OpenGL学习脚印:创建更多的实例(instancing object)
写在前面
前面我们学习了模型加载的相关内容,并成功加载了模型,令人十分兴奋。那时候加载的是少量的模型,如果需要加载多个模型,就需要考虑到效率问题了,例如下图所示的是加载了400多个纳米战斗服机器人的效果图:

渲染一个模型更多的实例,需要使用到实例化技术,就是本节要介绍的instancing object方法。本节示例代码均可以从我的github下载。
本节内容整理自:
www.learnopengl.com
渲染多个实例的方法
要渲染多个实例,基本的想法就是,在主程序中使用循环,在不同位置绘制多个物体,伪代码如下所示:
for(GLuint i = 0; i < instanceCount; ++i)
{
// 分别设置每个物体的模型变换矩阵 model matrix
// glDrawArrays(GL_TRIANGLES, ...)
}这种方式存在的缺点是,当要渲染多个模型的实例时,需要多次调用glDraw这类命令,而这类命令从CPU–>GPU是需要花费时间的,因为使用绘制命令时OpenGL需要做一些工作,例如通知GPU从哪个buffer里面读取数据。虽然GPU绘图很快,但是CPU–>GPU的命令发送,当量比较大时还是会成为瓶颈。
因此OpenGL提供了glDrawArrays和glDrawElements的绘制实例版本,分别对应为glDrawArraysInstanced和glDrawElementsInstanced 。实例版本的函数,多了一个参数,就是最后一个指定渲染多少个实例的参数。
下面以一个简单的绘制多个矩形的例子作为引例,开始熟悉绘制多个实例。
使用多个uniform传递实例数据
假设我们要绘制100个矩形,在顶点着色器中,我们使用一个uniform数组:
#version 330 core
layout(location = 0) in vec2 position;
layout(location = 1) in vec3 color;
uniform vec2 offsets[100]; // 每个实例的位移量
out vec3 fColor;
void main()
{
vec2 offset = offsets[gl_InstanceID]; // 通过gl_InstanceID索引每个实例的位移量
gl_Position = vec4(position + offset, 0.5f, 1.0f);
fColor = color;
}通过gl_InstanceID来索引每个实例,而在主程序中,我们通过循环设置这个uniform数组的内容:
//准备多个实例的位移量数据
glm::vec2 translations[100];
int index = 0;
GLfloat offset = 0.1f;
for (GLint y = -10; y < 10; y += 2)
{
for (GLint x = -10; x < 10; x += 2)
{
glm::vec2 translation;
translation.x = (GLfloat)x / 10.0f + offset;
translation.y = (GLfloat)y / 10.0f + offset;
translations[index++] = translation;
}
}
// 接着 向shader传递这100个translate uniform最后通过实例版本函数绘制多个矩形:
shader.use();
glBindVertexArray(quadVAOId);
glDrawArraysInstanced(GL_TRIANGLES, 0, 6, 100); // 使用instance方法绘制得到的效果如下图所示:

我们看到使用这个方法,确实渲染了多个矩形,但存在的问题时GLSL中支持的uniform受到限制,可以使用 GL_MAX_VERTEX_UNIFORM_COMPONENTS等枚举通过glGetIntegerv函数查询。一般情况下uniforms数组也够用,但是对于需要实例比较多的情形,这种方案变得不合适。
使用instance array 传递实例数据
