太深。通常会选择在网络的中间层,既不太浅也不很深,然后用一个预训练的卷积模型,本篇论文使用的是 VGG 网络。
之后需要衡量假如有一个内容图片和一个生成图片他们在内容上的相似度,令这个代表这两个图片α([L][C])和α([L][G])的l层的激活函数值。如果这两个激活值相似,那么就意味着两个图片的内容相似。
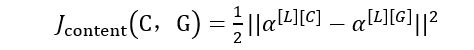
为两个激活值不同或者相似的程度,取l层的隐含单元的激活值,按元素相减,内容图片的激活值与生成图片相比较,然后取平方,也可以在前面加上归一化或者不加,比如1/2或者其他的,都影响不大,因为这都可以由这个超参数α来调整。
3.4 风格代价函数
图像的风格可以用使用图像的卷积层特征的Gram矩阵来进行表示。在线性代数中这种矩阵被称为Gram矩阵,在这里可以称之为风格矩阵。
风格矩阵是一组向量的内积对称矩阵,比如向量组
的Gram矩阵是
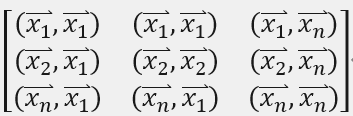
取内积即欧几里得空间上的标准内积,即
假设卷积层的输出为F_ij^l,那么这个卷积特征对应的Gram矩阵的第i行第j个元素定义为
设在第l层中,卷积特征的通道数为N_l,卷积的高、宽乘积数为M_l,那么F_ij^l满足
l≤i≤N_l,l≤j≤M_l
Gram矩阵在一定程度上可以体现图片的风格。多层的风格损失是单层风格损失的加权累加。
3.5 模型训练过程
首先,使用VGG中的一些层的输出来表示图片的内容特征和风格特征。
使用[‘conv4_2’,’conv5_2’]表示内容特征,使用[‘conv1_1’,’conv2_1’,’conv3_1’,’conv4_1’]表示风格特征。
将内容图片输入网络,计算内容图片在网络指定层上的输出值。
计算内容损失。可以这样定义内容损失:内容图片在指定层上提取出的特征矩阵,与噪声图片在对应层上的特征矩阵的差值的L2范数。即求两两之间的像素差值的平方。
对应每一层的内容损失函数:
其中,X是噪声图片的特征矩阵,P是内容图片的特征矩阵。M是P的长*宽,N是信道数。最终的内容损失为,每一层的内容损失加权和,再对层数取平均。
将风格图片输入网络,计算风格图片在网络指定层上的输出值。
计算风格损失。使用风格图像在指定层上的特征矩阵的GRAM矩阵来衡量其风格,风格损失可以定义为风格图像和噪音图像特征矩阵的格莱姆矩阵的差值的L2范数。
对于每一层的风格损失函数:
其中M是特征矩阵的长*宽,N是特征矩阵的信道数。G为噪音图像特征的Gram矩阵,A为风格图片特征的GRAM矩阵。
最终的风格损失为,每一层的风格损失加权和,再对层数取平均。
函数为内容损失和风格损失的加权和:
当训练开始时,根据内容图片和噪声,生成一张噪声图片。并将噪声图片传送给网络,计算loss,再根据loss调整噪声图片。将调整后的图片发给网络,重新计算loss,再调整,再计算,直到达到指定迭代次数,这时,噪声图片已兼具内容图片的内容和风格图片的风格,进行保存即可,其训练过程如图下所示,训练顺序依次从左向右。
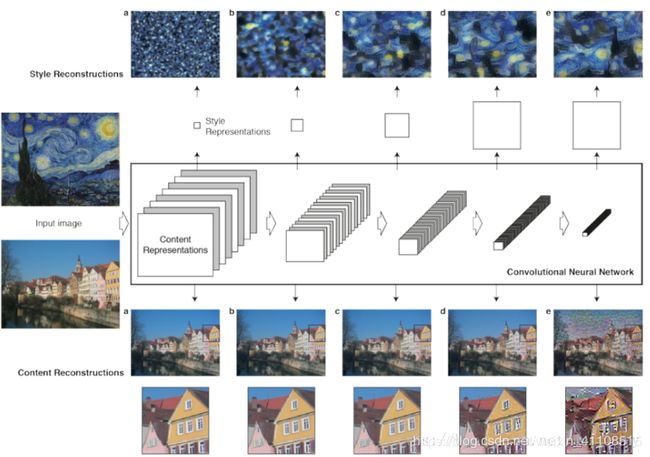
原理总结:感谢能翻到这的同学们,这一篇只是为了让大家了解到一些相关知识,毕竟操作简单,主要的是算法思想。下一篇就是与代码相关的部分了,可以开始打开建的工程,写代码了!
卷积神经网络:(三)风格迁移——代码部分