1、创建
1.1、打开Anaconda Navigator中的NoteBook-->new-->python3
1.2、快捷键Alt+enter运行并创建下一行
1.3、保存到本地:file-->download as-->html或其他格式
2、实例(每次输出表示按了alt+enter)
2.1、入门
2.1.1、导入库
import numpy as np
#检查版本
np.__version__
#如果出现版本号说明配置没问题
#输出:'1.15.1'
2.1.2、创建numpy
nparr=np.array([1,2,3,4])
nparr
#输出:array([1, 2, 3, 4])
type(nparr)
#输出:numpy.ndarray
np.array([i for i in range(10)])
#输出:array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
#类似range操作的函数
np.arange(10)
#输出:array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
#创建2维
x=np.arange(1,16)
x
#输出:array([ 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15])
X=x.reshape(3, 5)
X
#输出:array([[ 1, 2, 3, 4, 5],
[ 6, 7, 8, 9, 10],
[11, 12, 13, 14, 15]])
#维度
x.ndim
#输出:1
X.ndim
#输出:2
x.shape
#输出:(15,)
X.shape
#输出:(3,5)
2.1.3、ndarray的访问
x
#输出:array([ 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15])
x[2]
#输出:3
X[1,2]
#输出:8
#切片
x[:6]
#输出:array([1, 2, 3, 4, 5, 6])
X[:2,1:3]
#输出:array([[2, 3],
[7, 8]])
np.sum(x)
#输出:120
np.sin(X)
#输出:array([[ 0.84147098, 0.90929743, 0.14112001, -0.7568025 , -0.95892427],
[-0.2794155 , 0.6569866 , 0.98935825, 0.41211849, -0.54402111],
[-0.99999021, -0.53657292, 0.42016704, 0.99060736, 0.65028784]])
2.1.4、布尔索引
name=np.array(['zhangsan','lisi','wangmazi','haha'])
name
#输出:array(['zhangsan', 'lisi', 'wangmazi', 'haha'], dtype='2.1.5、argsort
x
#输出:array([ 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15])
#打乱顺序
np.random.shuffle(x)
x
#输出:array([ 2, 14, 3, 8, 5, 11, 6, 7, 4, 10, 9, 13, 1, 15, 12])
#返回排序前索引
np.argsort(x)
#输出:array([12, 0, 2, 8, 4, 6, 7, 3, 10, 9, 5, 14, 11, 1, 13],
dtype=int64)
2.2、鸢尾花数据可视化
2.2.1、导入库
import numpy as np
from matplotlib import pyplot as plt
# 加载数据集
# 1. 读取csv
# 2. 调用sklearn提供的数据集
from sklearn import datasets
2.2.2、加载鸢尾花数据
# 加载鸢尾花数据集
iris = datasets.load_iris()
iris.keys()
#输出:dict_keys(['data', 'target', 'target_names', 'DESCR', 'feature_names'])
iris.target
#输出:array([0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2])
iris.target_names
#输出:array(['setosa', 'versicolor', 'virginica'], dtype='2.2.3、绘制萼片维度的鸢尾花
# 提取数据
X = iris.data[:,:2]
X.shape
#输出:(150, 2)
y = iris.target
plt.scatter(X[y==0,0], X[y==0,1], color='r', marker ='+') # setosa
plt.scatter(X[y==1,0], X[y==1,1], color='b', marker ='o') # versicolor
plt.scatter(X[y==2,0], X[y==2,1], color='g', marker ='x') # virginica
plt.show()
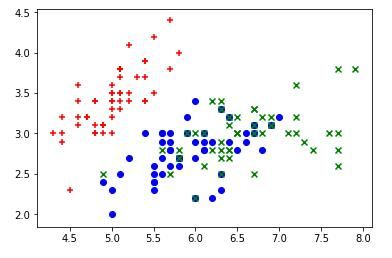
鸢尾花1.jpg
2.2.4、花瓣维度
X = iris.data[:,2:]
