学习笔记之机器学习
写在前面:新手小白刚上路,有些晦涩难懂,遂以个人博客的形式记录下来,主要用于巩固自己学到的知识以及便于后期查询,也欢迎处在同一学习阶段朋友的交流。老鸟勿喷,欢迎指正。
原视频教程:B站-黑马程序员-3天快速入门机器学习。
目录
一、关于机器学习的简单入门介绍
1.1 什么是机器学习?
1.2 数据集的构成
1.3 机器学习的算法分类
1.4 机器学习的开发流程
1.5 机器学习入门建议
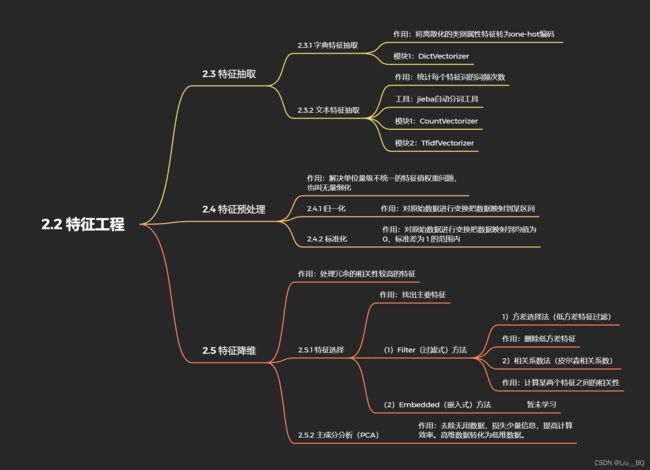
二、特征工程
2.1 数据集
2.1.1 sklearn数据集
2.1.2 数据集的划分
2.2 特征工程介绍
2.3 特征抽取
2.3.1 字典特征抽取
2.3.2 文本特征提取
2.4 特征预处理
2.4.1 归一化
2.4.2 标准化
2.5 特征降维
2.5.1 特征选择
2.5.2 主成分分析(PCA)
三、分类算法
3.1 了解sklearn转换器和预估器
3.2 K-近邻算法(KNN)
3.3 模型选择与调优
3.4 朴素贝叶斯算法
3.5 决策树
3.6 集成学习方法之随机森林
四、回归与聚类算法
4.1 线性回归
4.2 欠拟合与过拟合
4.3 岭回归
4.4 分类算法-逻辑回归与二分类
4.5 模型保存与加载
4.6 无监督学习-K-means算法
一、关于机器学习的简单入门介绍
1.1 什么是机器学习?
机器学习是人工智能的一个实现途径;
深度学习是机器学习的一个方法发展而来。
机器学习就是用机器来模仿人类学习以及其它方面的智能。
机器学习定义:机器学习是从数据中自动分析获得模型,并利用模型对未知数据进行预测。
1.2 数据集的构成
数据集是用于机器学习的数据,数据集一般由特征值和目标值两方面构成。
但是,有些数据集可以没有目标值,依据数据本身的特征来分类。
也就是“有监督学习”(supervised learning)和“无监督学习”(unsupervised learning)的区别。
1.3 机器学习的算法分类
(1)类别的分类问题,目标值是离散型的数据。
例如,给出猫和狗的图片,识别一张图片是猫还是狗。
特征值是猫和狗的图片,目标值是猫和狗的类别。
代表算法:K-近邻算法、贝叶斯分类、决策树与随机森林、逻辑回归。
(2)数据的回归问题,目标值是连续型的数据。
例如,根据房屋的各个属性(如地段、朝向等)来预测房屋的价格,价格就是连续型的数据。
特征值是房屋的各个属性信息,目标值是房屋价格(连续型数据)。
代表算法:线性回归、岭回归。
(3)聚类问题。数据集构成提到有些数据集没有目标值,即无监督学习,输入特征没有标签,依据数据本身的特征来分类。
代表算法:K-means聚类。
1.4 机器学习的开发流程
(1)获取数据
(2)数据处理:处理数据比较嘈杂或者缺失值
(3)特征工程:也算数据处理,这一步将数据处理成更能直接被机器学习算法使用的数据
(4)机器学习算法训练得到模型
(5)模型评估
(6)模型应用
(可搜索相关教程,爬虫获取数据、数据分析处理数据、机器学习训练数据,更能深刻理解一整套的流程)
1.5 机器学习入门建议
(1)明确重点:算法是核心,数据和计算是基础。(一定要做好训练数据)
(2)应用入门:先掌握一些机器学习算法等技巧,从某个业务领域切入解决问题。
(3)分析问题:先明确使用机器学习算法的目的是想完成什么样的任务,用算法想干什么事。
(4)掌握算法:掌握算法基本思想,对某个问题的应用能想到用相应的、合适的算法去解决。
(5)经典书籍:如果看书的话,先看实战类的书籍。如果想深入了解某一块,专业类的经典书籍有:《机器学习》,也被称作“西瓜书”,作者周志华;《统计学习方法》,作者李航;《深度学习》,也被称作“花书”,作者Ian Goodfellow、Yoshua Bengio 和Aaron Courville;
(6)其它:学会利用库或框架解决问题。(机器学习算法sklearn,深度学习框架tensorflow(谷歌出的)、pytorch、caffe(这俩是facebook出的)等,tensorflow目前用的人最多)
(总之,就是先入门看看教程,大致有个了解;再想深入了解某一领域的应用,看一些实战类书籍;再想深入研究某一块,看高认可度的经典书籍。)
二、特征工程
2.1 数据集
2.1.1 sklearn数据集
(1)获取数据集API
获取小规模的数据集,直接自带
datasets.load_*()
例如,获取经典鸢尾花数据集
sklearn.datasets.load_iris()
获取大规模的数据集,要从网上下载
第一个参数data_home是数据集下载的目录,默认~/scikit_learn_data/
datasets.fetch_*(data_home=None)
例如,获取经典的新闻文本分类数据集
subset可以选“train”, "test", "all",就是获取训练集、测试集还是两者都要
sklearn.datasets.fetch_20newsgroups(data_home=None, subset='train')
(2)sklearn数据集的返回值:
load和fetch返回的数据类型datasets.base.Bunch(字典格式)
data:特征数据数组,是[n_samples * n_features]的二维numpy.ndarray数组
target:标签数组,是n_samples的一位numpy.ndarray数组
DESCR:数据描述
feature_names:特征名。新闻数据、手写数字、回归数据集没有
target_names:标签名
2.1.2 数据集的划分
(1)数据集一般被划分为训练集和测试集。
训练集:用于训练、构建模型;
测试集:在模型检验时使用,用于评估模型是否有效;
(2)数据集划分的API:
sklearn.model_selection.train_test_split(arrays, *options)
test_size:测试集的大小(如果不设置,默认0.25)
random_state:随机数种子,不同种子会造成不同的随机采样结果。
(3)示例如下:
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
def datasets_demo():
"""
sklearn数据集使用
:return:
"""
# 获取数据集
iris = load_iris()
print("鸢尾花数据集:\n", iris)
print("查看数据集描述:\n", iris["DESCR"])
print("查看特征值的名字:\n", iris.feature_names)
print("查看特征值:\n", iris.data, iris.data.shape)
# 数据集划分
x_train, x_test, y_train, y_test = train_test_split(iris.data, iris.target, test_size=0.2, random_state=22)
print("训练集的特征值:\n", x_train, x_train.shape)
return None
if __name__ == "__main__":
# 代码1:sklearn数据集使用
datasets_demo()
2.2 特征工程介绍
(1)为什么要做特征工程:数据和特征决定了机器学习的上限,而模型和算法只是逼近这个上限而已。
(2)什么是特征工程:处理数据是特征能在机器学习过程中发挥更好作用的过程,特征工程会直接影响机器学习的效果。
(3)数据处理的比较:sklearn做特征工程;pandas做数据清洗、数据处理。
(4)特征工程包含内容:特征抽取(特征提取)、特征预处理、特征降维。
以下内容如图所示,按需查看。
2.3 特征抽取
(1)什么是特征抽取:将任意数据(如文本或图像)转换为可用于机器学习的数字特征,也叫做特征值化。例如,将类别属性特征通过one_hot编码处理成数字的哑变量使其用于机器学习的识别。
(2)特征抽取方法:对不同原始数据也有不同的转换方法:字典就用字典特征提取(特征离散化);文本就用文本特征提取;图像就用图像特征提取(深度学习方法更好)。
2.3.1 字典特征抽取
(1)字典特征抽取的作用:将类别属性特征转为one-hot编码。
(2)字典特征抽取的API:
sklearn.feature_extraction.DictVectorizer(sparse=True, ...)
