技术前沿
来源:olgalitech
编译整理:萝卜兔
今年的CVPR落下帷幕,会议总计接收了900+论文,我们整理了CVPR相关的内容成笔记,和大家一起分享。
三天的会议主要分享了以下主题:
特别会议:Workshop Competitions
物体识别和场景理解
图像中的人物分析
3D视觉
CV中的机器学习
视频分析
计算摄影
图像运动与跟踪
应用
有价值的趋势和主题:
视频分析:视频描述、动作分类、行人运动轨迹预测
虚拟空间中机器定向移动以及完成特定任务
视频行人再识别
风格迁移(GAaaaNs)
Adversarial attacks analysis
图像增强——消除阴影
自然语言与计算机视觉的结合
图像和视频显著性分析
边缘设备的高效计算
CV中的弱监督学习
领域自适应
可解释的机器学习
强化学习在CV中的应用
关于数据标记
笔记分为以下几个部分:
场景分析和问答
图像增强与操作
CV中的各种网络结构
目标驱动导航,室内3D场景
与人相关的分析
高效的DNN
数据和CV
场景分析和问答
会议主题
Embodied Question Answering
重点
向可以看、说话、行动以及推理的机器人迈进
框架和技术细节
论文连接:
https://arxiv.org/abs/1711.11543
视觉模型
以CNN作为编码器,使用多任务学习像素到像素预测
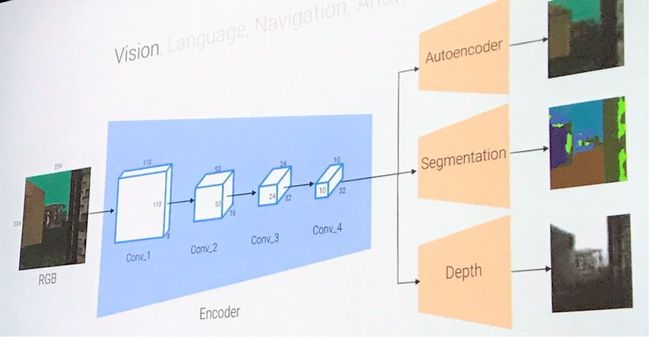
语言模型:2层 LSTMs
导航模型:
“Planner”选择动作(左、右、前、后)
“controller”执行预设动作多次

问答模型

检查最后5帧,基于图像与问题的相似度,采用注意力机制计算特征编码,将这与LSTM编码相结合,并在172个可能答案空间上输出softmax。
数据
EQA数据集:rgb图像、语义分割掩码、深度图、地图;12种房型:厨房、起居室...50种对象类型
计算机生成的问题:
https://github.com/facebookresearch/House3D
应用
仿人类机器人
会议主题
Learning by Asking Questions(LBA)
重点
让机器自己决策它们需要什么信息以及如何获取,优于监督学习
框架和技术细节
给出一些图像,通过询问问题,获得答案的方式进行监督

问题生成模型是一个图像描述模型,使用图像特征为条件的LSTM来生成问题
问答模块是标准的VQA模型
数据
CLEVR:70k images,700image-QA
参考
https://research.fb.com/publications/learning-by-asking-questions/
会议主题
Im2Flow: Motion Hallucination from Static Images for Action Recognition
重点
将静态图像转换为光流图,从而预测单个照片隐含的没有观察到的未来的运动趋势,有助于静态图像的动作识别
框架和技术细节
编码器-解码器CNN、新颖的光流编码将静态图转换为流。

数据
从UCF-101 HMDB-51的视频数据中抽取了70万帧
应用
图像以及视频分析、字幕、动态分析和动作识别
会议主题
Actor and Action Video Segmentation from a Sentence
重点
动作是由一句话来指定,而不是以前的一些词;做动作的主体不限于人,可以是动物等其它目标
框架和技术细节
论文:
https://arxiv.org/abs/1803.07485
代码:
https://kgavrilyuk.github.io/publication/actor_action/
模型由3个部分组成:
CNN编码输入的句子
3DCNN对视频进行编码
解码器进行像素分割
通过将从编码的文本表示生成的动态滤波器与编码的视频表示进行卷积来进行解码。相同的模型应用于Flow输入。

