前言
这是 RNN 第二讲,在这篇博客中,我们将会在第一讲基础之上,学习使用 Tensorflow 的 scan 和 dynamic_rnn 模型,多种 RNN Cell,和多层 RNN,并且有 dropout 和 layer normalization
Task
- 我们将会构建一个字符级语言模型来生成字符序列
- 为什么以字符级语言模型为例子?
- 此模型比上一讲模型难;此模型需要处理长序列并学习长时间的依赖关系;这对于我们了解RNN很重要
- 我们将会使用 tiny-shakespeare 文本作为数据集(也可以使用任何纯文本),选择文件中的所有字符作为词汇,小写字符和大写字符看做不同的字符。
# Imports
import numpy as np
import tensorflow as tf
import matplotlib.pyplot as plt
import time
import os
import urllib.request
'''
Load and process data
'''
file_url = 'https://raw.githubusercontent.com/jcjohnson/torch-rnn/master/data/tiny-shakespeare.txt'
file_name = 'tinyshakespeare.txt'
# 如果 file_name 存在,返回True;如果 file_name 不存在,返回False。
if not os.path.exists(file_name):
urllib.request.urlretrieve(file_url, file_name)
with open(file_name,'r') as f:
raw_data = f.read()
print("Data length:", len(raw_data)) # 1115394 为文本中的字符个数
# 文本中的所有字符(注意,此处为set,无顺序,也就是说每次运行得到的顺序是不一样的,最终对于结果基本没影响)
vocab = set(raw_data)
vocab_size = len(vocab) # 65,即文本中共计字符为65个
idx_to_vocab = dict(enumerate(vocab)) # 输出见下图
vocab_to_idx = dict(zip(idx_to_vocab.values(), idx_to_vocab.keys())) # 输出见下图
# 将文本中的字符转化为数字存储,毕竟计算机只认数字,计算机可不认识 a,b,c,
data = [vocab_to_idx[c] for c in raw_data]
# print(data[0:5])
# [14 34 31 63 60] 文本前5个字符为First,以单个字符为索引去vocab_to_idx找到First对应的value,
# 依次为 F:14, i:34, r:31, s:63, t:60,这仅仅是前5个,而文本中一共有1115394个字符,
# 我们要将每个字符都转化为数字,然后以list形式存储到data中
# 删除文本(个人估计为数据量大,占内存)
del raw_data
- vocab

- idx_to_vocab

- vocab_to_idx

state_size = 100
num_steps = 200
batch_size = 32
num_classes = vocab_size
learning_rate = 1e-4
# 处理数据
def gen_data(raw_data, batch_size, num_steps):
raw_data = np.array(raw_data, dtype=np.int32)
data_len = len(raw_data) # 1115394
batch_len = data_len // batch_size # 34856 = 1115394 // 32
data = np.zeros([batch_size, batch_len], dtype=np.int32) # (32, 34856)
for i in range(batch_size):
data[i] = raw_data[batch_len * i : batch_len * (i + 1)]
epoch_size = (batch_len - 1) // num_steps # 174 = (34856 - 1) // 200
if epoch_size == 0:
raise ValueError("epoch_size == 0, decrease batch_size or num_steps")
for i in range(epoch_size):
x = data[ :, i * num_steps : (i+1) * num_steps ] # (32, 200)
y = data[ :, i * num_steps+1 : (i+1) * num_steps + 1 ] # (32, 200)
yield (x, y)
def gen_epochs(n, num_steps, batch_size):
for i in range(n):
# 返回数据 X,Y 的shape = [batch_size, num_steps]
yield gen_data(data, batch_size, num_steps)
# 重新构建图
def reset_graph():
if 'sess' in globals() and sess:
sess.close()
tf.reset_default_graph()
def train_network(g, num_epochs, num_steps = num_steps, batch_size = batch_size, verbose = True, save = False):
tf.set_random_seed(2345)
init = tf.global_variables_initializer()
with tf.Session() as sess:
sess.run(init)
training_losses = []
