sklearn中的支持向量机SVM(上)
1 概述
支持向量机(SVM,也称为支持向量网络),是机器学习中获得关注最多的算法。它源于统计学习理论,是除了集成学习算法之外,接触到的第一个强学习器。
从算法的功能来看,SVM囊括了很多其他算法的功能:

从分类效力来讲,SVM在无论线性还是非线性分类中,都是明星般的存在。
在实际应用来看,SVM在各种实际问题中都表现非常优秀。它在手写识别数字和人脸识别中应用广泛,在文本和超文本的分类中举足轻重,因为SVM可以大量减少标准归纳(standard inductive)和转换设置(transductive settings)中对标记训练实例的需求。同时,SVM也被用来执行图像的分类,并用于图像分割系统。实验结果表明,在仅仅三到四轮相关反馈之后,SVM就能实现比传统的查询细化方案(query refinement schemes)高出一大截的搜索精度。除此之外,生物学和许多其他科学都是SVM的青睐者,SVM现在已经广泛被用于蛋白质分类,在化合物分类的业界平均水平可以达到90%以上的准确率。在生物科学的尖端研究中,还使用支持向量机来识别用于模型预测的各种特征,以找出各种基因表现结果的影响因素。
从学术的角度来看,SVM是最接近深度学习的机器学习算法。线性SVM可以看成是神经网络的单个神经元(虽然它的损失函数与神经网络不同),非线性的SVM则与两层的神经网络相当,非线性的SVM中如果添加多个核函数,就可以模仿多层的神经网络。从数学的角度来看,SVM的数学原理是公认的对初学者来说很难,对于没有数学基础和数学逻辑熏陶的人来说,探究SVM的数学原理是很难的。
1.1 支持向量机分类器是如何工作的
支持向量机的分类方法,是在一组数据分布中找出一个超平面作为决策边界,使模型在数据上的分类误差尽量小,尤其是在未知数据集上的分类误差(泛化误差)尽量小。
| 关键概念:超平面 |
|---|
| 在几何中,超平面是一个空间的子空间,它是维度比所在空间小一维的空间。如果数据空间本身是三维的,则其超平面是二维平面,而如果数据空间本身是二维的,则其超平面是一维的直线。在二分类问题中,如果一个超平面能够将数据划分为两个集合,其中每个集合中包含单独的一个类别,就说这个超平面是数据的“决策边界”。 |
决策边界一侧的所有点分类属于一个类,而另一侧的所有点分类属于另一个类。如果能够找出决策边界,分类问题就可以变成探讨每个样本对于决策边界而言的相对位置。如果把数据当作训练集,只要直线的一边只有一种类型的数据,就没有分类错误,训练误差就为0。但是,对于一个数据集来说,让训练误差为0的决策边界可以有无数条。
在此基础上,无法保证决策边界在未知数据集(测试集)上的表现也会优秀。对于现有的数据集来说,有 B 1 B_1 B1和 B 2 B_2 B2两条可能的决策边界,并且两条决策边界在数据集上的训练误差都是0,没有一个样本被分错。可以把决策边界 B 1 B_1 B1向两边平移,直到碰到离这条决策边界最近的方块或圆圈后停下,形成两个新的超平面,分别是 b 11 b_{11} b11和 b 12 b_{12} b12,并且将原始的决策边界移动到 b 11 b_{11} b11和 b 12 b_{12} b12的中间,确保 B 1 B_1 B1到 b 11 b_{11} b11和 b 12 b_{12} b12的距离相等。在 b 11 b_{11} b11和 b 12 b_{12} b12中间的距离,叫做 B 1 B_1 B1这条决策边界的边际(margin),通常记作 d d d,并称 b 11 b_{11} b11和 b 12 b_{12} b12为“虚线超平面”。对 B 2 B_2 B2也执行同样的操作。

引入与原本的数据集相同分布的测试样本(如图中红色方块和圆圈),平面中的样本变多了。可以发现,对决策边界 B 1 B_1 B1而言,依然没有一个样本被分错,这条决策边界上的泛化误差还是0。但是对于 B 2 B_2 B2而言,有三个方块被误分类为圆圈,而有两个圆被误分类为方块,这条决策边界上的泛化误差就远远大于 B 1 B_1 B1了。说明拥有更大边际的决策边界在分类中的泛化误差更小,这一点可以由结构风险最小化定律来证明(SRM)。如果边际很小,任何轻微的扰动都会对决策边界的分类产生很大的影响。边际很小的情况,是一种模型在训练集上表现很好,在测试集上表现糟糕的情况,所以会“过拟合”。因此,在寻找决策边界时,希望边际越大越好。

支持向量机就是通过找出边际最大的决策边界,来对数据进行分类的分类器。也因此,支持向量机分类器又叫做最大边际分类器。
1.2 支持向量机原理的三层理解
目标是“找出边际最大的决策边界”,这是一个最优化问题。而最优化问题往往与损失函数联系在一起。和逻辑回归中的过程一样,SVM也是通过最小化损失函数来求解一个用于后续模型使用的信息:决策边界。

1.3 sklearn中的支持向量机
| 类 | 含义 | 输入 |
|---|---|---|
| svm.LinearSVC | 线性支持向量分类 | [penalty, loss, dual, tol, C, …] |
| svm.LinearSVR | 线性支持向量回归 | [epsilon, tol, C, loss, …] |
| svm.SVC | 非线性多维支持向量分类 | [C, kernel, degree, gamma, coef0, …] |
| svm.SVR | 非线性多维支持向量回归 | [kernel, degree, gamma, coef0, tol, …] |
| svm.NuSVC | Nu支持向量分类 | [nu, kernel, degree, gamma, …] |
| svm.NuSVR | Nu支持向量回归 | [nu, C, kernel, degree, gamma, …] |
| svm.OneClassSVM | 无监督异常值检测 | [kernel, degree, gamma, …] |
| svm.l1_min_c | 返回参数C的最低边界,使得对于C in (l1_min_c, infinity),模型保证不为空 | X, y[, loss, fit_intercept, …] |
除了本身所带的类之外,sklearn还提供了直接调用libsvm库的几个函数。libsvm是易于使用和快速有效的英文的SVM库,提供了大量SVM的底层计算和参数选择,也是sklearn的众多类背后所调用的库。下载官网为:http://www.csie.ntu.edu.tw/~cjlin/libsvm/
因此,也可以直接使用libsvm的函数(函数直接输入参数返回结果,不需要实例化,不需要fit;类需要实例化,需要训练,然后使用接口来导出结果)
| 直接使用libsvm的函数 | |
|---|---|
| svm.libsvm.cross_validation | SVM专用的交叉验证 |
| svm.libsvm.decision_function | SVM专用的预测边际函数(libsvm名称为predict_values) |
| svm.libsvm.fit | 使用libsvm训练模型 |
| svm.libsvm.predict | 给定模型预测X的目标值 |
| svm.libsvm.predict_proba | 预测概率 |
注意:除了特别标明是线性的两个类LinearSVC和LinearSVR之外,其他的所有类都是同时支持线性和非线性的。NuSVC和NuSVR可以手动调节支持向量的数目,其他参数都与最常用的SVC和SVR一致。其中OneClassSVM是无监督的类。
2 sklearn.svm.SVC
sklearn.svm.svc(C = 1.0, kernel = ‘rbf’, degree = 3, gamma = ‘auto_deprecated’, coef0 = 0.0, shrinking = True, probability = False, tol = 0.001, cache_size = 200, class_weight = None, verbose = False, max_iter = -1, decision_function_shape = ‘ovr’, random_state = None)
2.1 线性SVM用于分类的原理
2.1.1 线性SVM的损失函数详解
要理解SVM的损失函数,先定义决策边界。假设现在数据中总计有 N N N个训练样本,每个训练样本 i i i可以被表示为 ( x i , y i ) ( i = 1 , 2 , . . . . . . , N ) (\textbf{x}_i,y_i)(i=1,2,......,N) (xi,yi)(i=1,2,......,N),其中 x i \textbf{x}_i xi是 ( x 1 i , x 2 i , . . . . . . , x n i ) T (x_{1i},x_{2i},......,x_{ni})^T (x1i,x2i,......,xni)T这样的一个特征向量,每个样本总共含有 n n n个特征。二分类标签 y i y_i yi的取值是 − 1 , 1 {-1,1} −1,1
如果n等于2,则有 i = ( x 1 i , x 2 i , y i ) T i = (x_{1i},x_{2i},y_i)^T i=(x1i,x2i,yi)T,分别由特征向量和标签组成。此时可以在二维平面上,以 x 2 x_2 x2为横坐标, x 1 x_1 x1为纵坐标, y y y为颜色,来可视化所有 N N N个样本。

其中紫色点的标签为1,红色点的标签为-1。要在这个数据集上寻找一个决策边界,在二维平面上,决策边界(超平面)就是一条直线。而二维平面上的任意一条线可以被表示为:
x 1 = a x 2 + b x_1 = ax_2 + b x1=ax2+b
将表达式变换一下: 0 = w T x + b 0 = \textbf{w}^T\textbf{x}+b 0=wTx+b
其中[ a a a,-1]就是参数向量 w \textbf{w} w, x \textbf{x} x就是特征向量, b b b是截距。这个表达式很像线性回归的公式: y ( x ) = θ T x + θ 0 y(x) = {\theta}^T\textbf{x}+\theta_0 y(x)=θTx+θ0
线性回归中等号的一边是标签,回归过后会拟合出一个标签,而决策边界的表达式中却没有标签的存在,全部是由参数、特征和截距组成的一个式子,等号的一边是0。
在一组数据下,给定固定的 w \textbf{w} w和 b b b,这个式子就是一条固定直线,在 w \textbf{w} w和 b b b不确定的状况下,这个表达式 w T x + b = 0 \textbf{w}^T\textbf{x}+b=0 wTx+b=0就可以代表平面上的任意一条直线。如果在 w \textbf{w} w和 b b b固定时,给定一个唯一的 x x x的取值,这个表达式可以表示一个固定的点。在SVM中,就使用这个表达式来表示决策边界。目标是求解能够让边际最大化的决策边界,所以要求解参数向量 w \textbf{w} w和截距 b b b。
如果在决策边界上任意取两个点 x a x_a xa、 x b x_b xb,并代入决策边界的表达式中,则有:
w T x a + b = 0 \textbf{w}^T\textbf{x}_a+b = 0 wTxa+b=0
w T x b + b = 0 \textbf{w}^T\textbf{x}_b+b = 0 wTxb+b=0
将两式相减,可以得到:
w T ∗ ( x a − x b ) = 0 \textbf{w}^T*(\textbf{x}_a - \textbf{x}_b) = 0 wT∗(xa−xb)=0
一个列向量的转置乘以另一个列向量,可以得到两个向量的点积(dot product),表示为 < w . ( x a − x b ) >

