本博客内容参考了厦门大学数据库实验室技术文献:http://dblab.xmu.edu.cn/post/8116/
实验准备
首先非常感谢厦门大学林子雨老师的支持,在经过他的许可之后,我将整个实验的过程以及一些自己的想法写了出来,在这里我并没有讨论spark回头客的预测分析,这在后期spark专栏里会有。
在进行实战之前,我们要确保已经配置好了部分环境:
1、hadoop环境的安装配置
2、hive的安装配置(mysql为元数据库):关于如何配置我在之前的博客说过
3、Sqoop的安装配置:本次实验会讲到
我使用的是两台阿里云服务器Ubuntu14.0的系统(因为还是学生,价格很优惠),分布式部署了hadoop2.6.5,spark2.4.1(这在后期会用到)。
实验步骤一:本地数据集上传到数据仓库hive
该数据集data_format(点击保存链接:https://pan.baidu.com/s/11HOMXdGw4P6Srnm3T6wGSg提取码:4feo)是淘宝2015年双11前6个月(包含双11)的交易数据(交易数据有偏移,但是不影响实验的结果),里面有三个文件,分别是用户行为日志文件user_log.csv 、回头客训练集train.csv 、回头客测试集test.csv,我们这里主要使用日志文件user_log.csv。
该数据集里的字段主要有:
1、user_id:买家id
2、item_id:商品id
3、cat_id:商品类别id
4、merchant_id:卖家id
5、brand_id:品牌id
6、month:交易时间:月
7、day:交易时间:日
8、action:行为,取值为0表示点击,1表示加入购物车,2表示购买,3表示关注商品
9、age_range:买家年龄分段:1表示年龄<18,2表示年龄在[18,24],3表示年龄在[25,29],4表示年龄在[30,34],5表示年龄在[35,39],6表示年龄在[40,49],7和8表示年龄>50,0和NULL表示未知
10、gender:性别0表示女性,1表示男性,2和NULL表示未知
11、province:收获地址省份
下载完数据集之后,解压并上传到服务器

为了确保数据集有效可以取出user_log.csv的前5条数据测试:

接下来我们进行数据的预处理
1、删除文件第一行记录,这一行数据我们不需要。
2、由于交易数据太大(5000万条),我们截取前100000条数据集作为一个小数据集,写一个脚本完成上面的截取任务,脚本文件放在data目录下和user_log.csv一起


#!/bin/bash
#下面设置输入文件,把用户执行predeal.sh命令时提供的第一个参数作为输入文件名称
infile=$1
#下面设置输出文件,把用户执行predeal.sh命令时提供的第二个参数作为输出文件名称
outfile=$2
#注意!!最后的$infile > $outfile必须跟在}’这两个字符的后面
awk -F "," 'BEGIN{
id=0;
}
{
if($6==11 && $7==11){
id=id+1;
print $1","$2","$3","$4","$5","$6","$7","$8","$9","$10","$11
if(id==10000){
exit
}
}
}' $infile > $outfile
进行截取

取前10条数据集测试一下:
head -10 small_user_log.csv

3、导入数据库
下面把small_user_log.csv中的数据集最终导入数据仓库hive中,为了完成这个任务我们首先把这个文件上传到分布式文件系统HDFS中,然后在hive中创建外部表完成数据的导入:
a.启动HDFS
可以选择在hadoop目录下的sbin文件下
./start-dfs.sh
或者直接选择
./start-all.sh
b.把small_user_log.csv上传到HDFS中
把本地系统中的small_user_log.csv上传到分布式文件系统HDFS中,存放在HDFS的“/dbtaobao/dataset”目录下
首先,在本地系统的根目录下创建一个新的目录dbtaobao,并在这个目录下创建一个子目录dataset
然后,把本地系统small_user_log.csv上传到分布式文件系统HDFS的“/dbtaobao/dataset”目录下,命令如下:
下面可以查看一下HDFS的small_user_log.csv的前10条记录
c、在hive上创建数据库
新开一个终端,提前启动mysql数据库,后期会用到
启动hadoop和hive,创建数据库dbtaobao

d、创建外部表

e、查询数据
上面创建外部表时已经成功把HDFS中的“/dbtaobao/dataset/user_log”目录下的small_user_log.csv数据加载到了数据仓库hive中,我们可以使用下面命令查询一下:

实验步骤二:hive数据分析
一、操作hive
使用dbtaobao数据库,显示数据库中所有表,查看user_log表的各种属性


查看表的简单结构

二、简单查询分析
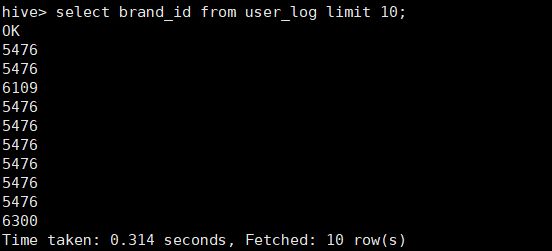
1、查看日志前10个交易日志的商品品牌
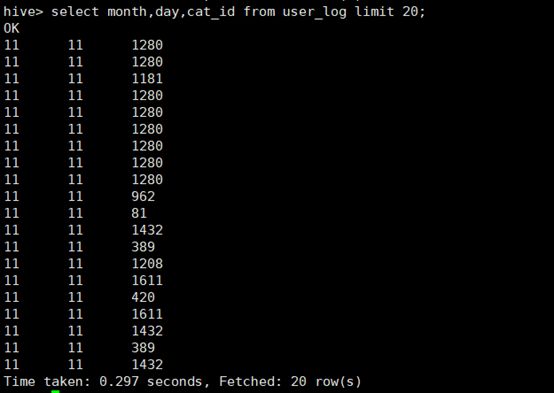
2、查询前20个交易日志中购买商品时的时间和商品的种类
三、查询条数统计分析
1、用聚合函数count()计算表内有多少条数据

