简介
之前在看volatile 可见性的时候,经常会看到内存屏障,但是对于其基本原理似懂非懂,也对于内存屏障是如何保障多个CPU之间的数据可见性保持好奇,网上的博客基本上只是停留于表面,导致我产生了几个误区:
1. CPU之间内存数据可见性问题是由于cpu cache没及时同步数据导致的。
2. 内存屏障为啥能通过防止指令重排序,就能让cpu cache及时同步数据?
不过最近发现这只是表面现象!所以今天写一下这篇文章来彻底介绍一下内存屏障
CPU cache
虽然内存可见性问题不是直接由cpu cache导致的,还是与cpu cache是有密切联系的,所以我们先来简单介绍一下cpu cache。
在我之前的文章中有提到内核对于小块内存是通过slab来管理的,slab将内存划分为小块,每一块为2的一个指数级,而这个内存块是与cpu cacheline一一对应的,cacheline的大小在一个16字节到256字节的范围,通过一些缓存失效机制来进行替换,比如FIFO,LRU之类的。
内核其实是有机制保证CPU之间数据一致性的,我们称这种缓存一致性协议为MESI 状态机。
MESI是一个比较啰嗦的机制,其主要作用就是通过四种状态之间的切换来保证同一数据在不同CPU中的一致性,这和内存屏障其实关系不大,所以我下面只做简单介绍,如果有兴趣详细了解的,见文章最后的参考资料。
M即"modify",表示一个CPU line独占当前变量数据,且该变量未同步回memory,所以更新该变量时需要同步回内存,或转发给其他cpu。
E即"exclusive",它和modify的唯一区别是,已经同步回memory,因而可以直接操作该line(读写),而不需要和其他cpu或者memory进行其他交互。
S即"share",表示该line至少被一个cpu共享着,如果需要操作该line需要通知其他也共享该line的cpu。
I即"invalid",表示空line或者无效line。
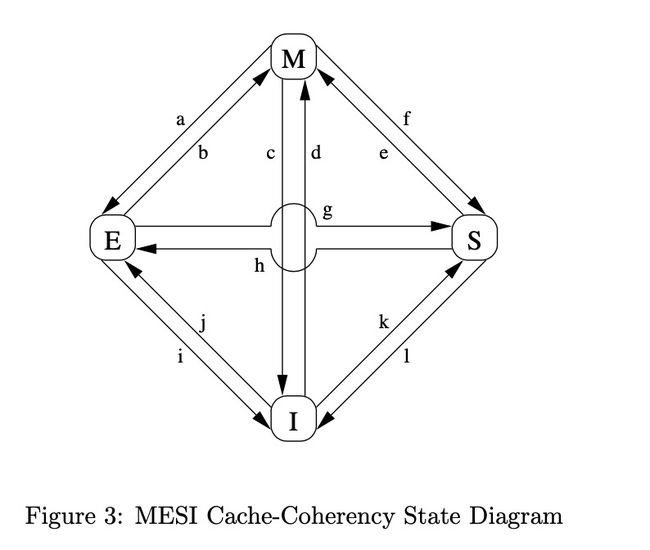
各个状态之间可以通过一些操作来切换,这些操作我称他为”消息调用“或组合,其实跟rpc调用之类的相似。
MESI message:
Read:从一个指定cache line物理地址读取数据
Read response: 返回数据
Invalidate: 将一个指定cache line物理地址标记为无效,所有相关CPU都要删除对应的cache line
Invalidate response: 收到invalidate消息的cpu要返回确认。
Read Invalidate: 原子性的发送 Read + Invalidate
Writeback: 将指定cache line中的数据写回memory
CPU通过MESI中一套严密的事务操作来保障操作同一变量,在各个CPU中都是一致的。这里状态切换,特别繁杂,就不一一介绍了,就举一个简单列子来说明一下两个CPU中是如何保障操作同一变量的一致性吧:
有如下三条指令
1 a=1;
2 b=a+1;
3 assert(b == 2);
其中a存在cpu1的cache中,b存在cpu0的cache中,现在在cpu0中执行上述指令:
那么操作过程为:
- cpu 0 发现a不在缓存中,且自己需要read-modify-write,所以就会发起一个Read Invalidate message,cpu1将a对应的cpu line置为无效,并返回ack。
- cpu 0 等待 Invalidate ACK,直至收到ACK后,才执行后续指令
- b就在cpu 0的cache line中,所以直接操作让b = 2;
- 指令3assert成功。