·DictVectorizer.fit_transform(X) X:字典或者包含字典的迭代器,返回值:返回sparse矩阵
·DictVectorizer.inverse_transform(X) X:array数组或者sparse矩阵,返回值:转换之前的数据格式
·DictVectorizer.get_feature_names() 返回值:类别名称
(sparse=True返回的就是稀疏矩阵,sparse=False返回的就是二维数组,两者等价)
(sparse矩阵的作用就是将非零值按位置表示出来,不表示零值,可以节省内存进而提高加载效率)
(3)示例如下:
from sklearn.feature_extraction import DictVectorizer
def dict_demo():
"""
字典特征抽取
:return:
"""
data = [{'city': '北京','temperature':100}, {'city': '上海','temperature':60}, {'city': '深圳','temperature':30}]
# 1、实例化一个转换器类
transfer = DictVectorizer(sparse=True)
# 2、调用fit_transform()
data_new = transfer.fit_transform(data) # fit是计算,transform是转换
print("data_new:\n", data_new, type(data_new))
print("特征名字:\n", transfer.get_feature_names())
return None
if __name__ == "__main__":
# 代码2:字典特征抽取
dict_demo()2.3.2 文本特征提取
(1)文本特征抽取的作用:统计每个样本中特征词出现的次数
(2)文本特征提取的API:
sklearn.feature_extraction.text.CountVectorizer(stop_words=[]) 返回值:返回词频矩阵
(stop_words是停用词,在文本中不想被统计的没有什么意义的词,可以以列表的形式传给CountVectorizer,也可以借助专业NLP机构已经开发的停用词表)
·CountVectorizer.fit_transform(X) X:文本或者包含文本字符串的可迭代对象,返回值:返回sparse矩阵
·CountVectorizer.inverse_transform(X) X:array数组或者sparse矩阵,返回值:转换之前的数据格式
·CountVectorizer.get_feature_names() 返回值:单词列表
(3)示例如下:
from sklearn.feature_extraction.text import CountVectorizer
def count_demo():
"""
文本特征抽取:CountVecotrizer
:return:
"""
data = ["life is short,i like like python", "life is too long,i dislike python"]
# 1、实例化一个转换器类
transfer = CountVectorizer(stop_words=["is", "too"])
# 2、调用fit_transform
data_new = transfer.fit_transform(data) # fit是计算,transform是转换
print("data_new:\n", data_new)
print("特征名字:\n", transfer.get_feature_names())
return None
if __name__ == "__main__":
# 代码3:文本特征抽取:CountVecotrizer
count_demo()
(此时没有设置sparse=True或False,默认返回的是词频计数的稀疏矩阵,如果想返回值是二维数组,类似于上述“代码2”直接设置“sparse=False”是不可取的,会报错。可以在代码3中做出以下修改,上述代码2也同理,即使不设置sparse=True或False,加上*.toarray.()就可以输出二维数组了)
print("data_new:\n", data_new.toarray())(4)那,中文的文本特征词怎么提取呢?
如果数据文本是中文语句的话,程序默认每一句话作为一个特征词。例如,将上述英文文本改为中文文本。
data = ["我爱北京天安门", "天安门上太阳升"]此时输出的是两个特征词(一句话一个特征词)。
data_new:
[[0 1]
[1 0]]
特征名字:
['天安门上太阳升', '我爱北京天安门']原因在于英文文本在每个单词中间会以空格隔开,而中文文本是连续的,中间没有空格。如果把中文语句按照词组隔开,进行分词,则每个词组就是一个特征词。例如
data = ["我 爱 北京 天安门", "天安门 上 太阳 升"]此时输出的是,类似于英文文本那样的词频统计。
data_new:
[[1 1 0]
[0 1 1]]
特征名字:
['北京', '天安门', '太阳'](5)借助自动分词工具jieba
但手工分词在实际应用中显然是不可取的,于是就借助分词工具,例如jieba分词工具。例如:
from sklearn.feature_extraction.text import CountVectorizer
import jieba
def cut_word(text):
"""
进行中文分词:"我爱北京天安门" --> "我 爱 北京 天安门"
:param text:
:return:
"""
text = " ".join(list(jieba.cut(text))) # jieba_cut是词语生成器,list转成列表形式,join转成字符串类型
return text
def count_chinese_demo2():
"""
中文文本特征抽取,自动分词
:return:
"""
# 将中文文本进行分词
data = ["一种还是一种今天很残酷,明天更残酷,后天很美好,但绝对大部分是死在明天晚上,所以每个人不要放弃今天。",
"我们看到的从很远星系来的光是在几百万年之前发出的,这样当我们看到宇宙时,我们是在看它的过去。",
"如果只用一种方式了解某样事物,你就不会真正了解它。了解事物真正含义的秘密取决于如何将其与我们所了解的事物相联系。"]
data_new = []
for sent in data:
data_new.append(cut_word(sent)) # append往元素里面添加内容
# print(data_new)
# 1、实例化一个转换器类
transfer = CountVectorizer(stop_words=["一种", "所以"])
# 2、调用fit_transform
data_final = transfer.fit_transform(data_new) # fit是计算,transform是转换
print("data_new:\n", data_final.toarray())
print("特征名字:\n", transfer.get_feature_names())
return None
if __name__ == "__main__":
# 代码4:中文文本特征抽取,自动分词
count_chinese_demo2()
(6)Tf-idf文本特征提取
1)Tf-idf文本特征提取的作用:如果某个词或者短语在一篇文章中出现的频率高,并且在其它文章中很少出现,则认为该词或短语具有很好的类别区分能力,适合用来分类。TF-IDF的作用就是用以评估一个词对于数据的重要程度,简而言之就是衡量一个词的重要程度。
词频(term frequency, tf)是某一个词语在该文件中出现的频率;
逆向文档频率(inverse document frequency, idf)是一个词语普遍重要性的度量,某个词语的idf,可以由总文件数目除以包含该词语的文件的数目,再将结果取以10为底的对数得到。
2)TF-IDF的公式:
例如,语料库有1000篇文章,有100篇文章有“非常”,有10篇文章有“经济”。
文章A有100个词,出现了10次“经济”,则 tf = 10/100 = 0.1,idf = lg(1000/10) = 2
文章B有100个词,出现了10次“非常”,则 tf = 10/100 = 0.1;idf = lg(1000/100) = 1
通过 tf 无法判断这两个词对于数据的重要程度。
“经济”的tfidf = 0.2;“非常”的tfidf = 0.1
则“经济”相对于“非常”在语料库中的重要程度更高。
3)TF-IDF文本特征提取的API:
sklearn.feature_extraction.text.TfidfVectorizer(stop_words=None, ...)
