我们加入房屋的卧室数量作为该例的另一特征量:

这样,是一个二维矢量,例如代表该训练集中第个房屋的住房面积,而代表其卧室数量。
我们使用关于的线性函数去估计:
为了简化公式,我们约定 (intercept term),因此有:
等式最右部分我们将和均视为矢量,表示输入变量的数量(不包含)。
为了衡量对每一,与相应的的逼近程度,我们定义代价函数(cost function):
(一)概率解释
当我们面对一个回归问题,为什么线性回归,特别地,最小均方代价函数是合理的选择?
我们假定目标变量与其输入有如下等式关系:
,
这里,是误差项(error term),捕捉未建模效应(例如,有许多特征量与房价相关,但我们未在线性回归中考虑他们),或随机噪声。让我们进一步假设是服从均值为0,方差为的高斯分布的独立同分布变量。即~,则的概率分布为:
,
故 。
似然函数: .
根据之前对的独立性假设,
现在,给定这个关于和的概率模型,如何去获得参数的值?根据最大似然估计法,通过选择参数使得样本数据有最大概率。因此,我们应选择参数去最大化。
为了简化推导,我们选择最大化对数似然函数(log likelihood function):
因此,最大化即最小化
,
即为我们最初的最小均方代价函数。
结论:基于之前的概率假设,线性回归法即是找到的最大似然估计值。
(二)最小均方算法(LMS algorithm)
我们想要通过选取去最小化,所以,让我们使用一个搜索算法,从的“初始猜测值”开始,不断改变的值去减少,直到得到收敛值,使得最小。我们考虑梯度下降算法(gradient descent algorithm):
(更新对所有同时进行。)这里,称为学习率(learning rate)。
为了完成这个算法,我们需要计算出等式右边的偏导数,当只有一个训练例子时,有:
。
对一个训练例子,我们给定以下更新规律:
,
该规律被称为LMS更新规则(LMS代表“least mean squares”最小均方根)。
当训练集中不止一个例子时,有两种方法修改LMS更新规则,
(1)批处理梯度下降算法(Batch Gradient Descent)
Repeat until convergence
(for every )

随着迭代次数的增加,每次的迭代变化会很小,可以设定一阈值,当两次迭代小于该阈值时,就停止迭代,得到的结果也近似最优解。
(2)随机梯度下降(stochastic gradient descent also incremental gradient descent)
Loop
for to ,
(for every ).
批处理梯度下降在执行每一次迭代时,都需要遍历整个训练集,当m较大时,算法会非常耗时,而随机梯度下降算法只需对当前传入的例子进行更新。值得注意的是,随机梯度下降算法永远不会在最优值收敛,参数的值会在的最小值附近持续震荡,但是实际上,在最优值附近的值都是对最优值的合理估计。当训练集较大时,我们一般都会优先选择随机梯度算法。
(三)正规方程组(the normal equations)
定义设计矩阵(design matrix)X是一个m * n的矩阵(如果我们包含截距项,则为m * n+1矩阵),在其行中包含训练例子的输入值:

令为包含所有训练集的目标值的n维向量:

因为,我们可以很容易的得到:

由于,则有
因此:

为了最小化,我们要使得其导数为0,所以我们得到正规方程组(normal equations):
因此,使得最小的值为:
。
(四)牛顿法(Newton's method)
假设我们有一函数,我们希望找到使得(为实数),牛顿法的更新方法如下:
牛顿法为我们提供了让的方法,如何利用这种方法去得到函数的最大值呢?当取得最大值时,有,所以令,所以:
推广到为高维次的情况有:

其中称为Hessian矩阵,。
通常而言,牛顿法比批处理梯度下降法需要更少的迭代次数,但由于牛顿法都需要计算n*n阶Hessian矩阵及其逆矩阵,牛顿法的每一次迭代会比梯度下降更加费时。当m不是太大时,一般而言使用牛顿法会更快。
(五)局部加权线性回归(Locally weighted linear regression)
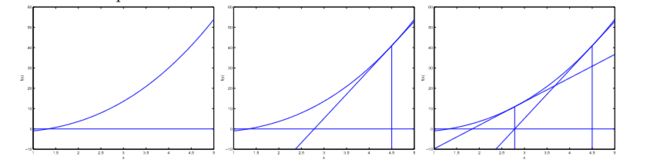
让我们考虑用预测,最左图是使用去匹配训练集,可以发现匹配效果不是太好。

我们额外再加入一个特征量,令,如中间那幅图所见,似乎参数越多,匹配的效果越好。当使用5个参数,,进行匹配时,结果如最右图所示,虽然曲线完美的通过了每一个数据点,我们依然不能说它是在不同住房面积()下,对房屋价格()的合理预测器。我们称左图的情况为欠拟合(underfitting),右图的情况为过拟合(overfitting)。
上述例子说明,特征量的选择很大程度上决定了学习算法的表现。本部分将讨论局部线性加权回归算法(locally weighted linear regression, LWR),使得特征量的选择不那么重要。
在原始的线性回归算法中,为了得到在查询点预测值,我们会:
1、选取使得最小的值。
2、输出。
而在局部加权线性回归中:
1、选取使得最小的值。
2、输出。
这里,是非负权值(weights)。显然,当对应的很大时,在选择时会很难使得很小,如果很小,将可以忽略不计。
权值的表达式为:
如果很小,那么会非常接近1,如果很大,那么会很小。因此,可以这样说,在局部构成了线性回归算法,对于的学习,主要依靠于查询点附近的值。
虽然的形式与高斯分布十分相似,但与高斯分布并无关系,因为中并无随机变量。
局部线性加权回归是一种非参数(non-parametric)学习算法,而之前的未加权线性回归算法是一种参数(parametric)学习算法,所谓参数学习算法,它有固定明确的参数去匹配训练集。一旦参数确定,我们就不需要保留训练集中的数据。相反,当使用局部线性加权回归进行·预测时,每进行一次预测,就要重新学习一次,我们需要一直保留整个训练集。“非参数”(non-parametric)大概指的是为了学习所需要的保存的数据随着训练集的大小线性增长。