任意一个紫色的点 x p x_p xp可以被表示为: w ∗ x p + b = p \textbf{w}*\textbf{x}_p+b = p w∗xp+b=p。由于紫色的点所代表的标签 y y y是1,所以规定 p > 0 p>0 p>0。同样的,对于任意一个红色的点 x r x_r xr而言,可以将其表示为: w ∗ x r + b = r \textbf{w}*\textbf{x}_r+b = r w∗xr+b=r,由于红色点所表示的标签 y y y是-1,所以规定 r < 0 r<0 r<0。由此,如果有新的测试数据 x t \textbf{x}_t xt,则 x t \textbf{x}_t xt的标签就可以根据以下式子来判定:
y = { 1 , i f w ∗ x t + b > 0 1 , i f w ∗ x t + b < 0 y = \begin{cases} 1,if \textbf{w}*\textbf{x}_t+b>0 \\ 1,if \textbf{w}*\textbf{x}_t+b<0 \end{cases} y={1,ifw∗xt+b>01,ifw∗xt+b<0
| 核心误区:p和r的符号 |
|---|
| 在这里,p和r的符号是人为规定的。存在这样的误解:认为p和r的符号是由原本的决策边界上下移动得到的(向上平移应该是截距增加,即在b后加上一个正数,变换到等号的另一边就是一个负数,与p>0不吻合,所以,p和r的符号不完全是平移的结果),或是认为“直线以上的点代入直线为正,直线以下的点代入直线为负”是直线的性质(一个点在直线的上方究竟会返回什么符号,是和直线的表达式的写法有关的,不是直线上的点都为正,直线下的点都为负)。p和r的符号主要是为了后续计算和推导的简便,这种规定不会影响对参数向量 w \textbf{w} w和截距 b b b的求解。 |
决策边界的两边要有两个超平面,这两个超平面在空间中就是两条平行线,他们之间的距离就是边际 d d d。这条决策边界位于两条线的中间,所以这两条平行线必然是对称的。令这两条平乡线表示为:
w ∗ x + b = k , w ∗ x + b = − k \textbf{w}*\textbf{x}+b = k,\textbf{w}*\textbf{x}+b = -k w∗x+b=k,w∗x+b=−k
两个表达式同时除以 k k k,则可以得到:
w ∗ x + b = 1 , w ∗ x + b = − 1 \textbf{w}*\textbf{x}+b = 1,\textbf{w}*\textbf{x}+b = -1 w∗x+b=1,w∗x+b=−1
这就是平行于决策边界的两条线的表达式,表达式两边的1和-1分别表示了两条平行于决策边界的虚线到决策边界的相对距离。可以让这两条线分别过两类数据中距离决策边界最近的点,这些点被称为“支持向量”,而决策边界永远在这两条线的中间,所以是可以被调整的。令紫色类的点为 x p x_p xp,红色类的点为 x r x_r xr,可以得到:
w ∗ x p + b = 1 , w ∗ x r + b = − 1 \textbf{w}*\textbf{x}_p+b = 1,\textbf{w}*\textbf{x}_r+b = -1 w∗xp+b=1,w∗xr+b=−1
两式相减,可得:
w ∗ ( x p − x r ) = 2 \textbf{w}*(\textbf{x}_p-\textbf{x}_r) = 2 w∗(xp−xr)=2

如图所示, ( x p − x r ) (\textbf{x}_p-\textbf{x}_r) (xp−xr)可表示为两点之间的连线,由于边际 d d d是平行于 w \textbf{w} w的,所以现在相当于是得到了三角形中的斜边,并且已知一条直角边的方向。根据线性代数中的数学性质(线性代数中模长的运用:向量b除以自身的模长||b||可以得到b方向上的单位向量;向量a乘以向量b方向上的单位向量,就可以得到向量a在向量b方向上的投影长度),将上式两边同时除以 ∣ ∣ w ∣ ∣ ||w|| ∣∣w∣∣,可以得到:
w ∗ ( x p − x r ) ∣ ∣ w ∣ ∣ = 2 ∣ ∣ w ∣ ∣ \frac{\textbf{w}*(\textbf{x}_p-\textbf{x}_r)}{||w||} = \frac{2}{||w||} ∣∣w∣∣w∗(xp−xr)=∣∣w∣∣2
d = 2 ∣ ∣ w ∣ ∣ d = \frac{2}{||w||} d=∣∣w∣∣2
别忘了!目标是最大边界所对应的决策边界,而要最大化 d d d,就是要求解 ∣ ∣ w ∣ ∣ ||w|| ∣∣w∣∣的最小值。极值问题可以相互转化,把求解 ∣ ∣ w ∣ ∣ ||w|| ∣∣w∣∣的最小值转化为求解以下函数的最小值:(之所以要在模长上加上平方,是因为模长的本质是一个距离,所以它是带根号的,对其取平方是为了消除根号,并且模长的本质是向量 w \textbf{w} w的L2范式。)
f ( w ) = ∣ ∣ w ∣ ∣ 2 2 f(w) = \frac{||w||^2}{2} f(w)=2∣∣w∣∣2
由于两条虚线表示的超平面,是数据边缘所在的点,因此对于任意样本 i i i,都可以把决策函数写作:
w ∗ x i + b > = 1 , i f y i = 1 \textbf{w}*\textbf{x}_i+b>=1,if y_i = 1 w∗xi+b>=1,ifyi=1
w ∗ x i + b < = − 1 , i f y i = − 1 \textbf{w}*\textbf{x}_i+b<=-1,if y_i = -1 w∗xi+b<=−1,ifyi=−1
整理一下,可以把两个式子整合成:
y i ( w ∗ x i + b ) > = 1 , i = 1 , 2 , . . . . . . , N y_i(\textbf{w}*\textbf{x}_i+b)>=1,i = 1,2,......,N yi(w∗xi+b)>=1,i=1,2,......,N(这个式子被称为“函数间隔”)
将函数间隔作为条件附加到 f ( w ) f(w) f(w)上,就得到了SVM的损失函数的最初形态:
m i n ∣ ∣ w 2 ∣ ∣ 2 , s . t . y i ( w ∗ x i + b ) > = 1 , i = 1 , 2 , . . . . . . , N min\frac{||\textbf{w}^2||}{2},s.t. y_i(\textbf{w}*\textbf{x}_i+b)>=1,i = 1,2,......,N min2∣∣w2∣∣,s.t.yi(w∗xi+b)>=1,i=1,2,......,N
至此,就完成了对SVM第一层理解的第一部分:线性SVM做二分类的损失函数。
2.1.2 函数间隔与几何间隔
| 重要定义:函数间隔和几何间隔 |
|---|
| 对于给定的数据集T和超平面 ( w , b ) (w,b) (w,b),定义超平面 ( w , b ) (w,b) (w,b)关于样本点 ( x i , y i ) (x_i,y_i) (xi,yi)的函数间隔为: |
| γ i = y i ( w ∗ x i + b ) \gamma_i = y_i(\textbf{w}*\textbf{x}_i+b) γi=yi(w∗xi+b),这其实是虚线超平面的表达式整理过后得到的式子。函数间隔可以表示分类预测的正确性以及确信度。在这个函数间隔的基础上,除以 w \textbf{w} w的模长 k k k来得到几何间隔: γ i = y i ( w k x i + b k ) \gamma_i = y_i(\frac{w}{k}x_i+\frac{b}{k}) γi=yi(kwxi+kb),几何间隔的本质其实就是点 x i x_i xi到超平面 ( w , b ) (w,b) (w,b)的距离,即决策边界的带符号的距离(signed distance)。 |
**为什么几何间隔能够表示点到决策边界的距离?**从点到直线的距离公式出发,对于平面上的一个点 ( x 0 , y 0 ) (x_0,y_0) (x0,y0)和一条直线 a x + b y + c = 0 ax+by+c=0 ax+by+c=0,可以推导出点到直线的距离为:
d i s t a n c e = a x 0 + b y 0 + c a 2 + b 2 distance = \frac{a_x0+by_0+c}{\sqrt{a^2+b^2}} distance=a2+b2ax0+by0+c
其中 [ a , b ] [a,b] [a,b]就是直线的参数向量 w \textbf{w} w,而 a 2 + b 2 \sqrt{a^2+b^2} a2+b2其实就是参数向量 w \textbf{w} w的模长 ∣ ∣ w ∣ ∣ ||w|| ∣∣w∣∣。而几何间隔中, y i y_i yi的取值是{-1,1},所以并不影响整个表达式的大小,只影响方向。而 w x + b = 0 wx+b=0 wx+b=0是决策边界,所以直线代入 x i x_i xi后再除以参数向量的模长,就可以得到点 x i x_i xi到决策边界的距离。
2.1.3 线性SVM的拉格朗日对偶函数和决策函数
在sklearn中,作为使用者完全无法干涉这个求解的过程。前面得到了线性SVM损失函数的最初形态:
m i n ∣ ∣ w 2 ∣ ∣ 2 , s . t . y i ( w ∗ x i + b ) > = 1 , i = 1 , 2 , . . . . . . , N min\frac{||\textbf{w}^2||}{2},s.t. y_i(\textbf{w}*\textbf{x}_i+b)>=1,i = 1,2,......,N min2∣∣w2∣∣,s.t.yi(w∗xi+b)>=1,i=1,2,......,N
这个损失函数分为两部分:需要最小化的函数,以及参数求解后必须满足的约束条件。这是一个最优化问题。
2.1.3.1 将损失函数从最初形态转换为拉格朗日乘数形态
-
为什么要进行转换?
目标是求解让损失函数最小化的 w \textbf{w} w,从目标函数很容易看出,如果 ∣ ∣ w ∣ ∣ ||w|| ∣∣w∣∣为0, f ( w ) f(w) f(w)必然是最小了。但 ∣ ∣ w ∣ ∣ = 0 ||w||=0 ∣∣w∣∣=0其实是一个无效的值,原因是:首先决策边界是 w ∗ x + b = 0 \textbf{w}*\textbf{x}+b = 0 w∗x+b=0,如果 w \textbf{w} w为0,则这个向量里面包含的所有元素都为0,则就有 b = 0 b=0 b=0这个唯一值。然后如果 b b b和 w \textbf{w} w都为0,决策边界就不再是一条直线了,函数间隔 y i ( w ∗ x i + b ) y_i(\textbf{w}*\textbf{x}_i+b) yi(w∗xi+b)就会为0,条件中的 y i ( w ∗ x i + b ) > = 1 y_i(\textbf{w}*\textbf{x}_i+b)>=1 yi(w∗xi+b)>=1也就不会实现,所以 w \textbf{w} w不可能是一个 0 \textbf{0} 0向量。可见,单纯让 f ( w ) = ∣ ∣ w ∣ ∣ 2 2 f(w) = \frac{||w||^2}{2} f(w)=2∣∣w∣∣2为0,是不能求解出合理的 w \textbf{w} w的。为了求解出合理的 w \textbf{w} w,且满足条件,可以想到使用拉格朗日乘数法(standard Lagrange multiplier method)。 -
为什么可以进行转换?
损失函数是二次的(quadratic),并且损失函数中的约束条件在参数 w \textbf{w} w和 b b b下是线性的,求解这个损失函数被称为“凸优化问题”(convex optimization problem)。拉格朗日乘数法正好可以用来解决凸优化问题,这种方法也是业界常用的,用来解决带约束条件,尤其是带有不等式约束条件的函数的数学方法。
首先需要使用拉格朗日乘数法来将损失函数改写为考虑了约束条件的形式: L ( w , b , α ) = 1 2 ∣ ∣ w ∣ ∣ 2 − ∑ i = 1 N α i ( y i ( w ∗ x i + b ) − 1 ) ( α i > = 0 ) L(w,b,\alpha) = \frac{1}{2}||w||^2-\sum_{i=1}^N\alpha_i(y_i(\textbf{w}*\textbf{x}_i+b)-1)(\alpha_i>=0) L(w,b,α)=21∣∣w∣∣2−i=1∑Nαi(yi(w∗xi+b)−1)(αi>=0)上式被称为拉格朗日函数,其中 α i \alpha_i αi被称为拉格朗日乘数。此时要求解的就不只是参数向量 w \textbf{w} w和截距 b b b了,还要求解朗格朗日乘数 α i \alpha_i αi,而 x i x_i xi和 y i y_i yi都是已知的特征矩阵和标签。 -
怎样进行转换?
朗格朗日函数也是分为两部分:第一部分和原始的损失函数一样,第二部分呈现了带有不等式的约束条件。希望 L ( w , b , α ) L(w,b,\alpha) L(w,b,α)不仅能够代表原有的损失函数 f ( w ) f(w) f(w)和约束条件,还能够表示想要最小化损失函数来求解 w \textbf{w} w和 b b b的目的,因此要先以 α \alpha α为参数,求解 L ( w , b , α ) L(w,b,\alpha) L(w,b,α)的最大值,再以 w \textbf{w} w和 b b b为参数,求解 L ( w , b , α ) L(w,b,\alpha) L(w,b,α)的最小值。因此,目标可写作: min w , b max α i > = 0 L ( w , b , α ) \min_{w,b}\max_{\alpha_i>=0}L(w,b,\alpha) w,bminαi>=0maxL(w,b,α)首先,第一步先执行max,即最大化 L ( w , b , α ) L(w,b,\alpha) L(w,b,α),则有两种情况:(1)当 y i ( w ∗ x i + b ) > 1 y_i(\textbf{w}*\textbf{x}_i+b)>1 yi(w∗xi+b)>1,函数的第二部分 ∑ i = 1 N α i ( y i ( w ∗ x i + b ) − 1 ) \sum_{i=1}^N\alpha_i(y_i(\textbf{w}*\textbf{x}_i+b)-1) ∑i=1Nαi(yi(w∗xi+b)−1)就一定为正,式子 1 2 ∣ ∣ w ∣ ∣ 2 \frac{1}{2}||w||^2 21∣∣w∣∣2就要减去一个正数,此时若要最大化 L ( w , b , α ) L(w,b,\alpha) L(w,b,α),则 α \alpha α必须取到0;(2)当 y i ( w ∗ x i + b ) < 1 y_i(\textbf{w}*\textbf{x}_i+b)<1 yi(w∗xi+b)<1,函数的第二部分 ∑ i = 1 N α i ( y i ( w ∗ x i + b ) − 1 ) \sum_{i=1}^N\alpha_i(y_i(\textbf{w}*\textbf{x}_i+b)-1) ∑i=1Nαi(yi(w∗xi+b)−1)就一定为负,式子 1 2 ∣ ∣ w ∣ ∣ 2 \frac{1}{2}||w||^2 21∣∣w∣∣2就要减去一个负数,相当于加上一个正数,此时若要最大化 L ( w , b , α ) L(w,b,\alpha) L(w,b,α),则 α \alpha α必须取到正无穷。
若把函数第二部分当作一个惩罚项来看待,则 y i ( w ∗ x i + b ) y_i(\textbf{w}*\textbf{x}_i+b) yi(w∗xi+b)大于1时函数没有受到惩罚,而 y i ( w ∗ x i + b ) y_i(\textbf{w}*\textbf{x}_i+b) yi(w∗xi+b)小于1时函数受到了极致的惩罚,即加上了一个正无穷项,函数整体永远不可能取到最小值。所以,第二步执行min的命令,求解函数整体的最小值,永远不能让 α \alpha α必须取到正无穷的状况出现,即是说永远不让 y i ( w ∗ x i + b ) < 1 y_i(\textbf{w}*\textbf{x}_i+b)<1 yi(w∗xi+b)<1的状况出现,从而实现求解最小值的同时让约束条件被满足。
2.1.3.2 将拉格朗日函数转换为拉格朗日对偶函数
- 为什么要进行转换?
要求极值,最简单的方法还是对参数求导后让一阶导数等于0.