- 如果cpu1上的进程如果读a的话,会向cpu0发送read请求
如果按照上面的逻辑走的话,即使没有mb(memory barrier),也不会有任何问题。但是有经验的同学会发现在步骤2中,必须要等待CPU1返回ACK后才能执行后续的指令,非常低效,因此CPU 引入了store buffer的机制,来提高CPU性能。
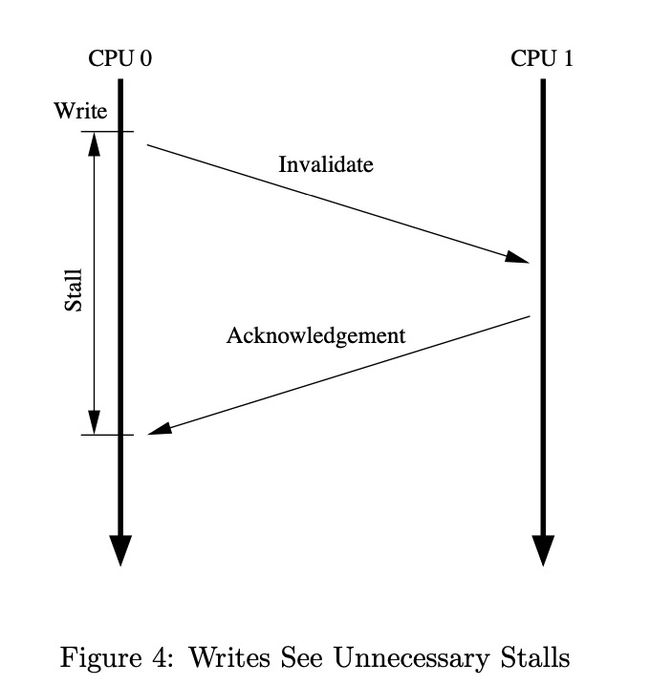
store buffer
在上述的例子中,可以发现CPU 0 其实并不依赖其他CPU中a的值,所以完全可以不用等待ack也能保障CPU 0中指令的执行正确性,通过把a的值存入store buffer就可以接着跑后续的指令了,性能大大提升。
但是这种有些特殊场景却无法涵盖,比如上述指令中对于变量a,Read Invalidate调用会将CPU 0 的cache line置为0(从CPU1读过来的),而store buffer中的值为1,如果CPU只拿cache line中的值的话,会有一致性问题,所以store buffer还需要与store forwarding机制一起合作。也就是如果store buffer中有值,就从store buffer中拿。
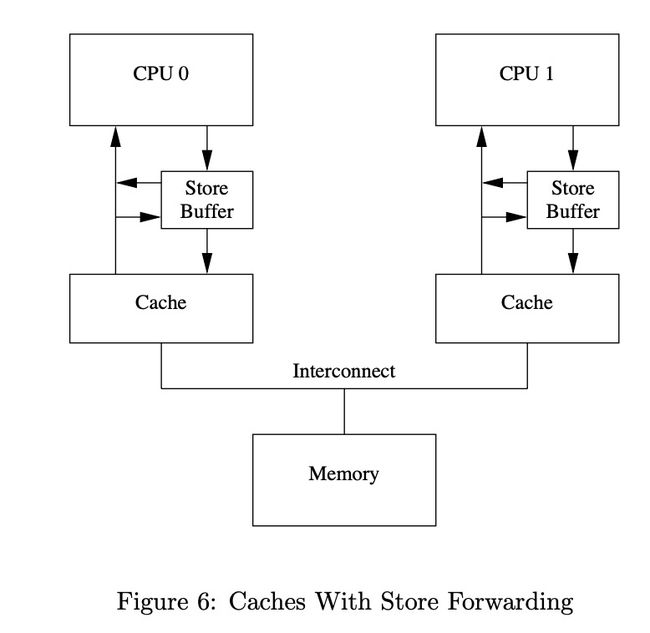
memory barrier
引入了store buffer 及 store forwarding 后看上去解决了cpu cache一致性问题,且性能大大提升,但是这仅仅保证了当前CPU的指令正确性。我们来看另外一个例子:
1 void foo(void)
2{
3 a=1;
4 b=1;
5}
6
7 void bar(void)
8{
9 while (b == 0) continue;
10 assert(a == 1);
11 }
在CPU 0中执行foo,CPU 1中执行bar,a在CPU 1的缓存中, b 在CPU 0的缓存中,执行序列如下:
- CPU0 执行 a=1,将a的值存入store buffer,发现a不在缓存中,所以向发送Read Invalidate message。
- CPU1 执行while (b == 0) continue;,b不在CPU1cache中,发送Read message。
- CPU0 执行 b=1,b owned by itself,所以直接更新。
- CPU0 接收到b的read请求后,将更新过后的值发给CPU1。
- CPU1 将b的值更新到自己的缓存
- CPU1 执行while (b == 0) continue;中b的值变为1,可以跳出该循环了。
- CPU1 执行assert(a == 1);,此时CPU1中的a值可能尚未被置为无效,所以直接从cache中拿出来其,值为0,导致assert failed。
从上可以看出,如果Read Invalidate message未被执行完时,会让两个CPU中对于同一值出现不一致的情况。按正常逻辑来说b已经更新为1了,a不可能还是0。
单从硬件方面来说,目前没有很好的机制来解决这一类问题,所以就引入了memory barrier 指令来防止CPU cache中的这种store buffer带来的不一致性问题。但是mb相比于原始的unnecessary stall机制还是有优化的,就是当遇到memory barrier 指令时,将store buffer中的已有的所有变量做标记,后续的write操作,必须要等buffer中所有被标记数据清空后,才将未做标记的数据更新到cache。我们将上述例子改写如下:
1 void foo(void)
2{
3 a=1;
4 smp_mb();
