
作者|青原行思(微信安全)
作者丨李琦、元东、苗园莉(清华大学深圳研究生院)
月活用户越高的互联网产品,被黑产盯上的可能性就越大。在微信的安全生态里,正是有网络黑产的层出不穷,变化多端,才有了微信安全的不断进化。本文将带你一窥究竟,微信是怎么做异常检测框架的?
1写在前面
如何在大规模数据下检测异常用户一直是学术界和工业界研究的重点,而在微信安全的实际生态中,一方面,黑产作恶手段多变,为了捕捉黑产多变的恶意模式,若采用有监督的方法模型可能需要频繁更新,维护成本较高;另一方面,通过对恶意帐号进行分析,我们发现恶意用户往往呈现一定的“聚集性”特征,因此这里需要更多地依赖无监督或半监督的手段对恶意用户进行检测。然而,微信每日活跃帐号数基本在亿级别,如何在有限的计算资源下从亿级别帐号中找出可疑帐号给聚类方案的设计带来了不小的挑战,而本文则是为了解决这一问题的一个小小的尝试。
2异常检测框架设计目标及核心思路
设计目标
为了满足在实际场景检测异常用户的要求,在设计初期,我们提出如下设计目标:
主要用于检测恶意帐号可能存在的环境聚集和属性聚集;
方案需要易于融合现有画像信息等其他辅助信息;
方案需要具有较强的可扩展性,可直接用于亿级别用户基数下的异常检测。
核心思路
通常基于聚类的异常用户检测思路是根据用户特征计算节点之间的相似度,并基于节点间相似度构建节点相似度连接图,接着在得到的图上做聚类,以发现恶意群体。然而,简单的分析就会发现上述方案在实际应用场景下并不现实,若要对亿级别用户两两间计算相似度,其时间复杂度和空间消耗基本上是不可接受的。为了解决这一问题,可将整个用户空间划分为若干子空间,子空间内用户相似度较高,而子空间之间用户之间的相似度则较低,这样我们就只需要在每个用户子空间上计算节点相似度,避免相似度较低的节点对之间的相似度计算 (这些边对最终聚类结果影响较低),这样就能大大地降低计算所需的时间和空间开销。
基于这一想法,同时考虑到恶意用户自然形成的环境聚集和属性聚集,我们可以根据环境以及用户属性对整个用户空间进行划分,只在这些子空间上计算节点之间的相似度,并基于得到的用户相似度图挖掘恶意用户群体。此外,直观上来分析,如果两个用户聚集的维度越“可疑”,则该维度对恶意聚集的贡献度应该越高,例如,如果两个用户同在一个“可疑”的 IP 下,相比一个正常的 IP 而言,他们之间存在恶意聚集的可能性更高。基于这一直觉,为了在每个用户子空间内计算用户对之间的相似度,可根据用户聚集维度的可疑度给每个维度赋予不同的权值,使用所有聚集维度的权值的加权和作为用户间的相似度度量。
注:依据上述思路,需要在属性划分后的子空间计算两两用户之间的相似度,然而实际数据中特定属性值下的子空间会非常大,出于计算时间和空间开销的考虑,实际实现上我们会将特别大的 group 按照一定大小 (如 5000) 进行拆分,在拆分后的子空间计算节点相似度。(实际实验结果表明这种近似并不会对结果造成较大影响)
3异常检测框架设计方案
基于上述思路,异常检测方案需要解决如下几个问题:
如何根据用户特征 / 使用怎样的特征将整个用户空间划分为若干子空间?
如何衡量用户特征是否“可疑”?
如何根据构建得到的用户相似度关系图找出异常用户群体?