由于两个求偏导的结果中都带有未知的拉格朗日乘数 α i \alpha_i αi,因此还是无法求解出 w \textbf{w} w和 b b b。而拉格朗日函数可以被转换为一种只带有 α i \alpha_i αi,而不带有 w \textbf{w} w和 b b b的形式,这种形式被称为拉格朗日对偶函数。在对偶函数下,就可以求解出拉格朗日乘数 α i \alpha_i αi,然后代入上面推导的(1)和(2)式中来求解 w \textbf{w} w和 b b b。 - 为什么能够进行转换?
对于任何一个拉格朗日函数 L ( x , α ) = f ( x ) + ∑ i = 1 q α i h i ( x ) L(x,\alpha) = f(x)+\sum_{i=1}^q\alpha_ih_i(x) L(x,α)=f(x)+∑i=1qαihi(x),都存在一个与之对应的对偶函数 g ( α ) g(\alpha) g(α),只带有拉格朗日乘数 α \alpha α作为唯一的参数。如果 L ( x , α ) L(x,\alpha) L(x,α)的最优解存在并可以表示为 min x L ( x , α ) \min_xL(x,\alpha) minxL(x,α),并且对偶函数的最优解也存在并可以表示为 max α g ( α ) \max_{\alpha}g(\alpha) maxαg(α),则可以定义对偶差异(dual gap),即拉格朗日函数的最优解与其对偶函数的最优解之间的差值: Δ = min x L ( x , α ) − max α g ( α ) \Delta = \min_xL(x,\alpha)-\max_{\alpha}g(\alpha) Δ=xminL(x,α)−αmaxg(α)如果 Δ = 0 \Delta=0 Δ=0,则称 L ( x , α ) L(x,\alpha) L(x,α)与其对偶函数之间存在强对偶关系(strong duality property),此时就可以通过求解对偶函数的最优解来替代求解原始函数的最优解。
那强对偶关系什么时候存在呢?拉格朗日函数必须满足KKT(Karush-Kun-Tucker)条件:
∂ L ∂ x i = 0 , ∀ i = 1 , 2 , . . . . . . , d \frac{\partial L}{\partial x_i} = 0,\forall_i = 1,2,......,d ∂xi∂L=0,∀i=1,2,......,d
h i ( x ) < = 0 , ∀ i = 1 , 2 , . . . . . . , q h_i(x)<=0,\forall_i =1,2,......,q hi(x)<=0,∀i=1,2,......,q
α i > = 0 , ∀ i = 1 , 2 , . . . . . . , q \alpha_i>=0,\forall_i = 1,2,......,q αi>=0,∀i=1,2,......,q
α i h i ( x ) = 0 , ∀ i = 1 , 2 , . . . . . . , q \alpha_ih_i(x)=0,\forall_i = 1,2,......,q αihi(x)=0,∀i=1,2,......,q
这里的条件其实都比较好理解。首先是所有参数的一阶导数必须为0,然后约束条件中的函数本身需要小于等于0,拉格朗日乘数需要大于等于0,以及约束条件乘以拉格朗日乘数必须等于0,即不同 i i i的取值下,两者之中至少有一个为0。当所有限制都被满足,则拉格朗日函数 L ( x , α ) L(x,\alpha) L(x,α)的最优解与其对偶函数的最优解相等,就可以将原始的最优化问题转换成对偶函数的最优化问题。对于损失函数 L ( w , b , α ) L(w,b,\alpha) L(w,b,α)而言,KKT条件都是可以操作的。如果能够人为的让KKT条件全部成立,就可以求解出 L ( w , b , α ) L(w,b,\alpha) L(w,b,α)的对偶函数来求解出 α \alpha α。
让拉格朗日函数对参数 w \textbf{w} w和 b b b的求导为0,得到: ∑ i = 1 N α i y i x i = w , ( 1 ) \sum_{i=1}^N\alpha_iy_i\textbf{x}_i = \textbf{w},(1) i=1∑Nαiyixi=w,(1) ∑ i = 1 N α i y i = 0 , ( 2 ) \sum_{i=1}^N\alpha_iy_i = 0,(2) i=1∑Nαiyi=0,(2)并且在函数中,通过先求解最大值再求解最小值的方法使得函数天然满足:
− y i ( w ∗ x i + b ) < = 0 -y_i(\textbf{w}*\textbf{x}_i+b)<=0 −yi(w∗xi+b)<=0,(3)
α i > = 0 \alpha_i>=0 αi>=0,(4)
所以,接下来只需要再满足一个条件:
α i ( y i ( w ∗ x i + b ) − 1 ) = 0 \alpha_i(y_i(\textbf{w}*\textbf{x}_i+b)-1)=0 αi(yi(w∗xi+b)−1)=0,(5)
这个条件其实很容易满足,能够让 y i ( w ∗ x i + b ) − 1 = 0 y_i(\textbf{w}*\textbf{x}_i+b)-1=0 yi(w∗xi+b)−1=0的就是落在虚线的超平面上的样本点,即支持向量。所有不是支持向量的样本点则必须满足 α i = 0 \alpha_i=0 αi=0。满足这个式子说明:求解的参数 w \textbf{w} w和 b b b以及求解的超平面的存在,只与支持向量相关,与其他样本点都无关。现在KKT的五个条件都满足了,就可以使用 L ( w , b , α ) L(w,b,\alpha) L(w,b,α)的对偶函数来求解 α \alpha α了。 - 如何进行转换?
首先让拉格朗日函数对参数 w \textbf{w} w和 b b b求导后的结果为0,本质是在探索拉格朗日函数的最小值,然后:


函数 L d L_d Ld就是对偶函数。对所有存在对偶函数的拉格朗日函数,有对偶差异表示如下: Δ = min x L ( x , α ) − max α g ( α ) \Delta = \min_xL(x,\alpha)-\max_{\alpha}g(\alpha) Δ=xminL(x,α)−αmaxg(α)对于 L ( w , b , α ) L(w,b,\alpha) L(w,b,α)和 L d L_d Ld,则有: Δ = min w , b max α i > = 0 L ( w , b , α ) − max α i > = 0 L d \Delta = \min_{w,b}\max_{\alpha_i>=0}L(w,b,\alpha)-\max_{\alpha_i>=0}L_d Δ=w,bminαi>=0maxL(w,b,α)−αi>=0maxLd
在推导 L d L_d Ld的过程中,第一步是对 L ( w , b , α ) L(w,b,\alpha) L(w,b,α)求偏导,并让偏导数都为0,所以求解对偶函数的过程其实是在求解 L ( w , b , α ) L(w,b,\alpha) L(w,b,α)的最小值。因此可以把公式写作: Δ = min w , b max α i > = 0 L ( w , b , α ) − max α i > = 0 min w , b L ( w , b , α ) \Delta = \min_{w,b}\max_{\alpha_i>=0}L(w,b,\alpha)-\max_{\alpha_i>=0\min_{w,b}L(w,b,\alpha)} Δ=w,bminαi>=0maxL(w,b,α)−αi>=0minw,bL(w,b,α)max由于KKT条件被满足,所以 min w , b max α i > = 0 L ( w , b , α ) = max α i > = 0 min w , b L ( w , b , α ) \min_{w,b}\max_{\alpha_i>=0}L(w,b,\alpha)=\max_{\alpha_i>=0\min_{w,b}L(w,b,\alpha)} w,bminαi>=0maxL(w,b,α)=αi>=0minw,bL(w,b,α)max这也就是对偶函数和原始函数的转化过程的由来。如此,只需要求解对偶函数的最大值,就可以求出 α \alpha α了。最终,目标函数也就转化为: max α i > = 0 ( ∑ i = 1 N α i − 1 2 ∑ i , j = 1 N α i α j y i y j x i ∗ x j ) \max_{\alpha_i>=0}(\sum_{i=1}^N\alpha_i-\frac{1}{2}\sum_{i,j=1}^N\alpha_i\alpha_jy_iy_j\textbf{x}_i*\textbf{x}_j) αi>=0max(i=1∑Nαi−21i,j=1∑Nαiαjyiyjxi∗xj)
2.1.3.3 求解拉格朗日对偶函数极其后续过程
到这一步,就需要使用梯度下降、SMO或者二次规划(QP,quadratic programming)来求解 α \alpha α。一旦求得了 α \alpha α值,就可以使用上面的(1)式求解 w \textbf{w} w,并使用(1)式和决策边界的表达式结合,得到下式来求解 b b b: ∑ i = 1 N α i y i x i ∗ x + b = 0 \sum_{i=1}^N\alpha_iy_i\textbf{x}_i*x+b = 0 i=1∑Nαiyixi∗x+b=0当求得参数向量 w \textbf{w} w和 b b b,就得到了决策边界的表达式,也就可以利用决策边界和其有关的超平面来进行分类了。决策函数可以被写作: f ( x t e s t ) = s i g n ( w ∗ x t e s t + b ) = s i g n ( ∑ i = 1 N α i y i x i ∗ x t e s t + b ) f(x_{test}) = sign(\textbf{w}*\textbf{x}_{test}+b)=sign(\sum_{i=1}^N\alpha_iy_i\textbf{x}_i*\textbf{x}_{test}+b) f(xtest)=sign(w∗xtest+b)=sign(i=1∑Nαiyixi∗xtest+b)其中 x t e s t \textbf{x}_{test} xtest是任意测试样本, s i g n ( h ) sign(h) sign(h)是 h > 0 h>0 h>0时返回1, h < 0 h<0 h<0是返回-1的符号函数。
2.1.4 线性SVM决策过程的可视化
可以使用sklearn来可视化决策边界、支持向量以及决策边界平行的两个超平面。
#导入需要的模块
from sklearn.datasets import make_blobs
from sklearn.svm import SVC
import matplotlib.pyplot as plt
import numpy as np
#实例化数据集,可视化数据集
x,y = make_blobs(n_samples = 50,centers = 2,random_state = 0,cluster_std = 0.6)
plt.scatter(x[:,0],x[:,1],c = y,s = 50,cmap = "rainbow")
plt.xticks([])
plt.yticks([])
plt.show()

画决策边界,先理解函数contour
- matplotlib.axes.Axes.contour([X,Y,]Z,[levels],**kwargs)
Contour是专门用来绘制等高线的函数。等高线本质上是二维图像上表现三维图像的一种形式,其中两维X和Y是两条坐标轴上的取值,而Z表示高度。Contour就是将由X和Y构成平面上的所有点中高度一致的连接成线段的函数,在同一条等高线上的点一定具有相同的Z值。利用这个性质就可以绘制决策边界。
| 参数 | 含义 |
|---|---|
| X,Y | 选填。两维平面上所有的点的横纵坐标取值,一般要求是二维结构并且形状需要与Z相同,往往通过numpy.meshgrid()这样的函数来创建。如果X和Y都是一维的,则Z的结构必须为(len(Y),len(X))。如果不填写则默认X=range(Z.shape[1]),Y=range(Z.shape[0])。 |
| Z | 必填。平面上所有的点所对应的高度。 |
| levels | 可不填,不填则默认显示所有的等高线,填写用于确定等高线的数量和位置。如果填写整数n,则显示n个数据区间,即绘制n+1条等高线。水平高度自动选择。如果填写的是数组和列表,则在指定的高度级别绘制等高线。列表或数组中的值必须按递增顺序排列。 |
决策边界是 w ∗ x + b = 0 \textbf{w}*\textbf{x}+b=0 w∗x+b=0,并在决策边界的两边找出两个超平面,使得超平面到决策边界的相对距离为1。只需要在样本构成的平面上,把所有到决策边界的距离为0的点相连,就是决策边界,而把所有到决策边界的相对距离为1的点相连,就是两个平行于决策边界的超平面了。此时,Z就是平面上的任意点到达超平面的距离。
首先需要获取样本构成的平面,作为一个对象。
#首先要有散点图
plt.scatter(x[:,0],x[:,1],c = y,s = 50,cmap = "rainbow")
ax = plt.gca()#获取当前的子图,如果不存在,则创建新的子图

有了这个平面,还需要在平面上制作一个足够细的网格,来代表“平面上所有的点”,不止是样本点。
#理解函数meshgrid和vstack的作用
a = np.array([1,2,3])
b = np.array([7,8])
#两两组合,会得到多少个坐标?
#答案是6个,分别是(1,7),(2,7),(3,7),(1,8),(2,8),(3,8)
v1,v2 = np.meshgrid(a,b)
v1
#结果:array([[1, 2, 3],
# [1, 2, 3]])
v2
#结果:array([[7, 7, 7],
# [8, 8, 8]])
v = np.vstack([v1.ravel(),v2.ravel()]).T
v
#结果:array([[1, 7],
# [2, 7],
# [3, 7],
# [1, 8],
# [2, 8],
# [3, 8]])
#画决策边界:制作网格,理解函数meshgrid
#获取平面上两条坐标轴的最大值和最小值
xlim = ax.get_xlim()
ylim = ax.get_ylim()
#在最大值和最小值之间形成30个规律的数据
axisx = np.linspace(xlim[0],xlim[1],30)
axisy = np.linspace(ylim[0],ylim[1],30)
axisy,axisx = np.meshgrid(axisy,axisx)
#将使用这里形成的二维数组作为contour函数中的X和Y
#使用meshgrid函数将两个一维向量转换为特征矩阵
#核心是将两个特征向量广播,以便获取y.shape*x.shape这么多个坐标点的横坐标和纵坐标
xy = np.vstack([axisx.ravel(),axisy.ravel()]).T
#其中ravel()是降维函数,vstack能够将多个结构一致的一维数组按行堆叠起来
#xy就是已经形成的网格,它是遍布在整个画布上的密集的点
plt.scatter(xy[:,0],xy[:,1],s=1,cmap = "rainbow")
有了网格之后,需要计算网格所代表的“平面上所有的点”到决策边界的距离,所以需要模型和决策边界。
#建模,计算决策边界并找出网格上每个点到决策边界的距离
#建模,通过fit计算出对应的决策边界
clf = SVC(kernel = "linear").fit(x,y)
z = clf.decision_function(xy).reshape(axisx.shape)
#重要接口decision_function,返回每个输入的样本所对应的到决策边界的距离
#然后再将这个距离转换为axisx的结构,这是由于画图的函数contour要求z的结构必须与x和y保持一致
#画决策边界和平行于决策边界的超平面
ax.contour(axisx,axisy,z
,colors = "k"
,levels = [-1,0,1]#画三条等高线,分别是z为-1,z为0和z为1的三条线
,alpha = 0.5
,linestyles = ["--","-","--"])
ax.set_xlim(xlim)
ax.set_ylim(ylim)
#z的本质是输入的样本到决策边界的距离,而contour函数中的level其实是输入了这个距离
#用一个点来验证
plt.scatter(x[:,0],x[:,1],c = y,s = 50,cmap = "rainbow")
plt.scatter(x[10,0],x[10,1],c = "black",s = 50,cmap = "rainbow")
clf.decision_function(x[10].reshape(1,2))
#结果:array([-3.33917354])
plt.scatter(x[:,0],x[:,1],c = y,s = 50,cmap = "rainbow")
ax=plt.gca()
ax.contour(axisx,axisy,z
,colors = "k"
,levels = [-3.33917354]
,alpha = 0.5
,linestyles = ["--"])