for idx, epoch in enumerate(gen_epochs(num_epochs, num_steps, batch_size)):
training_loss = 0
steps = 0
training_state = None
for X, Y in epoch:
steps += 1
feed_dict = {g['x']: X, g['y']: Y}
if training_state is not None:
feed_dict[g['init_state']] = training_state
training_loss_, training_state_, _= sess.run([g['total_loss'], g['final_state'],
g['train_step']], feed_dict)
training_loss += training_loss_
if verbose:
print('Average training loss for Epoch', idx, ':', training_loss / steps)
training_losses.append(training_loss / steps)
if isinstance(save, str):
g['saver'].save(sess,save)
return training_losses
使用 tf.scan 和 tf.nn.dynamic_rnn 来加快速度
对于上一篇文章来说,我们time_steps=7,也就是说依赖为7步。然而,对于字符序列来说,我们的依赖并不是很多,让我们来捕获更长的依赖关系,所以让我们来看一下我们构建一个time_steps = 200时间跨度时会发生什么
基本的单层 RNN
def build_basic_rnn_graph_with_list(state_size = state_size, # 100
num_classes = num_classes, # 65
batch_size = batch_size, # 32
num_steps = num_steps, # 200
learning_rate = learning_rate): # 1e-4
reset_graph()
x = tf.placeholder(tf.int32, [batch_size, num_steps], name = 'input_placeholder') # (32, 200)
y = tf.placeholder(tf.int32, [batch_size, num_steps], name = 'labels_placeholder') # (32, 200)
init_state = tf.zeros([batch_size, state_size]) # (32, 100)
x_one_hot = tf.one_hot(x, num_classes) # (batch_size, num_steps, num_classes) = [32, 200, 65]
rnn_inputs = tf.unstack(x_one_hot, axis = 1) # # 返回一个list,长度为 200, 每一个元素都是 shape = (32, 65)
cell = tf.contrib.rnn.BasicRNNCell(state_size)
rnn_outputs, final_state = tf.contrib.rnn.static_rnn(cell, rnn_inputs, initial_state = init_state)
with tf.variable_scope('softmax'):
W = tf.get_variable('W', [state_size, num_classes]) # (100, 65)
b = tf.get_variable('b', [num_classes], initializer = tf.constant_initializer(0.0))
logits = [tf.matmul(rnn_output, W) + b for rnn_output in rnn_outputs] # (32, 100)x(100, 65) = (32, 65)
predictions = [tf.nn.softmax(logit) for logit in logits]
# 返回list, 长度为 200, 每一个都是array,shape = (32,)
y_as_list = tf.unstack(y, num = num_steps, axis = 1)
losses = [tf.nn.sparse_softmax_cross_entropy_with_logits(labels = label, logits = logit) for \
logit, label in zip(predictions, y_as_list)]
total_loss = tf.reduce_mean(losses)
train_step = tf.train.AdamOptimizer(learning_rate).minimize(total_loss)
return dict(
x = x,
y = y,
init_state = init_state,
final_state = final_state,
total_loss = total_loss,
train_step = train_step
)
# 测试一下
t = time.time()
g = build_basic_rnn_graph_with_list()
print('构建图耗时: ',time.time() - t)
t = time.time()
train_network(g, 3)
print("训练耗时: ", time.time() - t)
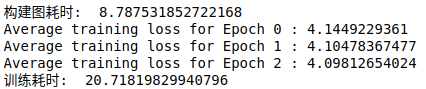
- 可以看到花费 8.78 秒去构建基本的单层
RNN模型,这很糟糕,那么当我们使用 3 层 LSTM 的时候,情况会如何呢? - 下面,我们将会移除 BsaicRNNCell ,替换为 3 层 LSTMCell ,我们将会在下面讨论它的细节!
