OpenGL + OpenGL ES +Metal 系列文章汇总
本案例的目的在于理解顶点数据的两种存储方式以及它们的区别和应用场景
在Metal 入门级02:加载三角形案例中,顶点数据的存储使用的是数组,当顶点传递时通过setVertexBytes(_:length:index:)方法,主要是由于绘制三角形时,所需的顶点只有3个,顶点数据很少,所以可以通过数组存储,此时的数据是存储在CPU中的。那当顶点数据很多时,我们如何存储及传递呢?
针对setVertexBytes(_:length:index:)方法在苹果的官方文档中有如下说明
对于小于4KB(即4096字节)的一次性数据,使用setVertexBytes(_:length:index:),如果数据长度超过4KB 或者需要多次使用顶点数据时,需要创建一个MTLBuffer对象,创建的buffer的目的就是为了将顶点数据存储到顶点缓存区,GPU可以直接访问该缓存区获取顶点数据,并且buffer缓存的数据需要通过setVertexBuffer(_:offset:index:)方法传递到顶点着色器。

下面以一个案例来说明MTLBuffer的使用,案例的整体效果如图所示

整体的执行流程如下
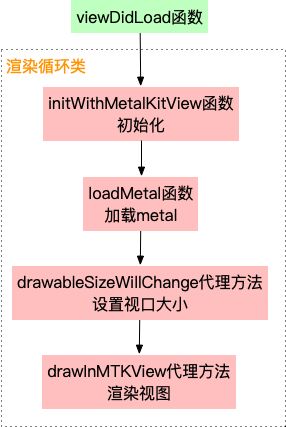
与Metal 入门级02:加载三角形案例相比,主要是以下两部分的变化
- Render渲染循环类:大批量顶点数据数据的存储及传递
- metal文件:顶点坐标需要归一化处理
其他的视图控制器及OC与C的桥接.h文件均没有任何变化,具体请参考文末完整代码
渲染循环类
主要是修改大批量顶点数据的存储及传递,涉及以下两个函数
- initWithMetalKitView函数:产生大量顶点数据并将数据存储到buffer中
- drawInMTKView代理方法:顶点数据的传递到顶点着色器通过
setVertexBuffer(_:offset:index:)方法
initWithMetalKitView函数
该函数主要是初始化GPU设备以及加载metal,流程如图所示
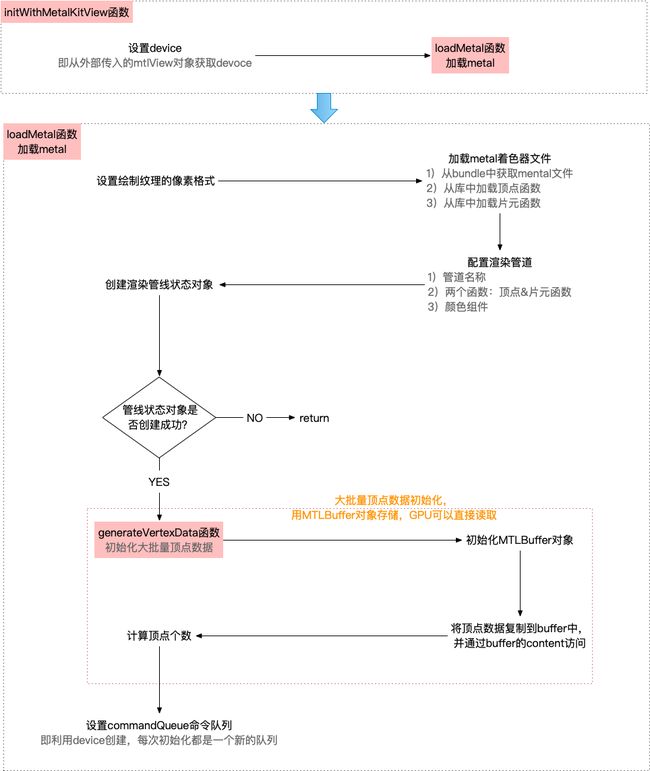
主要分为以下两步
- 初始化device
- loadMetal函数:加载metal
初始化device
通过视图控制器中初始化render对象时传入的MTKView对象view,利用view来获取GPU的使用权限
_device = mtkView.device;
loadMetal函数
该函数主要是初始化metal的一些准备工作,加载metal大致可以分为几步
- view设置绘制纹理的像素格式
mtkView.colorPixelFormat = MTLPixelFormatBGRA8Unorm_sRGB;
加载.metal文件 & 顶点着色和片元着色函数
创建渲染管道,并命名 & 设置渲染管道的顶点和片元function & 设置颜色数据的组件格式
创建渲染管线状态 & 判断是否创建成功
以上几步,基本上是使用metal绘制图形时的必备操作,在Metal 入门级02:加载三角形案例中已经有详细说明,这里不在过多说明-
获取顶点数据
- 通过
generateVertexData函数生成大批量的顶点数据 - 初始化MTLBuffer对象,该buffer存储的数据,可以由GPU直接读取
使用buffer的原因是顶点数据的大小超过了4KB,如果再用数组存储,从CPU传递到GPU,性能开销会非常大,所以苹果官方文档建议,当有大批量顶点数据时,需要创建MTLBuffer对象来存储数据 - 将顶点数据复制到顶点缓存区,通过缓存区的
content内容属性访问指针 - 计算顶点个数
通过顶点数据的长度 除以 单个顶点的大小 得到顶点的总个数
- 通过
// 5、获取顶点数据
NSData *vertexData = [CJLRenderer generateVertexData];
// 创建一个vertex buffer,可以由GPU来读取