为了解决以上三个问题,经过多轮的实验和迭代,我们形成了一个较为通用的异常检测方案,具体异常检测方案框架图如图 1 所示:
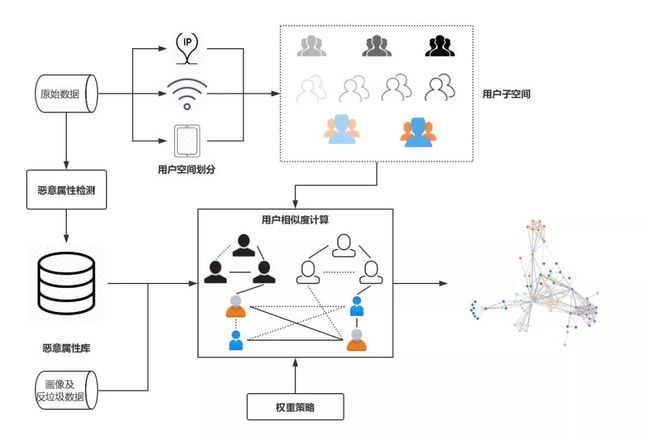
图 1 异常用户检测框架
如图 1 所示,首先,用户空间划分模块根据“划分属性”将整个用户空间划分为若干子空间,后续节点间相似度的计算均在这些子空间内部进行;恶意属性检测模块则根据输入数据自动自适应地识别用户特征中的“可疑”值;用户空间划分和恶意属性检测完成后,在每个用户子空间上,用户相似度计算模块基于恶意属性检测得到的恶意属性库和相应的权重策略计算用户之间两两之间的相似度,对于每个特征以及其对应的不同的可疑程度,权重策略模块会为其分配相应的权重值,用户间边的权重即为节点所有聚集项权重的加权和,为了避免建边可能带来的巨大空间开销,方案仅会保留权值大于一定阈值的边;得到上一步构建得到的用户相似度关系图后,可使用常用的图聚类算法进行聚类,得到可疑的恶意用户群体。
用户空间划分
为了进行节点间相似度的计算,首先需要将整个用户空间划分到不同的子空间中去,那么这些用于划分的属性该如何选取呢?经过一系列的实验和分析,我们将用户特征划分为以下两类:
核心特征:核心特征指黑产帐号若要避免聚集,需要付出较大的成本的特征,主要包括一些环境特征;
支撑特征:支撑特征指黑产帐号若要避免聚集,改变所需成本较小的特征。
不难发现,对于上述核心特征,黑产规避的成本较大,所以在具体的划分属性的选取上,我们使用核心特征对用户空间进行划分,并在划分得到的子空间上计算节点对之间的相似度。在子空间上计算节点之间的相似度时,我们引入支撑特征进行补充,使用核心特征和支撑特征同时计算用户之间的相似度,以提高恶意判断的准确率和覆盖率。
何为“可疑”
可疑属性提取
在确定划分属性后,一个更为重要的问题是如何确定哪些用户属性值是可疑的?这里我们主要对用户脱敏后的登录环境信息进行分析,依赖微信安全中心积累多年的环境画像数据,通过对用户属性值的出现频次、分布等维度进行分析,提取出一些可疑的属性值。
多粒度的可疑属性识别
在进行养号识别的实验过程中,我们发现,单纯依靠若干天登录数据的局部信息进行养号检测往往无法达到较高的覆盖率。为了解决这一问题,在可疑属性提取过程中,我们会融合安全中心现有的环境画像信息以及反垃圾数据等全局信息辅助进行判断,局部信息和全局信息的融合有以下两个好处:
融合局部信息和全局信息,可增大可疑属性判断的置信度和覆盖度,提高算法覆盖率;
增加了用户相似度计算设计上的灵活度,如若特定帐号与已封号帐号有边相连,可通过赋予该边额外的权重来加大对已知恶意用户同环境帐号的打击。
恶意用户识别

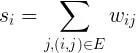

我们将超过一定阈值的用户视为恶意用户,其中,阈值可根据不同阈值得到的算法的准确率和覆盖率选取一个合适的阈值。
另,处于性能和可扩展考虑,我们使用 Connected Components 算法来识别可疑的用户团体,同时,得到恶意团体后我们会对团体进行分析,提取在团体维度存在聚集性的属性值,以增强模型的可解释性。
4从百万到亿——异常检测框架性能优化之路
初步实验时,我们随机抽取了百万左右的用户进行实验,为了将所提方案扩展到全量亿级别用户上,挖掘可疑的用户群体,我们做了如下优化:
Spark 性能优化