#将绘图过程包装成函数
def plot_svc_decision_function(model,ax = None):
if ax is None:
ax = plt.gca()
xlim = ax.get_xlim()
ylim = ax.get_ylim()
x = np.linspace(xlim[0],xlim[1],30)
y = np.linspace(ylim[0],ylim[1],30)
Y,X = np.meshgrid(y,x)
xy = np.vstack([X.ravel(),Y.ravel()]).T
P = model.decision_function(xy).reshape(X.shape)
ax.contour(X,Y,P,colors = "k",levels = [-1,0,1],alpha = 0.5,linestyles = ["--","-","--"])
ax.set_xlim(xlim)
ax.set_ylim(ylim)
#整个绘图过程可以写作:
clf = SVC(kernel = "linear").fit(x,y)
plt.scatter(x[:,0],x[:,1],c = y,s = 50,cmap = "rainbow")
plot_svc_decision_function(clf)

#探索建好的模型
clf.predict(x)
#根据决策边界,对x中的样本进行分类,返回的结构为n_samples
#结果:array([1, 1, 0, 0, 1, 1, 1, 1, 1, 0, 0, 0, 0, 1, 0, 0, 0, 1, 0, 0, 1, 1,
# 1, 1, 1, 0, 0, 0, 1, 0, 1, 0, 0, 0, 0, 1, 1, 0, 1, 0, 1, 0, 1, 1,
# 0, 1, 1, 0, 1, 0])
clf.score(x,y)
#返回给定测试数据和标签的平均准确度
#结果:1.0
clf.support_vectors_
#返回支持向量
#结果:array([[0.44359863, 3.11530945],
# [2.33812285, 3.43116792],
# [2.06156753, 1.96918596]])、
clf.n_support_
#返回每个类中支持向量的个数
#结果:array([2, 1])
前面的原理及绘图过程,都是基于数据本身是线性可分的情况。接下来将数据推广到非线性的情况。
#推广到非线性情况
from sklearn.datasets import make_circles
x,y = make_circles(100, factor = 0.1,noise = 0.1)
x.shape
#结果:(100, 2)
y.shape
#结果:(100,)
plt.scatter(x[:,0],x[:,1],c = y,s = 50,cmap = "rainbow")
plt.show()

尝试用已经定义的函数来划分这个数据集的决策边界。
clf = SVC(kernel = "linear").fit(x,y)
plt.scatter(x[:,0],x[:,1],c = y,s = 50,cmap = "rainbow")
plot_svc_decision_function(clf)
clf.score(x,y)
#结果:0.69
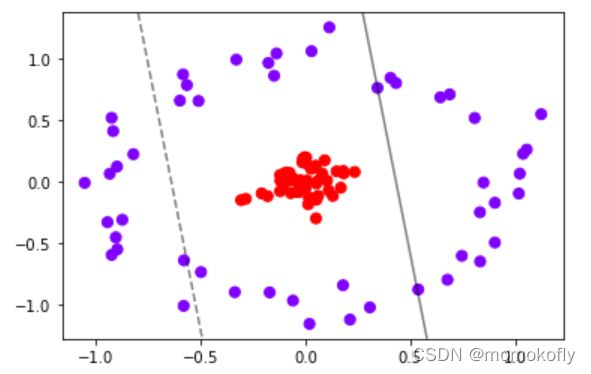
很明显,线性SVM已经不适合当前的数据集了,无法找到一条直线来划分数据集,使得直线的两边分别是两种类别。这个时候如果能够在原本的x和y的基础上,添加一个维度r,变成三维,可视化这个数据观察添加维度使得数据如何变化。
#为非线性数据增加维度并绘制3D图像
#定义一个由x计算出来的新维度r
r = np.exp(-(x**2).sum(1))
rlim = np.arange(min(r),max(r),0.2)
#
from mpl_toolkits import mplot3d
#定义一个绘制三维图像的函数
#elev表示上下旋转的角度
#azim表示平行旋转的角度
def plot_3D(elev = 30,azim = 30,x = x,y = y):
ax = plt.subplot(projection = "3d")
ax.scatter(x[:,0],x[:,1],r,c=y,s=50,cmap = "rainbow")
ax.view_init(elev = elev,azim = azim)
ax.set_xlabel("x")
ax.set_ylabel("y")
ax.set_zlabel("r")
plt.show()
plot_3D()

可以看到,此时数据明显是线性可分的了。可以使用一个平面来将数据完全分开,并使得平面上方的所有数据点为一类,平面下方的所有数据点为另一类。
#如果放到jupyter notebook中运行
from sklearn.svm import SVC
import matplotlib.pyplot as plt
import numpy as np
from sklearn.datasets import make_circles
x,y = make_circles(100,factor = 0.1,noise = 0.1)
plt.scatter(x[:,0],x[:,1],c=y,s=50,cmap="rainbow")
def plot_svc_decision_function(model,ax = None):
if ax is None:
ax = plt.gca()
xlim = ax.get_xlim()
ylim = ax.get_ylim()
x = np.linspace(xlim[0],xlim[1],30)
y = np.linspace(ylim[0],ylim[1],30)
Y,X = np.meshgrid(y,x)
xy = np.vstack([X.ravel(),Y.ravel()]).T
P = model.decision_function(xy).reshape(X.shape)
ax.contour(X,Y,P,colors = "k",levels = [-1,0,1],alpha = 0.5,linestyles = ["--","-","--"])
ax.set_xlim(xlim)
ax.set_ylim(ylim)
clf = SVC(kernel = "linear").fit(x,y)
plt.scatter(x[:,0],x[:,1],c=y,s=50,cmap="rainbow")
plot_svc_decision_function(clf)
r = np.exp(-(x**2).sum(1))
rlim = np.arange(min(r),max(r),0.2)
from mpl_toolkits import mplot3d
def plot_3D(elev = 30,azim = 30,x = x,y = y):
ax = plt.subplot(projection = "3d")
ax.scatter3D(x[:,0],x[:,1],r,c = y,s = 50,cmap = "rainbow")
ax.view_init(elev = elev,azim = azim)
ax.set_xlabel("x")
ax.set_ylabel("y")
ax.set_zlabel("r")
plt.show()
from ipywidgets import interact,fixed
interact(plot_3D,elev=[0,30,60,90,120],azim = (-180,180),x = fixed(x),y = fixed(y))
plt.show()
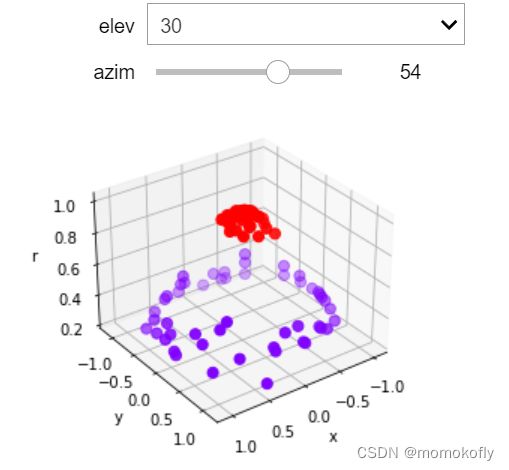
此时数据在三维空间中,超平面就是一个二维平面。明显可以用一个平面将两类数据隔开,这个平面就是决策边界。在这一过程中,计算r,并将r作为数据的第三维度来量数据升维的过程,被称为“核变换”,即是将数据投影到高维空间中,以寻找能够将数据完美分割的超平面。
2.2 非线性SVM与核函数
2.2.1 SVC在非线性数据上的推广
为了能够找出非线性数据的线性决策边界,需要将数据从原始的空间 x \textbf{x} x投射到新空间 Φ ( x ) \Phi(\textbf{x}) Φ(x)中。 Φ \Phi Φ是映射函数,它代表了某种非线性的变换,如同之前使用r来升维一样,这种非线性变换看起来是非常有效的方式。使用这种变换,线性SVM的原理可以被很容易推广到非线性情况下,其推导过程和逻辑都与线性SVM一模一样,只不过在定义决策边界之前,必须先对数据进行升维度,即将原始的 x x x转换成 Φ ( x ) \Phi(x) Φ(x)。
那么,非线性SVM的损失函数的初始形态为: min w , b ∣ ∣ w ∣ ∣ 2 2 , s . t . y i ( w ∗ Φ ( x i ) + b > = 1 ) , i = 1 , 2 , . . . . . . , N \min_{w,b}\frac{||w||^2}{2},s.t.y_i(\textbf{w}*\Phi(\textbf{x}_i)+b>=1),i=1,2,......,N w,bmin2∣∣w∣∣2,s.t.yi(w∗Φ(xi)+b>=1),i=1,2,......,N同理,非线性SVM的拉格朗日函数和拉格朗日对偶函数为: L ( w , b , α ) = 1 2 ∣ ∣ w ∣ ∣ 2 − ∑ i = 1 N α i ( y i ( w ∗ Φ ( x i ) + b ) − 1 ) L(w,b,\alpha)=\frac{1}{2}||w||^2-\sum_{i=1}^N\alpha_i(y_i(\textbf{w}*\Phi(\textbf{x}_i)+b)-1) L(w,b,α)=21∣∣w∣∣2−i=1∑Nαi(yi(w∗Φ(xi)+b)−1) L d = ∑ i = 1 N α i − 1 2 ∑ i , j α i α j y i y j Φ ( x i ) Φ ( x j ) L_d=\sum_{i=1}^N\alpha_i-\frac{1}{2}\sum_{i,j}\alpha_i\alpha_jy_iy_j\Phi(\textbf{x}_i)\Phi(\textbf{x}_j) Ld=i=1∑Nαi−21i,j∑αiαjyiyjΦ(xi)Φ(xj)
使用同样的推导方式,让拉格朗日函数满足KKT条件,并在拉格朗日函数上对每个参数求导,经过和线性SVM相同的变换后,就可以得到拉格朗日对偶函数。同样使用梯度下降或SMO等方法对 α \alpha α进行求解,最后可以求得决策边界,并得到最终的决策函数: f ( x t e s t ) = s i g n ( w ∗ Φ ( x t e s t ) + b ) = s i g n ( ∑ i = 1 N α i y i Φ ( x i ) ∗ Φ ( x t e s t ) + b ) f(x_test)=sign(\textbf{w}*\Phi(\textbf{x}_{test})+b)=sign(\sum_{i=1}^N\alpha_iy_i\Phi(\textbf{x}_i)*\Phi(\textbf{x}_{test})+b) f(xtest)=sign(w∗Φ(xtest)+b)=sign(i=1∑NαiyiΦ(xi)∗Φ(xtest)+b)
2.2.2 重要参数kernel
这种变换非常巧妙,但也存在一些现实问题。首先,可能不清楚应该什么样的数据应该使用什么类型的映射函数,来确保可以在变换空间中找出线性决策边界。极端情况下,数据可能会被映射到无限维度的空间中,这种高维空间可能不那么友好。维度越多,推导和计算的难度都会随之暴增。其次,即使已知适当的映射函数,想要计算类似于 Φ ( x i ) ∗ Φ ( x t e s t ) \Phi(\textbf{x}_i)*\Phi(\textbf{x}_{test}) Φ(xi)∗Φ(xtest)这样的点积,计算量可能会无比巨大,要找出超平面所需要的代价是很大的。
| 关键概念:核函数 |
|---|
| 解决这些问题的数学方式,叫做“核技巧(Kernel Trick)”,是一种能够使用数据原始空间中的向量计算来表示升维后的空间中的点积结果的数学方式。具体表现为, K ( u , v ) = Φ ( u ) ⋅ Φ ( v ) K(\textbf{u},\textbf{v})=\Phi(\textbf{u})\cdot\Phi(\textbf{v}) K(u,v)=Φ(u)⋅Φ(v)。而这个原始空间中的点积函数 K ( u , v ) K(\textbf{u},\textbf{v}) K(u,v),就被叫做“核函数(Kernel Function)” |
核函数能够解决三个问题:
- 有了核函数之后,无需担心 Φ \Phi Φ究竟是什么样,因为非线性SVM中的核函数都是正定核函数(positive definite kernel functions),都满足默瑟定律(Mercer’s theorem),确保了高维空间中任意两个向量的点积一定可以被低维空间中的这两个向量的某种计算来表示出来(多数时候是点积的某种变换)。
- 使用核函数计算低纬度中的向量关系比计算原本的 Φ ( x i ) ⋅ Φ ( x t e s t ) \Phi(\textbf{x}_i)\cdot\Phi(\textbf{x}_{test}) Φ(xi)⋅Φ(xtest)要简单太多。
- 因为计算是在原始空间中进行,所以避免了维度诅咒的问题。
选用不用的核函数,就可以解决不同数据分布下寻找超平面的问题。在SVC中,这个功能由参数“kernel”和一系列与核函数相关的参数进行控制。参数“kernel”中可选的选项如下:
| 输入 | 含义 | 解决问题 | 核函数的表达式 | 参数gamma | 参数degree | 参数coef0 |
|---|---|---|---|---|---|---|
| linear | 线性核 | 线性 | K ( x , y ) = x T y = x ⋅ y K(x,y)=x^Ty=x\cdot y K(x,y)=xTy=x⋅y | No | No | No |
| poly | 多项式核 | 偏线性 | K ( x , y ) = ( γ ( x ⋅ y ) + r ) d K(x,y)=(\gamma(x\cdot y)+r)^d K(x,y)=(γ(x⋅y)+r)d | Yes | Yes | Yes |
| sigmoid | 双曲正切核 | 非线性 | K ( x , y ) = t a n h ( γ ( x ⋅ y ) + r ) K(x,y)=tanh(\gamma(x\cdot y)+r) K(x,y)=tanh(γ(x⋅y)+r) | Yes | No | Yes |
| rbf | 高斯径向基 | 偏非线性 | K ( x , y ) = e − γ ∣ ∣ x − y ∣ ∣ 2 , γ > 0 K(x,y)=e^{-\gamma\mid\mid x-y\mid\mid^2},\gamma>0 K(x,y)=e−γ∣∣x−y∣∣2,γ>0 | Yes | No | No |
可以看出,除了选项“linear”之外,其他的核函数都可以处理非线性问题。多项式核函数有次数 d d d。当 d d d为1时,它就是处理线性问题,当 d d d为更高次项时,他就是在处理非线性问题。之前使用的选项是“linear”,自然不能处理环形数据这样的非线性问题。而使用的计算r的方法,其实就是高斯径向基核函数所对应的功能,在参数“kernel”中输入“rbf”就可以使用这种核函数。
clf = SVC(kernel = "rbf").fit(x,y)
plt.scatter(x[:,0],x[:,1],c=y,s=50,cmap="rainbow")
plot_svc_decision_function(clf)

