LinkedList源码解读—Java8版本
推荐阅读:Java小白进阶架构师学习路线
【手撕源码系列】LinkedList源码解读—Java8版本
-
- 相关阅读
- 一、LinkedList简介
-
- 1.1 原文
- 1.2 翻译
- 1.3 一语中的
- 1.4 LinkedList和ArrayList的区别
- 1.5 如何选择?
- 二、定义
- 三、数据结构
- 四、域的解读
- 五、构造方法
-
- 5.1 空参构造函数
- 5.2 collection参数构造函数
- 六、核心方法
-
- 6.1 List接口
-
- 6.1.1 add(E e)方法
- 6.1.2 add(int index, E element)方法
- 6.1.3 get(int index)方法
- 6.1.4 remove(int index)方法
- 6.1.5 clear()方法
- 6.1.6 indexOf(Object o)
- 6.2 Duque接口
-
- 6.2.1 addFirst(E e)方法
- 6.2.2 addLast(E e)方法
- 6.2.3 push(E e)方法
- 6.2.4 getFirst()方法
- 6.2.5 getLast()方法
- 6.2.6 peek()方法
- 6.2.7 peekFirst()方法
- 6.2.8 peekLast()方法
- 6.2.9 poll()方法
- 6.2.10 pollFirst()方法
- 6.2.11 pollLast()方法
- 6.2.12 pop()方法
- 6.2.13 push(E e)方法
- 6.3 其他
-
- 6.3.1 removeFirstOccurrence(Object o)
- 6.3.2 removeLastOccurrence(Object o)
- 6.3.3 clone()
- 6.3.4 toArray()
- 6.3.5 toArray(T[`] a)
- 6.3.6 writeObject(java.io.ObjectOutputStream s)
- 6.3.7 readObject(java.io.ObjectInputStream s)
- 6.3.8 迭代器
相关阅读
- ArrayList源码解读—Java8版本
- 深入浅出fail-fast机制
一、LinkedList简介
LinkedList顶部有一段很长的注释,大概的介绍了LinkedList。
1.1 原文
/**
* Doubly-linked list implementation of the {@code List} and {@code Deque}
* interfaces. Implements all optional list operations, and permits all
* elements (including {@code null}).
*
* All of the operations perform as could be expected for a doubly-linked
* list. Operations that index into the list will traverse the list from
* the beginning or the end, whichever is closer to the specified index.
*
*
Note that this implementation is not synchronized.
* If multiple threads access a linked list concurrently, and at least
* one of the threads modifies the list structurally, it must be
* synchronized externally. (A structural modification is any operation
* that adds or deletes one or more elements; merely setting the value of
* an element is not a structural modification.) This is typically
* accomplished by synchronizing on some object that naturally
* encapsulates the list.
*
* If no such object exists, the list should be "wrapped" using the
* {@link Collections#synchronizedList Collections.synchronizedList}
* method. This is best done at creation time, to prevent accidental
* unsynchronized access to the list:
* List list = Collections.synchronizedList(new LinkedList(...));
*
* The iterators returned by this class's {@code iterator} and
* {@code listIterator} methods are fail-fast: if the list is
* structurally modified at any time after the iterator is created, in
* any way except through the Iterator's own {@code remove} or
* {@code add} methods, the iterator will throw a {@link
* ConcurrentModificationException}. Thus, in the face of concurrent
* modification, the iterator fails quickly and cleanly, rather than
* risking arbitrary, non-deterministic behavior at an undetermined
* time in the future.
*
*
Note that the fail-fast behavior of an iterator cannot be guaranteed
* as it is, generally speaking, impossible to make any hard guarantees in the
* presence of unsynchronized concurrent modification. Fail-fast iterators
* throw {@code ConcurrentModificationException} on a best-effort basis.
* Therefore, it would be wrong to write a program that depended on this
* exception for its correctness: the fail-fast behavior of iterators
* should be used only to detect bugs.
*
*
This class is a member of the
*
* Java Collections Framework.
*
* @author Josh Bloch
* @see List
* @see ArrayList
* @since 1.2
* @param the type of elements held in this collection
*/
public class LinkedList<E>
extends AbstractSequentialList<E>
implements List<E>, Deque<E>, Cloneable, java.io.Serializable
{
...