_vertexBuffer = [_device newBufferWithLength:vertexData.length options:MTLResourceStorageModeShared];
// 复制vertex data 到vertex buffer 通过缓存区的"content"内容属性访问指针
/*
memcpy(void *dst, const void *src, size_t n);
dst:目的地 -- 读取到那里
src:源内容 -- 源数据在哪里
n: 长度 -- 读取长度
*/
memcpy(_vertexBuffer.contents, vertexData.bytes, vertexData.length);
// 计算顶点个数 = 顶点数据长度 / 单个顶点大小
_numVertices = vertexData.length / sizeof(CJLVertex);
- 通过device创建commandQueue命令队列
_commandQueue = [_device newCommandQueue];
drawInMTKView代理方法
在viewDidload函数中设置view的delegate的对象为render``,即在自定义的渲染循环类中处理view的委托代理方法,其中view默认的帧速率与屏幕的刷新速率是一致的,所以每当屏幕刷新时,就会调用MTKViewDelegate的drawInMTKView`绘制方法来进行图形渲染,drawInMTKView方法的流程图如下

主要分为以下几部分
- 创建命令缓存区 & 命名
- 创建renderPassDescriptor渲染描述 & 判断渲染描述是否为空
- 当渲染描述符不为空时,继续往下执行
- 当渲染描述符为空时,直接跳转至commit提交
- 创建commandEncoder命令编码器
- 设置视口
- 设置渲染管线状态
- 传递数据
- 绘制图形
- 结束commandEncoder工作
- 通过presentDrawable渲染到屏幕上
- 将commandBuffer提交至GPU
以上几步,除了传递数据部分,其他都是图形渲染的必须步骤,在文章开头提及的案例中均有说明,下面着重说下传递数据部分
在init初始化函数中,顶点数据的存储是使用buffer存储的,所以顶点数据的传递也需要使用与buffer相对应的传递函数setVertexBuffer,而viewpoertSize数据的传递仍然可以使用setVertexBytes函数,所以其实
buffer 和 bytes传递是可以混合使用的
| 函数 | 参数 |
|---|---|
| setVertexBytes:length:atIndex | 参数1-bytes:指向传递给着色器的内存指针 |
| 参数2-length:想要传递的数据的内存大小 | |
| 参数3-Index:对应的索引 | |
| setVertexBuffer:offset:atIndex | 参数1-buffer:需要传递数据的缓冲对象 |
| 参数2-offset:从缓冲器的开头字节偏移,一般传0 | |
| 参数3-atIndex:对应的索引 |
//我们调用-[MTLRenderCommandEncoder setVertexBuffer:offset:atIndex:] 为了从我们的OC代码找发送数据预加载的MTLBuffer 到我们的Metal 顶点着色函数中
/* 这个调用有3个参数
1) buffer - 包含需要传递数据的缓冲对象
2) offset - 它们从缓冲器的开头字节偏移,指示“顶点指针”指向什么。在这种情况下,我们通过0,所以数据一开始就被传递下来.偏移量
3) index - 一个整数索引,对应于我们的“vertexShader”函数中的缓冲区属性限定符的索引。注意,此参数与 -[MTLRenderCommandEncoder setVertexBytes:length:atIndex:] “索引”参数相同。
*/
//将_vertexBuffer 设置到顶点缓存区中,顶点数据很多时,存储到buffer
[commandEncoder setVertexBuffer:_vertexBuffer offset:0 atIndex:CJLVertexInputIndexVertices];
