纪念碑旁有一家破旧的电影院,往北走五百米就是南京火车西站
每天都有外地人在直线和曲线之间迷路,气喘吁吁眼泪模糊奔跑 跌倒 奔跑
秋林龙虾换了新的地方,三十二路还是穿过挹江门
高架桥修了新的隧道,走来走去走不出 我的盐仓桥
来到城市已经八百九十六天,热河路一直是相同的容颜
偶尔有干净的潘西路过,他不会说你好 再见
tensorflow游乐场
TensorFlow游乐场是一个通过网页浏览器就可以训练简单神经网络
并实现了可视化训练过程的工具。
经网络解决一个分类问题大致可以分为:
1.提取特征向量作为输入,比如说本例子中零件的长度和质量。
2.定义神经网络结构。包括隐藏层数,激活函数等等。
3.通过训练利用反响传播算法不断优化权重的值,使之达到最合理水平。
4.使用训练好的神经网络来预测未知数据,这里训练好的网络就是指权重达到最优的情况。
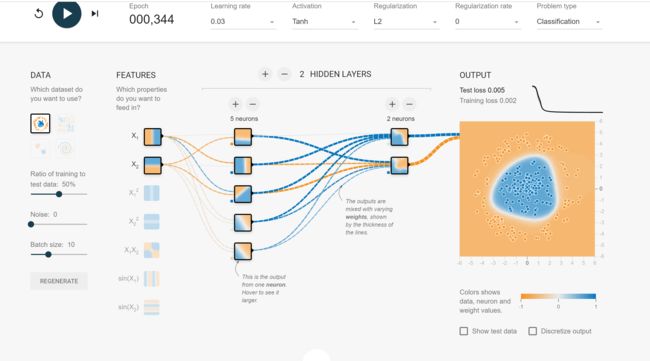
我玩了一会发现:这不就是我们做的实验一吗!!!怎么会有这么好用的工具!!可以选择分类和回归,可以选择输入数据的类型,我的天哪简直太好玩了啊!!
numpy.random.random(20,1)随机产生20个浮点数,每个在(0,1)取值
numpy.zeros(5) (5,dtype = np.int) (2,1) (2,2)
numpy.zeros((2,1)) 2*1矩阵
numpy.dot(A,B)
线性代数上的矩阵相乘,生成矩阵(1,1)为A第一行乘B第一列
A * B or numpy.multiply(A,B)
编程上的矩阵相乘,AB两矩阵对应位置元素相乘,生成矩阵(1,1)为A(1,1)乘B(1,1)
上周用到的反向传播算法,一共分为三个步骤:
前向计算每个神经元的输出值aj
反向计算每个神经元的误差项deltaj,为损失函数Loss对该神经元输入的偏导数
计算每个神经元连接权重wji(from i to j)的梯度,等于ai * deltaj
梯度下降法更新权重

对于卷积神经网络,由于涉及到局部连接、下采样的等操作,影响到了第二步误差项delta的具体计算方法,而权值共享影响了第三步权重w的梯度的计算方法。
numpy实现lenet5实现MNIST手写字符识别
背景知识
LeNet-5是一种典型的非常高效的用来识别手写体数字的卷积神经网络。LeNet-5出自论文Gradient-Based Learning Applied to Document Recognition,是由Yann LeCun提出的,对MNIST数据集的识别准确度可达99.2%。