}
1.2 翻译
双向链表是实现了List和Deque接口。实现了所有List的操作和允许值为Null。
所有的操作执行都与双向链表相似。操作索引将遍历整个链表,至于是从头开始遍历还是从尾部开始遍历取决于索引的下标距离哪个比较近。
需要注意的是这个方法不是同步的方法,需要同步的应用(ConcurrentLinkedDeque高效的队列),如果多个线程同时操作LinkedList实例和至少有一个线程修改list的结构,必须在外部加同步操作。关于结构性操作可以看前面的HashMap的介绍。这个同步操作通常是压缩在某些对象头上面。(synchronized就是存储在对象头上面。)
如果对象头不存在这样的对象,这个列表应该使用{@link Collections#synchronizedList Collections.synchronizedList}工具来封装,这个操作最好是在创建List之前完成,防止非同步的操作。List list = Collections.synchronizedList(new ArrayList(…));但是一般不用这个方法,而是用JUC包下的ConcurrentLinkedDeque更加高效,(因为这个底层采用的是CAS操作)
快速失败机制(…好像在集合容器下面都有这个机制来抛出异常…)
当一个list被多个线程成同时修改的时候会抛出异常。但是不能用来保证线程安全。
所以在多线程环境下,还是要自己加锁或者采用JUC包下面的方法来保证线程安全, 而不能依靠fail-fast机制抛出异常,这个方法只是用来检测bug。
整个说明文档其实是跟ArrayList差不多,只不过是他们的底层实现的数据结构不一样而已,可以参考对比ArrayList。【【手撕源码系列】ArrayList源码解读—Java8版本】
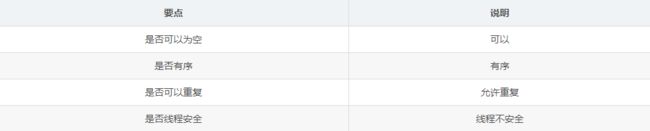
1.3 一语中的
1.4 LinkedList和ArrayList的区别
顺序插入的速度ArrayList会快些,LinkedList的速度会稍慢一些。因为ArrarList只是在指定的位置上赋值即可,而LinkedList则需要创建Node对象,并且需要建立前后关联,如果对象较大的话,速度会慢一些。
LinkedList的占用的内存空间要大一些。
数组遍历的方式ArrayList推荐使用for循环,而LinkedList则推荐使用foreach,如果使用for循环,效率将会很慢。
一般我们这样认为:ArrarList查询和获取快,修改和删除慢;LinkedList修改和删除快,查询和获取慢。其实这样说不准确的。
LinkedList做插入、删除的时候,慢在寻址,快在只需要改变前后Entry的引用地址;
ArrayList做插入、删除的时候,慢在数组元素的批量copy,快在寻址。
所以,如果待插入、删除的元素是在数据结构的前半段尤其是非常靠前的位置的时候,LinkedList的效率将大大快过ArrayList,因为ArrayList将批量copy大量的元素;越往后,对于LinkedList来说,因为它是双向链表,所以在第2个元素后面插入一个数据和在倒数第2个元素后面插入一个元素在效率上基本没有差别,但是ArrayList由于要批量copy的元素越来越少,操作速度必然追上乃至超过LinkedList。
1.5 如何选择?
1、如果你十分确定你插入、删除的元素是在前半段,使用LinkedList
2、如果你十分确定你删除、删除的元素后半段,使用ArrayList
3、如果你上面的两点不确定,建议你使用LinkedList
说明:
其一、LinkedList整体插入、删除的执行效率比较稳定,没有ArrayList这种越往后越快的情况;
其二、插入元素的时候,弄得不好ArrayList就要进行一次扩容,而ArrayList底层数组扩容是一个既消耗时间又消耗空间的操作,所以综合来看就知道选择哪个类型的list
二、定义
我们先来看看LinkedList的定义:
public class LinkedList<E>
extends AbstractSequentialList<E>
implements List<E>, Deque<E>, Cloneable, java.io.Serializable
LinkedList的类结构图:
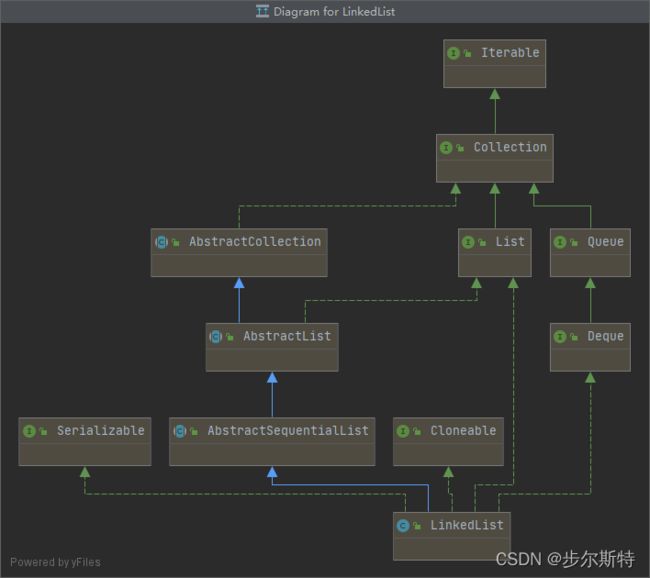
如何查看类的完整结构图可以参考如下文章:
IDEA如何查看类的完整结构图
从图中,我们可以看出:
继承了AbstractSequentialList抽象类:在遍历LinkedList的时候,官方更推荐使用顺序访问,也就是使用我们的迭代器。(因为LinkedList底层是通过一个链表来实现的)(虽然LinkedList也提供了get(int index)方法,但是底层的实现是:每次调用get(int index)方法的时候,都需要从链表的头部或者尾部进行遍历,每一的遍历时间复杂度是O(index),而相对比ArrayList的底层实现,每次遍历的时间复杂度都是O(1)。所以不推荐通过get(int index)遍历LinkedList。至于上面的说从链表的头部后尾部进行遍历:官方源码对遍历进行了优化:通过判断索引index更靠近链表的头部还是尾部来选择遍历的方向)(所以这里遍历LinkedList推荐使用迭代器)。
实现了List接口。(提供List接口中所有方法的实现)
实现了Cloneable接口,它支持克隆(浅克隆),底层实现:LinkedList节点并没有被克隆,只是通过Object的clone()方法得到的Object对象强制转化为了LinkedList,然后把它内部的实例域都置空,然后把被拷贝的LinkedList节点中的每一个值都拷贝到clone中。(后面有源码解析)
实现了Deque接口。实现了Deque所有的可选的操作。
实现了Serializable接口。表明它支持序列化。(和ArrayList一样,底层都提供了两个方法:readObject(ObjectInputStreamo)、writeObject(ObjectOutputStream o),用于实现序列化,底层只序列化节点的个数和节点的值)。
三、数据结构

如图所示,LinkedList底层通过数链表实现。
四、域的解读
// LinkedList节点个数
transient int size = 0;
/**
* Pointer to first node. 指向头结点
* Invariant: (first == null && last == null) ||
* (first.prev == null && first.item != null)
*/
transient Node<E> first;
/**
* Pointer to last node. 指向尾节点
* Invariant: (first == null && last == null) ||
* (last.next == null && last.item != null)
*/
transient Node<E> last;
LinkedList内部有两个引用,一个first,一个last,分别用于指向链表的头和尾,另外有一个size,用于标识这个链表的长度,而它的接的引用类型是Node,这是他的一个内部类:
private static class Node<E> {
E item;
Node<E> next;
Node<E> prev;
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
Node 类是LinkedList中的私有内部类,LinkedList中就是通过Node来存储集合中的元素。
E :节点的值。
Node next:当前节点的后一个节点的引用(可以理解为指向当前节点的后一个节点的指针)
Node prev:当前节点的前一个节点的引用(可以理解为指向当前节点的前一个节点的指针)
五、构造方法
LinkedList提供了两个构造器,ArrayList比它多提供了一个通过设置初始化容量来初始化类。
LinkedList不提供该方法的原因:因为LinkedList底层是通过链表实现的,每当有新元素添加进来的时候,都是通过链接新的节点实现的,也就是说它的容量是随着元素的个数的变化而动态变化的。而ArrayList底层是通过数组来存储新添加的元素的,所以我们可以为ArrayList设置初始容量(实际设置的数组的大小)。
相关阅读:【手撕源码系列】ArrayList源码解读—Java8版本
5.1 空参构造函数
/**
* Constructs an empty list.
