日志(可用来恢复数据)
注:MySQL 整体来看,一共有两块:一块是 Server 层,它主要做的是 MySQL 功能层面的事情;还有一块是引擎层,负责存储相关的具体事宜。它们各有自己的日志系统。 redo log 是 InnoDB 引擎特有的日志,而 Server 层也有自己的日志,称为 binlog(归档日志)。
日志的作用:因为每一次的更新操作都需要写进磁盘,然后磁盘也要找到对应的那条记录,然后再更新,整个过程 IO 成本、查找成本都很高。为了解决这个问题,MySQL 的设计者就用了类似酒店掌柜粉板的思路来提升更新效率。
redo Log(重做日志)(属于InnoDB引擎)(粉板)
Mysql采用WAL(write-Ahead Logging)技术,它的关键点在于先写日志再写磁盘。这个日志就是Redo Log。当一条记录需要更新的时候,InnoDB引擎会把记录先写到Redo Log中,并更新内存,等到合适的时间,再将记录更新到磁盘中。这个更新往往在系统比较空闲的时候做,但是当Redo Log的空间用完的时候,就需要先将记录更新,以便接下来继续操作。
InnoDB的Redo Log是固定大小的,比如可以配置为一组 4 个文件,每个文件的大小是 1GB,那么这块“粉板”总共就可以记录 4GB 的操作。从头开始写,写到末尾就又回到开头循环写,如下面这个图所示。
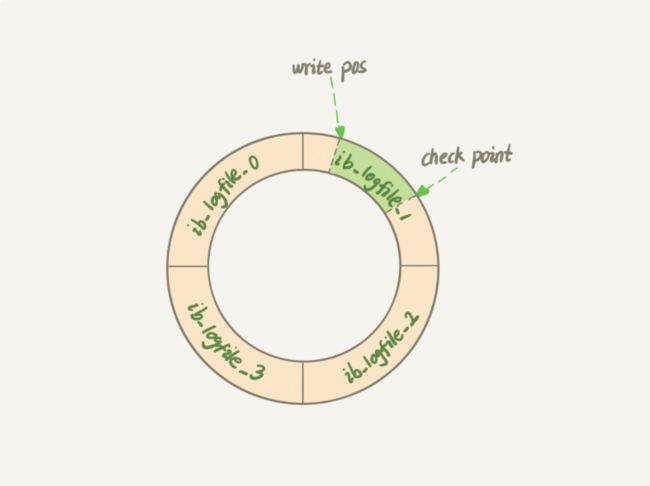
write pos 是当前记录的位置,一边写一边后移,写到第 3 号文件末尾后就回到 0 号文件开头。checkpoint 是当前要擦除的位置,也是往后推移并且循环的,擦除记录前要把记录更新到数据文件。
write pos 和 checkpoint 之间的是“粉板”上还空着的部分,可以用来记录新的操作。如果 write pos 追上 checkpoint,表示“粉板”满了,这时候不能再执行新的更新,得停下来先擦掉一些记录,把 checkpoint 推进一下。
有了 redo log,InnoDB 就可以保证即使数据库发生异常重启,之前提交的记录都不会丢失,这个能力称为 crash-safe。
Binlog(归档日志)(属于Service层)
有两份日志的原因:①mysql自带引擎MyISAM没有crash-safe能力,而binglog也只能用来归档。
Redo Log和Binlog的不同点:
redo log 是 InnoDB 引擎特有的;binlog 是 MySQL 的 Server 层实现的,所有引擎都可以使用。
redo log 是物理日志,记录的是“在某个数据页上做了什么修改”;binlog 是逻辑日志,记录的是这个语句的原始逻辑,比如“给 ID=2 这一行的 c 字段加 1 ”。
redo log 是循环写的,空间固定会用完;binlog 是可以追加写入的。“追加写”是指 binlog 文件写到一定大小后会切换到下一个,并不会覆盖以前的日志。
两阶段提交
更新一个数据的过程:
1、执行器先找引擎取 ID=2 这一行。ID 是主键,引擎直接用树搜索找到这一行。如果 ID=2 这一行所在的数据页本来就在内存中,就直接返回给执行器;否则,需要先从磁盘读入内存,然后再返回。
2、执行器拿到引擎给的行数据,把这个值加上 1,比如原来是 N,现在就是 N+1,得到新的一行数据,再调用引擎接口写入这行新数据。
3、引擎将这行新数据更新到内存中,同时将这个更新操作记录到 redo log 里面,此时 redo log 处于 prepare 状态。然后告知执行器执行完成了,随时可以提交事务。
4、执行器生成这个操作的 binlog,并把 binlog 写入磁盘。