2.2.3 探索核函数在不同数据集上的表现
除了“linear”以外的核函数都能够处理非线性情况,关于“究竟什么时候选择哪一个核函数”这一问题,在不同数据集上的研究甚少,更多研究的是核函数在深度学习、神经网络中如何使用。在sklearn中,也没有提供任何关于如何选取核函数的信息。可以通过在不同的核函数中循环去找到最佳的核函数来对核函数进行选取。本文探索不同数据集上核函数的表现。现在有一系列线性和非线性可分的数据,通过绘制SVC在不同核函数下的决策边界并计算SVC在不同核函数下分类准确率来观察核函数的效用。
#导入所需要的库和模块
import numpy as np
import matplotlib.pyplot as plt
from matplotlib.colors import ListedColormap
from sklearn import svm
from sklearn.datasets import make_circles,make_moons,make_blobs,make_classification
#创建数据集,定义核函数的选择
n_samples = 100
datasets = [
make_moons(n_samples = n_samples,noise = 0.2,random_state = 0),
make_circles(n_samples = n_samples,noise = 0.2,factor = 0.5,random_state = 1),
make_blobs(n_samples = n_samples,centers = 2,random_state = 5),
make_classification(n_samples = n_samples,n_features = 2,n_informative = 2,n_redundant = 0,random_state = 5)]
kernel = ["linear","poly","rbf","sigmoid"]
#四个数据集分别是什么分布
for x,y in datasets:
plt.figure(figsize = [5,4])
plt.scatter(x[:,0],x[:,1],c=y,s=50,cmap = "rainbow")



总共有四个数据集,四种核函数。为了观察每种数据集下每个核函数的表现,以核函数为列,以图像分布为行,总共需要16个子图来展示分类效果。而同时为了观察到图像本身的状况,所以总共需要20个子图,其中第一列是原始图像分布,后面四列分别是这种分布下不同核函数的表现。
#构建子图
nrows = len(datasets)
ncols = len(kernel)+1
fig,axes = plt.subplots(nrows,ncols,figsize = [20,16])

#构建子图
nrows = len(datasets)
ncols = len(Kernel)+1
fig,axes = plt.subplots(nrows,ncols,figsize = [20,16])
#开始进行子图循环
#第一层循环:在不同的数据集中循环
for ds_cnt,(x,y) in enumerate(datasets):
#在图像中的第一列,放置原数据的分布
ax = axes[ds_cnt,0]
if ds_cnt == 0:
ax.set_title("Input data")
ax.scatter(x[:,0],x[:,1],c=y,zorder = 10,cmap = plt.cm.Paired,edgecolors = "k")
ax.set_xticks([])
ax.set_yticks([])
#第二层循环:在不同的核函数中循环
#从图像的第二列开始,一个个填充分类结果
for est_idx,kernel in enumerate(Kernel):
#定义子图位置
ax = axes[ds_cnt,est_idx+1]
#建模
clf = SVC(kernel = kernel,gamma=2).fit(x,y)
score = clf.score(x,y)
#绘制图像本身分布的散点图
ax.scatter(clf.support_vectors_[:,0],clf.support_vectors_[:,1],s=50,facecolors = "none",zorder = 10,edgecolors = "k")
#绘制决策边界
x_min,x_max = x[:,0].min()-0.5,x[:,0].max()+0.5
y_min,y_max = x[:,1].min()-0.5,x[:,1].max()+0.5
#np.mgrid,合并了之前使用的np.linspace和np.meshgrid的用法
#一次性使用最大值和最小值来生成网络
#表示为[起始值:结束值:步长]
#如果步长是复数,则其整数部分就是起始值和结束值之间创建的点的数量,并且结束值被包含在内
xx,yy = np.mgrid[x_min:x_max:200j,y_min:y_max:200j]
#np.c_,类似于np.vstack的功能
z = clf.decision_function(np.c_[xx.ravel(),yy.ravel()]).reshape(xx.shape)
#填充等高线不同区域的颜色
ax.pcolormesh(xx,yy,z>0,cmap = plt.cm.Paired)
#绘制等高线
ax.contour(xx,yy,z,colors = ["k","k","k"],linstyles = ["--","-","--"],levels = [-1,0,1])
#设定坐标轴为不显示
ax.set_xticks([])
ax.set_yticks([])
#将标题放在第一行的顶上
if ds_cnt == 0:
ax.set_title(kernel)
#为每张图添加分类的分数
ax.text(0.95,0.06,("%.2f" % score).lstrip("0")
,size = 15
,bbox = dict(boxstyle = "round",alpha = 0.8,facecolor = "white")
#为分数添加一个白色的格子作为底色
,transform = ax.transAxes#确定文字所对应的坐标轴,就是ax子图的坐标轴本身
,horizontalalignment = "right"#位于坐标轴的什么方向
)
plt.tight_layout()
plt.show()

可以观察到,线性核函数和多项式核函数在非线性数据上表现会浮动,如果数据相对线性可分,则表现不错,如果是像环形数据那样彻底不可分的,则表现糟糕。在线性数据集上,线性核函数和多项式核函数即便有扰动项也可以表现不错,可见多项式核函数虽然也可以处理非线性情况,但更偏向于线性的功能。Sigmoid核函数就比较敢打了,它在非线性数据上强于两个线性核函数,但效果明显不如rbf,它在线性数据上完全比不上线性核函数,对扰动项的抵抗也比较弱,所以它功能比较弱小,很少被用到。高斯径向基核函数rbf基本在任何数据集上都表现不错,属于比较万能的核函数。因此,建议无论如何先试试高斯径向基核函数,它适用于核转换到很高的空间的情况,在各种情况下往往效果都很不错,如果rbf效果不好,再试试其他的核函数。另外,多项式核函数多被用于图像处理之中。
2.2.4 探索核函数的优势和缺陷
看起来,除了Sigmoid核函数,其他核函数效果都还不错。但其实rbf和poly都有自己的弊端,接下来使用乳腺癌数据集为例来探索。
from sklearn.datasets import load_breast_cancer
from sklearn.svm import SVC
from sklearn.model_selection import train_test_split
import matplotlib.pyplot as plt
import numpy as np
from time import time
import datetime
data = load_breast_cancer()
x = data.data
y = data.target
x.shape
#结果:(569, 30)
np.unique(y)
#结果:array([0, 1])
plt.scatter(x[:,0],x[:,1],c=y)
plt.show()