在基于 Spark 框架实现上述异常检测框架的过程中,我们也碰到了 Spark 大数据处理中常见的问题 ------ 数据倾斜。分析上述异常检测方案不难发现,方案实现中会涉及大量的 groupByKey,aggregateByKey,reduceByKey 等聚合操作,为了规避聚合操作中数据倾斜对 Spark 性能的影响,实际实现中我们主要引入了以下两个策略:两阶段聚合和三阶段自适应聚合。
两阶段聚合
如图 3 所示,两阶段聚合将聚合操作分为两个阶段:局部聚合和全局聚合。第一次是局部聚合,先给每个 key 都打上一个随机数,比如 10 以内的随机数,此时原先一样的 key 就变成不一样的了,比如 (hello, 1) (hello, 1) (hello, 1) (hello, 1) 就会变成 (1_hello, 1) (1_hello, 1) (2_hello, 1) (2_hello, 1)。接着对打上随机数后的数据,执行 reduceByKey 等聚合操作,进行局部聚合,得到局部聚合结果 (1_hello, 2) (2_hello, 2)。然后将各个 key 的前缀给去掉,得到 (hello,2),(hello,2),再次进行全局聚合操作,即可得到最终结果 (hello, 4)。
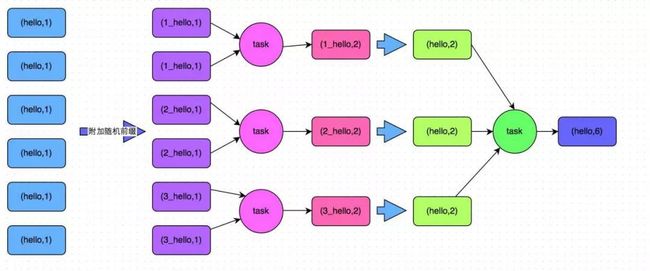
图 3 两阶段聚合
三阶段自适应聚合
用户空间划分阶段我们需要将整个用户空间根据划分属性划分为若干个子区间,实际实验时我们发现在亿级别数据下,使用两阶段聚合,也会出现特定 key 下的数据量特别大的情况,导致 Spark 频繁 GC,程序运行速度极其缓慢,甚至根本无法得到聚合后的结果。为了解决这一问题,注意到通过划分属性进行划分后,仍然会将特别大的 group 按照一定大小进行切割,那么直接在聚合过程中融合这一步骤不就可以了么,这样就能解决特定属性值下数据特别多的情形,也能极大地提升算法运行效率。
三阶段自适应聚合分为以下四个阶段:
随机局部聚合:设定一个较大的数(如 100),参照两阶段聚合第一阶段操作给每个 key 打上一个随机数,对打上随机数后的 key 进行聚合操作;
自适应局部聚合:经过随机局部聚合后,可获取每个随机 key 下的记录条数,通过单个随机 key 下的记录条数,我们可以对原 key 下的数据条数进行估算,并自适应地调整第二次局部聚合时每个原始 key 使用的随机数值;
第二轮随机局部聚合;根据自适应计算得到的随机数继续给每个 key 打上随机数,注意此时不同 key 使用的随机数值可能是不同的,并对打上随机数后的 key 进行第二轮局部聚合;
全局聚合:经过第二轮随机局部聚合后,若特定 key 下记录数超过设定阈值 (如 5000),则保留该结果,不再进行该阶段全局聚合;否则,则将随机 key 还原为原始 key 值,进行最后一阶段的全局聚合。
Faster, Faster, Faster
经过以上调优后,程序运行速度大致提升了 10 倍左右。然而,在实验中我们发现当对亿级别用户进行相似度计算并将边按阈值过滤后,得到的边数仍然在百亿级别,占用内存空间超过 2T。那么我们有没有可能减小这一内存占用呢?答案是肯定的。通过对整个异常用户检测流程进行细致的分析,我们发现我们并不需要对子空间内所有用户对进行相似度计算,通过前期实验我们发现当用户可疑度超过 0.7 时,基本就可以判定该用户是恶意用户。根据用户可疑度计算公式反推,当节点关联边的权重超过 18.2 时,其在最后结果中的权值就会超过 0.7,基于这一想法,我们引入了动态 Dropping 策略。
动态 Dropping 策略