5、执行器调用引擎的提交事务接口,引擎把刚刚写入的 redo log 改成提交(commit)状态,更新完成。
update 语句的执行流程图如下,图中浅色框表示是在 InnoDB 内部执行的,深色框表示是在执行器中执行的。
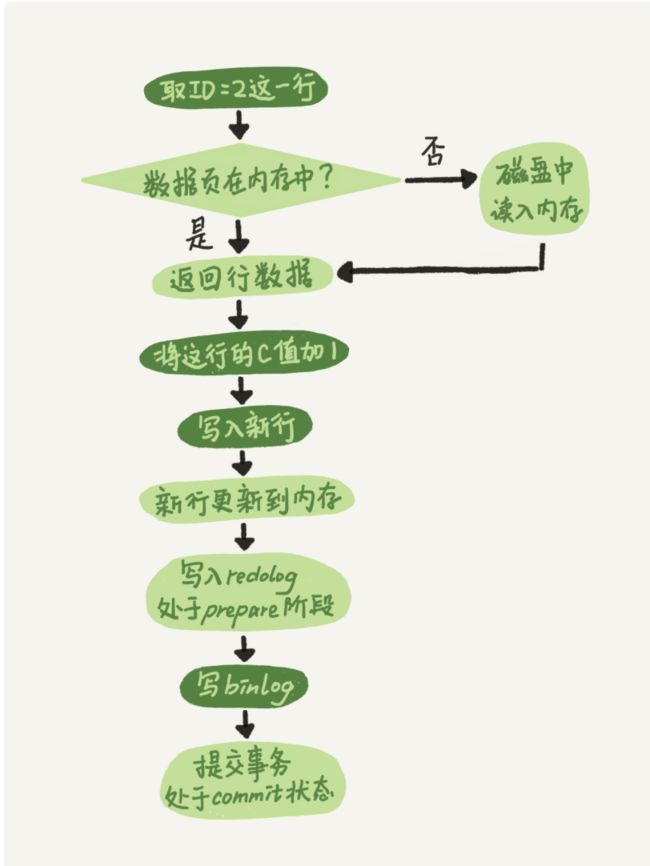
图中将 redo log 的写入拆成了两个步骤:prepare 和 commit,这就是"两阶段提交"。两阶段提交的主要是为了让两份日志之间的逻辑一致。
先写 redo log 后写 binlog。假设在 redo log 写完,binlog 还没有写完的时候,MySQL 进程异常重启。由于我们前面说过的,redo log 写完之后,系统即使崩溃,仍然能够把数据恢复回来,所以恢复后这一行 c 的值是 1。但是由于 binlog 没写完就 crash 了,这时候 binlog 里面就没有记录这个语句。因此,之后备份日志的时候,存起来的 binlog 里面就没有这条语句。然后你会发现,如果需要用这个 binlog 来恢复临时库的话,由于这个语句的 binlog 丢失,这个临时库就会少了这一次更新,恢复出来的这一行 c 的值就是 0,与原库的值不同。
先写 binlog 后写 redo log。如果在 binlog 写完之后 crash,由于 redo log 还没写,崩溃恢复以后这个事务无效,所以这一行 c 的值是 0。但是 binlog 里面已经记录了“把 c 从 0 改成 1”这个日志。所以,在之后用 binlog 来恢复的时候就多了一个事务出来,恢复出来的这一行 c 的值就是 1,与原库的值不同。
事务(事务间隔离)
事务就是要保证一组数据库操作,要么全部成功,要么全部失败。在MySQL中,事务支持是在引擎层实现的。(MySQL 原生的 MyISAM 引擎就不支持事务,这也是 MyISAM 被 InnoDB 取代的重要原因之一。)
隔离性与隔离级别
当数据库上有多个事务同时执行的时候,就可能出现脏读(dirty read)、不可重复读(non-repeatable read)、幻读(phantom read)的问题,为了解决这些问题,就有了“隔离级别”的概念。
隔离的越严实,效率就会越低。
SQL 标准的事务隔离级别包括:读未提交(read uncommitted)、读提交(read committed)、可重复读(repeatable read)和串行化(serializable )。
读未提交是指,一个事务还没提交时,它做的变更就能被别的事务看到。
读提交是指,一个事务提交之后,它做的变更才会被其他事务看到。
可重复读是指,一个事务执行过程中看到的数据,总是跟这个事务在启动时看到的数据是一致的。当然在可重复读隔离级别下,未提交变更对其他事务也是不可见的。
串行化,顾名思义是对于同一行记录,“写”会加“写锁”,“读”会加“读锁”。当出现读写锁冲突的时候,后访问的事务必须等前一个事务执行完成,才能继续执行。
如下图A、B事务同时执行,不同隔离级别看到的不同结果:

若隔离级别是“读未提交”, 则 V1 的值就是 2。这时候事务 B 虽然还没有提交,但是结果已经被 A 看到了。因此,V2、V3 也都是 2。
若隔离级别是“读提交”,则 V1 是 1,V2 的值是 2。事务 B 的更新在提交后才能被 A 看到。所以, V3 的值也是 2。
若隔离级别是“可重复读”,则 V1、V2 是 1,V3 是 2。之所以 V2 还是 1,遵循的就是这个要求:事务在执行期间看到的数据前后必须是一致的。