在使用多项式核函数进行训练时,长时间无法输出结果,因为选择其他三种核函数进行计算。
xtrain,xtest,ytrain,ytest = train_test_split(x,y,test_size = 0.3,random_state = 420)
Kernel = ["linear","rbf","sigmoid"]
for kernel in Kernel:
time0 = time()
clf = SVC(kernel = kernel
,gamma = "auto"
#,degree = 1 #多项式核函数的次数,默认为3
,cache_size = 5000 #MB
).fit(xtrain,ytrain)
print("The accuracy under kernel %s is %f" % (kernel,clf.score(xtest,ytest)))
print(datetime.datetime.fromtimestamp(time()-time0).strftime("%M:%S:%f"))
#结果:The accuracy under kernel linear is 0.929825
# 00:00:451092
# The accuracy under kernel rbf is 0.596491
# 00:00:046010
# The accuracy under kernel sigmoid is 0.596491
# 00:00:006002
可以发现,乳腺癌数据集是一个线性数据集,线性核函数跑出来的效果很好。rbf和sigmoid两个擅长非线性数据的核函数从效果上看完全不可用。并且线性核函数的运行速度远远不如非线性的两个核函数。而如果模型是线性的,那可以将degree参数调整为1,多项式核函数应该也可以得到不错的结果。
xtrain,xtest,ytrain,ytest = train_test_split(x,y,test_size = 0.3,random_state = 420)
Kernel = ["linear","rbf","sigmoid"]
for kernel in Kernel:
time0 = time()
clf = SVC(kernel = kernel
,gamma = "auto"
#,degree = 1 #多项式核函数的次数
,cache_size = 5000 #MB
).fit(xtrain,ytrain)
print("The accuracy under kernel %s is %f" % (kernel,clf.score(xtest,ytest)))
print(datetime.datetime.fromtimestamp(time()-time0).strftime("%M:%S:%f"))
#结果: The accuracy under kernel linear is 0.929825
# 00:00:460103
# The accuracy under kernel poly is 0.923977
# 00:00:085019
# The accuracy under kernel rbf is 0.596491
# 00:00:047011
# The accuracy under kernel sigmoid is 0.596491
# 00:00:005001
多项式核函数的运行速度加快了,并且精度也提升到了接近线性核函数的水平。但是明明rbf在线性数据上也可以表现得非常好,为什么这里跑出来的结果如此糟糕?其实这里真正的问题是数据的量纲问题。在求解决策边界和判断点是否在决策边界的一边时,是依靠计算“距离”。虽然不能说SVM完全是距离类模型,但是其严重受到数据量纲的影响。
import pandas as pd
data = pd.DataFrame(x)
data.describe([0.01,0.05,0.1,0.25,0.5,0.75,0.9,0.99]).T
#量纲不统一,并且数据存在偏态问题

从上表可以看出,数据存在严重的量纲不统一的问题,因此使用数据预处理中的标准化的类,对数据进行标准化。
from sklearn.preprocessing import StandardScaler
x = StandardScaler().fit_transform(x)
data = pd.DataFrame(x)
data.describe([0.01,0.05,0.1,0.25,0.5,0.75,0.9,0.99]).T

标准化完毕后,再次让SVC在核函数中遍历,此时把degree的数值设定为1,观察各个核函数在去量纲后的数据上的表现。
xtrain,xtest,ytrain,ytest = train_test_split(x,y,test_size = 0.3,random_state = 420)
Kernel = ["linear","poly,"rbf","sigmoid"]
for kernel in Kernel:
time0 = time()
clf = SVC(kernel = kernel
,gamma = "auto"
,degree = 1
,cache_size = 5000 #MB
).fit(xtrain,ytrain)
print("The accuracy under kernel %s is %f" % (kernel,clf.score(xtest,ytest)))
print(datetime.datetime.fromtimestamp(time()-time0).strftime("%M:%S:%f"))
#结果:The accuracy under kernel linear is 0.976608
# 00:00:011002
# The accuracy under kernel poly is 0.964912
# 00:00:005002
# The accuracy under kernel rbf is 0.970760
# 00:00:009002
# The accuracy under kernel sigmoid is 0.953216
# 00:00:004001
量纲统一之后,可以观察到,所有核函数的运算时间都大大地减少了,尤其是对于线性核函数来说,而多项式核函数居然变成了计算最快的。其次,rbf表现出了非常优秀的结果。经过探索,可以得到的结论是:
- 线性核,尤其是多项式核函数在高次项时计算非常缓慢
- rbf和多项式核函数都不擅长处理量纲不统一的数据集
但这两个缺点都可以由数据无量纲化来解决。因此,在SVM执行之前,非常推荐先进行数据的无量纲化。
2.2.5 选取与核函数相关的参数:degree & gamma & coef0
在知道如何选取核函数后,还要观察一下除了kernel之外的核函数相关的参数。对于线性核函数,“kernel”是唯一能够影响它的参数,但是对于其他三种非线性核函数,还受到参数gamma、degree以及coef0的影响。参数gamma就是表达式中的 γ \gamma γ,degree就是多项式核函数的次数 d d d,参数coef0就是常数项 r r r。其中,高斯径向基核函数受到gamma的影响,而多项式核函数受到全部三个参数的影响。
| 参数 | 含义 |
|---|---|
| degree | 整数,可不填,默认为3。多项式核函数的次数(“poly”),如果核函数没有选择“poly”,这个参数会被忽略 |
| gamma | 浮点数,可不填,默认为“auto”。核函数的系数,仅在参数kernel的选项为“rbf”、“poly”和“sigmoid”的时候有效。输入“auto”,自动使用1/(n_features)作为gamma的取值;输入“scale”,则使用1/(n_features*X.std())作为gamma的取值;输入“auto-deprecated”,则表示没有传递明确的gamma值(不推荐使用) |
| coef0 | 浮点数,可不填,默认为0.0。核函数中的常数项,它只在参数kernel为“poly”和“sigmoid”的时候有效 |
从核函数的公式来看,很难去界定具体每个参数如何影响了SVM的表现。当gamma的符号变化,或者degree的大小变化时,核函数本身甚至都不是永远单调的。所以如果想要彻底地理解这三个参数,要先推导出它们如何影响核函数的变化,再找出核函数的变化如何影响预测函数(可能改变核变换所在的维度),再判断出决策边界随着预测函数的改变发生了怎样的变化。无论从数学角度还是实践角度来说,这个过程太复杂也太低效。所以往往避免去真正探究这些参数如何影响了核函数,而直接使用学习曲线或者网格搜索来帮助查找最佳的参数组合。
对于高斯径向基核函数,调整gamma的方式其实比较容易,就是画学习曲线。下面试试看高斯径向基核函数rbf的参数gamma在乳腺癌数据集上的表现。
score = []
gamma_range = np.logspace(-10,1,50)
for i in gamma_range:
clf = SVC(kernel = "rbf",gamma = i,cache_size = 5000).fit(xtrain,ytrain)
score.append(clf.score(xtest,ytest))
print(max(score),gamma_range[score.index(max(score))])
plt.plot(gamma_range,score)
plt.show()
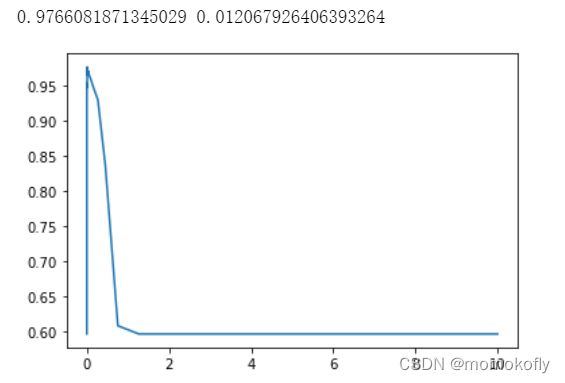
通过学习曲线很容易找出了rbf的最佳gamma值,并且通过多次调整gamma_range观察结果,可以确定97.6608应该是rbf核函数的极限了,这其实与线性核函数的准确率是一样的。但对于多项式核函数来说,三个参数共同作用在一个数学公式上影响它的效果,因此往往使用网格搜索来共同调整三个对多项式核函数有影响的参数。
from sklearn.model_selection import StratifiedShuffleSplit
from sklearn.model_selection import GridSearchCV
time0 = time()
gamma_range = np.logspace(-10,1,20)
coef0_range = np.logspace(0,5,10)
param_grid = dict(gamma = gamma_range,coef0 = coef0_range)
cv = StratifiedShuffleSplit(n_splits = 5,test_size = 0.3,random_state = 420)
grid = GridSearchCV(SVC(kernel = "poly",degree = 1,cache_size = 5000),param_grid = param_grid,cv=cv)
grid.fit(x,y)
print("The best parameters are %s with a score of %0.5f" % (grid.best_params_,grid.best_score_))
print(datetime.datetime.fromtimestamp(time()-time0).strftime("%M:%S:%f"))
#结果:The best parameters are {'coef0': 1.0, 'gamma': 0.18329807108324375} with a score of 0.96959
# 00:06:260419
可以发现,网格搜索返回了参数coef0=1.0,gamma=0.18329807108324375,但整体分数是0.96959,虽然比调参之前高,但依然没有超过线性核函数和rbf核函数的结果。可见,如果最初选择核函数的时候,就发现多项式的结果不如rbf和线性核函数,那就不要再尝试多项式核函数,试试调整rbf或者直接使用线性核函数。
2.3 硬间隔与软间隔:重要参数C
| 关键概念:硬间隔和软间隔 |
|---|
| 当两组数据是完全线性可分,可以找出一个决策边界使得训练集上的分类误差为0,这两种数据就被称为是存在“硬间隔”的。当两组数据几乎是完全线性可分的,但决策边界在训练集上存在较小的训练误差,这两种数据就被称为是存在“软间隔”的。 |
2.3.1 SVM在软间隔数据上的推广
可以通过调整对决策边界的定义,将硬间隔时得出的数学结论推广到软间隔的情况下,让决策边界能够忍受一小部分训练误差,这是决策边界就不是单纯地寻求最大边际了,因为对于软间隔的数据来说,边际越大被分错的样本也就越多,因此需要找出一个“最大边际”与“被分错的样本数量”之间的平衡。