返回词的权重矩阵
TfidfVectorizer.fit_transform(X) X:文本或者包含文本字符串的可迭代对象;返回值:返回sparse矩阵
TfidfVectorizer.inverse_transform(X) X:array数组或者sparse矩阵;返回值:转换之前数据格式
TfidfVectorizer.get_feature_names(X) 返回值:单词列表
4)TF-IDF文本特征抽取示例如下:(与代码4非常类似。里面只有文本特征抽取,后面可以找案例进行tf-idf计算的案例实践)
from sklearn.feature_extraction.text import CountVectorizer, TfidfVectorizer
import jieba
def cut_word(text):
"""
进行中文分词:"我爱北京天安门" --> "我 爱 北京 天安门"
:param text:
:return:
"""
text = " ".join(list(jieba.cut(text))) # jieba_cut是词语生成器,list转成列表形式,join转成字符串类型
return text
def tfidf_demo():
"""
用TF-IDF的方法进行文本特征抽取
:return:
"""
# 将中文文本进行分词
data = ["一种还是一种今天很残酷,明天更残酷,后天很美好,但绝对大部分是死在明天晚上,所以每个人不要放弃今天。",
"我们看到的从很远星系来的光是在几百万年之前发出的,这样当我们看到宇宙时,我们是在看它的过去。",
"如果只用一种方式了解某样事物,你就不会真正了解它。了解事物真正含义的秘密取决于如何将其与我们所了解的事物相联系。"]
data_new = []
for sent in data:
data_new.append(cut_word(sent)) # append往元素里面添加内容
# print(data_new)
# 1、实例化一个转换器类
transfer = TfidfVectorizer(stop_words=["一种", "所以"])
# 2、调用fit_transform
data_final = transfer.fit_transform(data_new) # fit是计算,transform是转换
print("data_new:\n", data_final.toarray())
print("特征名字:\n", transfer.get_feature_names())
return None
if __name__ == "__main__":
# 代码5:用TF-IDF的方法进行文本特征抽取
tfidf_demo()
2.4 特征预处理
(1)什么是特征预处理:通过一些转换函数将特征数据转换成更加适合算法模型的特征数据过程。
(2)特征预处理包含内容:无量纲化(归一化、标准化)。归一化、标准化统称无量纲化,使不同规格的数据转换到同一规格。
(3)为什么要进行归一化、标准化:特征值的单位或大小相差较大,或某特征的方差比其它特征大好几个数量级,容易支配目标结果,算法无法学习到其它特征。(简而言之就是学习特征值的权重问题)
2.4.1 归一化
(1)归一化的作用:就是对原始数据进行变换把数据映射到某区间之间(默认[0, 1])。
(2)归一化的公式:
作用于每一列,max为一列的最大值,min为每一列的最小值,X''为最终结果,mx、mi分别为指定区间的最大最小值。例如,下表对特征1: X' = 1, X'' = 1 (默认[0, 1]区间)。
| 特征1 | 特征2 | 特征3 | 特征4 |
| 90 | 2 | 10 |
40 |
| 60 | 4 | 15 | 45 |
| 75 | 3 | 13 | 46 |
(3)归一化的API:
sklearn.preprocessing.MinMaxScaler(feature_range=(1,1), ...)
MinMaxScaler.fit_transform(X) X:要求numpy array格式的数据[n_samples, n_features],返回值:转换后的形状相同的array
(4)示例如下:
import pandas as pd # 读取文本文件,调用pandas读取是最方便的
from sklearn.preprocessing import MinMaxScaler
def minmax_demo():
"""
归一化
:return:
"""
# 1、获取数据
data = pd.read_csv("dating.txt") # 读取当前路径下的dating.csv文件
data = data.iloc[:, :3] # 归一化不用目标值,所以只需要前3列的特征值,用iloc索引前三列
print("data:\n", data)
# 2、实例化一个转换器类
transfer = MinMaxScaler(feature_range=[2, 3]) # 设定归一化范围在[2, 3] 区间内
# 3、调用fit_transform
data_new = transfer.fit_transform(data) # fit是计算,transform是转换
print("data_new:\n", data_new)
return None
if __name__ == "__main__":
# 代码6:归一化
minmax_demo()
(归一化是根据数据中的最大值和最小值求出来的,如果最大值最小值异常的话,则归一化的鲁棒性较差,因此,归一化适合传统的精确小数据场景。由此引入标准化。)
2.4.2 标准化
(1)标准化的作用:通过对原始数据进行变换把数据变换到均值为0,标准差为1的范围内。
(2)标准化的公式:
作用于每一列,mean为平均值, 为标准差。
为标准差。
(如果最大值最小值异常的话,均值和标准差都不会发生太大变化,因此这种情况下标准化的鲁棒性会更强)
(3)标准化的API:
sklearn.preprocessing.StandardScaler()
处理之后,对每列来说,所有数据都聚集在均值为0附近,标准差为1
StandardScaler.fit_transform(X) X要求numpy array格式的数据[n_samples, n_features],返回值:转换后的形状相同的array
(4)示例如下:(和上述归一化同理,但不能设置目标映射区间feature_rande=[])
import pandas as pd # 读取文本文件,调用pandas读取是最方便的
from sklearn.preprocessing import StandardScaler
def standard_demo():
"""
标准化
:return:
"""
# 1、获取数据
data = pd.read_csv("dating.txt") # 读取当前路径下的dating.csv文件
data = data.iloc[:, :3] # 归一化不用目标值,所以只需要前3列的特征值,用iloc索引前三列
print("data:\n", data)
# 2、实例化一个转换器类
transfer = StandardScaler()
# 3、调用fit_transform
data_new = transfer.fit_transform(data) # fit是计算,transform是转换
print("data_new:\n", data_new)
return None
if __name__ == "__main__":
# 代码7:标准化
standard_demo()
(在已有样本足够多的情况下比较稳定,适合现代嘈杂大数据场景)
2.5 特征降维
(1)什么是降维:降维是指在某些限定条件下,降低随机变量(特征)个数,得到一组“不相关”主变量的过程。(其实就是降低特征的个数,得到的特征与特征之间不相关,去除冗余的相关特征,例如相对湿度和降雨量之间就是相关的特征。)
(2)降维的方法:降维有特征选择和主成分分析(PCA)两种方法。
2.5.1 特征选择
(1)特征选择的作用:数据中包含冗余或相关变量,旨在找出主要特征。
(2)特征选择的方法:Filter(过滤式)、Embedded(嵌入式)。
(3)特征选择的Filter(过滤式)方法:
特征选择的Filter(过滤式)方法主要探究特征本身特点、特征与特征和目标值之间的关联,主要有方差选择法(低方差特征过滤)和相关系数法(特征与特征之间的相关性)。
1)低方差特征过滤的API:
sklearn.feature_selection.VarianceThreshold(threshold = 0.0)
删除所有低方差特征
threshold是方差阈值,默认设定为0,即把一样的特征过滤掉。
Variance.fit_transform(X) X要求numpy array格式的数据[n_samples, n_features];返回值:训练集差异地狱阈值的特征将被删除,默认保留所有非零方差特征。
2)低方差特征过滤的示例如下:
import pandas as pd # 读取文本文件,调用pandas读取是最方便的
from sklearn.feature_selection import VarianceThreshold
def variance_demo():
"""
过滤低方差特征
:return:
"""
# 1、获取数据
data = pd.read_csv("factor_returns.csv") # 读取当前路径下的factor_returns.csv文件
data = data.iloc[:, 1:-2] # 用iloc索引出数据中需要的特征
print("data:\n", data)
# 2、实例化一个转换器类
transfer = VarianceThreshold(threshold=10)
# 3、调用fit_transform
data_new = transfer.fit_transform(data) # fit是计算,transform是转换
print("data_new:\n", data_new, data_new.shape)
return None
if __name__ == "__main__":
# 代码8:过滤低方差特征
variance_demo()
3)相关系数法(皮尔森相关系数)的API:
相关系数法以皮尔森相关系数为例,反映变量之间相关关系密切程度的统计指标。
当两个变量相关性很强的时候,可以选取其中一个变量、或者将这两个变量进行加权求和形成一个新的变量,也可以用主成分分析自动处理掉相关性比较强的变量。
4)皮尔森相关系数的公式:
相关系数的取值范围在[-1, 1]之间
当 r > 0,两变量正相关;当 r < 0,两变量负相关
当 | r | = 1,两变量完全相关,当 r = 0,两变量不相关
当 0 < | r | < 1,两变量存在一定程度的相关,越接近1越相关,越接近0越不相关
一般按三级划分:| r | < 0.4低度相关;0.4 < | r | < 0.7显著性相关;0.7 < | r | < 1高度相关;
5)皮尔森相关系数的API:
from.scipy.stats import pearsonr
返回值:皮尔森相关系数的值
6)计算皮尔森相关系数的示例如下:(继续在上述代码8中加入皮尔森相关系数的计算)
import pandas as pd # 读取文本文件,调用pandas读取是最方便的
from sklearn.feature_selection import VarianceThreshold
from scipy.stats import pearsonr
def variance_demo():
"""
过滤低方差特征
:return:
"""
# 1、获取数据
data = pd.read_csv("factor_returns.csv") # 读取当前路径下的factor_returns.csv文件
data = data.iloc[:, 1:-2] # 用iloc索引出数据中需要的特征
print("data:\n", data)
# 2、实例化一个转换器类
transfer = VarianceThreshold(threshold=10)
# 3、调用fit_transform
data_new = transfer.fit_transform(data) # fit是计算,transform是转换
print("data_new:\n", data_new, data_new.shape)
# 计算某两个变量之间的相关系数
r1 = pearsonr(data["pe_ratio"], data["pb_ratio"])
print("相关系数:\n", r1)
r2 = pearsonr(data['revenue'], data['total_expense'])
print("revenue与total_expense之间的相关性:\n", r2)
return None
if __name__ == "__main__":
# 代码8:过滤低方差特征
# 代码8:计算某两个变量之间的皮尔森相关系数
variance_demo()
(4)特征选择的Embedded(嵌入式)方法:
特征选择的Embedded(嵌入式)方法是算法自动选择特征(特征与目标值之间的关联),主要有决策树(信息熵、信息增益)、正则化(L1、L2)、深度学习(卷积等)。
2.5.2 主成分分析(PCA)
(1)什么是主成分分析:高维数据转化为低维数据的过程,可能会舍弃原有数据、创造新的变量。
(2)主成分分析的作用:数据维数压缩,尽可能降低原数据的维数(复杂度),损失少量信息。
(3)主成分分析(PCA)的API:
sklearn.decomposition.PCA(n_compositions=None)
将数据分解为较低维数空间
n_compositions:如果是小数,则表示保留百分之多少的信息;如果是整数,表示减少到多少特征
PCA.fit_transform(X) X要求numpy array格式的数据[n_smaples, n_features]
返回值:转换后指定维度的array
(4)主成分分析(PCA)的示例如下:
from sklearn.decomposition import PCA
def pca_demo():
"""
PCA降维
:return:
"""
data = [[2, 8, 4, 5], [6, 3, 0, 8], [5, 4, 9, 1]]
# 1、实例化一个转换器类
transfer = PCA(n_components=0.95) # 设定数据是小数,意为保留95%的信息
# 2、调用fit_transform
data_new = transfer.fit_transform(data) # fit是计算,transform是转换
print("data_new:\n", data_new)
return None
if __name__ == "__main__":
# 代码9:PCA降维
pca_demo()三、分类算法
3.1 了解sklearn转换器和预估器
转换器(transformer)
估计器(estimator)
(1)什么是转换器:转换器是特征工程的父类。上一节代码中的流程,先实例化一个转换器类(Transform);再调用fit_transform,fit是计算,transform是进行转换。
(2)什么是估计器:估计器是sklearn机器学习算法的实现。这一节代码中的流程,先实例化一个估计器类(estimator);再调用estimator.fit(x_train, y_train),fit同样是计算,这一步命令意味着训练模型;生成模型再进行模型评估,有两种方法:
1)直接比对真实值和预测值
y_predict = estimator.predict(x_test) 根据模型生成相应的预测结果
y_test == y_predic根据测试集和预测的目标值进行比对结果,如果都是true则说明预测对的比较多
2)用模型的方法直接计算准确率
accuracy = estimator.score(x_test, y_test) 测试集的特征值和目标值都传进来
3.2 K-近邻算法(KNN)
(1)什么是K-近邻算法(KNN):如果一个样本再特征空间中的 K 个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别。
(2)欧氏距离的计算公式:
假设有两个样本,分别有3个特征:a(a1, a2, a3) b(b1, b2, b3)
(3)KNN算法要注意的问题:
① K 值取得过小,容易受到异常点的影响;K值取得过大,容易受到样本不均衡的影响。
② 在使用算法之前一般要先对样本特征进行无量纲化——标准化的处理。
③ 必须指定K值,K值选择不当则分类精度不能保证。
(4)K-近邻算法的API:
sklearn.neighbors.KNeighborsClassifier(n_neighbors=5, algorithm='auto')
n_neighbors: int,可选(默认=5) , k_neighbors查询默认使用的邻居数
algorithm: {'auto','ball_tree','kd_tree','brute'},可选用于计算最近邻居的算法: ‘ball_tree'将会使用BallTree,‘kd_tree'将使用KDTree。‘auto'将尝试根据传递给fit方法的值来决定最合适的算法。(不同实现方式影响效率)
(5)KNN算法示例如下:(鸢尾花种类预测)
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.neighbors import KNeighborsClassifier
def knn_iris():
"""
用KNN算法对鸢尾花进行分类
:return:
"""
# 1)获取数据
iris = load_iris()
# 2)划分数据集
x_train, x_test, y_train, y_test = train_test_split(iris.data, iris.target, random_state=22)
# 3)特征工程:标准化
transfer = StandardScaler()
x_train = transfer.fit_transform(x_train) # 训练集的特征值需要计算并转换
x_test = transfer.transform(x_test) # 测试集和训练集同样需要标准化,但只需转换即可
# 4)KNN算法预估器
estimator = KNeighborsClassifier(n_neighbors=3)
estimator.fit(x_train, y_train)
# 5)模型评估
# 两个方法看3.1的(2)
# 方法1:直接比对真实值和预测值
y_predict = estimator.predict(x_test)
print("y_predict:\n", y_predict)
print("直接比对真实值和预测值:\n", y_test == y_predict)
# 方法2:计算准确率
score = estimator.score(x_test, y_test)
print("准确率为:\n", score)
return None
if __name__ == "__main__":
# 代码10: 用KNN算法对鸢尾花进行分类
knn_iris()3.3 模型选择与调优
上述3.2中的KNN算法必须指定 K 值,K 值选择不当则分类精度无法保证,如何选定最佳的K值,则需要用到以下方法。
(1)交叉验证:
什么是交叉验证(cross validation):将训练数据集分为训练和验证集。以下图为例,将数据分成4份,其中一份作为验证集。然后经过4次测试,每次都更换不同的验证集。即得到4组模型的结果,取平均值作为最终结果。又称4折交叉验证。
训练集:训练集+验证集
测试集:测试集

(2)超参数搜索-网格搜索(Grid search)
什么是超参数搜索-网格搜索:通常,有很多参数是需要手动指定的(如KNN中的K值),这种叫超参数。但是手动过程繁杂。所以需要对模型预设几种超参数组合,每组超参数都采用交叉验证来进行评估,最后选出最优参数组合建立模型。
(3)模型选择与调优API
sklearn.model_selection.GridSearchCV(estimator, param_grid=None, cv=None)
对估计器的指定参数值进行详尽搜索
estimator:估计器对象
param_grid:估计器参数(dict){"n_neighbors":[1, 3, 5]}