局部感受野:卷积神经网络把每一个隐藏节点只连接到图像的某个局部区域,从而减少参数训练的数量
共享权值:在卷积神经网络的卷积层中,神经元对应的权值是相同的,由于权值相同,因此可以减少训练的参数量。共享的权值和偏置也被称作卷积核或滤波器
池化:对图像进行卷积之后,通过一个下采样过程,来调整图像的大小
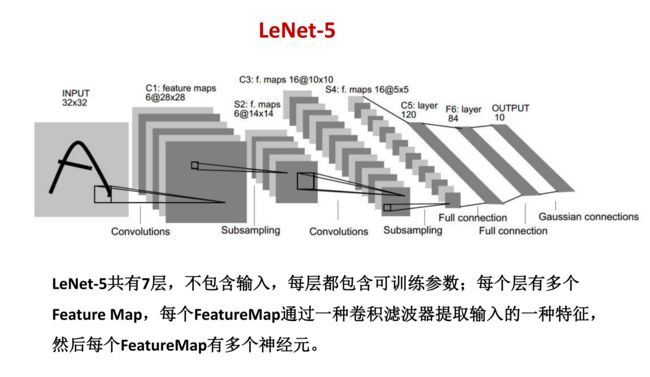
INPUT:输入图像的尺寸统一归一化为32 * 32
C1卷积层:对输入图像进行第一次卷积运算,使用 6 个大小为 5 * 5 的卷积核,得到6个28 * 28的特征图feature map
S2池化层:使用 2 * 2核进行池化,得到了S2,6个14 * 14的特征图(28/2=14)
C3卷积层:第二次卷积,第二次卷积的输出是C3,16个10x10的特征图,卷积核大小是 5 * 5
S4池化层:窗口大小仍然是2*2,共计16个feature map,S4中每个特征图的大小是C3中特征图大小的1/4
C5卷积层:由于S4层的16个图的大小为5x5,与卷积核的大小相同,所以卷积后形成的图的大小为1x1
F6全连接:有84个节点,对应于一个7x12的比特图,-1表示白色,1表示黑色,这样每个符号的比特图的黑白色就对应于一个编码(ASCII编码图)
output全连接:有10个节点,分别代表数字0到9,且如果节点i的值为0,则网络识别的结果是数字i
lenet5可以分为三个部分:
1.网络定义 2.训练部分 3.验证部分
将训练部分与验证部分分开的好处在于,训练部分可以持续输出训练好的模型,验证部分可以每隔一段时间验证模型的准确率;如果模型不好,则需要及时调整网络结构的参数。
LeNet-5 的一些性质:
- 如果输入层不算神经网络的层数,那么 LeNet-5 是一个 7 层的网络。LeNet-5 大约有 60,000 个参数
- 随着网络越来越深,图像的高度和宽度在缩小,与此同时,图像的 channel 数量一直在增加
- 现在常用的 LeNet-5 结构和 Yann LeCun论文中提出的结构在某些地方有区别,比如激活函数的使用,以及输出层一般选择 softmax
MNIST:
MNIST是一个非常有名的手写数字识别数据集,是NIST数据集的一个子集,包含了60000张图片作为训练数据,10000张图片作为测试数据。在MNIST数据集中的每一张图片都代表0~9中的一个数字
初始思路
最初我的实现思路是和之前的全连接神经网络拟合y=sinx一样,将所有的层c1、s2、c3 等等等等封装在一个类里,每一层作为一个方法,里面包含前向与反向传播。
后来发现,层与层之间重复的部分太多,代码复用率太高,例如c1和c3基本是一样的,都是实现了卷积操作。于是果断弃用,换为将卷积层、池化层、全连接层、非线性层每个都单独封装为一个类。这样构建每一层的时候只要初始化类对象就可以。
数据读取