5 b=1;
6 }
7
8 void bar(void)
9{
10 while (b == 0) continue;
11 assert(a == 1);
12 }
那么CPU0执行完a=1后,将其写入store buffer,执行到smp_mb后将store buffer中的所有变量标记,执行到b=1时,写入store buffer后不做标记,且不写回cache line,在收到CPU1的请求后将b的cache line 标记为shared,当CPU0收到CPU1对于a的Invalidate ACK后,将a更新回cache line并将其置为modified,且清除store buffer中a的值,所以CPU0中store buffer没有被标记的数据了,剩余的b就可以更新会cache了,此时其是share状态所以其更新会向其share CPU发送Invalidate message,CPU1接收到message后重新Read,将b置一继续后面的逻辑,这样assert就是没问题的了。
Store Sequence Capacity
有了上续机制后,可以通过mb来禁止指令读取乱序后,解决了数据CPU间的一致性问题,但是又带了另外一个问题,store buffer的容量是很小的,如果等待的Invalidate指令迟迟不返回,那么store buffer就会被填满,而无法继续执行后续指令。
所以就需要一些机制来加速Invalidate message的执行,便引入了Invalidate Queue,这是因为Invalidate message执行慢的主要原因是需要确保对应的cache line确实是无效的,但是这个验证工作有时候会因为CPU过忙而推迟。所以有了Invalidate Queue后可以不做有效性验证,直接ACK,后续有空了再验证清除对应的cache line,这样就不会stalling 其他 CPU了。但这又产生了另外一个问题,要确保当前CPU中读取某一个值时,其是否在Invalidate Queue中,否则就会读到无效的数据。比如上述例子中的a如果只存在CPU1的Invalidate Queue中,却未被真正的清除,那么bar还是assert 失败(a == 0)的,具体过程可以自己推到。
Invalidate Queues and Memory Barriers
所以我们需要另外一种机制确保读某一个值时,其不能存在于Invalidate Queues中,所以硬件开发者又提供了一种方式来解决该问题,这种机制还是基于mb 指令,但是这次带来了一个新的限制,当遇到mb时将Invalidate Queues中的所有变量做标记,后续有读指令时,必须要等所有被标记的Invalidate Queues的数据被处理完后才能继续执行。因此我们可以将上述代码修改如下:
1 void foo(void)
2{
3 a=1;
4 smp_mb();
5 b=1;
6}
7
8 void bar(void)
9{
10 while (b == 0) continue;
11 smp_mb();
12 assert(a == 1);
13 }
至此就可以保障变量a在CPU0 和 CPU1中的完全一致可见性了。
后记
由此可见,CPU之间的变量可见性不是直接由于CPU cache,也不是由于指令乱序,而是由于CPU Cache-Coherence Protocols性能优化中store buffer带来的数据不一致性问题带来的的cache不一致性问题,而内存屏障也不是用来禁止指令乱序,而是解决由于数据只更新到了store buffer却没有更新回cache以及Invalidate不同步问题。
参考资料
whymb