参加实验楼的楼赛21期,关于机器学习的, 我以前没怎么接触过,所以是临时在网上查找资料解答的. 如果有一些错误或者是不完善的地方,欢迎指出.
题目
介绍
题目提供一个来自某银行的真实数据集,数据集前 10 行预览如下:

其中:
- 第 1~6 列为客户近期历史账单信息。
- 第 7 列为该客户年龄。
- 第 8 列为该客户性别。(Female, Male)
- 第 9 列为该客户教育程度。(Graduate School, University, High School, Others)
- 第 10 列为该客户婚姻状况。(Married, Single, Others)
- 第 11 列为客户持卡风险状况 。(LOW, HIGH)
此外:
- 训练数据集
credit_risk_train.csv总共有 20000 条数据。 - 测试数据集
credit_risk_test.csv总共有 5000 条数据。
下载:
wget http://labfile.oss.aliyuncs.com/courses/1109/credit_risk_train.csv
wget http://labfile.oss.aliyuncs.com/courses/1109/credit_risk_test.csv
目标
你需要使用训练数据集构建机器学习分类预测模型,并针对测试数据集进行预测,准确率 ≥0.8 即为合格。
要求
提交时,请将预测结果按测试数据集中每条数据的排列顺序,以单列数据的形式存入
credit_risk_pred.csv数据文件中,列名为RISK。需要将
credit_risk_pred.csv放置于/home/shiyanlou/Code路径下方。
credit_risk_pred.csv 数据文件仅存在 RISK 列,示例如下:

提示
- 你可能会用到 scikit-learn 提供的分类预测模型。
- 你可能会用到 Pandas 对数据进行预处理。
- 完成本题目可以自由使用第三方模块,在线环境
/home/shiyanlou/anaconda3/bin/python路径下有 scikit-learn, pandas 等常用模块。
知识点
- 机器学习分类预测
分析与解答
模型选择
首先要选出合适的模型, 最开始随便试了 SGDClassifier,LogisticRegression等模型, 都没有达到0.8的准确度
然后上网查找,根据这张图选择了 svm 支持向量机模型
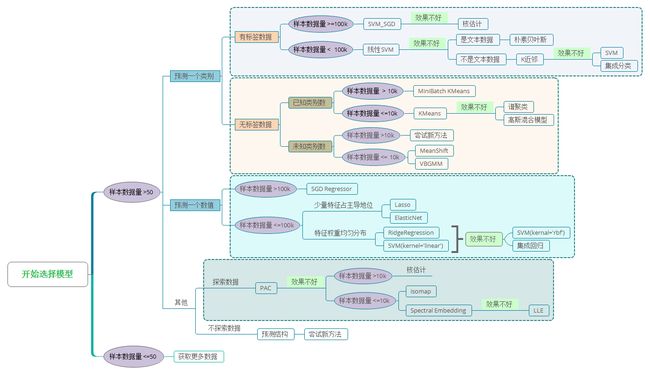
from sklearn.svm import SVC as MODEL
读取数据
可以用 pandas 读取 csv 数据, 并进行一些预处理, 并分好训练数据集与测试数据集
import pandas as pd
def getData():
data = pd.read_csv(trainfile)
test = pd.read_csv(testfile) #names = cols) #.replace(to_replace ='"',value = np.nan)
data = label(data)
test = label(test)
x_train,y_train =data.iloc[:,:-1].as_matrix(), data.iloc[:,-1].as_matrix()
x_test = test.iloc[:,:].as_matrix()
y_test=None
return x_train,y_train, x_test,y_test
非数值特征处理
有些特征是非数值的, 需要进行编码, 比如 gender education 等, 编码有很多方式, 比如 onehotkey, 由于这里是字符串类型的, 可以用 labelencoder , 它可以将一个特征下的值集合一次编码为 0,1,2...
要想解码, 保存最后的预测结果. 我设置了一个全局变量 converetor , 来保存这个 encoder
from sklearn.preprocessing import LabelEncoder as LE
convertor = None # result convertor
def label(data):
global convertor
for col in data.columns:
if data[col].dtype == 'object':
le = LE()
if col=='RISK':
convertor = le
le.fit(data[col])
data[col]= le.transform(data[col])
return data
拟合预测
fit 函数拟合时, 不同的模型时间不一样, 适应的场景,数据也不一样, 准确度也不一样
def predict(model=MODEL):
predictor = model()
x_train,y_train,x_test,_ = getData()
predictor.fit(x_train,y_train)
res = predictor.predict(x_test)
save(res)
保存数据
用 pandas 保存为 csv
def save(result):
result = convertor.inverse_transform(result)
dataframe = pd.DataFrame({'RISK':result})
dataframe.to_csv('credit_risk_pred.csv',index=False,sep=',')
总结与反思
时间匆忙, 这个代码比较粗略,还有很多可以考虑的地方, 比如检验一些值的方差是否过大, 特征缩放, 评估模型的准确度等等
最后, 感觉这个网站,这个比赛挺有趣的, 如果想注册, 可以点这里, 邀请了:)
代码
import pandas as pd
from sklearn.preprocessing import LabelEncoder as LE
from sklearn.svm import SVC as MODEL
trainfile = 'credit_risk_train.csv'
testfile = 'credit_risk_test.csv'
convertor = None # result convertor
def label(data):
global convertor
for col in data.columns:
if data[col].dtype == 'object':
le = LE()
if col=='RISK':
convertor = le
le.fit(data[col])
data[col]= le.transform(data[col])
return data
def getData():
data = pd.read_csv(trainfile)
test = pd.read_csv(testfile) #names = cols) #.replace(to_replace ='"',value = np.nan)
data = label(data)
test = label(test)
x_train,y_train =data.iloc[:,:-1].as_matrix(), data.iloc[:,-1].as_matrix()
x_test = test.iloc[:,:].as_matrix()
y_test=None
return x_train,y_train, x_test,y_test
def save(result):
result = convertor.inverse_transform(result)
dataframe = pd.DataFrame({'RISK':result})
dataframe.to_csv('credit_risk_pred.csv',index=False,sep=',')
def predict(model=MODEL):
predictor = model()
x_train,y_train,x_test,_ = getData()
predictor.fit(x_train,y_train)
res = predictor.predict(x_test)
save(res)
if __name__=='__main__':
predict()
参考资料
[1] : 数据预处理中的数据编码问题 | python 数据挖掘思考笔记 (2)
[2]: sklearn.preprocessing.LabelEncode
[3]: sklearn: 选择正确的模型
[4]: 利用 Scikit Learn 的 Python 数据预处理实战指南