plt.scatter(X[y==0,0], X[y==0,1], color='r', marker ='+') # setosa
plt.scatter(X[y==1,0], X[y==1,1], color='b', marker ='o') # versicolor
plt.scatter(X[y==2,0], X[y==2,1], color='g', marker ='x') # virginica
plt.show()
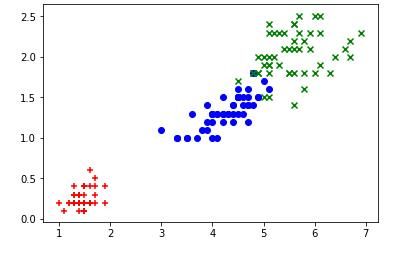
鸢尾花2.jpg
2.3、机器学习
2.3.1、机器学习的分类
根据学习的任务模式 (训练数据是否有标签),机器学习可分为四大类:
*有监督学习 (有标签)
*无监督学习 (无标签)
*半监督学习 (有部分标签)
*增强学习 (有评级标签)
监督学习
- 分类
- 回归
2.3.2、KNN
# 自己实现knn算法过程
import numpy as np
from matplotlib import pyplot as plt
raw_data_X = [[3.393533211, 2.331273381],
[3.110073483, 1.781539638],
[1.343808831, 3.368360954],
[3.582294042, 4.679179110],
[2.280362439, 2.866990263],
[7.423436942, 4.696522875],
[5.745051997, 3.533989803],
[9.172168622, 2.511101045],
[7.792783481, 3.424088941],
[7.939820817, 0.791637231]
]
raw_data_y = [0, 0, 0, 0, 0, 1, 1, 1, 1, 1]
# 转化成ndarray类型
X_train = np.array(raw_data_X)
X_train
#输出:array([[3.39353321, 2.33127338],
[3.11007348, 1.78153964],
[1.34380883, 3.36836095],
[3.58229404, 4.67917911],
[2.28036244, 2.86699026],
[7.42343694, 4.69652288],
[5.745052 , 3.5339898 ],
[9.17216862, 2.51110105],
[7.79278348, 3.42408894],
[7.93982082, 0.79163723]])
y_train = np.array(raw_data_y)
y_train
#输出:array([0, 0, 0, 0, 0, 1, 1, 1, 1, 1])
2.3.3、可视化
plt.scatter(X_train[y_train==0,0],X_train[y_train==0, 1],color='g') # 0
plt.scatter(X_train[y_train==1,0],X_train[y_train==1, 1],color='r') # 1
plt.show()
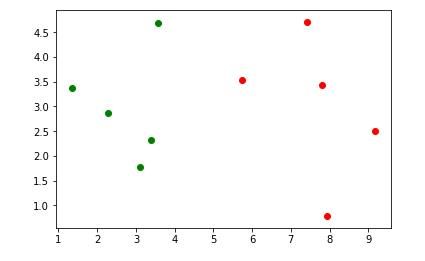
可视化.jpg
假设新来一个样本数据,我们判断他是恶性肿瘤还是良性肿瘤
# 假如新来的一个数据
x = np.array([8.093607318, 3.365731514])
#可视化一下x
plt.scatter(X_train[y_train==0,0],X_train[y_train==0, 1],color='g') # 0
plt.scatter(X_train[y_train==1,0],X_train[y_train==1, 1],color='r') # 1
plt.scatter(x[0],x[1],color='b')
plt.show()
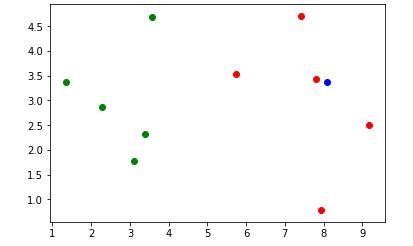
可视化2.jpg
#计算每一个点距离x距离
distances = []
from math import sqrt
for x_train in X_train:
d = sqrt(np.sum((x_train-x)**2))
distances.append(d)
distances
#输出:
[4.812566907609877,
5.229270827235305,
6.749798999160064,
4.6986266144110695,
5.83460014556857,
1.4900114024329525,
2.354574897431513,
1.3761132675144652,
0.3064319992975,
2.5786840957478887]
# 指定k的值
K = 6
nearest = np.argsort(distances)
nearest
#输出:array([8, 7, 5, 6, 9, 3, 0, 1, 4, 2], dtype=int64)
[i for i in nearest[:6]]
#输出:[8, 7, 5, 6, 9, 3]
top_k = [y_train[i] for i in nearest[:6]]
from collections import Counter
votes = Counter(top_k)
votes.most_common(1)
#输出:[(1, 5)]
# 预测结果 x 属于 1 类别 恶性肿瘤
predict = votes.most_common(1)[0][0]
predict
#输出:1