人脸颜值评分软件_通过爬虫爬取2000名明星照片进行颜值评测,并进行数据分析,你心中的男/女神有多少评分?(一)...
前言
五一假期无聊,当然是学爬虫了。这次我们将爬取2000多个明星的照片,然后通过百度云的人脸识别api对他/她们进行颜值评测,不知道你心目中的男/女神能得多少分呢?
本文仅供娱乐,请勿对结果较真。
准备和分析
首先我们要获取明星的图片,这里我爬取的网站是http://www.yue365.com/mingxing/zimu/a.shtml,下面我们对网页中的元素进行分析:

我们打开上述网址可以发现,域名中a的变化指的就是明星名字开头的字母的变化,因此我们只要爬取26个页面(a-z)就可以获取全部的明星信息。然后我们再对单个页面进行分析:

观察页面可知明星的分布,前10个以图片形式显示,然后56个以文字显示,而剩余的需要点击‘加载更多’来显示。F12打开检查界面:

我们点击a标签中的url链接可以打开明星的个人界面:

该页面中的图片就是我们想要的,所以我们的思路是先获取明星的名字和个人界面的网址,再通过个人界面网址爬取明星的图片(页面中前十个明星的图片可以直接获取,但为尽量统一,我们也通过该方法获取)。
人脸识别api使用
在进行核心代码前,我们先把人脸识别api的调用搞定,很多云都提供人脸识别api服务,这里我采用的是百度智能云提供的(调用方式简单,调用次数不限),百度智能云中的人脸识别api网址:https://cloud.baidu.com/product/face 开通服务很容易,这里不做赘述,接下来打开人脸检测的技术文档:https://cloud.baidu.com/doc/FACE/Face-Detect.html#.E8.B0.83.E7.94.A8.E6.96.B9.E5.BC.8F,查看调用方式:
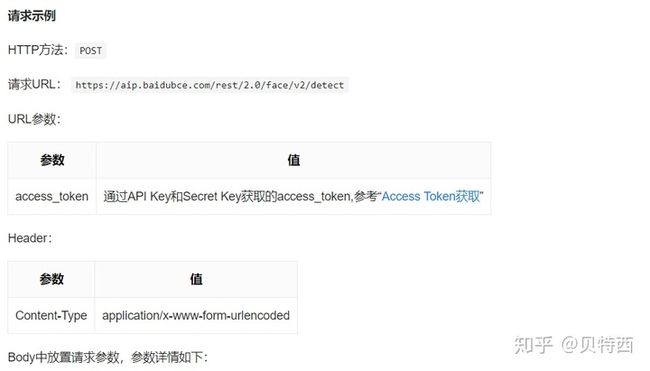
请求参数和返回参数(我们只需要颜值):


主要代码如下:
token = 'xxxxxxxx'
requests_url = "https://aip.baidubce.com/rest/2.0/face/v3/detect"
requests_url = requests_url + '?access_token=' + token
headers = {
'Content-Type': 'application/json'
}
params = {
'image': get_img(img),
'image_type': 'BASE64',
'face_field': 'age,beauty,gender',
'max_face_num': 3,
}
res = requests.post(requests_url, data=params, headers=headers)
result = res.text
json_result = json.loads(result)
beauty = json_result['result']['face_list'][0]['beauty']这里get_img方法是用来读取图片的,我们后面会补充
数据库准备
我们要爬取的数据是不少的,我把这些存到Mysql数据库中,我们在Mysql.py中完成数据库的连接,查询,插入等操作,这里一并给出代码:
import pymysql.cursors
connection = pymysql.connect(host='localhost',
user='xxxx',
password='xxxxx',
db='star',
port = 3306,
charset='utf8mb4',
cursorclass=pymysql.cursors.DictCursor)
# 导入明星名字,网址
def insert_stars(star_name, star_url):
with connection.cursor() as cursor:
sql = "INSERT INTO `star` (`STAR_NAME`, `STAR_URL`) VALUES (%s, %s)"
cursor.execute(sql, (star_name, star_url))
connection.commit()
# 获取所有明星的名字,网址
def get_star_info():
with connection.cursor() as cursor:
sql = "SELECT star_name,star_img FROM star"
cursor.execute(sql)
return cursor.fetchall()
# 导入明星的图片地址
def insert_img(star_img,star_url):
with connection.cursor() as cursor:
sql = "UPDATE `star` SET star_img = %s WHERE star_url = %s"
cursor.execute(sql, (star_img, star_url))
connection.commit()
#导入明星颜值评分
def insert_star_beauty(star_name,star_beauty):
with connection.cursor() as cursor:
sql = "UPDATE `star` SET star_beauty = %s WHERE star_name = %s"
cursor.execute(sql, (star_beauty, star_name))
connection.commit()基本操作,大家可以在以上代码中进行一些优化。
爬取信息
第一步,我们爬取明星的图片和对应名字,打开前面提到的界面


获取这些节点信息可以使用xpath和Beautiful Soup,出于学习的角度,我们分别用两种方法进行爬取,主要代码如下:
#获取前十个
url = 'http://www.yue365.com/mingxing/zimu/a.shtml'
headers = {
'Host':'www.yue365.com',
'Referer':'http://www.yue365.com/mingxing/zimu/z.shtml',
'User-Agent':'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.131 Mobile Safari/537.36'
}
r = requests.get(url, headers=headers)
r.encoding = 'utf-8'
response = r.text
parser = etree.HTMLParser(encoding='utf-8')
response2 = etree.HTML(response,parser=parser)
star_count = response2.xpath('//p/a/text() ')
for i in range(10):
star_name = response2.xpath('//p/a/text() ')[i]
star_url = 'http://www.yue365.com' + response2.xpath('//p/a/@href')[i]
try:
Mysql.insert_stars(star_name, star_url)
except Exception as e:
print(e)
#爬取剩余的
try:
soup = BeautifulSoup(r.content.decode(), 'html.parser')
body = soup.body
stars_as = body.find_all('a', attrs={'class': 'show'})
stars_bs = body.find_all('a', attrs={'class': 'dis-112'})
for star in stars_as:
star_url = 'http://www.yue365.com' + star['href']
star_name = star.string
try:
Mysql.insert_stars(star_name,star_url)
except Exception as e:
print(e)
for star in stars_bs:
star_url = 'http://www.yue365.com' + star['href']
star_name = star.string
try:
Mysql.insert_stars(star_name,star_url)
except Exception as e:
print(e)
except:
pass下一步,获取图片地址。从数据库中提取明星网址,然后爬取网址中的图片,根据图4便可爬取,然后再存到数据库中,这一步较为简单,
代码如下:
items = Mysql.get_star_url()
headers = {
'Host':'www.yue365.com',
'User-Agent':'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.131 Mobile Safari/537.36'
}
for item in items:
url = item.get('star_url')
r = requests.get(url,headers=headers)
r.encoding = 'utf-8'
response = r.text
parser = etree.HTMLParser(encoding='utf-8')
response2 = etree.HTML(response, parser=parser)
star_img = response2.xpath('//div[@class="mx_tu f_l"]/img/@src')
try:
Mysql.insert_img(star_img, url)
except Exception as e:
print(e)第三步,保存图片并定义加载图片函数。这里以保存在本地为例。item为包含明星名字和其图片网址的字典,我们通过os.path.sep格式化路径,以明星名字作为文件夹名,然后请求图片url,以二进制形式写入数据,调用md5以图片md5格式命名,避免文件名重复,。代码如下:
def save_image(item):
img_path = 'img' + os.path.sep + item.get('star_name')
if not os.path.exists(img_path):
os.makedirs(img_path)
try:
resp = requests.get(item.get('star_img'))
if codes.ok == resp.status_code:
file_path = img_path + os.path.sep + '{file_name}.{file_suffix}'.format(
file_name=md5(resp.content).hexdigest(),
file_suffix='jpg')
if not os.path.exists(file_path):
with open(file_path, 'wb') as f:
f.write(resp.content)
print('Downloaded image path is %s' % file_path)
print('success')
else:
print('Already downloaded', file_path)
except requests.ConnectionError:
print('Failed to save image,item %s' % item)运行程序后可看到程序所在文件夹多了Img文件夹,文件夹中又包含2000多个子文件夹用来存储明星照片:
最后在开始获得明星颜值分数。人脸识别程序请求参数应该是Base64形式的图片文件,我们可以通过调用base64库实现:
def get_img_base(file):
with open(file,'rb') as fp:
content = base64.b64encode(fp.read())
return content然后再利用os.listdir获取文件夹的名字(明星的名字),格式化图片路径,将其传入get_img_base,再传入人脸检测程序:
def load_data(img_dir):
for guy in os.listdir(img_dir):
star_name = guy
person_dir = pjoin(img_dir, guy)
for i in os.listdir(person_dir):
image_dir = img_dir + r'/' + star_name + r'/' + i
star_beauty = beauty_test(image_dir)
try:
print(star_name,star_beauty)
Mysql.insert_star_beauty(star_name, star_beauty)
except Exception as e:
# 打印错误日志
print(e)
到此为止,我们已经爬取了一个网页上明星的全部信息,只需通过一个简单的for循环,就可以爬取全部26个网页的信息:
def get_star(x):
x = chr(x)
url = 'http://www.yue365.com/mingxing/zimu/' + x + '.shtml':
for x in range(97,123):
get_star(x)后记
调用人脸识别接口时可能会有个别识别异常,为防止程序中断,只需通过try,except来跳过异常位置。
下图为颜值前十名名单,你猜到了吗?

你是否认可api对颜值的判定呢?

个人网站:我的数据生活
一些其他有趣API的调用:
贝特西:基于API实现Django网站’历史上的今天‘功能zhuanlan.zhihu.com