数据
使用超过7500种自然语言描述扩展了两个流行的actor和action数据集
应用
视频分析、索引、字幕
会议主题
Egocentric Activity Recognition on a Budget(EAR)
重点
使用RL来学习具有差异能量分布的策略
框架和技术细节
论文:http://web.it.usyd.edu.au/~framos/Publications_files/egocentric-activity-recognition%20%282%29.pdf
智能眼镜的电池和处理能力有限
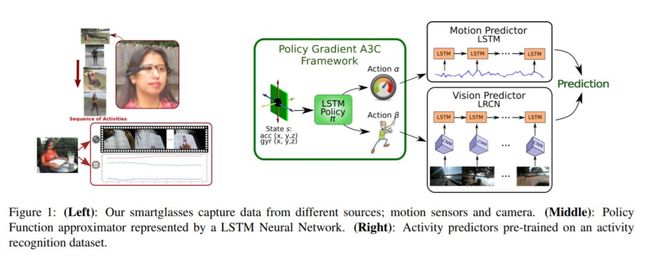
数据
数据集:
http://sheilacaceres.com/dataego/
应用
将AI用于辅助生活和护理服务(活动跟踪和分类,使用智能眼镜的数据)EAR可以提供提醒、警告,帮助有认知障碍的人规避风险
会议主题
Emotional Attention: A Studt of Image Sentiment and Visual Attention
重点
第一个研究图像情感属性和视觉注意力之间联系的研究,创建了MOtional注意数据集
框架和技术细节
论文和代码:
https://nussesame.top/emotionalattention/
设计一个用于显著性预测的DNN,包括一个学习图像场景的空间和语义上下文的新子网络结构
CASNet:通道加权子网络(虚线橙色矩形内)为每个图像计算一组1024维特征权重,以捕获特定图像的语义特征的相对重要性。
灰色虚线箭头说明如何通过子网络修改图像内不同区域的相对显著性。

数据
EMOd(1019张图像), NUSEF(751张), CAT2000(2000张)
应用
视频监控、描述
会议主题
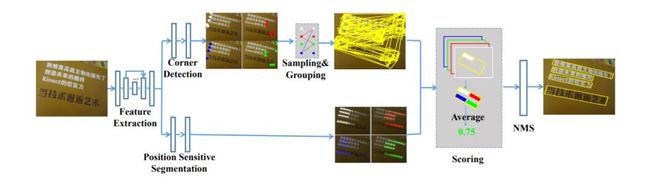
Multi-Oriented Scene Text Detection via Corner Localization and Region Segmentation
重点
通过定位文本边界框的角点并在相对位置分割文本区域来检测场景文本
框架和技术细节
论文:
https://arxiv.org/abs/1802.08948
结合目标检测和语义分割的思想,并以另一种方式应用它们
给定图像,网络通过角点检测和位置敏感分割输出角点和分割图。然后通过采样和分组角点生成候选框。最后利用分割图和NMS选择候选框。
数据
ICDAR2013,ICDAR2015,MSRA-TD500, MLT and COCO-Text
应用
从自然场景图像中提取文本信息:产品搜索、图像检索、自动驾驶
会议主题
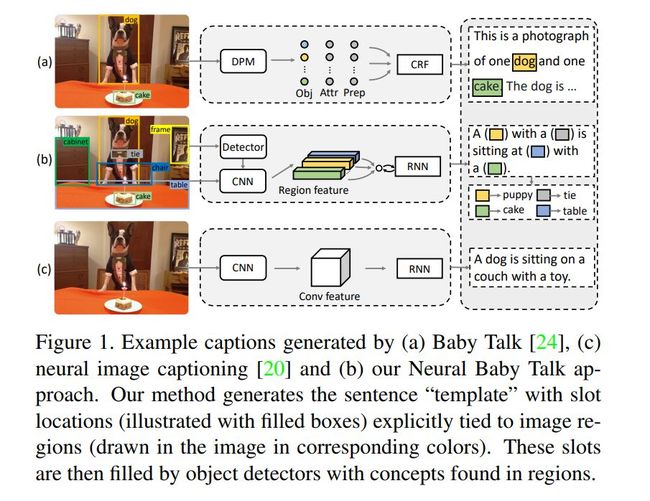
Neural baby talk
重点
采用物体检测器检测图像中的物体(visual words),然后在每个word的生成时刻,自主决定选取text word(数据集中的词汇) 还是 visual word(检测到的词汇)。
框架和技术细节
论文:
https://arxiv.org/pdf/1803.09845.pdf
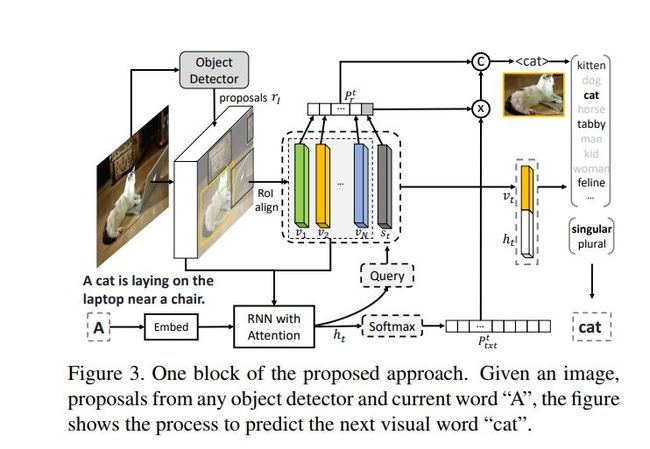
数据
Coco dataset
应用
图像字幕任务
图像增强
会议主题
xUnit: Learning a Spatial Activation Function for Efficient Image Restoration
重点
显著减少学习参数的数量,对于超分辨率和去噪结构,参数的数量减少了一半以上。
框架和技术细节
论文:
https://arxiv.org/abs/1711.06445
与ReLUs和sigmoid这样应用广泛的逐点激活函数不同,本文实现了具有空间连接的可学习非线性函数,使得网络能够捕获更加复杂的特征,实现更少的层数达到相同的性能。