引入 HashMap 保存当前子空间每个节点的累计权重值,初始化为 0.0;按照原始算法依次遍历子空间下的节点对,若节点对两个节点累计权重值均超过阈值(18.2),则跳过该节点对权值计算,否则则根据原始算法计算节点对权重,并累加到 HashMap 中,更新关联节点的累积权重值。引入动态 Dropping 策略后,对于较大的用户子空间,程序会跳过超过 90% 的节点对的相似度计算,极大地减少了计算量;同时,亿级别用户相似度计算生成的边的内存占用从原来超过 2T 降到 50G 左右,也极大地降低了程序所需内存占用。
图划分策略
通过相似度计算得到的用户相似度关系图节点分布是极不均匀的,大部分节点度数较小,少部分节点度数较大,对于这种分布存在严重倾斜的网络图,图划分策略的选择对图算法性能具有极大影响。为了解决这一问题,我们使用 EuroSys 2015 Best Paper 提出的图划分算法 HybridCut 对用户相似度关系图进行划分。
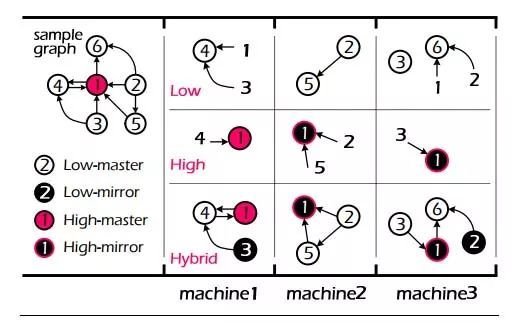
图 4 HybridCut 图划分算法
如图 4 所示,HybridCut 图划分算法根据节点度数的不同选取差异化的处理策略,对于度数较低的节点,如节点 2,3,4,5,6,为了保证局部性,算法会将其集中放置在一起,而对于度数较高的节点,如 1,为了充分利用图计算框架并行计算的能力,算法会将其对应的边摊放到各个机器上。通过按节点度数对节点进行差异化的处理,HybridCut 算法在局部性和算法并行性上达到了较好的均衡。以上仅对 HybridCut 算法基本思路进行粗略的介绍,更多算法细节请参阅论文 PowerLyra: Differentiated Graph Computation and Partitioning on Skewed Graphs。
5总结和讨论
优点与不足
优点
上述异常用户检测框架具有如下优点:
能够较好地检测恶意用户可能存在的环境聚集和属性聚集,且具有较高的准确率和覆盖率;
能够自然地融合画像信息以及反垃圾信息,通过融合不同粒度的信息,可提高算法的覆盖率,同时也给算法提供了更大的设计空间,可以按需选择使用的特征或信息;
良好的扩展性,可直接扩展到亿级别用户进行恶意用户检测,且算法具有较高的运行效率。
不足
无法对非环境和属性聚集的恶意用户进行检测 (当然,这也不在方案的设计目标里),无法处理恶意用户使用外挂等手段绕过环境和属性聚集检测的情况;
上述方案权重策略部分需要人工指定权重,这无疑增加了人工调参的工作量,若黑产恶意模式或使用特征发生较大的变更,则可能需要对权重重新进行调整,维护成本较高。
Next...
探索自动化的权重生成策略,以应对可能的特征或黑产模式变更;
是否可以根据聚类过程中的信息生成规则,用于实时恶意打击;
上述方案比较适合用来检测恶意用户可能存在的环境聚集和属性聚集,对于非环境和属性聚集的恶意类型则显得无能为力了 (一种可能的方案是将连续属性离散化,不过这样太不优雅了!),因此后续我们会尝试从行为维度对用户行为进行分析,并构建相应的打击模型。
6参考文献
Chen R, Shi J, Chen Y, et al. PowerLyra: differentiated graph computation and partitioning on skewed graphs[C]// Tenth European Conference on Computer Systems. ACM, 2015:1.
Spark 性能优化指南——高级篇 https://tech.meituan.com/spark-tuning-pro.html
作者介绍
青原行思,腾讯微信安全中心员工,主要研究机器学习方法在安全业务中的应用。