李宏毅ML作业一
任务说明

 train.csv
train.csv

test.csv
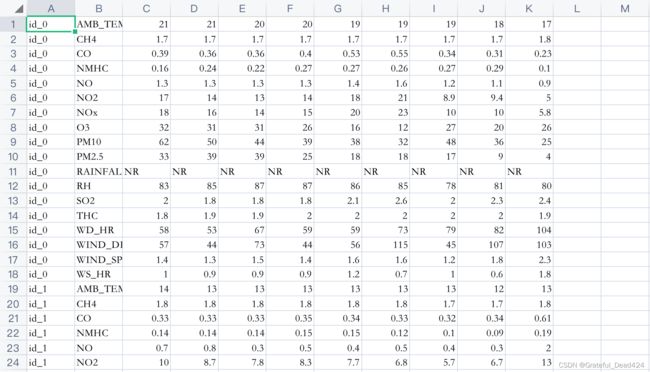
任务目标
输入:9个小时的数据,共18项特征(AMB_TEMP, CH4, CO, NHMC, NO, NO2, NOx, O3, PM10, PM2.5, RAINFALL, RH, SO2, THC, WD_HR, WIND_DIREC, WIND_SPEED, WS_HR)
输出:第10小时的PM2.5数值
模型:线性回归
任务解答
数据处理
"""导入数据"""
import sys
import pandas as pd
import numpy as np
#读入train.csv,繁体字以big5编码
data = pd.read_csv('/Users/zhucan/Desktop/李宏毅深度学习作业/第一次作业/train.csv',encoding = 'big5')
#显示前10行
print(data.head())
data.shape结果:

data.shape
#(4320, 27)# 丢弃前两列,需要的是从第三列开始的数值
data = data.iloc[:, 3:]
# 把降雨的NR字符变成数值0
data[data == 'NR'] = 0
# 把dataframe转换成numpy的数组
raw_data = data.to_numpy()
raw_data结果:
现在shape变成了(4320,24)
提取特征
分成了12个月,每个月有18行×480列的数据。
对于每个月,每10个小时分成一组,由前9个小时的数据来预测第10个小时的PM2.5,把前9小时的数据放入x,把第10个小时的数据放入y。窗口的大小为10,从第1个小时开始向右滑动,每次滑动1小时。因此,每个月都有471组这样的数据。
把一组18×9的数据平铺成一行向量,然后放入x的一行中,每个月有471组,共有12×471组向量,因此x有12×471行,18×9列。

将预测值放入y中,y有12(月)×471(组)行,1列。
month_data = {}
for month in range(12):
sample = np.empty([18, 480])
for day in range(20):
sample[:, day * 24 : (day + 1) * 24] = raw_data[18 * (20 * month + day) : 18 * (20 * month + day + 1), :]
month_data[month] = samplex = np.empty([12 * 471, 18 * 9], dtype = float)
y = np.empty([12 * 471, 1], dtype = float)
for month in range(12):
for day in range(20):
for hour in range(24):
if day == 19 and hour > 14:
continue
x[month * 471 + day * 24 + hour, :] = month_data[month][:,day * 24 + hour : day * 24 + hour + 9].reshape(1, -1) #vector dim:18*9 (9 9 9 9 9 9 9 9 9 9 9 9 9 9 9 9 9 9)
y[month * 471 + day * 24 + hour, 0] = month_data[month][9, day * 24 + hour + 9] #value
print(x)
print(y)结果:
[[14. 14. 14. ... 2. 2. 0.5]
[14. 14. 13. ... 2. 0.5 0.3]
[14. 13. 12. ... 0.5 0.3 0.8]
...
[17. 18. 19. ... 1.1 1.4 1.3]
[18. 19. 18. ... 1.4 1.3 1.6]
[19. 18. 17. ... 1.3 1.6 1.8]]
[[30.]
[41.]
[44.]
...
[17.]
[24.]
[29.]]标准化(Normalization)
mean_x = np.mean(x, axis = 0) #18 * 9 按列求平均
std_x = np.std(x, axis = 0) #18 * 9 按列求标准差
for i in range(len(x)): #12 * 471
for j in range(len(x[0])): #18 * 9
if std_x[j] != 0:
x[i][j] = (x[i][j] - mean_x[j]) / std_x[j]
x
结果:

划分数据
把训练数据分成训练集train_set和验证集validation,其中train_set用于训练,而validation不会参与训练,仅用于验证。
import math
x_train_set = x[: math.floor(len(x) * 0.8), :] #math.floor向下取整
y_train_set = y[: math.floor(len(y) * 0.8), :]
x_validation = x[math.floor(len(x) * 0.8): , :]
y_validation = y[math.floor(len(y) * 0.8): , :]
print(x_train_set)
print(y_train_set)
print(x_validation)
print(y_validation)
print(len(x_train_set))
print(len(y_train_set))
print(len(x_validation))
print(len(y_validation))结果:

