storm包里面是给了wordcount程序实例的,所以我们是可以参考这个来自己实现。从源码来看,如下
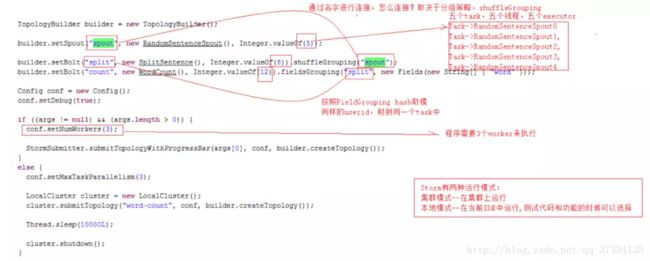
image.png
首先创建TopologyBuilder对象,通过该对象来设置spout和bolt。
设置spout的时候可以指定自己编写的Spout类以及使用的线程数(即executor数或者说task数,因为默认情况下就是相等的)。设置bolt的时候可以指定自己编写的Bolt类,指定分组策略。比如图中,split这个Bolt的数据(以tuple为单位)来源与id为spout的Spout对象,该对象发射数据给Bolt的策略是随机发。而count对应的Bolt的数据来源于split对应的Bolt对象,该对象发送数据按照word字段来发。
单词计数的各种实现伪代码
1、java实现
//一行一行读取文件中数据
String line = BufferedReader.readLine();
//按空格切割
String[] words = line.split(" ");
//进行统计
Map map = new HashMap<>();
for (String word : words){
if(map.containskey(word)){
map.put(word,map.get(word)+1);
}else {
map.put(word,1);
}
}
2、hadoop实现单词计数
protected void map(LongWritable key, Text value,Context context)
throws IOException, InterruptedException {
//每读一行会调用一次
//按空格切分单词
String values = value.toString();
String[] words = values.split(" ");
for (String word : words) {
//将单词作为key,1作为value输出
context.write(new Text(word), new IntWritable(1));
}
}
protected void reduce(Text key, Iterable values,
Context context) throws IOException, InterruptedException {
int count = 0;
for (IntWritable in : values) {
count += in.get();
}
context.write(new Text(key), new IntWritable(count));
}
3、storm实现单词计数
Spout:
FileReader.readLine();
输出:line(tuple对象)
SplitBolt:
输入:line(tuple对象)
String[] words = line.split();
for(String word : words){
//输出word
collectot.emit(word);
}
CountBolt:
输入:word
Map map = new HashMap<>();
for (String word : words){
if(map.containskey(word)){
map.put(word,map.get(word)+1);
}else {
map.put(word,1);
}
}
Storm的单词计数代码编写
1、主程序
public class WordCountTopologyDriver {
public static void main(String[] args) throws AlreadyAliveException, InvalidTopologyException {
//1、创建topologyBuilder,设置spout和bolt
TopologyBuilder topologyBuilder = new TopologyBuilder();
//设置spout 传参:id,使用的Spout类,并发度
topologyBuilder.setSpout("myspout",new MySpout(),1);
//设置Bolt 传参:id,使用的Bolt类,并发度
//设置分组策略 随机分 参数为spout的id
//mybolt1与myspout跟进id进行连接,怎么连接?取决于分组策略,shuffleGrouping会对myspout进行分组
//五个task(也就是五个executor或者说五个线程)
topologyBuilder.setBolt("mybolt1",new SplitBolt(),4).shuffleGrouping("myspout");
//设置分组策略 按字段分 参数为上一阶段的bolt的id
//注:如果字段与mybolt里面声明的不一致会出现backtype.storm.generated.InvalidTopologyException: null
topologyBuilder.setBolt("mybolt2",new CountBolt(),2).fieldsGrouping("mybolt1",new Fields("word"));
//2、创建Config,指定分配的worker的数量
Config config = new Config();
config.setNumWorkers(3);
//提交任务,可以使用storm集群来提交也可以使用本地模式来提交(便于调试)
// StormSubmitter.submitTopology("wordcountsubmit",config,topologyBuilder.createTopology());
//使用本地模式提交
LocalCluster localCluster = new LocalCluster();
localCluster.submitTopology("wordcountsubmit",config,topologyBuilder.createTopology());
}
}
2、自定义Spout
/**
* 获取数据
* 将数据一行行写出去
* Created by 12706 on 2017/11/6.