若隔离级别是“串行化”,则在事务 B 执行“将 1 改成 2”的时候,会被锁住。直到事务 A 提交后,事务 B 才可以继续执行。所以从 A 的角度看, V1、V2 值是 1,V3 的值是 2。
在实现上,数据库里面会创建一个视图,访问的时候以视图的逻辑结果为准。在“可重复读”隔离级别下,这个视图是在事务启动时创建的,整个事务存在期间都用这个视图。在“读提交”隔离级别下,这个视图是在每个 SQL 语句开始执行的时候创建的。这里需要注意的是,“读未提交”隔离级别下直接返回记录上的最新值,没有视图概念;而“串行化”隔离级别下直接用加锁的方式来避免并行访问。
事务隔离的实现
可重复读事务实现:
在 MySQL 中,实际上每条记录在更新的时候都会同时记录一条回滚操作。记录上的最新值,通过回滚操作,都可以得到前一个状态的值。(不同时刻启动事务,会有不同的读视图(read-view)产生)
假设一个值从 1 被按顺序改成了 2、3、4,在回滚日志里面就会有类似下面的记录。

当前值是 4,但是在查询这条记录的时候,不同时刻启动的事务会有不同的 read-view。如图中看到的,在视图 A、B、C 里面,这一个记录的值分别是 1、2、4,同一条记录在系统中可以存在多个版本,就是数据库的多版本并发控制(MVCC)。对于 read-view A,要得到 1,就必须将当前值依次执行图中所有的回滚操作得到。即使现在有另外一个事务正在将 4 改成 5,这个事务跟 read-view A、B、C 对应的事务是不会冲突的。
尽量不要使用长事务。长事务意味着系统里面会存在很老的事务视图。由于这些事务随时可能访问数据库里面的任何数据,所以这个事务提交之前,数据库里面它可能用到的回滚记录都必须保留,这就会导致大量占用存储空间。
事务的启动方式
MySQL 的事务启动方式有以下几种:
1、显式启动事务语句, begin 或 start transaction。配套的提交语句是 commit,回滚语句是 rollback。
2、set autocommit=0,这个命令会将这个线程的自动提交关掉。意味着如果你只执行一个 select 语句,这个事务就启动了,而且并不会自动提交。这个事务持续存在直到你主动执行 commit 或 rollback 语句,或者断开连接。
有些客户端连接框架会默认连接成功后先执行一个 set autocommit=0 的命令。这就导致接下来的查询都在事务中,如果是长连接,就导致了意外的长事务。因此,最好总是使用 set autocommit=1, 通过显式语句的方式来启动事务。
锁
全局锁和表锁 增删改查数据(DML),修改表字段(DDL)
全局锁
使用场景:做全库逻辑备份。
①MYSQL加全局锁的命令:Flush table with read lock(FTWRL) (相比较②目前优选,对引擎没有要求)
②官方逻辑备份工具MysqlDump: -single-transaction (缺点:需要引擎支持这个隔离级别,single-transaction 方法只适用于所有的表使用事务引擎的库。)
③不推荐使用:set global readonly=true(相较于①,readonly在有些系统可能用来做其他逻辑,还有就是发生异常之后不会释放,而①会释放)
表锁:表锁、元数据锁
表锁。语法:lock tables ... read/write (例线程A: lock tables t1 read, t2 write;则其他线程写 t1、读写 t2 的语句都会被阻塞) 解锁:unlock tables(或者客户端断开的时候自动释放)(而对于 InnoDB 这种支持行锁的引擎,一般不使用 lock tables 命令来控制并发,毕竟锁住整个表的影响面还是太大。)
