学号:20021110074 电院 姓名:梁雪玲
转载自:https://blog.csdn.net/heivy/article/details/100512264?utm_medium=distribute.pc_relevant.none-task-blog-title-2&spm=1001.2101.3001.4242
【嵌牛导读】:人工智能这么火热,看了那么多理论后该如何实践?本文带你走进实践的殿堂
【嵌牛鼻子】:鸢尾花多分类 TensorFlow 模型构建
【嵌牛提问】:针对鸢尾花多分类的神经网络如何构建模型?模型的详解?如何撸代码?
【嵌牛正文】:
人工智能领域分化为两个阵营:其一是规则式(rule-based)方法,在人工智能早期占主峰;其二是神经网络(neural network)方法,后起之秀。随着硬件水平的提高,算力的指数式增长;人工智能的重心已经从规则式的专家时代转移到神经网络的数据时代。
“神经网络”不选择把人脑熟稔的逻辑规则传授给计算机,而是直接在机器上重建人脑(类似人脑神经元网络)。即模仿人脑结构,构建类似生物神经元网络结构来进行收发信息。不同于规则式方法,人工神经元网络的建造者一般不会给网络设定决策规则(即给定网络系数),而只是把某一现象(图片、人声、文本等)的大量实际例子输入人工神经元网络,并给定这一现象的结果(此图片有猫,此人声是某某文本,此文本属于正向积极情感等等)让网络从这些数据中学习(有监督、半监督)、识别规律。换言之,神经网络的原则是来自人的干预越少越好。 神经网络通过把数百万张标示了“有猫”或“没有猫”的样本图片“喂”给计算机系统,让它自行从这数百万张图片中去辨察哪些特征和“猫”的标签最密切相关。
根据神经网络的特点,大批量(百万级)数据”喂“入网络,让网络进行特征即规则的学习和提取,可知数据是人工智能时代的核心之一,人工智能的另一个核心则是神经网络的模型构建。下面我们就鸢尾花多分类问题来详解简单的神经网络模型构建及相应代码实现。
一、数据处理
鸢尾花多分类问题是tensorflow 官方文档里面的一个tensorflow入门教程;选取的是比较典型特点的三种鸢尾花:山鸢尾Iris setosa(0)、变色鸢尾Iris versicolor (1)、维吉尼亚鸢尾Iris virginica (2) 如图一所示:

图一:鸢尾花(从左到右依次山鸢尾、维吉尼亚鸢尾、变色鸢尾)
从图一可以看出三种鸢尾花区别很明显,主要体现在花瓣和花萼上;tensorFlow提供的数据集中,每个样本包含四个特征和一个标签。这四个特征确定了单株鸢尾花的植物学特征鸢尾花花瓣(petals)的长度和宽度、花萼(sepals)的长度和宽度,单位CM;而标签则确定了此鸢尾花所属品种:山鸢尾 (0)、变色鸢尾 (1)、维吉尼亚鸢尾 (2)。数据格式如图二所示,所有数据直接用逗号隔开(csv数据常用格式)。

图二:鸢尾花分类问题训练数据集格式
数据集包括训练数据及测试数据,数据格式统一为csv格式如图三所示,,下载地址:
训练数据集(iris_training.csv):http://download.tensorflow.org/data/iris_training.csv
测试数据集(iris_test.csv):http://download.tensorflow.org/data/iris_test.csv

图三:鸢尾花训练及测试数据集
数据拿到后,我们首先要进行数据的清洗(这里数据是干净的,此步可省略),数据特征和数据标签的分割,即把鸢尾花的花瓣长度、宽度,花萼长度、宽度提取另存,标签提取另存,以便于训练喂入网络。进行csv数据的处理,代码如下,处理结果如图五所示:
def parse_csv(line):
# 设置特征和标签的数据接收格式
featlab_types = [[0.], [0.], [0.], [0.], [0]]
# 解析csv数据,以featlab_types的格式接收
parsed_line = tf.io.decode_csv(line, featlab_types)
# 提取出特征数据,并转化成张量
features = tf.reshape(parsed_line[:-1], shape=(4,))
# 提取出标签数据,并转化成张量
label = tf.reshape(parsed_line[-1], shape=())
return features, label
def getFeaturesLables(dataPath):
# 使用TextLineDataset 读取文件内容
FeatLabs = tf.data.TextLineDataset(trainPath)
# 跳过第一行,因为第一行是所有数据内容的总结,不能用于训练或测试
FeatLabs = FeatLabs.skip(1)
# 把每一行数据按照parse_csv的格式报错
FeatLabs = FeatLabs.map(parse_csv)
# 打乱数据原来的存放位置,
FeatLabs = FeatLabs.shuffle(buffer_size=1000)
# 以float32的格式保存数据
FeatLabs = FeatLabs.batch(32)
return FeatLabs

