前言
字典树(Trie树)这一数据结构是不太常见但是十分好用
定义
首先,何为字典树(Trie树)?顾名思义,就是在查询目标时,像字典一样按照一定排列顺序标准和步骤访问树的节点,举一个简单例子,英文字典查单词"He",那么第一步你肯定要按照a-z的顺序先找到h这个首字母,然后再按照相同顺序找到e。博主所要介绍的字典树就是类似字典这样的结构。

上述查找单词的过程就是不断查找与所查单词相同前缀的字符串,直至查找到所查单词的最后一个字母。因此,字典树又称为前缀树(prefix Tree)。
性质
以hell、hi、new、nop为例建立一个字典树,构造如下
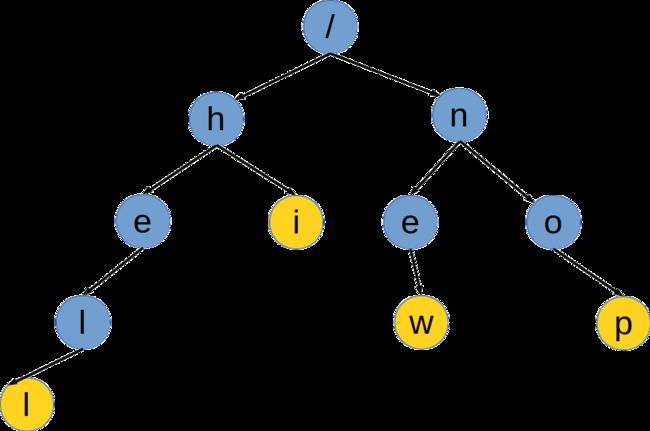
根据上文所述可以得到字典树的结构性质
- Trie树的根节点不存放任何字符,除根节点以外,每个节点只存放一个字符
- 从根节点到某一节点路径上组成的字符串即为该节点所对应的字符串
- 每个节点的子节点存放的字符互不相同
根据以上三点来构造字典树。
字典树的构造
字典树的构造其实较为简单,和一般树的构造没有太大区别。接下来将对字典树的插入、删除、查询操作进行分析与讲解。
插入操作
在没有字典树的时候,我们需要先构建出字典树。
以插入hell为例:
- 先检查根节点的子节点中是否存在'h',没有则插入一个保存'h'的节点,有则继续访问到'h'节点
- 继续到'h'节点,检查'h'节点是否是否存在'e',没有则插入一个保存'e'的节点,以此类推
- 直到需要插入的字符串中所有的字符都插入完,
再 最后一个节点处标记上单词标记,表示从根节点到达该点即为一个单词
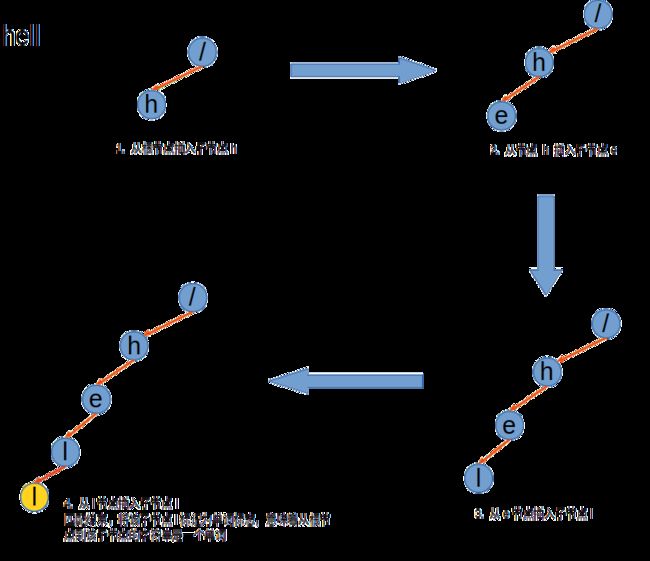
再插入单词hit,过程如下,检查=>存在则访问/不存在则建立新节点再访问=>直到要插入的单词到达最后一个字符。

字典树的插入操作比较简单,不需要考虑太多排序问题。
查询操作
正如上文所说,按照一定的标准进行查询目标字符串,每个节点都储存一个字符,根节点到达子节点路径组成的字符串即为该节点所对应的字符串,那么查询目标字符串时按照从根节点一步一步访问相应字符所在的节点,其实也就是匹配字符串前缀的过程。
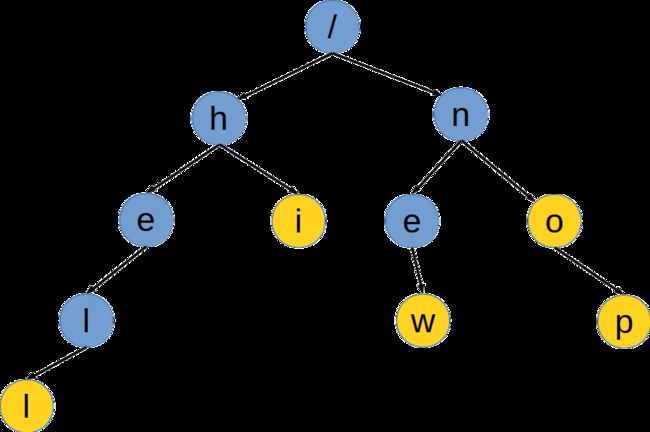
如下图,在字典树中,查询"hell",
- 从根节点查询根节点的子节点找寻到'h'
- 从'h'的子节点中查询到'e'
- 从'e'的子节点中查询到'l'
- 从'l'的子节点中查询到'l',该节点有单词标记位,字符串匹配成功,返回
[图片上传失败...(image-f028c4-1611057619223)]
如果在该字典中查询no
- 从根节点查询根节点的子节点找寻到'n'
- 从'n'的子节点中查询到'o',匹配结束,但是由于该节点没有单词标记位,字符串匹配失败,没有找到该单词,返回
删除操作
删除操作相对于插入与查询复杂一点,但是也很简单,删除的前提是单词已经存在于字典树。
删除字典树节点的操作需要考虑目标字符串最后一个字符是否是树中的叶子节点。
因为一个单词可能是另一个单词的前缀部分,如果不是叶子节点,我们只需要把该单词的单词标志位清空即可,无需删除整个“树枝”。
删除的单词处于前缀
比如,想要删除"no"这个单词
- 首先从根节点出发找到'n'这一节点
- 从'n'出发找到'0'这一节点
- 字符串匹配结束,'o'节点处有单词标志位,由于'o'此时不是叶子节点,那么清除掉该节点的单词标志位即可。
删除整个单词
比如,想要删除"hell"这个单词,与第一种删除相同,只不过是从最后一个节点,'l'节点是叶子节点,开始往上进行节点删除操作。
删除分支上的单词
比如,想要删除"hi",那么与前两种其实一致,访问到叶子节点'i',删除叶子节点,并向上访问,访问到'h',由于删除'i'以后,'h'依然不是叶子节点,因此不再继续删除节点。
删除的单词包含了其他单词
比如,想要删除"nop",与前几种类似,先访问到叶子节点'p'删除,然后上移发现'o'是叶子节点,然而'o'有单词标记位,所以,这里不再继续删除。
有上面几种删除操作,我们得到了删除的标准:
- 如果单词最后字符是非叶子节点的单词,只清除单词标志位
- 如果单词单独一枝,与其他单词都独立,那么整枝删除
- 如果单词删除过程中遇到非叶子结点,那么删除操作结束
- 如果单词删除过程中遇到其他单词的单词标志位,删除操作结束
字典树的用途
了解了这么多字典树的各种操作,相信你对字典树的用途有个大概了解了,字典树最大作用是用于==字符串的各种匹配==,前缀匹配(模糊搜索),字符串查找(字典)等等。
前缀匹配(模糊搜索)
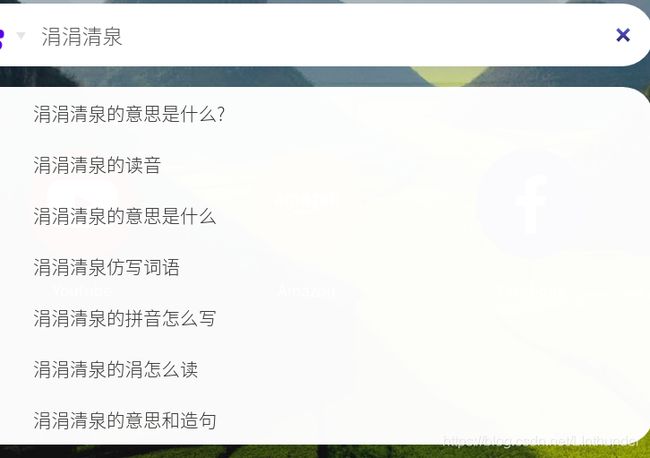
博主只打出了“涓涓清泉”四个关键字,其搜索列表返回了诸多以涓涓清泉为首的选项
字符串查找(字典)
顾名思义,就是一个单纯的字典而已,不多举例。
意义
字典树的构建,通过利用空间换时间的思想以及字符串的公共前缀减少无效的字符串比较操作从而使得插入和查找字符串变得高效.其插入或者查找的时间复杂度为O(n),n为字符串长度。
当然,字典树有着它的弊端,当所插入的单词没有很多公共前缀时,字典树的构建变得十分复杂和低效。
代码实现(Java + Go)
