论文地址:https://arxiv.org/pdf/1812.11703.pdf
源码地址:https://lb1100.github.io/SiamRPN++
SiamRPN++源于2018年收录于cs.CV上的论文《SiamRPN++: Evolution of Siamese Visual Tracking with Very Deep Networks》,基于深度网络的孪生视觉跟踪的发展。
孪生网络算法使用的互相关层在视频帧(搜索区域search region)中搜索范例物体(目标模板target template),尽管它非常快速,但相对于目标跟踪领域最优的算法(如ECO、MDNet),在准确度上还有很大差异。
随着深度神经网络的发展,当前更深层的网络能更好地描述图片特征,但作者使用ResNet替代之前类似AlexNet的网络收效甚微,后来发现这是由于较新的网络中都使用了填充padding损失了平移不变性造成的,本文中使用空间感知采样算法,解决了这一问题,使孪生网络能使用更深层的底层网络。同时提出了层聚合和深度聚合的方案,使SiamRPN++模型效果明显提升,且有效地减少了模型参数。
论文主要贡献有几下几点:
- 通过研究证明增加网络深度时模型效果变差的原因是破坏了平移不变性。
- 用简单有效的方法打破了平移不变性的限制,使Siamese网络可使用ResNet基础网络。
- 利用互相关的分层结构,使模型从多个层次学习的相似特征(layer-wise)。
- 用深度结构增强互相关性,产生多个语义相关的相似图(depth-wise)。
最终实现的模型可达35 fps(帧每秒)的速度,并在五种评测中超越之前最佳模型效果,基于MobileNet的模型可达70fps,
深层孪生网络
在跟踪任务中使用比较深层的卷积网络提取特征时,模型效果反而变差,先来看看该问题的原因。
用于跟踪的孪生网络
孪生网络是一个Y型网络,它的两个分枝分别用于获取目标模板的特征和获取搜索区域的特征。目标模板一般是视频第一帧中的一个区域用z表示,目标是找到每帧中与其最相似的区域x:
其中f计算二者相似性,φ用于提取特征,b为偏移参数。孪生网络需要满足以下两个约束条件:第一区域需要严格的平移不变性,它保证了训练和预测的有效性。
中括号中表示子窗口的平移操作。第二需要服从对称性:
无法在孪生网络中使用更深层网络的原因与上述两点有关,深度网络中的填充padding破坏了严格的平移不变性,SiamRPN需要计算分类与回归又影响了对称性。
之前SiamFC孪生网络基于的底层网络AlexNet不需要填充padding,因此没有遇到平移不变性的问题,在更深层的网络中无法避免padding,异致了空间偏见。论文中用模拟实验验证了这一点,将目标设置为分别与图像中心偏移(0,16,32)分别实验,测试集中产生如下热点:
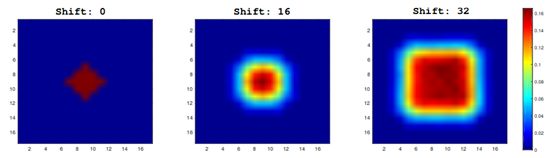
颜色表示正例的概率,左图中偏移为0,它展示了严重的中心偏见,边缘的概率快速衰减为0,右边当偏移变大时,更近似于测试集中实际分布。空间感知采样(spatial aware sampling)可以有效地解决了这一问题。
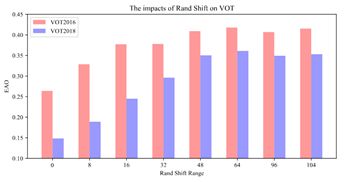
简单地说,如果把目标放在图像的正中心,模型就很难检测到位置不太正的备选区域,若在训练时将目标相对于图片中心位置随机偏移一些(空间感知采样),就可以解决该问题。下图展示了使用ResNet-50提取特征时,偏移带来的模型效果提升:
基于ResNet的孪生跟踪网络
普通的ResNet的步长是32,也就是说输入是224x224像素的图片经过多层网络处理后,最后空间被压缩到7x7,这样的分辨率用于孪生网络比较图片相似度太低了,于是修改了其conv4和conv5层,将它们的空间步长变为1,这样原来缩小32和16就变成了8,提升了输出层卷积的分辨率,在每个模块后面又加了一层卷积层,将输出通道大小转换为256。
然后,结合了互相关网络和卷积网络实现了头部模块(Head),用于计算分类得分(是否为前景)、精调边框、和SiaemeseRPN模型。
另外,在精调模型时,将ResNet特征提取部分的学习率设为RPN部分的十分之一,以适应跟踪任务,参数在端到端的网络中统一训练。
分层聚合
使用更深层次的网络可提取到更多层面的特征,可为跟踪任务提取从高到低的抽象、各种不同的大小,以及从精细到粗糙的分辨率。ResNet相对于之前的模型,层次更加明确,比如低层能提取到颜色、形状、位置等信息,高层测包含更抽象的语义信息,它们在模糊、形变的场景中发挥了更大作用。
在ResNet网络中使用最后三个残差模型的输出作为特征,分别代入三个RPN模块,如下图所示:

三个RPN层的输出具有相同的空间分辨率,可以直接相加:
其中S表示RPN的类别评分,B表示位置框评分,α和B是对不同层的权重。由于分类和回归的领域不同,因而分别计算。
深度互相关
互相关模块是网络的核心,SiamFC算法使用一个互相关层计算单通道互的相关性,并且返回目标位置的映射表(矩阵);SiamRPN将互相关扩展成更高层次信息(像Anchors一样),它加入了庞大的卷积层用于升通道(维度),名为UP-XCorr,升通道模型造成了参数不平衡,如ResNet网络中升通道有20M参数,而特征提取只有4M参数,加大了模型训练的难度。
文中提取了一个轻量级的互相关模块,名为Depthwise Cross Correlation (DW- XCorr),它的参数是UP-Xcorr的十分之一,并实现了与之相似的效果。
与SiamFC框架不同的是,在使用了SiamRPN之后,最后的分类模块和回归模型使用网络不再具有对称性,为了处理差异,目标分枝和搜索分枝使用了不同的卷积模块(不共享参数),两个特征具有同样的通道数,并计算每一通道的相关性,另一个卷积模块用于融合不同通道的输出,最后将卷积后的结果送入了分类和回归层。这样就节约了大量的算力和空间,使得模型参数达到平衡,训练过程更加稳定。

另外,一个有趣的现象是同种类的目标在相同的通道中得到更高的响应,而其它通道的响应被抑制,如下图所示,这可以被解释成depth-wise方法产生的通道特征近似正交,每个通道都表示了一定的语义信息,相对来说Up-Channel方法得到的结果可解释性就比较差。

实验
训练基于ImageNet预测训练的卷积网络,目标分辨率为127像素,搜索区域255像素。评测时使用了OTB2015, VOT2018和UAV123,其中VOT2018-LT评测了长时跟踪:目标有时在视频之外,有时被完全遮挡,难度大于短时跟踪。
消融实验
下图对比了使用不同基础网络的模型效果:
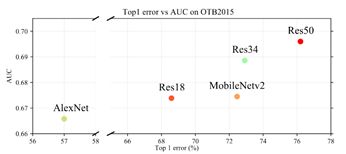
下表中展示了更加详细的消融实验结果:

下表中展示了文中模型与当前流行的其它模型的效果对比:
