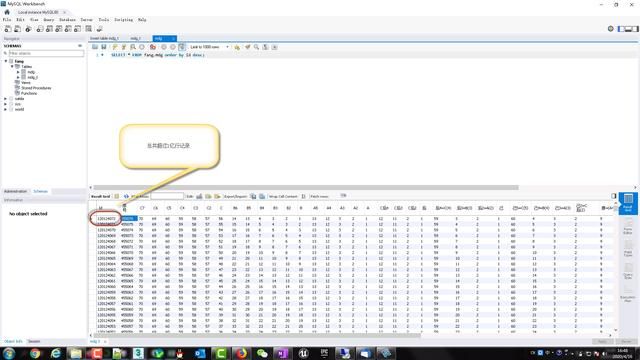
最近有位老铁,他手头上有四百多个Excel文件,每个文件的记录数都达到百万行左右,他很苦恼,因为想把这些文件都合并到一起,但Excel最大的记录数是1048576,他没有办法,所以咨询我,看有什么方法可以做到把这些记录都合并到一起。
我给他推荐的方案是,使用Python + Mysql, 实现Excel数据的自动读取和数据导入。
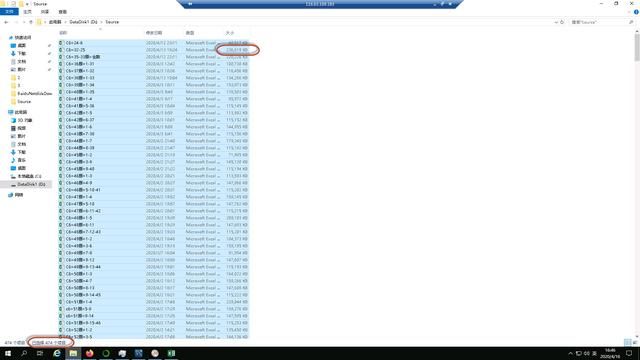
平均200M的Excel文件公有474个
为了方便使用Python,安装了Anaconda,做Python的环境管理;安装了MySQL的社区版和Workbench,方便对数据的操作。
Anaconda可以直接到官网上下载,下载后安装到电脑上就可以,安装过程就不细说;MySQL也可以到官网上下载,下载后安装到电脑上,这里需要注意的是,安装开发者版本,里面包含了数据库实例和Workbench等工具。
我重点说下Python代码,如何使用Pandas库读取Excel,批量写入Mysql数据库。
首先打开Anaconda Navigator, 然后再打开Jupyter notebook,检查环境里是否包括了如下Python库 :
1)Pandas;
2)sqlalchemy;
3)openpyxl.
-Panda 库用是用来处理Excel的;
-Sqlalchemy用来管理Mysql,
-Openpyxl用来读取xlsx后缀的大数据量Excel文件。
如果某个库不存在的话,可以通过Anaconda prompt来安装,举例,命令行输入pip install openpyxl。
如果所有库都准备好后,新建一个Python 3脚本文件,输入如下代码
#引入之前安装好的python库
import pandas as pd
import os
from sqlalchemy import create_engine
import datetime
#遍历存放Excel文件的目录,获取Excel文件的绝对路径
path = r'D:/data/2'
files = os.listdir(path)
for i in files:
path1 = path + '/' + i
print(path1)
#因为文件合并后是有先后次序的,所以上面的代码会把文件的名字打印出来,可以
#检查文件名的排序是否正确
#检查完文件名排序正确后,创建MySQL连接器
engine = create_engine('mysql+pymysql://root:~1Qaz2Wsx@localhost/fang?charset=utf8MB4')
conn = engine.connect()
#为了记录已经导入Excel文件的个数,先定义一个文件数的变量
file_number = 0
#通过遍历所有的Excel文件,把Excel里的数据都导入到MySQL数据库里
for i in files:
path1 = path + '/'+I #i是文件名
print(path1)
starttime = datetime.datetime.now() #记录开始时间
print(starttime)
data = pd.read_excel(path1,engine = 'openpyxl',header =
3,usecols='A:AR')
#header指从第4行开始,并以第4行作为列头,usecols指只读取从A列到AR列的数据,其他列的数据都不要,openpyxl指使用大数#据量的引擎,
把数据从Excel里读入内存里的Pandas Dataframe
data.to_sql(name='mdg',con=conn,index=False,if_exists='append') #然后再把数据从data frame导入到mysql
endtime = datetime.datetime.now() #完成后,打印完成时间
print(endtime)
duration = endtime - starttime #计算单个文件导入消耗时间(秒)
print(duration.seconds)
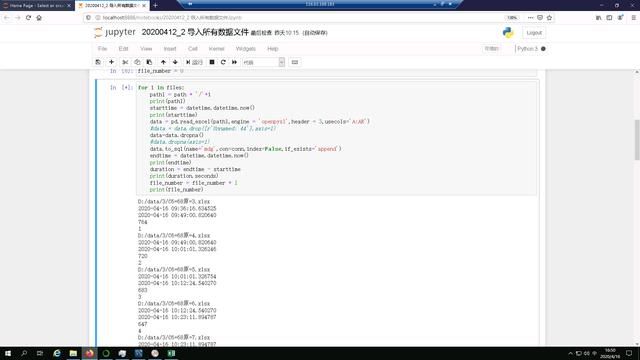
代码执行过程会产生日志