cv:指定几折交叉验证
fit():输入训练数据
score():准确率
结果分析:
最佳参数:best_params_
最佳结果:best_score_
最佳估计器:best_estimator_
交叉验证结果:cv_results_
(4)模型选择与调优示例如下:(KNN鸢尾花案例增加K值调优)
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import GridSearchCV # 导入模型选择与调优——网格搜索模块
def knn_iris_gscv():
"""
用KNN算法对鸢尾花进行分类,添加网格搜索和交叉验证
:return:
"""
# 1)获取数据
iris = load_iris()
# 2)划分数据集
x_train, x_test, y_train, y_test = train_test_split(iris.data, iris.target, random_state=22)
# 3)特征工程:标准化
transfer = StandardScaler()
x_train = transfer.fit_transform(x_train)
x_test = transfer.transform(x_test)
# 4)KNN算法预估器
estimator = KNeighborsClassifier()
# 加入网格搜索与交叉验证
# 参数准备
param_dict = {"n_neighbors": [1, 3, 5, 7, 9, 11]} # param预估器参数给定一些K值
estimator = GridSearchCV(estimator, param_grid=param_dict, cv=10) # param预估器参数给定一些K值,10折交叉验证
estimator.fit(x_train, y_train)
# 5)模型评估
# 方法1:直接比对真实值和预测值
y_predict = estimator.predict(x_test)
print("y_predict:\n", y_predict)
print("直接比对真实值和预测值:\n", y_test == y_predict)
# 方法2:计算准确率
score = estimator.score(x_test, y_test)
print("准确率为:\n", score)
# 最佳参数:best_params_
print("最佳参数:\n", estimator.best_params_)
# 最佳结果:best_score_
print("最佳结果:\n", estimator.best_score_)
# 最佳估计器:best_estimator_
print("最佳估计器:\n", estimator.best_estimator_)
# 交叉验证结果:cv_results_
print("交叉验证结果:\n", estimator.cv_results_)
return None
if __name__ == "__main__":
# 代码10: 用KNN算法对鸢尾花进行分类,加入模型选择与调优
knn_iris_gscv()
3.4 朴素贝叶斯算法
(1)什么是朴素贝尔斯分类方法:上述KNN算法直接把属性预测到某一类别中,而朴素贝叶斯算法是把每一种目标值的预测概率计算出来,得到每一种分类的可能性,最后会取概率比较大的分类结果。
(2)概率基础
①联合概率:包含多个条件,且所有条件同时成立的概率。记作P(A ,B)
②条件概率:就是事件A在另外一个事件B已经发生条件下的发生概率。记作P(A|B)
③相互独立:如果P(A ,B)=P(A)P(B),则称事件A与事件B相互独立。
(3)朴素贝叶斯的重要特点:
①朴素贝叶斯算法是做了一个重要的假设,假设特征与特征之间是相互独立的。
②朴素贝叶斯算法就等于“朴素”+“贝叶斯”,其中“朴素”就是假设特征与特征之间相互独立。
③应用场景:一般用于文本分类、文本情感分析。
(4)朴素贝叶斯方法优缺点
优点:对缺失数据不太敏感,算法比较简单,常用于文本分类;分类准确度高,速度快
缺点:由于朴素贝叶斯假定了样本属性之间是相互独立的,所以如果特征属性有关联时效果不好
(5)朴素贝叶斯算法的相关公式:
①贝叶斯公式
w为给定文档的特征值(频数统计,预测文档提供),c为文档类别
例如,如果应用在具体文章分类场景中,可以这么理解:
其中C可以是不同类别
公式分为3部分:
P(C):每个文档类别的概率(某文档类别数/总文档数量)
P(W|C):给定类别下特征(被预测文档中出现的词)的概率
·计算方法:P(F1|C)=Ni/N(训练文档中去计算)
·Ni为该F1词在C类别下所有文档中出现的次数
·N为所属类别C下的文档所有词出现的次数和
P(F1,F2,...)预测文档中每个词的概率
②拉普拉斯系数
为防止有些情况下(例如样本量不足)计算出的分类概率为0,则需要引入拉普拉斯平滑系数。
注意:如果其中一项加入拉普拉斯平滑系数,则其它项也需要加入拉普拉斯平滑系数
 为指定的系数一般为1,m为训练文档中统计出的特征词个数
为指定的系数一般为1,m为训练文档中统计出的特征词个数

以文本分类的小案例理解公式,测试集文档中共包含5个词,根据训练集中的词语(特征值)和是否属于c=China类(目标值)等数据,来判断测试集是否属于c=China?
分别计算属于目标值和不属于目标值的概率
P(C|F1,F2,...)=P(C|Chinese,Chinese,Chinese,Tokyo,Japan)
P(非C|F1,F2,...)=P(非C|Chinese,Chinese,Chinese,Tokyo,Japan)
分子:
P(C)=3/4 P(非C)=1/4
P(F1,F2,...|C)=P(Chinese,Chinese,Chinese,Tokyo,Japan|C)=(P(Chinese|C))^3*P(Tokyo|C)*P(Japan|C)=(5/8)^3 * 0 * 0 =0
结合实际情况,是由于样本量不足导致的为0,不能等于0,需引入拉普拉斯系数。引入之后的结果:P(Chinese|C)=(5+1)(8+6)=3/7;P(Tokyo|C)=(0+1)(8+6)=1/14;P(Japan|C)=(0+1)(8+6)=1/14。因此得出P(F1,F2,...|C),同理可得P(非C|F1,F2,...)。
(6)朴素贝叶斯算法的API
sklearn.naive_bayes.MultinomialNB(alpha= 1.0)
朴素贝叶斯分类
alpha:拉普拉斯平滑系数
(7)朴素贝叶斯算法的示例如下:(20类新闻分类)
from sklearn.model_selection import train_test_split
from sklearn.datasets import fetch_20newsgroups
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.naive_bayes import MultinomialNB
def nb_news():
"""
用朴素贝叶斯算法对新闻进行分类
:return:
"""
# 1)获取数据
news = fetch_20newsgroups(subset="all")
# 2)划分数据集
x_train, x_test, y_train, y_test = train_test_split(news.data, news.target)
# 3)特征工程:文本特征抽取-tfidf
transfer = TfidfVectorizer()
x_train = transfer.fit_transform(x_train)
x_test = transfer.transform(x_test)
# 4)朴素贝叶斯算法预估器流程
estimator = MultinomialNB()
estimator.fit(x_train, y_train)
# 5)模型评估
# 方法1:直接比对真实值和预测值
y_predict = estimator.predict(x_test)
print("y_predict:\n", y_predict)
print("直接比对真实值和预测值:\n", y_test == y_predict)
# 方法2:计算准确率
score = estimator.score(x_test, y_test)
print("准确率为:\n", score)
return None
if __name__ == "__main__":
# 代码11:用朴素贝叶斯算法对新闻进行分类
nb_news()
3.5 决策树
(1)什么是决策树:决策树的思想是如何高效迅速地进行决策,决策是有顺序的,意味着特征是有先后顺序的,哪一个特征更有利于高效迅速地决策,如何知道哪个特征更“重要”,就是决策树解决的问题。
(2)决策树分类原理:如何快速找到特征的先后顺序,需要引入信息熵和信息增益。
①什么是信息熵:香农给“信息”的定义——消除随机不确定性的东西。如何去衡量消除不确定性的大小——信息量的计算——用信息熵。信息熵公式如下,(n是目标值类别的种类)。
②什么是信息增益:特征A对训练集D的信息增益g(D,A),定义为集合D的信息熵H(D)与特征A给定条件下D的信息条件熵H(D|A)之差,即信息增益的公式为:
信息熵的计算:(表示属于某个类别的样本数)
条件熵的计算:(n表示特征A的特征值种类的数量)
(3)决策树的API:
sklearn.tree.DecisionTreeClassfifier(criterion='gini', max_depth=None, random_state=None)
决策树分类器
criterion:默认是'gini'系数,也可以选择信息增益的熵'entropy'
max_depth:树的深度大小
random_state:随机数种子
(4)决策树可视化:(分为两步)
①保存树的结构到dot文件
sklearn.tree.export_graphviz() 该函数能够导出DOT格式
tree.export_grapgviz(estimator, out_file='tree.dot', feature_names=['',''])
②网站显示树的结构
http://webgraphviz.com/
打开网站,把dot文件内容粘贴进去,就可以生成树。