同顶点属性中位置、纹理坐标等其他属性一样,我们可以通过VBO来充当一个instance array,传递每个实例的数据。一般地顶点属性,当顶点着色器执行时需要获取每个顶点的这些属性信息,而充当instance array的顶点属性需要每个实例更新一次。这是instance array与普通顶点属性之间的差别。
创建一个instance array的包括两个步骤,第一步同普通顶点属性一样,创建VBO,填充数据;第二步是通知OpenGL如何解析VBO中的数据。在顶点着色器中,我们定义一个layout=2表示这个instance array,如下:
#version 330 core
layout(location = 0) in vec2 position;
layout(location = 1) in vec3 color;
layout(location = 2) in vec2 offset; // 通过VBO传递位移量
// uniform vec2 offsets[100]; // 不再使用
out vec3 fColor;
void main()
{
gl_Position = vec4(position + offset, 0.5f, 1.0f);
fColor = color;
}在主程序中,创建VBO,填充translations数组的数据,如下:
GLuint instanceVBOId;
glGenBuffers(1, &instanceVBOId);
glBindVertexArray(quadVAOId);
glBindBuffer(GL_ARRAY_BUFFER, instanceVBOId);
glBufferData(GL_ARRAY_BUFFER, sizeof(glm::vec2) * 100, &translations[0], GL_STATIC_DRAW);并通知OpenGL解析这个VBO数据的方式:
glVertexAttribPointer(2, 2, GL_FLOAT, GL_FALSE, 0, NULL);
glEnableVertexAttribArray(2);
glVertexAttribDivisor(2, 1); // 注意这里 指定1表示每个实例更新一次数据
glBindBuffer(GL_ARRAY_BUFFER, 0);
glBindVertexArray(0);这里关键是使用glVertexAttribDivisor来指定数据更新方式,第一个参数2表示layout索引,第二个参数指定顶点属性的更新方式,默认是0表示着色器每次执行时更新属性数据,填写1表示每个实例更新一次属性数据,填写2则表示每2个实例更新一次属性数据,依次类推。上面填写1则通知了OpenGL这是一个instance array,每个实例更新一次数据。
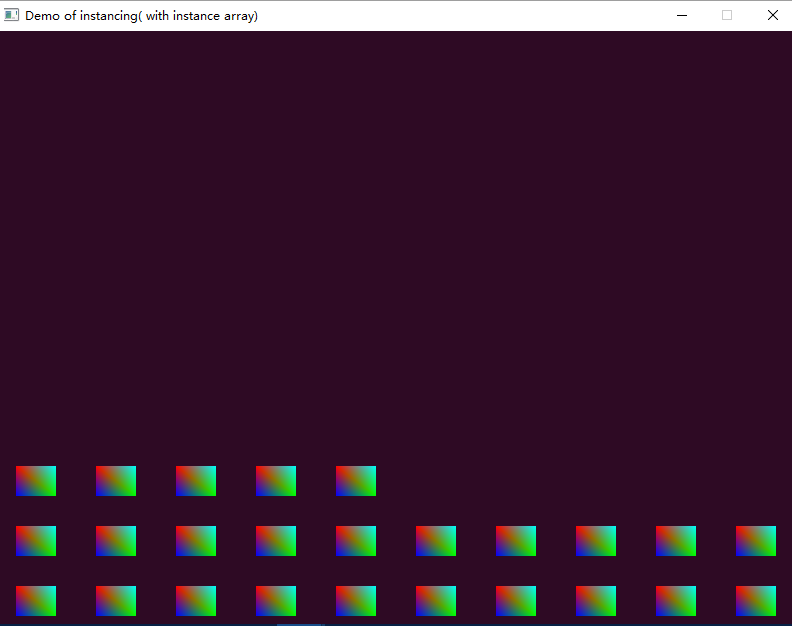
运行上述代码,我们得到的效果与上面相同,当设置:
glVertexAttribDivisor(2, 4);每4个实例更新一次数据时,我们将会得到100 / 4 =25个矩形,因为每4个矩形的模型变换矩阵相同,因此放在了同一个位置,重合了,效果如下图所示:
上面是一个简单的引例,下面我们通过两个案例,深入对比下instance array方式的性能差别。
绘制行星带
通过加载一个行星模型和石头模型来模拟一个行星带,这里我们通过下面的函数,来构造一个石头模型随机环绕行星的模型变换矩阵:
// 这里通过随机方式 构造多个石头模型的模型变换矩阵
void prepareInstanceMatrices(std::vector上面随机方式构造变换矩阵的计算细节,可以不用深究,我们需要重点理解的是对比使用普通方式和使用instance array的效率问题。
不使用instance array的绘制方式
构造了多个实例的矩阵后,我们使用普通的绘制方式如下:
// 这里填写场景绘制代码
shader.use();
glUniformMatrix4fv(glGetUniformLocation(shader.programId, "projection"),
1, GL_FALSE, glm::value_ptr(projection));
glUniformMatrix4fv(glGetUniformLocation(shader.programId, "view"),