//可以buffer 和 bytes传递混合使用
//将 _viewportSize 设置到顶点缓存区绑定点设置数据
[commandEncoder setVertexBytes:&_viewportSize length:sizeof(_viewportSize) atIndex:CJLVertexInputIndexViewportSize];
Metal文件
.metal文件中,在顶点着色函数需要对顶点坐标进行归一化处理,因为顶点数据初始化时使用的是物体坐标。顶点坐标的归一化主要有以下几步:
- 初始化输出裁剪空间位置
- 获取当前顶点坐标的xy:主要是因为绘制的图形是2D的,其z都为0
- 将传入的视图大小转换为
vector_float2二维向量类型 - 顶点坐标归一化:可以通过一行代码同时分隔两个通道x和y,并执行除法,然后将结果放入输出的x和y通道中,即从像素空间位置转换为裁剪空间位置
vertex RasterizerData
vertexShader(uint vertexID [[vertex_id]],
constant CJLVertex *vertices [[buffer(CJLVertexInputIndexVertices)]],
constant vector_uint2 *viewportSizePointer [[buffer(CJLVertexInputIndexViewportSize)]])
{
/*
处理顶点数据:
1) 执行坐标系转换,将生成的顶点剪辑空间写入到返回值中.
2) 将顶点颜色值传递给返回值
*/
// 1、定义out
RasterizerData out;
// 2、初始化输出剪辑空间位置,将w改为2.0,实际运行结果比1.0小一倍
out.clipSpacePosition = vector_float4(0.0, 0.0, 0.0, 1.0);
// 3、获取当前顶点坐标的xy,因为是2D图形
// 索引到我们的数组位置以获得当前顶点
// 我们的位置是在像素维度中指定的.
float2 pixelSpacePosition = vertices[vertexID].position.xy;
//将vierportSizePointer 从verctor_uint2 转换为vector_float2 类型
vector_float2 viewportSize = vector_float2(*viewportSizePointer);
// 4、顶点坐标归一化处理
//每个顶点着色器的输出位置在剪辑空间中(也称为归一化设备坐标空间,NDC),剪辑空间中的(-1,-1)表示视口的左下角,而(1,1)表示视口的右上角.
//计算和写入 XY值到我们的剪辑空间的位置.为了从像素空间中的位置转换到剪辑空间的位置,我们将像素坐标除以视口的大小的一半.
//如果是1倍,除以1.0,如果是3倍
//可以使用一行代码同时分割两个通道。执行除法,然后将结果放入输出位置的x和y通道中
out.clipSpacePosition.xy = pixelSpacePosition / (viewportSize / 2.0);
// 5、颜色原样输出
//把我们输入的颜色直接赋值给输出颜色. 这个值将于构成三角形的顶点的其他颜色值插值,从而为我们片段着色器中的每个片段生成颜色值.
out.color = vertices[vertexID].color;
//完成! 将结构体传递到管道中下一个阶段:
return out;
}
总结
顶点数据的存储方式有两种
- 通过
数组存储在CPU,需要利用setVertexBytes:length:atIndex:函数将顶点数据传递到GPU,这种情况仅适合小于4KB的顶点数据 - 当顶点数据
大于4KB时,需要将顶点数据存储在MTLBuffer对象,即顶点缓存区中,这种存储方式GPU可以直接读取,传递到着色函数时需要通过setVertexBuffer: offset: atIndex:函数
完整的代码见Github - 18_Metal_三角形_OC