(5)决策树的示例如下:(对鸢尾花进行分类)
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier, export_graphviz
def decision_iris():
"""
用决策树对鸢尾花进行分类
:return:
"""
# 1)获取数据集
iris = load_iris()
# 2)划分数据集
x_train, x_test, y_train, y_test = train_test_split(iris.data, iris.target, random_state=22)
# 3)决策树预估器
estimator = DecisionTreeClassifier(criterion="entropy")
estimator.fit(x_train, y_train)
# 4)模型评估
# 方法1:直接比对真实值和预测值
y_predict = estimator.predict(x_test)
print("y_predict:\n", y_predict)
print("直接比对真实值和预测值:\n", y_test == y_predict)
# 方法2:计算准确率
score = estimator.score(x_test, y_test)
print("准确率为:\n", score)
# 可视化决策树(如果不传特征名字的话生成的树可能比较抽象看不懂)
export_graphviz(estimator, out_file="../../datasets/iris_tree.dot", feature_names=iris.feature_names)
return None
if __name__ == "__main__":
# 代码12:用决策树对鸢尾花进行分类
decision_iris()
3.6 集成学习方法之随机森林
(1)什么是集成学习方法:集成学习通过建立几个模型组合来解决单一预测问题。它的工作原理是生成多个分类器、模型,各自独立地学习和做出预测。这些预测最后结合成组合预测,因此由于任何一个单分类预测。
(2)什么是随机森林:随机森林是一个包含多个决策树的分类器,并且其输出的类别是由个别树输出类别的众数而定。随机是训练集随机和特征随机;森林是包含多个决策树的分类器。
(3)随机森林原理过程:
随机包含两个随机,分别是训练集随机、特征随机。
①训练集随机采用bootstrap(随机有放回抽样),从训练集N个样本中随机有放回抽样N个样本。
②特征随机从训练集M个特征中随机抽取m个特征,并且 M >> m,这样可以有降维的效果。
(4)随机森林的API:
sklearn.ensemble.RandomForestClassifier(n_estimators=10, criterion='gini',max_depth=None, bootstrap=True, random_state=None,min_samples_split=2)
···随机森林分类器
···n_estimators: integer,optional (default = 10)森林里的树木数量120,200,300,500,800,1200
···criteria: string,可选(default =“gini")分割特征的测量方法
···max_depth: integer或None,可选(默认=无)树的最大深度5,8,15,25,30
···max_features="auto",每个决策树的最大特征数量
···lf "auto" , then max_features=sqrt(n_features) .
···lf "sqrt", then max_features=sqrt(n_features)(same as "auto").- lf "log2" , then
···max_features=log2(n_features) .
···lf None, then max_features=n_features .
···bootstrap: boolean,optional (default = True)是否在构建树时使用放回抽样
···min_samples_split:节点划分最少样本数
···min_samples_leaf:叶子节点的最小样本数
超参数:n_estimator, max_depth, min_samples_split,min_samples_leaf
(5)随机森林示例如下:(和上述决策树代码12类似)
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
def decision_iris():
"""
用随机森林对鸢尾花进行分类
:return:
"""
# 1)获取数据集
iris = load_iris()
# 2)划分数据集
x_train, x_test, y_train, y_test = train_test_split(iris.data, iris.target, random_state=22)
# 3)决策树预估器
estimator = RandomForestClassifier(n_estimators=10, criterion="entropy", max_depth=None)
estimator.fit(x_train, y_train)
# 4)模型评估
# 方法1:直接比对真实值和预测值
y_predict = estimator.predict(x_test)
print("y_predict:\n", y_predict)
print("直接比对真实值和预测值:\n", y_test == y_predict)
# 方法2:计算准确率
score = estimator.score(x_test, y_test)
print("准确率为:\n", score)
return None
if __name__ == "__main__":
# 代码13:用随机森林对鸢尾花进行分类
decision_iris()
(6)总结
①在当前所有算法中,具有极好的准确率;
②能够有效运行在大数据集上,处理具有高维特征的输入样本,而且不需要降维
③能够评估各个特征在分类问题上的重要性
四、回归与聚类算法
什么是回归?目标值是连续型的数据;什么是聚类?没有目标值的无监督学习。
4.1 线性回归
(1)什么是线性回归?
线性回归(Linear regression)是利用回归方程(函数)对一个或多个自变量(特征值)和因变量(目标值)之间关系进行建模的一种分析方式。只有一个自变量的情况称为单变量回归,多于一个自变量情况的叫做多元回归。
(2)线性回归的公式:(线性模型)
自变量一次幂或者参数一次幂都可以叫线性模型。
线性关系一定是线性模型,但线性模型不一定是线性关系。
(3)损失函数:预测值减真实值的平方,再相加,就是损失函数,也就是最小二乘法。
(4)如何优化损失?(就是如何求出最优的模型参数使得损失最小)
教程中介绍了两种损失优化方法,分别是正规方程和梯度下降。(梯度下降用的更多一些)
如何去选择损失优化方法?根据sklearn官方建议,在回归问题中,小于10万条数据不用梯度下降;小规模数据集用LinearRegression或岭回归,但LinearRegression不能解决拟合问题;大规模数据集用SGDRegressor。
正规方程:
理解:X为特征值矩阵,Y是目标值矩阵,直接求出最好的w
缺点:当特征过多过复杂时,求解速度太慢并且得不到结果。
梯度下降:(Gradient Descent):(迭代)
理解:\alpha为学习率(超参数,需要手动设定),\alpha旁边的整体表示方向沿着这个函数下降的方向找,最后就能找到函数的最低点,然后更新权重值
使用:面对训练数据规模十分庞大的任务,能够找到较好的结果。
梯度下降也分为:GD(梯度下降)、SGD(随机梯度下降)、SAG(随机平均梯度法)
(5)线性回归API
(正规方程)
sklearn.linear_model.LinearRegression(fit_intercept=True)
···通过正规方程优化
···fit_intercept:是否计算偏置
···LinearRegression.coef_:回归系数
···LinearRegression.intercept_:偏置
(梯度下降)
sklearn.linear_model.SGDRegressor(loss="squared_loss", fit_intercept=True,learning_rate ='invscaling', eta0=0.01)
···SGDRegressor类实现了随机梯度下降学习,它支持不同的loss函数和正则化惩罚项来拟合线性回归模型。
···loss:损失类型
······loss=”squared_loss”:普通最小二乘法
···fit_intercept:是否计算偏置
···learning_rate : string, optional
······学习率填充
······'constant': eta = eta0
······'optimal': eta = 1.0 / (alpha * (t+ tO))[default] 'invscaling': eta = eta0 / pow(t, power_t)
·········power_t=o.25:存在父类当中
······对于一个常数值的学习率来说,可以使用learning_rate='constant’,并使用eta0来指定学习率。
···SGDRegressor.coef_:回归系数
···SGDRegressor.intercept_:偏置
(6)回归的性能评估:引入均方误差(Mean Squared Error, MSE)评价机制
为预测值,为真实值
MSE的API
sklearn.metrics.mean_squared_error(y_ture, y_pred)
···均方误差回归损失
···y_true:真实值
···y_pred:预测值
···return:浮点数结果
(6)线性回归示例如下:(波士顿房价预测)
from sklearn.datasets import load_boston
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LinearRegression, SGDRegressor