1, GL_FALSE, glm::value_ptr(view));
glm::mat4 model;
model = glm::translate(model, glm::vec3(0.0f, -3.0f, 0.0f));
model = glm::scale(model, glm::vec3(4.0f, 4.0f, 4.0f));
glUniformMatrix4fv(glGetUniformLocation(shader.programId, "model"),
1, GL_FALSE, glm::value_ptr(model));
planet.draw(shader); // 先绘制行星
// 绘制多个小行星实例
for (std::vector使用instance array的绘制方式
同上面使用的instance array有些不同,这里使用的instance array是mat4类型的矩阵,因为顶点属性允许的最大数据为vec4,因此我们需要使用4 * vec4表示这个mat4类型的instance array。在顶点着色器中定义这个mat4 instance array如下:
#version 330 core
layout(location = 0) in vec3 position;
layout(location = 1) in vec2 textCoord;
layout(location = 2) in vec3 normal;
layout(location = 3) in mat4 instanceMatrix; // 顶点属性最多vec4 输入 实际上有4个vec4输入构造这个mat4
uniform mat4 projection;
uniform mat4 view;
out vec2 TextCoord;
void main()
{
gl_Position = projection * view * instanceMatrix * vec4(position, 1.0);
TextCoord = textCoord;
}同时我们还需要在主程序中向着色器传递这个instance array。之前设计的mesh.h类,需要少量修改,允许获取mesh相关信息,修改后的mesh.h类。我们这里不去大量修改mesh类,采用的策略是为每个mesh使用这个instance array,实现如下:
void prepareInstanceMatrices(std::vector这个地方稍微有点绕,关键一点就是每个mesh都包含了这个modelMatrices数据,因此每个mesh绘制三角形时,都会在每个实例上更新modelMatrix,从而整体上绘制出的模型也用了这些模型变换矩阵。
上面绘制的效果如下图所示:
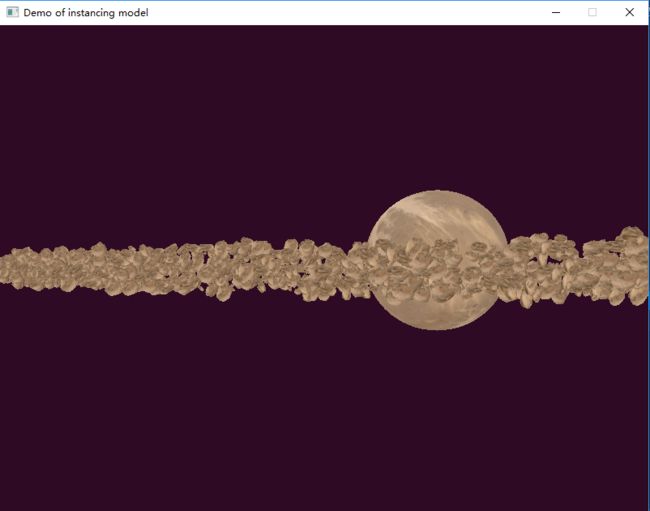
使用上面两种方法渲染包含1000, 10000, 100000个石头模型的行星带,在NVIDIA Graphics 上粗略的一个对比数据(这不是基准测试结果),如下表1所示:
| 实例数目 | 普通绘制 | instancing方法 |
|---|---|---|
| 1000 | 0.05s | 0.01s |
| 10,000 | 0.45s | 0.12s |
| 100,000 | 4.0s | 1.25s |
这个计时是通过glfwGetTime来实现的,更科学的对比可能是使用帧率,暂时不细究这个问题了。通过对比,可以看到使用instance array渲染多个实例速度比普通方式快了4到5倍。
渲染更多的纳米战斗服机器人
再给出一个使用instance方法,绘制多个机器人的方法,我们指定了要绘制的机器人数量,然后平铺在钢铁纹理上。绘制9个机器人的效果如下图所示:

121个机器人效果如下图所示:
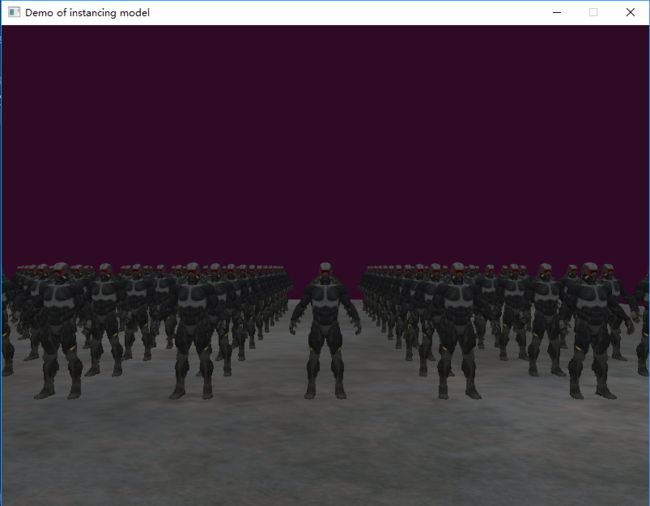
渲染的441个机器人效果如下图所示:

你可以根据需要将机器人的摆放成其他形式,例如同心圆、心形图案等,可以自己玩会儿了。
最后的说明
本节学习了instance实例的方法,并对比了普通渲染方式和它在性能上的差别。实际应用中,instance实例一般应用在草地、树木等模型上面,来构成游戏场景中很好的布景。