1 简介
描述统计学(descriptive statistics)是一门统计学领域的学科,主要研究如何取得反映客观现象的数据,并以图表形式对所搜集的数据进行处理和显示,最终对数据的规律、特征做出综合性的描述分析。
下列表格对 Pandas 常用的统计学函数做了简单的总结:
| 函数名称 | 描述说明 |
|---|---|
| count() | 统计某个非空值的数量。 |
| sum() | 求和 |
| mean() | 求均值 |
| median() | 求中位数 |
| mode() | 求众数 |
| std() | 求标准差 |
| min() | 求最小值 |
| max() | 求最大值 |
| abs() | 求绝对值 |
| prod() | 求所有数值的乘积。 |
| cumsum() | 计算累计和,axis=0,按照行累加;axis=1,按照列累加。 |
| cumprod() | 计算累计积,axis=0,按照行累积;axis=1,按照列累积。 |
| corr() | 计算数列或变量之间的相关系数,取值-1到1,值越大表示关联性越强。 |
在 DataFrame 中,使用聚合类方法时需要指定轴(axis)参数。下面介绍两种传参方式:
-
- 对行操作,默认使用 axis=0 或者使用 "index";
- 对列操作,默认使用 axis=1 或者使用 "columns"。
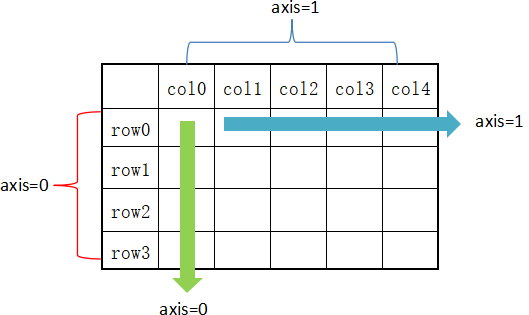
从上图可看出,axis=0 表示按垂直方向进行计算,而 axis=1 则表示按水平方向。
创建一个 DataFrame 结构,如下所示:
d = {'Name':pd.Series(['Jack','Blair','Jane','Lee']),
'Age':pd.Series([11,12,13,14]),
'Score':pd.Series([1,2,3,4])
}
df = pd.DataFrame(d)
print(df)
输出结果:
Name Age Score
0 Jack 11 1
1 Blair 12 2
2 Jane 13 3
3 Lee 14 4
2 应用
2.1 sum()求和
在默认情况下,返回 axis=0 的所有值的和。示例1 如下:
df.sum()
输出结果:
Name JackBlairJaneLee
Age 50
Score 10
dtype: object
注意:sum() 和 cumsum() 函数可以同时处理数字和字符串数据。虽然字符聚合通常不被使用,但使用这两个函数并不会抛出异常;而对于 abs()、cumprod() 函数则会抛出异常,因为它们无法操作字符串数据。
示例2:
df.sum(axis= 1)#只对number数据进行处理
输出结果:
0 12
1 14
2 16
3 18
dtype: int64
2.2 mean()求均值
示例3:
df.mean()#只对number数据进行处理
输出结果:
Age 12.5
Score 2.5
dtype: float64
示例4:
df.mean(axis=1)#只对number数据进行处理
输出结果:
0 6.0
1 7.0
2 8.0
3 9.0
dtype: float64
2.3 std()求标准差
返回数值列的标准差。
标准差是方差的算术平方根,它能反映一个数据集的离散程度。注意,平均数相同的两组数据,标准差未必相同。
示例5:
df.std()
输出结果:
Age 1.290994
Score 1.290994
dtype: float64
示例6:
df.std(axis = 1)
输出结果:
0 7.071068
1 7.071068
2 7.071068
3 7.071068
dtype: float64
2.4 数据汇总描述
describe() 函数显示与 DataFrame 数据列相关的统计信息摘要。
示例7:
df.describe()
输出结果:
Age Score
count 4.000000 4.000000
mean 12.500000 2.500000
std 1.290994 1.290994
min 11.000000 1.000000
25% 11.750000 1.750000
50% 12.500000 2.500000
75% 13.250000 3.250000
max 14.000000 4.000000
describe() 函数输出了平均值、std 和 IQR 值(四分位距)等一系列统计信息。通过 describe() 提供的include能够筛选字符列或者数字列的摘要信息。
include 相关参数值说明如下:
- object: 表示对字符列进行统计信息描述;
- number:表示对数字列进行统计信息描述;
- all:汇总所有列的统计信息。
示例8:
df.describe(include=['number'])
输出结果:
Age Score
count 4.000000 4.000000
mean 12.500000 2.500000
std 1.290994 1.290994
min 11.000000 1.000000
25% 11.750000 1.750000
50% 12.500000 2.500000
75% 13.250000 3.250000
max 14.000000 4.000000
示例9:
df.describe(include='object')
输出结果:
Name
count 4
unique 4
top Blair
freq 1
示例10:
df.describe(include='all')
输出结果:
Name Age Score
count 4 4.000000 4.000000
unique 4 NaN NaN
top Blair NaN NaN
freq 1 NaN NaN
mean NaN 12.500000 2.500000
std NaN 1.290994 1.290994
min NaN 11.000000 1.000000
25% NaN 11.750000 1.750000
50% NaN 12.500000 2.500000
75% NaN 13.250000 3.250000
max NaN 14.000000 4.000000