from sklearn.metrics import mean_squared_error
def linear1():
"""
正规方程的优化方法对波士顿房价进行预测
:return:
"""
# 1)获取数据
boston = load_boston()
# 2)划分数据集
x_train, x_test, y_train, y_test = train_test_split(boston.data, boston.target, random_state=22)
# 3)标准化
transfer = StandardScaler()
x_train = transfer.fit_transform(x_train)
x_test = transfer.transform(x_test)
# 4)预估器
estimator = LinearRegression()
estimator.fit(x_train, y_train)
# 5)得出模型
print("正规方程-权重系数为:\n", estimator.coef_)
print("正规方程-偏置为:\n", estimator.intercept_)
# 6)模型评估
y_predict = estimator.predict(x_test)
print("预测房价:\n", y_predict)
error = mean_squared_error(y_test, y_predict)
print("正规方程-均方误差为:\n", error)
return None
def linear2():
"""
梯度下降的优化方法对波士顿房价进行预测
:return:
"""
# 1)获取数据
boston = load_boston()
print("特征数量:\n", boston.data.shape)
# 2)划分数据集
x_train, x_test, y_train, y_test = train_test_split(boston.data, boston.target, random_state=22)
# 3)标准化
transfer = StandardScaler()
x_train = transfer.fit_transform(x_train)
x_test = transfer.transform(x_test)
# 4)预估器
estimator = SGDRegressor(learning_rate="constant", eta0=0.01, max_iter=10000, penalty="l1")
estimator.fit(x_train, y_train)
# 5)得出模型
print("梯度下降-权重系数为:\n", estimator.coef_)
print("梯度下降-偏置为:\n", estimator.intercept_)
# 6)模型评估
y_predict = estimator.predict(x_test)
print("预测房价:\n", y_predict)
error = mean_squared_error(y_test, y_predict)
print("梯度下降-均方误差为:\n", error)
return None
if __name__ == "__main__":
# 代码14:正规方程的优化方法对波士顿房价进行预测
linear1()
# 代码15:梯度下降的优化方法对波士顿房价进行预测
linear2()
4.2 欠拟合与过拟合
(1)什么是欠拟合与过拟合
欠拟合:训练集和测试集表现都不好,模型太简单;
过拟合:训练集上表现好,测试集表现不好,模型太复杂;
欠拟合原因及解决方法:原因是学习到数据的特征过少,解决办法是增加数据的特征数量;
过拟合原因及解决方法:原因是原始特征过多,存在嘈杂特征,模型过于复杂是因为模型尝试去兼顾各个测试数据点,解决办法是正则化。

过拟合中,怎么样减少高次项的影响?就是正则化。
(2)正则化类别
L2正则化:
作用:可以是其中一些w都很小,都接近于0,消弱某个特征的影响
优点:越小的参数说明模型越简单,越简单的模型则越不容易产生过拟合现象
代表算法:Ridge回归(岭回归)
加入L2正则化后的损失函数:
损失函数+ 惩罚项
惩罚项
m为样本数,n为特征数
L1正则化:
作用:可以使得其中一些w的值直接为0,删除这个特征的影响
代表算法:LASSO回归
损失函数+惩罚项
L1和L2的区别就是惩罚项绝对值和平方的区别
4.3 岭回归
(带L2正则化的线性回归)
(1)岭回归的API
sklearn.linear_model.Ridge(alpha=1.0, fit_intercept=True,solver="auto",normalize=False)
具有l2正则化的线性回归
alpha:正则化力度,也叫,取值:0~11~10
solver:会根据数据自动选择优化方法
sag:如果数据集、特征都比较大,选择该随机梯度下降优化
normalize:数据是否进行标准化
normalize=False:可以在fit之前调用preprocessing.StandardScaler标准化数据
(normalize=True相当于不用先进行标准化了)
Ridge.coef_:回归权重
Ridge.intercept_:回归偏置
Ridge方法相当于SGDRegressor(penalty='l2', loss="squared_loss"),只不过SGDRegressor实现了一个普通的随机梯度下降学习,推荐使用Ridge(实现了SAG)
加上了交叉验证的岭回归
sklearn.linear_model.RidgeCV(BaseRidgeCV, RegressorMixin)
具有l2正则化的线性回归,可以进行交叉验证
coef_:回归系数
(2)岭回归的示例如下:和上述代码13、14类似
from sklearn.datasets import load_boston
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import Ridge
from sklearn.metrics import mean_squared_error
def linear3():
"""
岭回归对波士顿房价进行预测
:return:
"""
# 1)获取数据
boston = load_boston()
print("特征数量:\n", boston.data.shape)
# 2)划分数据集
x_train, x_test, y_train, y_test = train_test_split(boston.data, boston.target, random_state=22)
# 3)标准化
transfer = StandardScaler()
x_train = transfer.fit_transform(x_train)
x_test = transfer.transform(x_test)
# 4)预估器
estimator = Ridge(alpha=0.5, max_iter=10000)
estimator.fit(x_train, y_train)
# 5)得出模型
print("岭回归-权重系数为:\n", estimator.coef_)
print("岭回归-偏置为:\n", estimator.intercept_)
# 6)模型评估
y_predict = estimator.predict(x_test)
print("预测房价:\n", y_predict)
error = mean_squared_error(y_test, y_predict)
print("岭回归-均方误差为:\n", error)
return None
if __name__ == "__main__":
# 代码16:岭回归对波士顿房价进行预测
linear3()
4.4 分类算法-逻辑回归与二分类
(1)什么是逻辑回归?
逻辑回归(Logistic Regression)是机器学习中的一种分类模型,逻辑回归是一种分类算法,名字中带有回归,与线性回归之间有一定的联系。逻辑回归很好适用于二分类问题。
(2)逻辑回归的原理
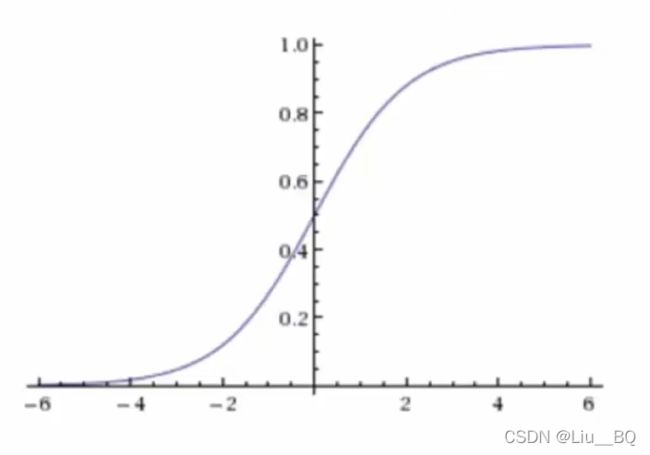
1)逻辑回归的输入,就是一个线性回归的结果
2)激活函数:将逻辑回归的输出代入到sigmoid函数的x
sigmoid函数的值域是[0, 1]
3)输出结果:[0, 1]区间的一个概率值,默认0.5为阈值(大于0.5是一种分类,小于0.5是另一种)
(3)逻辑回归的损失
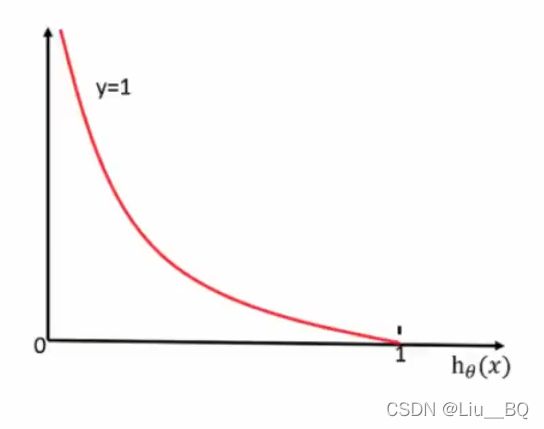
逻辑回归的损失,称之为对数似然损失,公式如下:

y=1,表示真实值属于这个类别,用第一个函数
当真实值为1,映射到sigmoid函数的[0, 1]区间输出越接近1,说明损失值越小,直到0
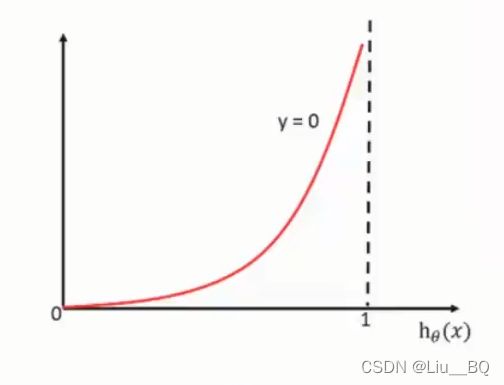
y=0,表示真实值不属于这个类别,用第二个函数
当真实值为0,映射到sigmoid函数的[0, 1]区间输出越接近1,说明损失值越大,直到无穷大
综合完整的损失函数表达式:(等价于上面的分段函数)
(4)逻辑回归的优化
同样使用梯度下降优化算法,去减少损失函数的值。
这样去更新逻辑回归前面对应算法的权重参数,提升原本属于1类别的概率,降低原本是0类别的概率。
(5)逻辑回归API
sklearn.linear_model.LogisticRegression(solver='liblinear' , penalty=12',C =1.0)
solver:优化求解方式(默认开源的liblinear库实现,内部使用了坐标轴下降法来迭代优化损失函数)
sag:根据数据集自动选择,随机平均梯度下降
penalty:正则化的种类
C:正则化力度
默认将类别数量少的当做正例
LogisticRegression方法相当于SGDClassifier(loss="log",penalty=" "),SGDClassifier实现了一个普通的随机梯度下降学习,也支持平均随机梯度下降法(ASGD),可以通过设置average=True。而使用LogisticRegression(实现了SAG).