Java版本
import java.util.*;
public class TrieTree {
class TrieNode{
public TrieNode[] subNode;
public int count;//该节点的子节点个数
public boolean isWord;//单词标记位
public TrieNode() {
this.count = 0;
this.isWord = false;
this.subNode = new TrieNode[26];//只包含小写字母a-z
}
}
public TrieNode root;
public TrieTree() {
root = new TrieNode();
}
public boolean search(String word) {
TrieNode curNode = root;
int index;
for(int i = 0; i < word.length(); i++) {
index = word.charAt(i)-'a';
if(curNode.subNode[index]!= null) {
curNode = curNode.subNode[index];
}else{
return false;
}
}
return curNode.isWord;
}
public void insert(String word) {
if(search(word)) {
System.out.println("The word already exists.");
return;
}
TrieNode node = root;
int index;
for(int i = 0; i < word.length(); i++) {
index = word.charAt(i) - 'a';
if(node.subNode[index]==null) {
node.subNode[index]= new TrieNode();
}
node.count++;
node = node.subNode[index];
}
node.isWord = true;
}
public void delete(String word) {
if(!search(word)) {
System.out.println("No such word.");
return;
}
TrieNode node = root;
LinkedList indexList = new LinkedList();
LinkedList nodeList = new LinkedList();
int index;
for(int i = 0; i < word.length(); i++) {
index = word.charAt(i) - 'a';
indexList.add(index);
nodeList.add(node);
node = node.subNode[index];
}
for(int i = word.length() - 1; i >= 0; i--) {
node = nodeList.pollLast();
index = indexList.pollLast();
if(node.subNode[index].subNode == null) {
if(i != word.length() - 1) {
if(node.subNode[index].isWord == true) {//如果前缀节点中有单词标记位,那么不再继续删除
return;
}
}
node.subNode[index] = null;
node.count--;
}
if(i == word.length()-1) {
if(node.subNode[index].subNode != null) {
node.subNode[index].isWord = false;
return;
}
}
}
}
public static void main(String[] args) {
TrieTree myTrieTree = new TrieTree();
String[] words = {"hello","face","hi","hell","why"};
//插入字符串
for(String word : words)
myTrieTree.insert(word);
//插入重复字符串
myTrieTree.insert("hello");
//删除字符串
myTrieTree.delete("hell");
//重复删除字符串
myTrieTree.delete("hell");
myTrieTree.delete("hi");
//查询字符串,找到为true,未找到为false
System.out.println(myTrieTree.search("hello"));
System.out.println(myTrieTree.search("hi"));
System.out.println(myTrieTree.search("hell"));
}
}
Go版本
package main
import (
"fmt"
)