*/
public class MySpout extends BaseRichSpout {
SpoutOutputCollector collector;
//初始化方法
public void open(Map map, TopologyContext topologyContext, SpoutOutputCollector collector) {
this.collector = collector;
}
//storm 框架会循环调用(while(true){..})该方法,将数据射出去
public void nextTuple() {
//需要传入的是一个List,而Vlaues本身就是一个list
collector.emit(new Values("hadoop hive hbase storm kafka spark"));
}
public void declareOutputFields(OutputFieldsDeclarer outputFieldsDeclarer) {
//给写出去的数据做声明,格式根据 collector.emit来定
outputFieldsDeclarer.declare(new Fields("bigdata"));
}
}
3、单词切割Bolt
/**
* 接收MySpout射出的数据
* 每次接收list中的第一个数据(也只有这一个,是一行单词),按照空格切分,射出到下一个单词统计的CountBolt
* Created by 12706 on 2017/11/6.
*/
public class SplitBolt extends BaseRichBolt{
OutputCollector collector;
//初始化方法
public void prepare(Map map, TopologyContext topologyContext, OutputCollector outputCollector) {
this.collector = outputCollector;
}
//storm框架会循环调用该方法
//对MySpout射出的数据进行处理,将数据按照空格切割写出
public void execute(Tuple tuple) {
//获取list中的第一个数据(实际也只有这一个)
// public String getString(int i) {
// return (String)this.values.get(i);
// }这是源码中代码,而value本身就是个list。所以取的就是spout射出的list中的第一个数据
String line = tuple.getString(0);
//按空格切割
String[] words = line.split(" ");
for (String word : words){
collector.emit(new Values(word,1));
}
}
public void declareOutputFields(OutputFieldsDeclarer outputFieldsDeclarer) {
//写出声明collector.emit(new Values(word,1)),可知需要两个参数对应word和1
// public Fields(String... fields) {
// this(Arrays.asList(fields));
// }可以从源码看到可以传入多个参数
outputFieldsDeclarer.declare(new Fields("word","num"));
}
}
4、单词统计Bolt
/**
* 接收上一个单词划分Bolt传来的数据,进行单词统计
* Created by 12706 on 2017/11/6.
*/
public class CountBolt extends BaseRichBolt {
OutputCollector collector;
//创建一个map用来缓存单词统计结果
Map countMap = new HashMap();
public void prepare(Map map, TopologyContext topologyContext, OutputCollector outputCollector) {
this.collector = outputCollector;
}
public void execute(Tuple tuple) {
//获取单词
String word = tuple.getString(0);
//获取数量(1)
Integer num = tuple.getInteger(1);
if(countMap.containsKey(word)){
//单词已经存在,数量叠加
countMap.put(word,countMap.get(word)+1);
}else {
//单词不存在,添加单词
countMap.put(word,num);
}
//控制台输出查看
System.out.println(countMap);
}
public void declareOutputFields(OutputFieldsDeclarer outputFieldsDeclarer) {
//不需要输出所以不再做声明了,今后有可能输出到redis中等
}
}
设置的是本地运行模式,所以可以直接运行
控制台查看
...
{storm=79526, spark=79524, hadoop=79527, hbase=79526}
{storm=79526, spark=79525, hadoop=79527, hbase=79526}
{storm=79526, spark=79525, hadoop=79528, hbase=79526}
{storm=79526, spark=79525, hadoop=79528, hbase=79527}
{storm=79527, spark=79525, hadoop=79528, hbase=79527}
{hive=109259, kafka=109257}
{hive=109260, kafka=109257}
{hive=109260, kafka=109258}
{hive=109261, kafka=109258}
...
注:这里分两段是因为设置了单词计算Bolt(CountBolt)的并发度为2,而且指定了分组策略是按字段分组,所以分了两段来统计,且各个段里面的单词是一样的。
如果使用集群模式,那么讲工程打包(如storm.jar)传到集群上,执行命令
storm jar storm.jar com.itheima.storm.WordCountTopologyDriver wordcount