引言
上一篇文章中介绍了一些无缓冲文件I/O函数,但应该什么时机调用这些函数,调用这些I/O函数时进程和内核的行为如何,如何高效率地实现I/O?这篇文章就来谈一谈Linux下的5种I/O模型,以及高性能服务器编程中常用的I/O复用,为后面实现精简版本的高性能服务器做铺垫。
Linux下的5种I/O模型
Linux下可用的5种I/O模型:
- 阻塞I/O
- 非阻塞I/O
- I/O复用
- 信号驱动式I/O
- 异步I/O
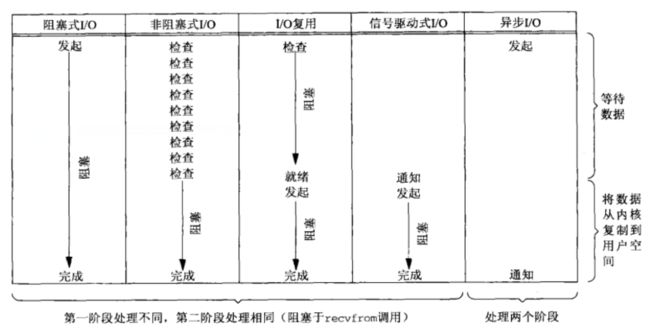
一个输入操作通常包括两个不同阶段:
- 等待数据准备好
- 从内核向进程复制数据
对于套接字的输入操作来说,第一步是等待数据从网络中到达,当分组到达时,它被暂存到内核的某个缓冲区。第二步就是把数据从内核缓冲区复制到应用进程缓冲区。
阻塞式I/O
默认情况下,所有套接字都是阻塞的。
阻塞I/O的典型情形如下:
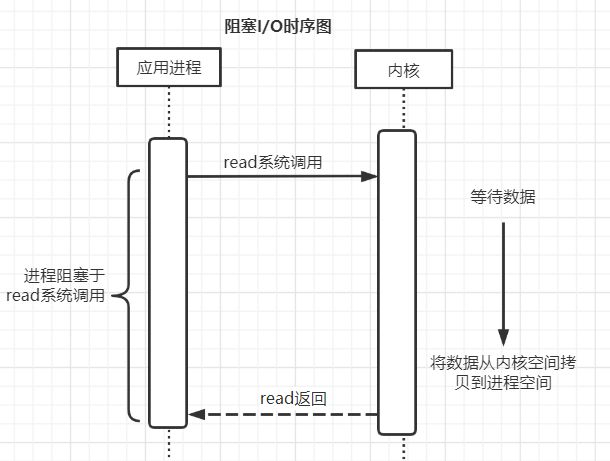
进程对TCP套接字调用read,系统调用直到数据报到达并被复制到应用进程的缓冲区或发生错误才返回。其中等待数据的时间是不可控的,取决于网络何时有数据到来。而对于期间可能发生的错误,最常见的就是被信号中断。
这样的I/O就是阻塞式I/O。
非阻塞I/O
当进程把某个文件描述符设置为非阻塞时,典型的情形如下所示:

对设置为非阻塞的文件描述符调用recvfrom,若没有数据准备好,recvfrom立即返回错误(错误号为EWOULDBLOCK)(调用真的出错时也会立即返回,需要根据errno来区分,常见的因非阻塞事件未发生时的errno为EAGAIN、EWOULDBLOCK、EINPROGRESS)。
若数据准备好,则需要等待内核把数据从内核缓冲区拷贝到进程空间缓冲区。
I/O复用
典型的I/O复用模型如下:
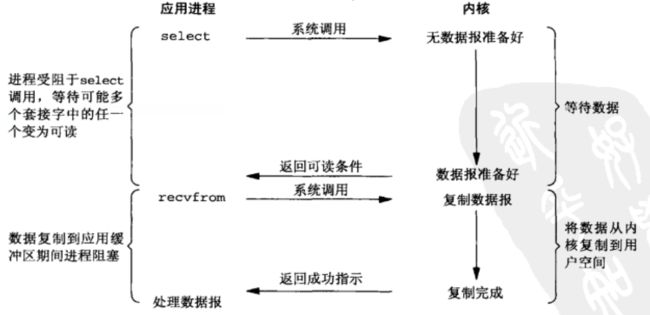
有了I/O复用,我们可以阻塞在I/O复用函数上(select、poll、epoll),等待多个文件就绪,而不用阻塞于对单个文件描述符读写的系统调用。使用select的优势在于可以等待多个描述符就绪。