(共享读锁,独占写锁,加上读锁,不会限制别的线程读,但会限制别的线程写。加上写锁,会限制别的线程读写。线程 A 在执行 unlock tables 之前,也只能执行读 t1、读写 t2 的操作。连写 t1 都不允许,自然也不能访问其他表。)
另一类表级的锁是MDL(metadata lock)
mdl需不要显示调用,在访问一个表的时候会被自动加上。mdl的作用是保证读书的正确性。
在 MySQL 5.5 版本中引入了 MDL,当对一个表做增删改查操作的时候,加 MDL 读锁;当要对表做结构变更操作的时候,加 MDL 写锁。
(读锁之间不互斥,因此你可以有多个线程同时对一张表增删改查。
读写锁之间、写锁之间是互斥的)
给一个表加字段,或者修改字段,或者加索引,需要扫描全表的数据
事务中的 MDL 锁,在语句执行开始时申请,但是语句结束后并不会马上释放,而会等到整个事务提交后再释放。
如何安全的给小表加字段:①考虑在长事务中不进行DDL,或者kill掉这个事务。 ②先尝试拿MDL的写锁。
备注
全局锁主要用在逻辑备份过程中,对于引擎全部是InnoDB的库来说,用-Single-transation参数,对应用更友好。
表锁一般是在数据库引擎不支持行锁的时候才会用到。
如果你发现你的应用程序里有 lock tables 这样的语句,你需要追查一下,比较可能的情况是:
要么是你的系统现在还在用 MyISAM 这类不支持事务的引擎,那要安排升级换引擎;
要么是你的引擎升级了,但是代码还没升级。我见过这样的情况,最后业务开发就是把 lock tables 和 unlock tables 改成 begin 和 commit,问题就解决了。
MDL 会直到事务提交才释放,在做表结构变更的时候,你一定要小心不要导致锁住线上查询和更新。
行锁
Mysql的行锁是引擎自己实现的,这个InnoDB替代MylSAM的原因之一。
行锁:行锁就是针对数据表中行记录的锁。比如事务 A 更新了一行,而这时候事务 B 也要更新同一行,则必须等事务 A 的操作完成后才能进行更新。(例如:update t set k = k + 1 where id = 1 会锁update t set k = k + 2where id = 1 而不会锁update t set k = k + 1 where id = 2 )
两阶段锁(见下图)

事务 B 的 update 语句会被阻塞,直到事务 A 执行 commit 之后,
事务 B 才能继续执行。
事务 A 持有的两个记录的行锁
事务 A 持有的两个记录的行锁,都是在 commit 的时候才释放的。
在 InnoDB 事务中,行锁是在需要的时候才加上的,但并不是不需要了就立刻释放,而是要等到事务结束时才释放。这个就是两阶段锁协议
因为两阶段锁的存在,如果事务中需要锁多行,要把最可能造成锁冲突、影响并发度的锁往后放。
死锁和死锁检测(见下图)

避免死锁的方式。 一、超时机制(不推荐,时间长影响使用,时间容易误会锁的正常等待。) 二、死锁检测。发现死锁后主动回滚死锁链中的某一事物。过程如下:每当一个事务被锁的时候,就要看看它所依赖的线程有没有被别人锁住,如此循环,最后判断是否出现了循环等待,也就是死锁。缺点:每个新来的被堵住的线程,都要判断会不会由于自己的加入导致了死锁,这是一个时间复杂度是 O(n) 的操作。假设有 1000 个并发线程要同时更新同一行,那么死锁检测操作就是 100 万这个量级的。
解决死锁方案
临时把死锁检测关掉。
控制并发度。
减少死锁的主要方向,就是控制访问相同资源的并发事务量。
注:笔记主要来自于极客时间的《Mysql实战45讲》