*/
public LinkedList() {
}
5.2 collection参数构造函数
public LinkedList(Collection<? extends E> c) {
this();
// 将集合添加到链表中去
addAll(c);
}
public boolean addAll(Collection<? extends E> c) {
// 从链表尾巴开始集合中元素
return addAll(size, c);
}
public boolean addAll(int index, Collection<? extends E> c) {
// 1.添加位置的下标的合理性检查
checkPositionIndex(index);
// 2.将集合转换为Object[]数组对象
Object[] a = c.toArray();
int numNew = a.length;
if (numNew == 0)
return false;
// 3.得到插入位置的前继节点和后继节点
Node<E> pred, succ;
if (index == size) {
// 从尾部添加的情况:前继节点是原来的last节点;后继节点是null
succ = null;
pred = last;
} else {
// 从指定位置(非尾部)添加的情况:前继节点就是index位置的节点,后继节点是index位置的节点的前一个节点
succ = node(index);
pred = succ.prev;
}
// 4.遍历数据,将数据插入
for (Object o : a) {
@SuppressWarnings("unchecked") E e = (E) o;
// 创建节点
Node<E> newNode = new Node<>(pred, e, null);
if (pred == null)
// 空链表插入情况:
first = newNode;
else
// 非空链表插入情况:
pred.next = newNode;
// 更新前置节点为最新插入的节点(的地址)
pred = newNode;
}
if (succ == null) {
// 如果是从尾部开始插入的,则把last置为最后一个插入的元素
last = pred;
} else {
// 如果不是从尾部插入的,则把尾部的数据和之前的节点连起来
pred.next = succ;
succ.prev = pred;
}
size += numNew; // 链表大小+num
modCount++; // 修改次数加1
return true;
}
六、核心方法
6.1 List接口
6.1.1 add(E e)方法
// 作用:将元素添加到链表尾部
public boolean add(E e) {
linkLast(e);
return true;
}
void linkLast(E e) {
final Node<E> l = last; // 获取尾部元素
final Node<E> newNode = new Node<>(l, e, null); // 以尾部元素为前继节点创建一个新节点
last = newNode; // 更新尾部节点为需要插入的节点
if (l == null)
// 如果空链表的情况:同时更新first节点也为需要插入的节点。(也就是说:该节点既是头节点first也是尾节点last)
first = newNode;
else
// 不是空链表的情况:将原来的尾部节点(现在是倒数第二个节点)的next指向需要插入的节点
l.next = newNode;
size++; // 更新链表大小和修改次数,插入完毕
modCount++;
}
6.1.2 add(int index, E element)方法
// 作用:在指定位置添加元素
public void add(int index, E element) {
// 检查插入位置的索引的合理性
checkPositionIndex(index);
if (index == size)
// 插入的情况是尾部插入的情况:调用linkLast()解释如上。
linkLast(element);
else
// 插入的情况是非尾部插入的情况(中间插入):linkBefore()见下面。
linkBefore(element, node(index));
}
private void checkPositionIndex(int index) {
if (!isPositionIndex(index))
throw new IndexOutOfBoundsException(outOfBoundsMsg(index));
}
private boolean isPositionIndex(int index) {
return index >= 0 && index <= size;
}
void linkBefore(E e, Node<E> succ) {
// assert succ != null;
final Node<E> pred = succ.prev; // 得到插入位置元素的前继节点
final Node<E> newNode = new Node<>(pred, e, succ); // 创建新节点,其前继节点是succ的前节点,后接点是succ节点
succ.prev = newNode; // 更新插入位置(succ)的前置节点为新节点
if (pred == null)
// 如果pred为null,说明该节点插入在头节点之前,要重置first头节点
first = newNode;
else
// 如果pred不为null,那么直接将pred的后继指针指向newNode即可
pred.next = newNode;
size++;
modCount++;
}
6.1.3 get(int index)方法
public E get(int index) {
// 元素下表的合理性检查
checkElementIndex(index);
// node(index)真正查询匹配元素并返回
return node(index).item;
}
// 作用:查询指定位置元素并返回
Node<E> node(int index) {
// assert isElementIndex(index);
// 如果索引位置靠链表前半部分,从头开始遍历
if (index < (size >> 1)) {
Node<E> x = first;
for (int i = 0; i < index; i++)
x = x.next;
return x;
} else {
// 如果索引位置靠链表后半部分,从尾开始遍历
Node<E> x = last;
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
6.1.4 remove(int index)方法
// 作用:移除指定位置的元素
public E remove(int index) {
// 移除元素索引的合理性检查
checkElementIndex(index);
// 将节点删除
return unlink(node(index));
}
E unlink(Node<E> x) {
// assert x != null;
final E element = x.item; // 得到指定节点的值
final Node<E> next = x.next; // 得到指定节点的后继节点