信号驱动I/O
典型的信号驱动I/O模型如下:
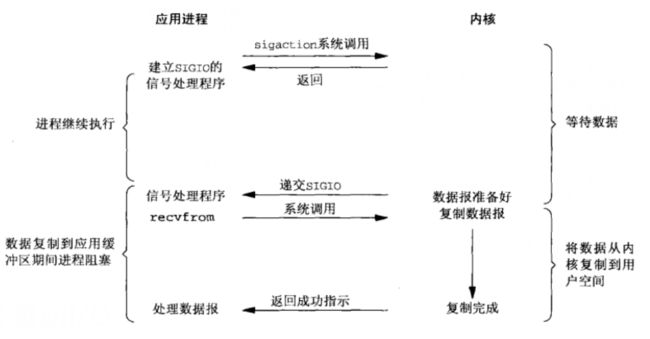
首先开启套接字的信号驱动I/O功能,并安装信号处理函数,进程接下来继续做其他工作,没有被阻塞
当数据报准备好时,内核就为进程产生SIGIO信号,调用前面安装的信号处理函数,在处理函数中调用recvfrom。
优势在于等待数据报到达期间进程无需阻塞。
异步I/O
异步I/O模型如下:
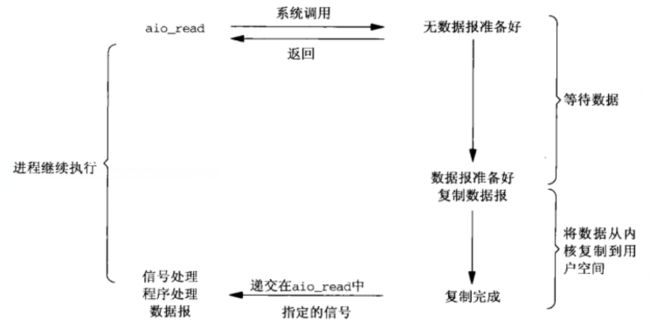
在异步I/O中,调用aio_read将描述符、进程缓冲区指针、进程缓冲区大小、文件偏移告知内核,并告诉内核当操作完成时如何通知我们。该系统调用立即返回,在等待I/O期间进程不被阻塞。
5种I/O模型比较
仔细分析就会发现,虽然有些I/O模型可以不必等待数据就绪(不必阻塞于数据在内核缓冲区准备好的这段时间),但除了异步I/O外,其余4种I/O都无法避免进程阻塞于数据从内核复制到进程空间的这部分时间。
因此,前4种I/O都属于同步式I/O,只有异步I/O模型与POSIX定义的异步I/O匹配。异步I/O将数据从内核复制到用户空间这一任务完全托付给内核处理,不必由进程实时监管,进程只需要给出一些必要信息即可(学过操作系统的同学很快就会发现这有点类似于通过通道处理机在设备和内存之间传送数据)。
下图是这5种I/O模型的时序比较,帮助大家更好理解他们之间的差别:
I/O复用
Linux提供了三个系统调用以支持I/O复用:
- select
- poll
- epoll_wait
我们可以用这些系统调用同时等待多个描述符上的事件就绪。I/O复用函数本身是阻塞的,他们能提高效率的原因就在于具有同时监听多个I/O事件的能力。
select调用
select函数的定义如下:
#include
#include
int select(int maxfdp1, fd_set* read_set, fd_set* write_set, fd_set* except_set, const struct timeval*
timeout);
返回值:
有就绪描述符时返回就绪的描述符的数目,超时则返回0,出错返回-1.