数据
BSD68, Rain12.
应用
超级分辨率、降噪
会议主题
Deformation Aware Image Compression
重点
编码器不需要过多比特来描述精细结构的精确几何形状,更多的比特用在重要部分,保存图像更多的的细节。
框架和技术细节
论文:
https://arxiv.org/abs/1804.04593
易于并入任何CODEC
由于人类对轻微的局部平移没有什么察觉,作者提出了一种变形不敏感的SSD度量:变形感知SSD。
数据
Berkley分段数据集、Kodak数据集
应用
压缩
会议主题
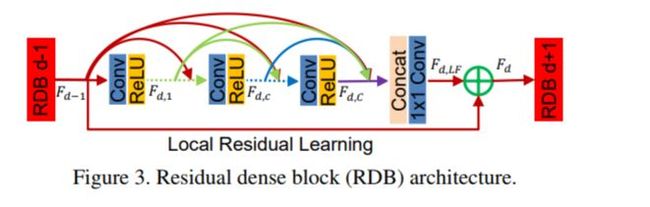
Residual Dense Network for Image Super-Resolution
重点
他的目标是充分利用原始低分辨率(LR)图像的特征
框架和技术细节
论文:
https://arxiv.org/abs/1802.08797

RDB
数据
DIV2K,Set5, Set14, B100, Urban100, Manga109
应用
照片编辑app
会议主题
Attentive Generative Adversarial Network for Raindrop Removal from a Single Image
重点
提出将视觉注意注入生成网络和判别网络,特别注意雨滴区域。
框架和技术细节
论文:
https://arxiv.org/abs/1711.10098
混合GANs、LSTM和Unet

数据
作者自己创建的数据集(1k图像对)
应用
照片编辑app
会议主题
Burst Denoising with Kernel Prediction Networks
重点
CNN的预测可对齐和去噪帧的空间变化内核,有趣的数据生成方法
框架和技术细节
论文:
https://arxiv.org/abs/1712.02327

数据
合成数据,使用来自公开图像数据集的图像,修改图像引入接近真实图像突发特征的合成失调和噪声。
应用
照片编辑app
会议主题
Crafting a Toolchain for Image Restoration by Deep Reinforcement Learning
重点
由专门从事不同任务的小规模CNNs组成的工具箱与RL:学习策略以选择适当的工具来恢复损坏的图像。
框架和技术细节

项目链接:
http://mmlab.ie.cuhk.edu.hk/projects/RL-Restore/
数据
DIV2K
应用
照片编辑app
原文链接:
https://olgalitech.wordpress.com/2018/06/30/cvpr-2018-recap-notes-and-trends/