训练


和上图不同处: 下面Loss的代码用到的是 Root Mean Square Error
因为存在常数项b,所以维度(dim)需要多加一列,即原来是y = wx + b,可以统一成 y = [w b] [x 1];eps项是极小值,避免adagrad的分母为0.
每一个维度(dim)会对应到各自的gradient和权重w,通过一次次的迭代(iter_time)学习。最终,将训练得到的模型(权重w)存储为.npy格式的文件。
dim = 18 * 9 + 1
w = np.zeros([dim, 1]) #最后一个w是b
x = np.concatenate((np.ones([12 * 471, 1]), x), axis = 1).astype(float)
learning_rate = 100
iter_time = 1000
adagrad = np.zeros([dim, 1])
eps = 0.0000000001
for t in range(iter_time):
loss = np.sqrt(np.sum(np.power(np.dot(x, w) - y, 2))/471/12)
#rmse power(x,y)函数,计算x的y次方。
if(t%100 == 0):
print(str(t) + ":" + str(loss))
gradient = 2 * np.dot(x.transpose(), np.dot(x, w) - y) #dim*1
adagrad += gradient ** 2
w = w - learning_rate * gradient / np.sqrt(adagrad + eps)
np.save('weight.npy', w)
w结果:
0:27.071214829194115
100:33.78905859777454
200:19.91375129819709
300:13.531068193689686
400:10.645466158446165
500:9.27735345547506
600:8.518042045956497
700:8.014061987588416
800:7.636756824775686
900:7.33656374037112
array([[ 2.13740269e+01],
[ 3.58888909e+00],
[ 4.56386323e+00],
[ 2.16307023e+00],
[-6.58545223e+00],
[-3.38885580e+01],
[ 3.22235518e+01],
...
[-5.57512471e-01],
[ 8.76239582e-02],
[ 3.02594902e-01],
[-4.23463160e-01],
[ 4.89922051e-01]])
预测

# 读入测试数据test.csv
testdata = pd.read_csv('/Users/zhucan/Desktop/李宏毅深度学习作业/第一次作业/test.csv', header = None, encoding = 'big5')
# 丢弃前两列,需要的是从第3列开始的数据
test_data = testdata.iloc[:, 2:]
# 把降雨为NR字符变成数字0
test_data[test_data == 'NR'] = 0
# 将dataframe变成numpy数组
test_data = test_data.to_numpy()
# 将test数据也变成 240 个维度为 18 * 9 + 1 的数据
test_x = np.empty([240, 18*9], dtype = float)
for i in range(240):
test_x[i, :] = test_data[18 * i: 18* (i + 1), :].reshape(1, -1)
for i in range(len(test_x)):
for j in range(len(test_x[0])):
if std_x[j] != 0:
test_x[i][j] = (test_x[i][j] - mean_x[j]) / std_x[j]
test_x = np.concatenate((np.ones([240, 1]), test_x), axis = 1).astype(float)
test_x结果:

ans_y = np.dot(test_x, w)
ans_y结果:
Out:
array([[ 5.17496040e+00],
[ 1.83062143e+01],
[ 2.04912181e+01],
[ 1.15239429e+01],
[ 2.66160568e+01],
...,
[ 4.12665445e+01],
[ 6.90278920e+01],
[ 4.03462492e+01],
[ 1.43137440e+01],
[ 1.57707266e+01]])
修改代码(加入二次项)
# 训练集
for month in range(12):
for day in range(20):
for hour in range(24):
if day == 19 and hour > 14:
continue
x1 = month_data[month][:, day * 24 + hour: day * 24 + hour + 9].reshape(1,-1) # vector dim:18*9 (9 9 9 9 9 9 9 9 9 9 9 9 9 9 9 9 9 9)
x[month * 471 + day * 24 + hour, :18 * 9] = x1
# 在这里加入了x的二次项
x[month * 471 + day * 24 + hour, 18 * 9: 18 * 9 * 2] = np.power(x1, 2)
y[month * 471 + day * 24 + hour, 0] = month_data[month][9, day * 24 + hour + 9] # value
# 测试集
testdata = pd.read_csv('./test.csv', header = None, encoding = 'big5')
test_data = testdata.iloc[:, 2:]
test_data[test_data == 'NR'] = 0
test_data = test_data.to_numpy()
test_x1 = np.empty([240, 18*9], dtype = float)
test_x = np.empty([240, 18*9*2], dtype = float)
for i in range(240):
test_x1 = test_data[18 * i: 18 * (i + 1), :].reshape(1, -1).astype(float)
# 同样在这里加入test x的二次项
test_x[i, : 18 * 9] = test_x1
test_x[i, 18 * 9:] = np.power(test_x1 , 2)
for i in range(len(test_x)):
for j in range(len(test_x[0])):
if std_x[j] != 0:
test_x[i][j] = (test_x[i][j] - mean_x[j]) / std_x[j]
test_x = np.concatenate((np.ones([240, 1]), test_x), axis = 1).astype(float)