final Node<E> prev = x.prev; // 得到指定节点的前继节点
// 如果prev为null表示删除是头节点,否则就不是头节点
if (prev == null) {
first = next;
} else {
prev.next = next;
x.prev = null; // 置空需删除的指定节点的前置节点(null)
}
// 如果next为null,则表示删除的是尾部节点,否则就不是尾部节点
if (next == null) {
last = prev;
} else {
next.prev = prev;
x.next = null; // 置空需删除的指定节点的后置节点
}
// 置空需删除的指定节点的值
x.item = null;
size--; // 数量减1
modCount++;
return element;
}
6.1.5 clear()方法
// 清空链表
public void clear() {
// Clearing all of the links between nodes is "unnecessary", but:
// - helps a generational GC if the discarded nodes inhabit
// more than one generation
// - is sure to free memory even if there is a reachable Iterator
// 进行for循环,进行逐条置空;直到最后一个元素
for (Node<E> x = first; x != null; ) {
Node<E> next = x.next;
x.item = null;
x.next = null;
x.prev = null;
x = next;
}
// 置空头和尾为null
first = last = null;
size = 0;
modCount++;
}
6.1.6 indexOf(Object o)
// 返回元素在链表中的索引,如果不存在则返回-1
public int indexOf(Object o) {
int index = 0;
// 如果元素为null,进行如下循环判断
if (o == null) {
for (Node<E> x = first; x != null; x = x.next) {
if (x.item == null)
return index;
index++;
}
} else {
// 元素不为null.进行如下循环判断
for (Node<E> x = first; x != null; x = x.next) {
if (o.equals(x.item))
return index;
index++;
}
}
return -1;
}
6.2 Duque接口
6.2.1 addFirst(E e)方法
// 作用:在链表头插入指定元素
public void addFirst(E e) {
linkFirst(e);
}
private void linkFirst(E e) {
final Node<E> f = first; // 获取头部元素
final Node<E> newNode = new Node<>(null, e, f); // 创建新的头部元素(原来的头部元素变成了第二个)
first = newNode;
// 链表头部为空,(也就是链表为空)
if (f == null)
last = newNode; // 头尾元素都是e
else
f.prev = newNode; // 否则就更新原来的头元素的prev为新元素的地址引用
size++;
modCount++;
}
6.2.2 addLast(E e)方法
// 作用:在链表尾部添加元素e
public void addLast(E e) {
// 上面已讲解过,参考上面。add()方法
linkLast(e);
}
6.2.3 push(E e)方法
// 作用:往链表头部添加元素e
public void push(E e) {
addFirst(e);
}
6.2.4 getFirst()方法
// 作用:得到头元素
public E getFirst() {
final Node<E> f = first;
if (f == null)
throw new NoSuchElementException();
return f.item;
}
6.2.5 getLast()方法
// 作用:得到尾部元素
public E getLast() {
final Node<E> l = last;
if (l == null)
throw new NoSuchElementException();
return l.item;
}
6.2.6 peek()方法
// 作用:返回头元素,并且不删除。如果不存在也不错,返回null
public E peek() {
final Node<E> f = first;
return (f == null) ? null : f.item;
}
6.2.7 peekFirst()方法
// 作用:返回头元素,并且不删除。如果不存在也不错,返回null
public E peekFirst() {
final Node<E> f = first;
return (f == null) ? null : f.item;
}
6.2.8 peekLast()方法
// 作用:返回尾元素,如果为null,则就返回null
public E peekLast() {
final Node<E> l = last;
return (l == null) ? null : l.item;
}
6.2.9 poll()方法
// 作用:返回头节点元素,并删除头节点。并将下一个节点设为头节点。
public E poll() {
final Node<E> f = first;
return (f == null) ? null : unlinkFirst(f);
}
6.2.10 pollFirst()方法
// 作用:返回头节点,并删除头节点,并将下一个节点设为头节点。
public E pollFirst() {
final Node<E> f = first;
return (f == null) ? null : unlinkFirst(f);
}
6.2.11 pollLast()方法
// 作用:返回尾节点,并且将尾节点删除,并将尾节点的前一个节点置为尾节点
public E pollLast() {
final Node<E> l = last;
return (l == null) ? null : unlinkLast(l);
}
6.2.12 pop()方法
// 作用:删除头节点,如果头结点为null.则抛出异常
public E pop() {
return removeFirst();
}
public E removeFirst() {
final Node<E> f = first;
if (f == null)
throw new NoSuchElementException();
return unlinkFirst(f);
}
6.2.13 push(E e)方法
// 作用:将元素添加到头部
public void push(E e) {
addFirst(e);
}
public void addFirst(E e) {
linkFirst(e);
}
private void linkFirst(E e) {