2、在函数内部加上distinct,查出uid不重复的数据有多少条
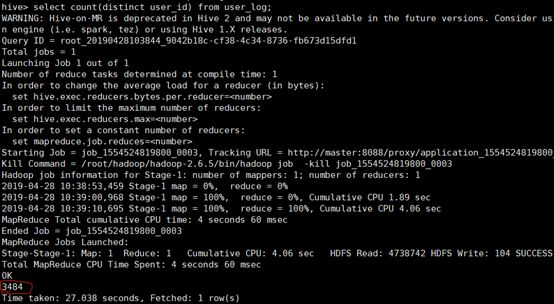
3、查询不重复的数据有多少条(为了排除客户刷单情况)

四、关键字条件查询分析
1、以关键字的存在区间为条件的查询
查询双11那天有多少人购买了商品
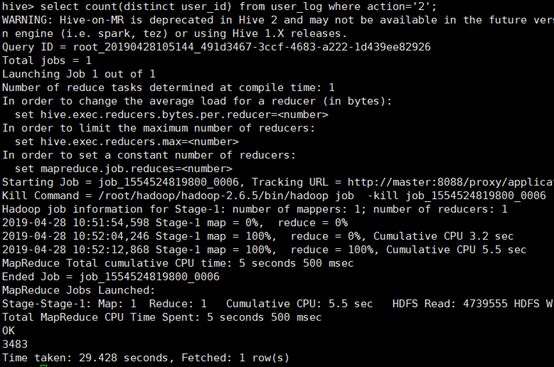
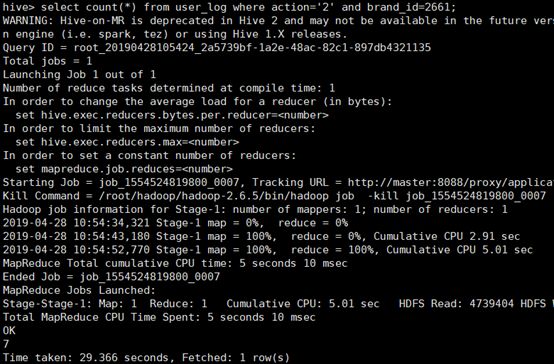
2、关键字赋予给定值为条件,对其他数据进行分析
取给定时间和给定品牌,求当天购买的此品牌商品的数量
五、根据用户行为分析
1、查询一件商品在某天的购买比例或浏览比例
根据上面语句得到购买数量和点击数量,两个相除即可得到当天该商品的购买率
2、查询双11那天,男女买家购买商品的比例
双十一女性购买商品的数量

双十一男性购买商品的数量

两者相除就得到了要求的比例
3、给定购买商品的数量范围,查询某一天在该网站的该买该数量商品的用户id
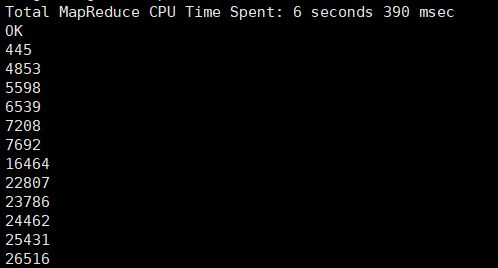
六、用户实时查询分析
不同的品牌的浏览次数

实验步骤三:将数据从hive导入到mysql中
一、准备工作:安装Sqoop(可以将数据导入mysql中)
服务器上新建文件夹sqoop,使用xftp上传到sqoop中解压缩
解压缩完成后,添加到环境变量

进入sqoop安装目录下的conf文件夹中执行以下命令复制sqoop-env-template.sh为sqoop-env.sh并在里面添加以下内容
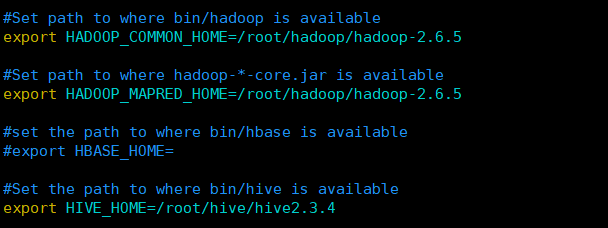
连接数据库之前不要忘记把jar包放到sqoop安装目录下的lib文件夹中,这个jar可以在官网中下载,百度或者谷歌搜索:mysql-connection-java,选择下载的版本,我下载的是mysql-connector-java-5.1.47.zip版本


测试一下:能看到已经读取了mysql中的数据库就说明安装成功,出现warning没有关系,因为没有安装hbase和zookeeper等

二、Hive预操作
1、创建临时表inner_user_log

2、将user_log表中的数据插入到inner_user_log

执行下面命令查询上面的插入命令是否成功执行

三、使用sqoop将数据从hive导入mysql
1、登录到mysql创建数据库


2、创建表

注意:语句中的引号是反引号,不是单引号,sqoop抓数据的时候会把类型转为string类型,所以mysql设计字段的时候,设置为varchar
3、创建完表后,另开一个终端或者退出当前的mysql,进行导入操作

4、返回到刚才的mysql终端或者重新进入mysql查看user_log表中的数据,会得到类似下面的查询结果
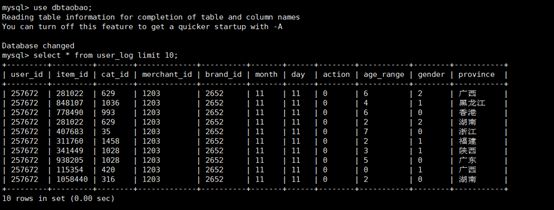
说明从hive导入数据到mysql中,成功!