上图中,原始的决策边界 w ∗ x + b = 0 \textbf{w}*\textbf{x}+b=0 w∗x+b=0,原本平行于决策边界的两个虚线超平面 w ∗ x + b = 1 \textbf{w}*\textbf{x}+b=1 w∗x+b=1和 w ∗ x + b = − 1 \textbf{w}*\textbf{x}+b=-1 w∗x+b=−1都依然有效。原始判别函数为:
w ∗ x i + b > = 1 , i f y i = 1 \textbf{w}*\textbf{x}_i+b>=1,if y_i=1 w∗xi+b>=1,ifyi=1
w ∗ x i + b < = − 1 , i f y i = − 1 \textbf{w}*\textbf{x}_i+b<=-1,if y_i=-1 w∗xi+b<=−1,ifyi=−1
但这些超平面现在无法让数据上的训练误差等于0,因为此时存在一个混杂在红色点中的紫色点 x p x_p xp。于是需要放松原始判别函数中的不等条件,来让决策边界能够适用于异常点。于是引入松弛系数 ζ \zeta ζ来帮助优化原始的判别函数:
w ∗ x i + b > = 1 − ζ i , i f y i = 1 \textbf{w}*\textbf{x}_i+b>=1-\zeta_i,if y_i=1 w∗xi+b>=1−ζi,ifyi=1
w ∗ x i + b < = − 1 + ζ i , i f y i = − 1 \textbf{w}*\textbf{x}_i+b<=-1+\zeta_i,if y_i=-1 w∗xi+b<=−1+ζi,ifyi=−1
其中 ζ i > 0 \zeta_i>0 ζi>0。可以看出,这其实是将原本的虚线超平面向图像上方和下方平移。松弛系数其实很好理解,上面的图像中位于红色点附近的紫色点 x p x_p xp在原本的判别函数中必定会被分为红色,所以一定会被判断错误。现在作一条与决策边界平行,但过点 x p x_p xp的直线 w ∗ x i + b = 1 − ζ i \textbf{w}*\textbf{x}_i+b=1-\zeta_i w∗xi+b=1−ζi(图中的蓝色虚线)。这条直线是由 w ∗ x i + b = 1 \textbf{w}*\textbf{x}_i+b=1 w∗xi+b=1平移得到,所以两条直线在纵坐标上的差异就是 ζ \zeta ζ(竖直的黑色箭头)。而点 x p x_p xp到直线 w ∗ x i + b = 1 \textbf{w}*\textbf{x}_i+b=1 w∗xi+b=1的距离就可以表示为 ζ ⋅ w ∣ ∣ w ∣ ∣ \frac{\zeta\cdot w}{\mid\mid w\mid\mid} ∣∣w∣∣ζ⋅w,即 ζ \zeta ζ在 w \textbf{w} w方向上的投影。由于单位向量是固定的,所以 ζ \zeta ζ可以作为点 x p x_p xp在原始的决策边界上的分类错误程度的表示,隔得越远,分得越错。但注意, ζ \zeta ζ并不是点到决策超平面的距离本身。
不难注意到,让 w ∗ x i + b > = 1 − ζ i \textbf{w}*\textbf{x}_i+b>=1-\zeta_i w∗xi+b>=1−ζi作为新的决策超平面是存在一定问题的。虽然把异常的紫色点分类正确了,但同时也分错了一系列红色的点,所以必须在求解最大边际的损失函数中加上一个惩罚项,用来惩罚具有巨大松弛系数的决策超平面。拉格朗日函数、拉格朗日对偶函数也都因此被松弛系数改变,现在,损失函数为: min w , b , ζ ∣ ∣ w ∣ ∣ 2 2 + C ∑ i = 1 n ζ i , s . t . y i ( w ⋅ Φ ( x i ) + b ) > = 1 − ζ i , ζ i > = 0 , i = 1 , 2 , . . . . . . , N \min_{w,b,\zeta}\frac{\mid\mid\textbf{w}\mid\mid^2}{2}+C\sum_{i=1}^n\zeta_i,s.t. y_i(\textbf{w}\cdot\Phi(\textbf{x}_i)+b)>=1-\zeta_i,\zeta_i>=0,i=1,2,......,N w,b,ζmin2∣∣w∣∣2+Ci=1∑nζi,s.t.yi(w⋅Φ(xi)+b)>=1−ζi,ζi>=0,i=1,2,......,N其中 C C C是用来控制惩罚项的惩罚力度的系数。
拉格朗日函数为(其中 μ \mu μ是第二个拉格朗日函数): L ( w , b , α , ζ ) = 1 2 ∣ ∣ w ∣ ∣ 2 + C ∑ i = 1 N ζ i − ∑ i = 1 N α i ( y i ( w ⋅ Φ ( x i ) + b ) − 1 + ζ i ) − ∑ i = 1 N μ i ζ i L(w,b,\alpha,\zeta)=\frac{1}{2}||w||^2+C\sum_{i=1}^N\zeta_i-\sum_{i=1}^N\alpha_i(y_i(\textbf{w}\cdot\Phi(\textbf{x}_i)+b)-1+\zeta_i)-\sum_{i=1}^N\mu_i\zeta_i L(w,b,α,ζ)=21∣∣w∣∣2+Ci=1∑Nζi−i=1∑Nαi(yi(w⋅Φ(xi)+b)−1+ζi)−i=1∑Nμiζi需要满足的KKT条件为:
∂ L ( w , b , α , ζ ) ∂ w = ∂ L ( w , b , α , ζ ) ∂ b = ∂ L ( w , b , α , ζ ) ∂ ζ \frac{\partial L(w,b,\alpha,\zeta)}{\partial w}=\frac{\partial L(w,b,\alpha,\zeta)}{\partial b}=\frac{\partial L(w,b,\alpha,\zeta)}{\partial \zeta} ∂w∂L(w,b,α,ζ)=∂b∂L(w,b,α,ζ)=∂ζ∂L(w,b,α,ζ)=0
ζ i > = 0 , α i > = 0 , μ i > = 0 \zeta_i>=0,\alpha_i>=0,\mu_i>=0 ζi>=0,αi>=0,μi>=0
α i ( y i ( w ⋅ Φ ( x i ) + b ) − 1 + ζ i ) = 0 \alpha_i(y_i(\textbf{w}\cdot\Phi(\textbf{x}_i)+b)-1+\zeta_i)=0 αi(yi(w⋅Φ(xi)+b)−1+ζi)=0
μ i ζ i = 0 \mu_i\zeta_i=0 μiζi=0
拉格朗日对偶函数为: L D = ∑ i = 1 N α i − 1 2 ∑ i , j α i α j y i y j Φ ( x i ) Φ ( x j ) , s . t . C > = α i > = 0 L_D=\sum_{i=1}^N\alpha_i-\frac{1}{2}\sum_{i,j}\alpha_i\alpha_jy_iy_j\Phi(\textbf{x}_i)\Phi(\textbf{x}_j),s.t. C>=\alpha_i>=0 LD=i=1∑Nαi−21i,j∑αiαjyiyjΦ(xi)Φ(xj),s.t.C>=αi>=0这种状况下的拉格朗日对偶函数看起来和线性可分状况下的对偶函数一模一样,但拉格朗日乘数 α \alpha α的取值的限制改变了。在硬间隔的状况下,拉格朗日乘数值需要大于等于0,而现在被要求不能够大于用来控制惩罚项的惩罚力度的系数 C C C。有了对偶函数之后,求解过程和硬间隔下的步骤一致。以上所有的公式,是以线性硬间隔数据为基础,考虑了软间隔存在的情况和数据是非线性的状况而得来的。这些公式也就是sklearn类SVC背后使用的最终公式。公式中唯一的新变量,松弛系数的惩罚力度 C C C,由参数 C C C来进行控制。
2.3.2 重要参数C
参数 C C C用于权衡将“训练样本的正确分类”与“决策函数的边际最大化”的效力。
| 参数 | 含义 |
|---|---|
| C | 浮点数,默认为1,且必须大于等于0,可不填。松弛系数的惩罚项系数,如果C值设定比较大,那SVC可能会选择边际较小的,能够更好地分类所有训练点的决策边界,不过模型的训练时间也会更长。如果C的设定较高,那么SVC会尽量最大化边际,决策功能会更简单,但代价是训练的准确度。换句话说,C在SVM中的影响就像正则化参数对逻辑回归的影响。 |
在实际使用中,C和核函数的相关参数(gamma、degree等)搭配,往往是SVM调参的重点。与gamma不同,C没有在对偶函数中出现,并且是明确了调参目标的,所以可以明确究竟是否需要训练集上的高精确度来调整C的方向。默认情况下C为1,通常来说这都是一个合理的参数。如果数据很嘈杂,那往往减小C。当然也可以使用网格搜索或学习曲线来调整C值。
#调线性核函数
score = []
c_range = np.linspace(0.01,30,50)
for i in c_range:
clf = SVC(kernel = "linear",C = i,cache_size = 5000).fit(xtrain,ytrain)
score.append(clf.score(xtest,ytest))
print(max(score),c_range[score.index(max(score))])
plt.plot(c_range,score)
plt.show()

#换rbf
score = []
c_range = np.linspace(0.01,30,50)
for i in c_range:
clf = SVC(kernel = "rbf",C = i,gamma = 0.012067926406393264
,cache_size = 5000).fit(xtrain,ytrain)
score.append(clf.score(xtest,ytest))
print(max(score),c_range[score.index(max(score))])
plt.plot(c_range,score)
plt.show()
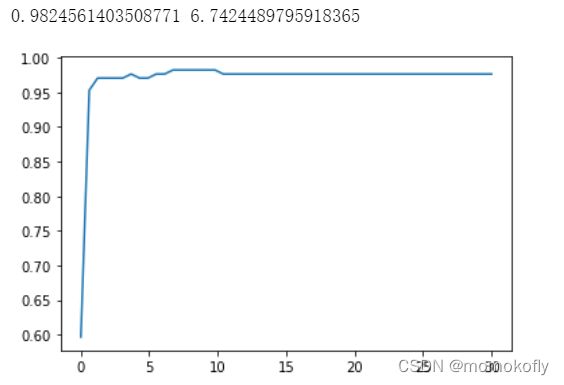
此时找到了乳腺癌数据集上的最优解:rbf核函数下的98.24%的准确率。当然,还可以使用交叉验证来改进模型,获得不同测试集和训练集上的交叉验证结果。
2.4 总结
本文包括支持向量机的原理、损失函数、拉格朗日函数、拉格朗日对偶函数、预测函数以及这些函数在非线性、软间隔这些情况下的推广。介绍了四种核函数,包括它们的特点、适合什么样的数据、有什么相关参数、优缺点以及何时使用。最后介绍了核函数在相关参数上的调参。
参考资料:https://www.bilibili.com/video/BV1WL4y1H7rD?p=43&spm_id_from=pageDriver