final Node<E> f = first;
final Node<E> newNode = new Node<>(null, e, f);
first = newNode;
if (f == null)
last = newNode;
else
f.prev = newNode;
size++;
modCount++;
}
6.3 其他
6.3.1 removeFirstOccurrence(Object o)
//移除第一次出现的元素。(从前向后遍历集合)
//底层调用remove()方法,通过从前向后遍历集合。
public boolean removeFirstOccurrence(Object o) {
return remove(o);
}
6.3.2 removeLastOccurrence(Object o)
//移除第一次出现的元素。(从后向前遍历集合)
public boolean removeLastOccurrence(Object o) {
if (o == null) {
for (Node<E> x = last; x != null; x = x.prev) {
if (x.item == null) {
unlink(x);
return true;
}
}
} else {
for (Node<E> x = last; x != null; x = x.prev) {
if (o.equals(x.item)) {
unlink(x);
return true;
}
}
}
return false;
}
6.3.3 clone()
克隆方法:
首先获取从辅助方法返回的LinkedList对象,接着把该对象的所有域都设置为初始值。
然后把LinkedList中所有的内容复制到返回的对象中。
public Object clone() {
LinkedList<E> clone = superClone();
// Put clone into "virgin" state
clone.first = clone.last = null;
clone.size = 0;
clone.modCount = 0;
// Initialize clone with our elements
for (Node<E> x = first; x != null; x = x.next)
clone.add(x.item);
return clone;
}
克隆的辅助方法:
直接调用超类的clone()方法,然后把得到的Object对象转换为LinkedList类型。
Object的clone()方法是本地方法(通过native修饰)
@SuppressWarnings("unchecked")
private LinkedList<E> superClone() {
try {
return (LinkedList<E>) super.clone();
} catch (CloneNotSupportedException e) {
throw new InternalError(e);
}
}
6.3.4 toArray()
转化为数组:(没有参数)
通过遍历LinkedList中的每个节点,把值添加到数组中。
public Object[] toArray() {
Object[] result = new Object[size];
int i = 0;
for (Node<E> x = first; x != null; x = x.next)
result[i++] = x.item;
return result;
}
6.3.5 toArray(T[`] a)
/**
* 泛型方法
* 在方法内部,如果a的长度小于集合的大小的话,
* 通过反射创建一个和集合同样大小的数组,
* 接着把集合中的所有元素添加到数组中。
* 如果数组的元素的个数大于集合中元素的个数,则把a[size]设置
* 为空。
* 我估计代码设计者这样设计代码的目的是为了能够通过返回值观察到
* LinkedList集合中原来的元素有哪些。通过null把集合中的元素凸显出来。
* ArrayList中也有同样的考虑和设计。
*
* @param a
* @param
* @return
*/
public <T> T[] toArray(T[] a) {
if (a.length < size)
a = (T[])java.lang.reflect.Array.newInstance(
a.getClass().getComponentType(), size);
int i = 0;
Object[] result = a;
for (Node<E> x = first; x != null; x = x.next)
result[i++] = x.item;
if (a.length > size)
a[size] = null;
return a;
}
6.3.6 writeObject(java.io.ObjectOutputStream s)
将LinkedList写入到流中。(也就是把LinkedList状态保存到流中)(序列化)
private void writeObject(java.io.ObjectOutputStream s)
throws java.io.IOException {
// Write out any hidden serialization magic
s.defaultWriteObject();
// Write out size
s.writeInt(size);
// Write out all elements in the proper order.
for (Node<E> x = first; x != null; x = x.next)
s.writeObject(x.item);
}
6.3.7 readObject(java.io.ObjectInputStream s)
从流中把LinkedList读取出来(读取流,拼装成LinkedList)(反序列化)
@SuppressWarnings("unchecked")
private void readObject(java.io.ObjectInputStream s)
throws java.io.IOException, ClassNotFoundException {
// Read in any hidden serialization magic
s.defaultReadObject();
// Read in size
int size = s.readInt();
// Read in all elements in the proper order.
for (int i = 0; i < size; i++)
linkLast((E)s.readObject());
}
6.3.8 迭代器
①返回ListIterator迭代器:
public ListIterator<E> listIterator(int index) {
checkPositionIndex(index);
return new ListItr(index);
}
②返回Iterator迭代器:
public Iterator<E> descendingIterator() {
return new DescendingIterator();
}
LinkedList的迭代器也是提供了两种,一种是指提供向后遍历的Iterator,另一种是List的专有迭代器ListIterator。
推荐阅读:Java小白进阶架构师学习路线