读取测试数据(原数据的第一行被丢掉,因为它不属于正式测试数据)
处理后的数据张量如图所示:

标签列表、标签和ID对照字典处理函数:
def readCategory():
"""
Args:
None
Returns:
categories: a list of labels
cat_to_id: a dict of label to id
"""
categories = ['山鸢尾setosa', '变色鸢尾versicolor', '维吉尼亚鸢尾virginica']
cat_to_id = dict(zip(categories, range(len(categories))))
return categories, cat_to_id
二、网络搭建
神经网络可以建有很多层,每层用什么网络根据需求;其中最简单的网络结构是三层结构:输入层,隐藏层以及输出层。
在这里,已知输入是4个特征数据(花瓣(petals)的长度和宽度、花萼(sepals)的长度和宽度),输出是3种类别(‘山鸢尾setosa’, ‘变色鸢尾versicolor’, ‘维吉尼亚鸢尾virginica’)设置的是隐藏层为3层,节点分布分别是:10、20、10。
整体网络示意图如图七所示:

图七:神经网络示意图
网络搭建代码如图八所示:共分为网络参数设置类和网络搭建类:
class NNetConfig():
num_classes = 3 # 多分类的种类
num_epochs = 161 # 训练总批次
print_per_epoch = 20 # 每训练多少批次时打印训练损失函数值和预测准确率值
layersls = [4, 10, 20, 10, 3] # 【输入,隐藏各层节点数,输出】
learning_rate = 0.01 # 网络学习率
train_filename = './data/iris_training.csv' # 训练数据
test_filename = './data/iris_test.csv' # 测试数据
best_model_savepath = "./dnn/best_validation" # 最好模型的存放文件夹
三、网络训练及验证
3.1训练代码:
def iris_train():
# 调用NNet网络,搭建自己的神经网络
nnet = NNet(config)
model = nnet.NNet()
# 获取训练数据
featsLabs = getFeaturesLables(trainPath)
# 定义网络优化器:梯度下降,以learning_rate 的速率进行网络的训练优化
optimizer = tf.compat.v1.train.GradientDescentOptimizer(config.learning_rate)
# 防止网络过拟合的,当准确率大幅度下降时 停止训练,这里没有用到
flag_train = False
# 损失函数,使用的是交叉熵
def loss(model, x, y):
y_ = model(x)
return tf.compat.v1.losses.sparse_softmax_cross_entropy(labels=y, logits=y_)
# 当前网络梯度
def grad(model, inputs, targets):
with tfe.GradientTape() as tape:
loss_value = loss(model, inputs, targets)
return tape.gradient(loss_value, model.variables)
best_epoch_accuracy = 0
last_improved = 0
improved_str = ''
for epoch in range(config.num_epochs):
epoch_loss_avg = tfe.metrics.Mean()
epoch_accuracy = tfe.metrics.Accuracy()
# 轮回训练网络
for x, y in tfe.Iterator(featsLabs):
# 优化网络
grads = grad(model, x, y)
optimizer.apply_gradients(zip(grads, model.variables),
global_step=tf.compat.v1.train.get_or_create_global_step())
# 当前批次训练的损失函数均值
epoch_loss_avg(loss(model, x, y)) #
# 预测的标签值和实际标签值进行对比,得到当前的预测准确率
epoch_accuracy(tf.argmax(model(x), axis=1, output_type=tf.int32), y)
# 本批次训练结束,保存本批次的损失函数结果和准确率结果
train_loss_results.append(epoch_loss_avg.result())
train_accuracy_results.append(epoch_accuracy.result())
# 每隔print_per_epoch次 输出损失函数值、准确率值等信息,方便监控网络的训练
if epoch % config.print_per_epoch == 0:
if not (epoch_accuracy.result()) > best_epoch_accuracy:
# flag_train = True #防止网络被过度训练
# break
improved_str = ''
pass
else:
best_epoch_accuracy = epoch_accuracy.result()
print("当前最高准确率:%.3f:" % best_epoch_accuracy)
# 最好模型的保存
model.save(os.path.join(config.best_model_savepath,
"model_best.h5"))
last_improved = epoch
improved_str = '*'
print("Epoch {:03d}: Loss: {:.3f}, Accuracy: {:.3%}, isBest:{}".format(epoch,
epoch_loss_avg.result(),
epoch_accuracy.result(),
improved_str))
if flag_train:
break
训练过程结果如图九所示:

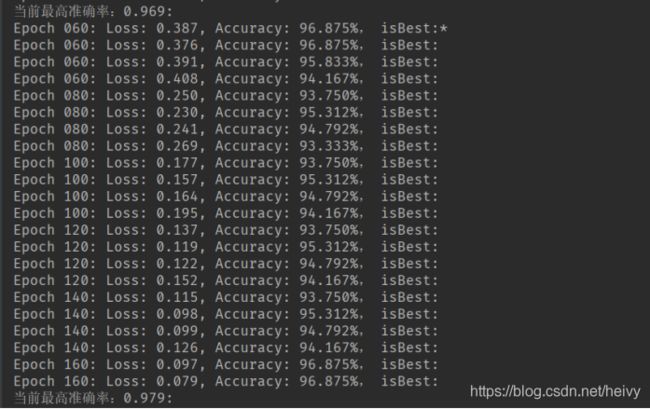
图九:训练过程数据输出
从输出第一行可以看到有个警告,大意是:当前电脑是支持AVX2 计算的,但当前使用的Tensor Flow是不支持AVX2 计算。其他没有太大影响,如果你感觉很扎眼,那喔下次告诉你怎么把它藏起来哈~~
训练过程中的损失函数和准确率变化如图十所示,从图中可以看出,损失函数的值在稳定下降,没有太大的震荡,从准确率变化,可以看出,其实在训练到500Eoph时就可以终止训练了,训练结果已经达到最优了。后面如果再加大训练,可以会引起网络的过度训练,出现过拟合现象。

图十:训练过程中的损失函数值及准确率值随训练批次的变化
3.2测试代码:
def iris_test():
# 加载已经训练好的最优模型(包括网络结构及网络权值矩阵)
model = tf.keras.models.load_model(
os.path.join(config.best_model_savepath, "model_best.h5"),
compile=False)
# 数据批量处理,把测试数据进行清洗、结构化、张量化
testFeatsLabs = getFeaturesLables(testPath)
# 计算测试数据在此模型下的准确率
test_accuracy = tfe.metrics.Accuracy()
for x, y in tfe.Iterator(testFeatsLabs):
# 模型的预测结果
prediction = tf.argmax(model(x), axis=1, output_type=tf.int32)
test_accuracy(prediction, y)
print("测试数据的测试结果为: {:.3%}".format(test_accuracy.result()))
return test_accuracy.result()
测试数据的测试结果如下图所示:达到了97.5%,比单层网络的91%优化了很多

3.3预测代码:
def iris_prediction(features=[]):
# 预测函数
# 加载已经训练好的最优模型(包括网络结构及网络权值矩阵)
# compile=False 表示对此模型,我只用不再次训练
model = tf.keras.models.load_model(
os.path.join(config.best_model_savepath, "model_best.h5"),
compile=False)
# 当预测特征为空时,使用下面给出的默认值进行预测
if (len(features)==0):
predFeats = tf.convert_to_tensor([
[5.9, 3.0, 4.2, 1.5],
[5.1, 3.3, 1.7, 0.5],
[6.9, 3.1, 5.4, 2.1]
])
else:
# 预测特征数据转换成张量
predFeats = tf.convert_to_tensor(features)
# 预测结果存放列表
cat_probs = []
# 使用已训练模型预测的预测结果,是张量
y_probs = model(predFeats)
# 取出每条预测结果进行处理,取出其中最大值,即最可能的结果,
# 根据最大值所在下标,取到cat可读文本
for prob in y_probs:
top1 = tf.argmax(prob).numpy()
cat_probs.append(cat[top1])
return cat_probs
最后,是给了3个鸢尾花的数据,进行鸢尾花类别的预测,

最后的最后,我猜测大家最关心的是喔的训练、测试、预测代码在哪里吖~
传送门:链接:https://pan.baidu.com/s/1m4TPja9JzkbLplsISC8fxg
提取码:ngtn