参数说明
timeout参数指定select函数最多等待多长时间,如果这段事件内没有就绪描述符,就返回0。timeval结构体定义如下:
struct timeval{
long tv_sec;
long tv_usec;
};
timeout的3种情形:
- timeout参数可以为
NULL,代表select将永远阻塞直到有描述符就绪。 - timeout参数不为
NULL,且timeval各字段不为0。 - timeout参数不为
NULL,但timeval各字段为0。
select在阻塞期间会被进程在等待期间捕获的信号中断,并从信号处理函数返回,那么select就会返回EINTR的错误。
read_set、write_set、except_set分别指定等待可读、可写、异常(异常条件目前只需关注套接字存在带外数据时的情况)发生的文件描述符集。
fd_set的设定要通过宏来操作:
void FD_ZERO(fd_set* fdset); // 清空,fd_set变量使用前必须要清空
void FD_SET(int fd, fd_set* fdset); // 设置某描述符
void FD_CLR(int fd, fd_set* fdset); // 取消设置某描述符
int FD_ISSET(int fd, fd_set* fdset); // 检查是否设置
maxfdp1参数为等待的所有描述符的最大值加1。
select返回时,会修改fd_set,将未就绪的置为0,就绪的保持。因此中间三个参数为传入传出参数。而且,我们必须通过FD_ISSET宏遍历fd_set,来检查哪些描述符就绪,每次重新调用select时,我们还必须重新设置要等待的描述符集合fd_set。
当某个套接字发生错误时,由select标记为既可读又可写。此处的错误不是excep_set等待的异常条件。
局限
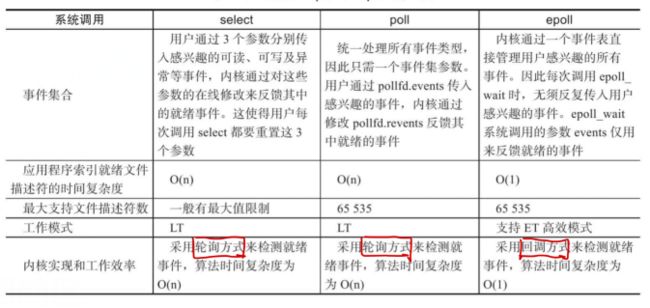
通过上面的介绍可以发现,select返回时我们需要轮询以获取就绪的描述符,效率不高,而且每次调用select必须重新设置fd_set。
此外,select能监听的最大描述符数目是有限制的。
poll调用
poll函数的定义如下:
#include
int poll(strcut pollfd* fd_array, unsigned long nfds, int timeout);
返回值:
若有就绪返回就绪描述符数目;
超时返回0;
出错返回-1。
参数说明
struct pollfd定义如下:
struct pollfd{
int fd;
short events;
short revents;
};
要测试的条件由events指定,返回时revents存储就绪事件。
timeout参数指定等待的毫秒数。可以为INFTIM、0、正数。
局限
虽然poll没有了监听描述符数目的限制,但poll返回时我们还是要轮询遍历pollfd,来检查就绪的描述符,同样效率不高。
epoll调用
不同于select、poll,epoll把用户关心的文件描述符上的事件放在内核的一个事件表中,因此无需每次调用都重复传入文件描述符集或事件集。epoll需要使用一个额外的文件描述符,来标识内核中的这个事件表。
创建事件表的函数epoll_create函数定义如下:
#include
int epoll_create(int size);
返回:
成功返回表示事件表的描述符。
size参数只是给内核一个提示,告诉内核事件表需要多大。
操作事件表的函数如下:
#include
int epoll_ctl(int epfd, int op, struct epoll_event* event);
返回值:
成功返回0;
失败返回-1。
epfd为epoll_create的返回值。
op指定操作类型,可以为:
- EPOLL_CTL_ADD:注册fd上的事件。
- EPOLL_CTL_MOD:修改fd上的注册事件。
- EPOLL_CTL_DEL:删除fd上的注册事件。
event指定事件和描述符,struct epoll_event定义如下:
struct epoll_event{
__uint32_t events; //事件
epoll_data_t data; //用户数据
};
typedef union epoll_data{
void* ptr;
int fd; //指定描述符
uint32_t u32;
uint64_t u64;
}epoll_data_t;
发起等待的epoll_wait函数定义如下:
#include
int epoll_wait(int epfd, struct epoll_event* events, int maxevents, int timeout);
返回值:
成功返回就绪的描述符的个数;
失败返回-1。
events为传出参数,结合maxevents说明了预先开辟的数组空间用于存放就绪的epoll_event。timeout参数与poll接口的timeout相同。
epoll_wait函数如果检测到事件,就将所有就绪的事件从内核事件表中复制到events指向的数组中,这个参数只为传出参数,不像select、poll参数既传入又传出需要轮询,提高了效率。
3种调用的区别
对于3种调用的详细区别以及他们的具体使用例子不可能在本篇文章的篇幅中展开,以后的文章具体分析,这里贴出《Linux高性能服务器编程》一书上的图例:
参考资料
《UNP 卷1》 3/e
《Linux高性能服务器编程》
《后台开发 核心技术与应用实践》