type TrieNode struct {
children []*TrieNode
count int
isWord bool
}
func createTrieNode() *TrieNode{
return &TrieNode{
children: make([]*TrieNode, 26),
count: 0,
isWord: false,
}
}
type TrieTree struct {
root *TrieNode
}
func createTrieTree() *TrieTree{
root := createTrieNode()
return &TrieTree{
root: root,
}
}
type method interface {
search(word string) bool
insert(word string)
delete(word string)
}
func(tireTree *TrieTree) search(word string) bool{
tmpNode := tireTree.root
for _,w := range word {
index := int(w - 'a')
if tmpNode.children[index] != nil{
tmpNode = tmpNode.children[index]
}else{
return false
}
}
return tmpNode.isWord
}
func(tireTree *TrieTree) insert(word string) {
if tireTree.search(word){
fmt.Println("The word already exists!")
}
tmpNode := tireTree.root
for _,w := range word {
index := int(w - 'a')
if tmpNode.children[index] == nil{
tmpNode.children[index] = createTrieNode()
tmpNode.count++
}
tmpNode = tmpNode.children[index]
}
tmpNode.isWord = true
}
func(tireTree *TrieTree) delete(word string) {
if !tireTree.search(word){
fmt.Println("No such word")
}
tmpNode := tireTree.root
var (
indexList []int
nodeList []*TrieNode
)
for _,w := range word {
index := int(w - 'a')
indexList = append(indexList, index)
nodeList = append(nodeList, tmpNode)
tmpNode = tmpNode.children[index]
}
for i := len(indexList)-1; i >=0; i++ {
index := indexList[i]
tmpNode = nodeList[i]
if tmpNode.children[index].children == nil{
if i != len(indexList) - 1 {
if tmpNode.children[index].isWord {
return
}
}
tmpNode.children[index] = nil
tmpNode.count--
}
if i == len(indexList) - 1{
if tmpNode.children[index].children != nil{
tmpNode.children[index].isWord = false
return
}
}
}
}
func main(){
words := []string{"hello","face","hi","hell","why"}
myTrieTree := createTrieTree()
//插入字符串
for _, word := range words {
myTrieTree.insert(word)
}
//插入重复字符串
myTrieTree.insert("hello")
//删除字符串
myTrieTree.delete("hell")
//重复删除字符串
myTrieTree.delete("hell")
myTrieTree.delete("hi")
//查询字符串,找到为true,未找到为false
fmt.Println(myTrieTree.search("hello"))
fmt.Println(myTrieTree.search("hi"))
fmt.Println(myTrieTree.search("hell"))
}
总结
字典树的难度不是很大,但却是一种十分有用的数据结构,掌握之后,对于解决一些有关字符串匹配、公共前缀的问题十分有帮助。
当然我们也说了,字典树有着自己的弊端,由于用空间换时间,如果遇到了一堆公共前缀很少的单词进行字典树构造时,空间需求就显得十分大了。