(6)分类的评估方法
混淆矩阵:在分类任务下,预测结果(Predicted Condition)与正确标记(True Condition)之间存在四种不同组合,构成混淆矩阵(适用于多分类)。
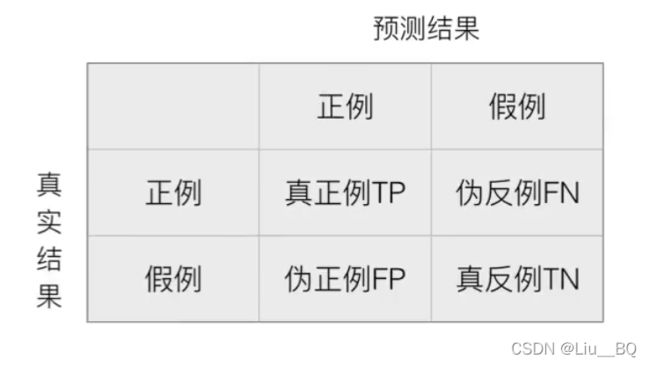
1)精确率(Precision)与召回率(Recall)
精确率:是预测结果为正例样本中真实为正例的比例

召回率:是真实为正例样本中预测结果为正例的比例(查的全,对正样本的区分能力)

F1—score:衡量模型的稳健性
2)分类评估报告API
sklearn.metrics.classification_report(y_true, y_pred, labels=[], target_names=None)
y_true:真实目标值
y_pred:估计器预测目标值
labels:指定类别对应的数字
target_names:目标类别名称
return:每个类别精确率与召回率
3)样本不均衡情况下的评估指标
假设有100个人,如果99个样本为癌症,1个样本非癌症,全部预测为正例(癌症)。
则准确率为99%,召回率为100%,精确率为99%,F1-score为99.497
每个指标都很高,但该模型预测得不准。
为衡量样本不均衡情况下得预测,于是引入另一种评估方式,ROC曲线和AUC指标
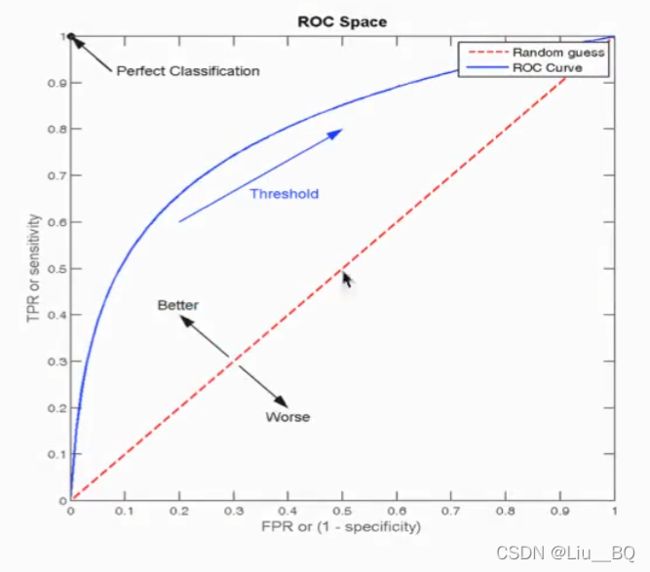
ROC曲线是蓝色的曲线,AUC指标是蓝色曲线所围成的面积
TPR=TP/(TP+FN),是所有真实类别为1得样本中,预测类别为1的比例(也就是召回率)
FPR=FP/(FP+TN),是所有真实类别为0的样本中,预测类别为1的比例
ROC曲线中,当横纵坐标相等时,表示的意义是:对于不论真实类别是1还是0的样本,分类器预测为1的概率是相等的,此时AUC为0.5,此时就代表预测过程是在瞎猜。当纵坐标为1、横坐标为0时,意味着在(0,1)坐标时,真实为1则预测为1,真实为0则预测为0,是完美的分类器。
AUC最小值为0.5,最大值为1,取值越高越好(AUC值域[0, 1],越接近1越好)
AUC=1是完美分类器,采用这个预测模型,不管设定什么阈值都能得出完美预测,绝大多数预测场景下不存在完美分类器。
0.5 也有可能ROC曲线是向下凹的情况,假如以y=x直线为轴对ROC曲线进行翻转,则代表反向预测。AUC指标小于0.5就反着看。 AUC只能用来评价二分类。 AUC非常适合评价样本不平衡中的分类器性能。 4)AUC计算API from sklearn.metircs import roc_auc_score sklearn.metrics.roc_auc_score(y_true, y_score) 计算ROC曲线面积,即AUC值 y_true:每个样本的真是类别,必须为0(反例)、1(正例)标记 y_score:预测得分,可以是正类的估计概率、置信值或者分类器方法的返回值 (1)sklearn模型的保存和加载API from sklearn.externals import joblib 保存:joblib.sump(rf, 'test.pkl') 加载:estimator = joblib,load('test.pkl') (1)无监督学习包含算法:聚类:K-means(K均值聚类);降维:PCA (2)k-means聚类步骤: 1)随机设置K个特征空间内的点作为初始的聚类中心; 2)对于其他每个点计算到K个中心的距离,未知的点选择最近的一个聚类中心点作为标记类别; 3)接着对着标记的聚类中心之后,重新计算出每个聚类的新中心点(平均值) 4)如果计算得出的新中心点 (3)k-means聚类API sklearn.cluster.KMeans(n_clusters=8, init='k_means++') K-means聚类 n_clusters:开始的聚类中心数量 init:初始化方法,默认为'k-means++' labels_:默认标记的类型,可以和真实值比较 (4)k-means性能评估指标 轮廓系数
对于每个点i为已知聚类数据中的样本,b_i为i到其它族群的所有样本的距离最小值,a_i为i到本身簇的距离平均值。最终计算出所有样本点的轮廓系数平均值。 如果b_i>>a_i,趋近于1效果越好; 如果b_i< 轮廓系数的值与是[-1, 1],越趋近于1代表内聚度和分离度都相对较优。 轮廓系数API sklearn.metrics.silhouette_score(X, labels) 计算所有样本的平均轮廓系数 X:特征值 labels:被聚类标记的目标值 (5)k-means总结 特点分析:采用迭代式算法,直观易懂并且非常实用 缺点:容易收敛到局部最优解(多次聚类) 注意:聚类一般做在分类之前 写在后面:教程基本内容就是这样,有时间再扩充一下。4.5 模型保存与加载
4.6 无监督学习-K-means算法