3 层 BasicLSTMCell / LSTMCell
def lstm_cell(state_size = 100):
# state_is_tuple:如果为True,接受并返回状态是的2元组 c_state 和 m_state
# 测试 BasicLSTMCell
lstm = tf.contrib.rnn.BasicLSTMCell(state_size, state_is_tuple=True)
# 测试 LSTMCell
# lstm = tf.contrib.rnn.LSTMCell(state_size, state_is_tuple=True)
return lstm
def build_multilayer_lstm_graph_with_list(state_size = 100,
num_classes = vocab_size, # 65
batch_size = 32,
num_steps = 200,
num_layers = 3,
learning_rate = 1e-4):
reset_graph()
x = tf.placeholder(tf.int32, [batch_size, num_steps], name = 'input_placeholder') # (32, 200)
y = tf.placeholder(tf.int32, [batch_size, num_steps], name = 'labels_placeholder') # (32, 200)
x_one_hot = tf.one_hot(x, num_classes) # (32, 200, 65)
rnn_inputs = tf.unstack(x_one_hot, axis = 1) # # 返回一个list,长度为 200, 每一个元素都是 shape = (32, 65)
cell = tf.contrib.rnn.MultiRNNCell([lstm_cell() for _ in range(num_layers)], state_is_tuple=True)
init_state = cell.zero_state(batch_size, tf.float32)
rnn_outputs, final_state = tf.contrib.rnn.static_rnn(cell, rnn_inputs, initial_state=init_state)
with tf.variable_scope('softmax'):
W = tf.get_variable('W', [state_size, num_classes]) # (100, 65)
b = tf.get_variable('b', [num_classes], initializer = tf.constant_initializer(0.0))
logits = [tf.matmul(rnn_output, W) + b for rnn_output in rnn_outputs] # (32, 100)x(100, 65) = (32, 65)
predictions = [tf.nn.softmax(logit) for logit in logits]
# 返回list, 长度为 200, 每一个都是array,shape = (32,)
y_as_list = tf.unstack(y, num = num_steps, axis = 1)
losses = [tf.nn.sparse_softmax_cross_entropy_with_logits(labels = label, logits = logit) for \
logit, label in zip(predictions, y_as_list)]
total_loss = tf.reduce_mean(losses)
train_step = tf.train.AdamOptimizer(learning_rate).minimize(total_loss)
return dict(
x = x,
y = y,
init_state = init_state,
final_state = final_state,
total_loss = total_loss,
train_step = train_step
)
- 注意,在应用
MultiRNNCell时候,会出现bug,参考 链接1 链接2
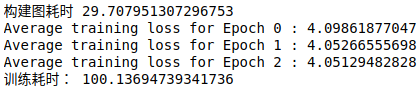
# 测试 BasicLSTMCell
start_time = time.time()
g = build_multilayer_lstm_graph_with_list()
print("构建图耗时", time.time()-start_time)
start_time = time.time()
train_network(g, 3)
print("训练耗时:", time.time()-start_time)
# 测试 LSTMCell
start_time = time.time()
g = build_multilayer_lstm_graph_with_list()
print("构建图耗时", time.time()-start_time)
start_time = time.time()
train_network(g, 3)
print("训练耗时:", time.time()-start_time)
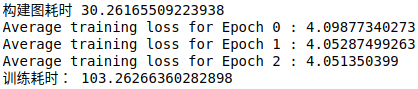
- 哇,两种 LSTM cell 竟然建图都有 30 秒
- 对于训练来说,图仅仅建立一次,这不是个大问题;然而,如果我们在测试的时候多次建立图,那对于我们来说就是一个大问题了
- 为了避免这么长的编译时间,TensorFlow 允许我们在运行时创建图,以下是使用 dynamic_rnn 的实例:
tf.nn.dynamic_rnn
def build_multilayer_lstm_graph_with_dynamic_rnn(
state_size = 100,
num_classes = vocab_size,
batch_size = 32,
num_steps = 200,
num_layers = 3,
learning_rate = 1e-4):
reset_graph()
x = tf.placeholder(tf.int32, [batch_size, num_steps], name='input_placeholder')