通过glob和struct模块来实现训练集和测试集的读取
glob:kind表示前缀,'t10k' 为测试集,'train'为训练集, .表示当前目录,%s为path和kind代表的字符串,*匹配任意字符,3-ubyte为图片数据集的后缀,返回的为list,[0]表示我们要的是这个list中的第一个文件
struct:pack与unpack 实现python中字节流与其他格式的转换,>II表示解压至少需要8个字节的缓冲区,将bytes文件转换为python数据文件,返回为元组
np.fromfile:按照指定的格式读取数据,对数组的形状做简单的修改
卷积层
初始化:
def __init__(self, shape, output_channels, kernel_size=3, stride=1, method='VALID'):
shape为四维数组,如[64, 28, 28, 1],代表[batchsize, width, height, channels]
output_channels为输出的层数
kernel_size为卷积核的大小,如3 * 3的卷积核的大小就为3
stride为卷积的步长
method为是否做zero padding ,VALID代表不做,SAME代表做
前向传播:利用im2col方法来做卷积,同时得到self.col_image
求梯度:
def gradient(self, last_delta):
输入为下一层的误差项last_delta,将其reshape
col_delta = np.reshape(last_delta, [self.batchsize, -1, self.output_channels])
将前向传播得到的self.col_image转置后与误差项col_delta相乘,得到self.w的梯度,将col_delta求和,得到self.b的梯度
将col_delta矩阵与翻转180度后的权重矩阵self.weight矩阵相乘,reshape后得到上一层的误差项next_delta
反向传播:
def backward(self, learning_rate = 1e-4, weight_decay = 0.0004):
根据学习率和self.w、self.b的梯度进行梯度下降来更新
全连接层
思路和week18做的全连接层一样,只不过这次要把层抽象出来,方法分为前向传播forward、求梯度gradient和反向传播backward
初始化:
def __init__(self, shape, output_amount = 2):
shape为四维数组同上,output_amount代表输出层神经元的数目
前向传播:矩阵相乘,求卷积
求梯度:
def gradient(self, last_delta):
根据后一层的误差项来求出前一层的误差项,并求出self.w和self.b的梯度
反向传播:
def backward(self, learning_rate = 1e-4, weight_decay = 0.0004):
根据学习率和梯度来进行梯度下降来更新
非线性层
采用relu激活函数,前向传播为
return np.maximum(self.x, 0)
反向传播为
self.delta[self.x < 0] = 0
最大池化层
前向传播为(2,2)区域内做池化,取最大值,值得注意的是要记录每一区域内最大值对应的索引
index = np.argmax(x[b, i:i + self.kernel_size, j:j + self.kernel_size, c])
self.index[b, i+index//self.stride, j + index % self.stride, c] = 1
反向传播为
def gradient(self, delta):return np.repeat(np.repeat(delta, self.stride, axis=1), self.stride, axis=2) * self.index
Softmax层
初始化
def __init__(self, shape):
self.delta = np.zeros(shape)
self.softmax = np.zeros(shape)
self.batchsize = shape[0]
预测
根据softmax原理进行预测
def predict(self, prediction):
exp_prediction = np.zeros(prediction.shape)
self.softmax = np.zeros(prediction.shape)
for i in range(self.batchsize):
prediction[i, :] -= np.max(prediction[i, :])
exp_prediction[i] = np.exp(prediction[i])
self.softmax[i] = exp_prediction[i]/np.sum(exp_prediction[i])
return self.softmax
求梯度
def gradient(self):
self.delta = self.softmax.copy()
for i in range(self.batchsize):
self.delta[i, self.label[i]] -= 1
return self.delta
计算损失
def cal_loss(self, prediction, label):
self.label = label
self.prediction = prediction
self.predict(prediction)
self.loss = 0
for i in range(self.batchsize):
self.loss += np.log(np.sum(np.exp(prediction[i]))) - prediction[i,
label[i]]
return self.loss
运行效果
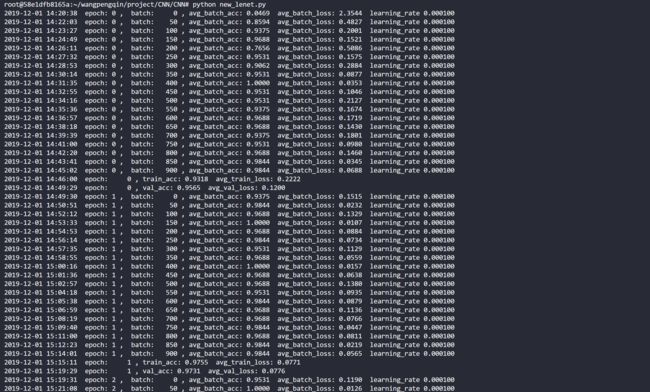
网络结构略有不同
早期由于计算资源有限,S2到C3的连接方式是规定好的,如图

而在算力发达的今天,我们便不再规定二者之间的连接方法
如图所示初始化类对象,设置epoch、batchsize,开始训练

在训练5个epoch即5轮后,训练集上的正确率达到了98.3%,验证集上达到了97.8%

结语
算上在家里“天伦之乐”的时间,这个Lenet5我足足写了三个星期,我看到有博主理解和复写这个写了小半年。关于实验课,老师的要求是每一句代码都要手写,完全不要农夫三拳。这样的初衷和目的当然是好我能理解,但是在要求的一个星期的时间内真的有新手能完完整整的手写出来吗?同学们真的不会为了完成目标而采取特殊手段吗?这都是值得思考的问题。在实验上我已经鸽了太久了hhhh,能过就赶快过看后面的吧。现在先吃饭去咯