y = tf.placeholder(tf.int32, [batch_size, num_steps], name='labels_placeholder')
embeddings = tf.get_variable('embedding_matrix', [num_classes, state_size])
'''
这里的输入是三维的[batch_size, num_steps, state_size]
embedding_lookup(params, ids)函数是在params中查找ids的表示, 和在matrix中用array索引类似,
这里是在二维embeddings中找二维的ids, ids每一行中的一个数对应embeddings中的一行,
所以最后是[batch_size, num_steps, state_size]
'''
# Note that our inputs are no longer a list, but a tensor of dims batch_size x num_steps x state_size
rnn_inputs = tf.nn.embedding_lookup(embeddings, x)
cell = tf.nn.rnn_cell.LSTMCell(state_size, state_is_tuple=True)
cell = tf.nn.rnn_cell.MultiRNNCell([cell] * num_layers, state_is_tuple=True)
init_state = cell.zero_state(batch_size, tf.float32)
rnn_outputs, final_state = tf.nn.dynamic_rnn(cell, rnn_inputs, initial_state=init_state)
with tf.variable_scope('softmax'):
W = tf.get_variable('W', [state_size, num_classes])
b = tf.get_variable('b', [num_classes], initializer=tf.constant_initializer(0.0))
#reshape rnn_outputs and y so we can get the logits in a single matmul
rnn_outputs = tf.reshape(rnn_outputs, [-1, state_size])
y_reshaped = tf.reshape(y, [-1])
logits = tf.matmul(rnn_outputs, W) + b
total_loss = tf.reduce_mean(tf.nn.sparse_softmax_cross_entropy_with_logits(logits=logits, labels=y_reshaped))
train_step = tf.train.AdamOptimizer(learning_rate).minimize(total_loss)
return dict(
x = x,
y = y,
init_state = init_state,
final_state = final_state,
total_loss = total_loss,
train_step = train_step
)
# 测试一下
start_time = time.time()
g = build_multilayer_lstm_graph_with_dynamic_rnn()
print("构建图耗时", time.time()-start_time)
start_time = time.time()
train_network(g, 3)
print("训练耗时:", time.time()-start_time)
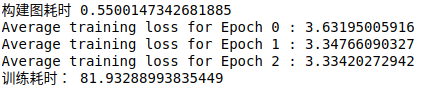
- 可以看到,使用
dynamic_rnn之后,构建图耗时大大缩短,由使用 (三层)LSTMCell的 30 秒到现在的 0.55 秒,训练耗时由 103 秒缩短至 81.93 秒
tf.scan
- 要理解 dynamic_rnn 并不是一件容易的事情,通过使用 tf.scan 可以获得相近的结果;虽然 tf.scan 比 dynamic_rnn 慢,但是 scan 更加容易理解和编写。
- tf.scan 是一个函数。一般来说,函数形式为 ( f : (xt, yt-1) -> yt ), 一个序列 ([x0,x1,..., xn]) 和一个初始值 (y-1) 根据函数 yt = f(xt, yt-1) 能返回一个序列 ([y0,y1,..., yn]) , 在 Tensorflow 中,scan 将张量的第一维当做序列处理,因此,如果给出张量 shape = [n,m,o]作为序列, scan 将会解压为 n 个张量序列,每一个张量序列 shape = [m,o]。
- 下面,我们将会使用 3 层
LSTMCell,以便与上面的dynamic_rnn进行比较。因为LSTM存储state在一个2 维元组中(每一个都为state),并且我们使用3 层的网络。scan 实现同样的功能,正如final_state,这是一个 3 维元组(因为 3 层),每一维中有 2 维(对应 LSTM 中的2个state,每个state的shape = [num_steps,batch_size,state_size]。然而,我们仅仅需要最后的state,所以下面代码中有,我们要从final_state中获取final_state - 还需要注意的是,
scan的输出rnn_outputs的shape = [num_steps,batch_size,state_size];然而,dynamic_rnn的输出rnn_outputs的shape = [batch_size,num_steps,state_size](前两个维度颠倒了),dynamic_rnn 可以轻易的使用time_major更改维度; scan 需要使用transpose更改维度
'''
使用 scan 实现 dynamic_rnn 的效果
'''
def build_multilayer_lstm_graph_with_scan(
state_size = 100,
num_classes = vocab_size, # 65
batch_size = 32,
num_steps = 200,
num_layers = 3,
learning_rate = 1e-4):
reset_graph()
x = tf.placeholder(tf.int32, [batch_size, num_steps], name='input_placeholder') # (32, 200)
y = tf.placeholder(tf.int32, [batch_size, num_steps], name='labels_placeholder') # (32, 200)
embeddings = tf.get_variable('embedding_matrix', [num_classes, state_size])
'''这里的输入是三维的[batch_size, num_steps, state_size]'''
rnn_inputs = tf.nn.embedding_lookup(embeddings, x)
cell = tf.nn.rnn_cell.LSTMCell(state_size, state_is_tuple=True)
cell = tf.nn.rnn_cell.MultiRNNCell([cell] * num_layers, state_is_tuple=True)
init_state = cell.zero_state(batch_size, tf.float32)
'''
使用tf.scan方式
- tf.transpose(rnn_inputs, [1,0,2]) 是将rnn_inputs的第一个和第二个维度调换,即[num_steps,batch_size, state_size],
在dynamic_rnn函数有个time_major参数,就是指定num_steps是否在第一个维度上,默认是false的,即不在第一维
- tf.scan会将elems按照第一维拆开,所以一次就是一个step的数据(和我们static_rnn的例子类似)
- a的结构和initializer的结构一致,所以a[1]就是对应的state,cell需要传入x和state计算
- 每次迭代cell返回的是一个rnn_output(batch_size,state_size)和对应的state,
num_steps之后的rnn_outputs的shape就是(num_steps, batch_size, state_size)
- 每次输入的x都会得到的state(final_states),我们只要的最后的final_state
'''
def testfn(a, x):
return cell(x, a[1])
rnn_outputs, final_states = tf.scan(fn=testfn, elems=tf.transpose(rnn_inputs, [1,0,2]),
initializer=(tf.zeros([batch_size,state_size]),init_state))
# 或者使用 lambda 的方式
# rnn_outputs, final_states = \
# tf.scan(lambda a, x: cell(x, a[1]),
# tf.transpose(rnn_inputs, [1,0,2]),
# initializer=(tf.zeros([batch_size, state_size]), init_state))
# there may be a better way to do this:
final_state = tuple([tf.nn.rnn_cell.LSTMStateTuple(
tf.squeeze(tf.slice(c, [num_steps-1,0,0], [1, batch_size, state_size])),
tf.squeeze(tf.slice(h, [num_steps-1,0,0], [1, batch_size, state_size])))
for c, h in final_states])
with tf.variable_scope('softmax'):
W = tf.get_variable('W', [state_size, num_classes])
b = tf.get_variable('b', [num_classes], initializer=tf.constant_initializer(0.0))
rnn_outputs = tf.reshape(rnn_outputs, [-1, state_size]) # (batch_size x num_steps, state_size)
logits = tf.matmul(rnn_outputs, W) + b # (batch_size x num_steps, num_classes)
y_reshaped = tf.reshape(tf.transpose(y,[1,0]), [-1]) # (num_steps x batch_size,1)
total_loss = tf.reduce_mean(tf.nn.sparse_softmax_cross_entropy_with_logits(logits = logits, labels = y_reshaped))
train_step = tf.train.AdamOptimizer(learning_rate).minimize(total_loss)
return dict(
x = x,
y = y,
init_state = init_state,
final_state = final_state,
total_loss = total_loss,
train_step = train_step
)
# 测试一下
start_time = time.time()
g = build_multilayer_lstm_graph_with_scan()
print("构建图耗时", time.time()-start_time)
start_time = time.time()
train_network(g, 3)
print("训练耗时:", time.time()-start_time)
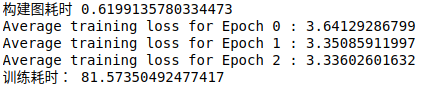
- 可以看到
scan的效果仅仅比dynamic__rnn慢一点,但是他让我们更加好的去理解dynamic_rnn(对于我来说,没啥感觉,什么比dynamic_rnn更麻烦...)
参考
- Recurrent Neural Networks in Tensorflow II